
Ví dụ về một thành phần chính của TensorFlow Extended
 Xem nguồn trên GitHub
Xem nguồn trên GitHubSổ ghi chép cột ví dụ này minh họa cách xác thực dữ liệu TensorFlow (TFDV) có thể được sử dụng để điều tra và trực quan hóa tập dữ liệu của bạn. Điều đó bao gồm việc xem xét các thống kê mô tả, suy ra một lược đồ, kiểm tra và sửa các điểm bất thường cũng như kiểm tra độ lệch và lệch trong tập dữ liệu của chúng tôi. Điều quan trọng là phải hiểu các đặc điểm của tập dữ liệu, bao gồm cả cách nó có thể thay đổi theo thời gian trong quy trình sản xuất của bạn. Điều quan trọng là phải tìm kiếm các điểm bất thường trong dữ liệu của bạn và so sánh các tập dữ liệu đào tạo, đánh giá và phục vụ của bạn để đảm bảo rằng chúng nhất quán.
Chúng tôi sẽ sử dụng dữ liệu từ bộ dữ liệu Chuyến đi taxi do Thành phố Chicago phát hành.
Đọc thêm về tập dữ liệu trong Google BigQuery . Khám phá tập dữ liệu đầy đủ trong giao diện người dùng BigQuery .
Các cột trong tập dữ liệu là:
| pickup_community_area | giá vé | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | Pick_census_tract |
| dropoff_census_tract | hình thức thanh toán | Công ty |
| trip_seconds | dropoff_community_area | lời khuyên |
Cài đặt và nhập các gói
Cài đặt các gói cho TensorFlow Data Validation.
Nâng cấp Pip
Để tránh nâng cấp Pip trong hệ thống khi chạy cục bộ, hãy kiểm tra để đảm bảo rằng chúng tôi đang chạy trong Colab. Hệ thống cục bộ tất nhiên có thể được nâng cấp riêng.
try:
import colab
!pip install --upgrade pip
except:
pass
Cài đặt gói Xác thực Dữ liệu
Cài đặt các gói và các gói phụ thuộc TensorFlow Data Validation, quá trình này sẽ mất vài phút. Bạn có thể thấy các cảnh báo và lỗi liên quan đến các phiên bản phụ thuộc không tương thích mà bạn sẽ giải quyết trong phần tiếp theo.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Nhập TensorFlow và tải lại các gói đã cập nhật
Bước trước đó cập nhật các gói mặc định trong môi trường Gooogle Colab, vì vậy bạn phải tải lại tài nguyên gói để giải quyết các phần phụ thuộc mới.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Kiểm tra các phiên bản của TensorFlow và Data Validation trước khi tiếp tục.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Tải tập dữ liệu
Chúng tôi sẽ tải xuống tập dữ liệu của mình từ Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Tính toán và trực quan hóa số liệu thống kê
Đầu tiên, chúng tôi sẽ sử dụng tfdv.generate_statistics_from_csv để tính toán thống kê cho dữ liệu đào tạo của chúng tôi. (bỏ qua các cảnh báo linh hoạt)
TFDV có thể tính toán số liệu thống kê mô tả cung cấp tổng quan nhanh về dữ liệu về các tính năng hiện có và hình dạng của các phân phối giá trị của chúng.
Bên trong, TFDV sử dụng khung xử lý song song dữ liệu của Apache Beam để mở rộng quy mô tính toán thống kê trên các tập dữ liệu lớn. Đối với các ứng dụng muốn tích hợp sâu hơn với TFDV (ví dụ: đính kèm tạo thống kê ở cuối đường dẫn tạo dữ liệu), API cũng hiển thị Beam PTransform để tạo thống kê.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
Bây giờ, hãy sử dụng tfdv.visualize_statistics , sử dụng Các khía cạnh để tạo hình ảnh trực quan ngắn gọn về dữ liệu đào tạo của chúng tôi:
- Lưu ý rằng các đối tượng địa lý dạng số và đối tượng địa lý được hiển thị riêng biệt và các biểu đồ được hiển thị cho thấy sự phân bổ cho từng đối tượng địa lý.
- Lưu ý rằng các tính năng có giá trị bị thiếu hoặc không hiển thị phần trăm màu đỏ như một chỉ báo trực quan rằng có thể có vấn đề với các ví dụ trong các tính năng đó. Phần trăm là phần trăm các ví dụ có giá trị bị thiếu hoặc bằng không cho đối tượng địa lý đó.
- Lưu ý rằng không có ví dụ nào có giá trị cho
pickup_census_tract. Đây là một cơ hội để giảm kích thước! - Hãy thử nhấp vào "mở rộng" phía trên biểu đồ để thay đổi màn hình
- Hãy thử di chuột qua các thanh trong biểu đồ để hiển thị phạm vi và số lượng nhóm
- Hãy thử chuyển đổi giữa thang đo nhật ký và thang đo tuyến tính và lưu ý cách thang đo nhật ký tiết lộ nhiều chi tiết hơn về tính năng phân loại
payment_type - Hãy thử chọn "lượng tử" từ menu "Biểu đồ để hiển thị" và di chuột qua các điểm đánh dấu để hiển thị phần trăm lượng tử
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
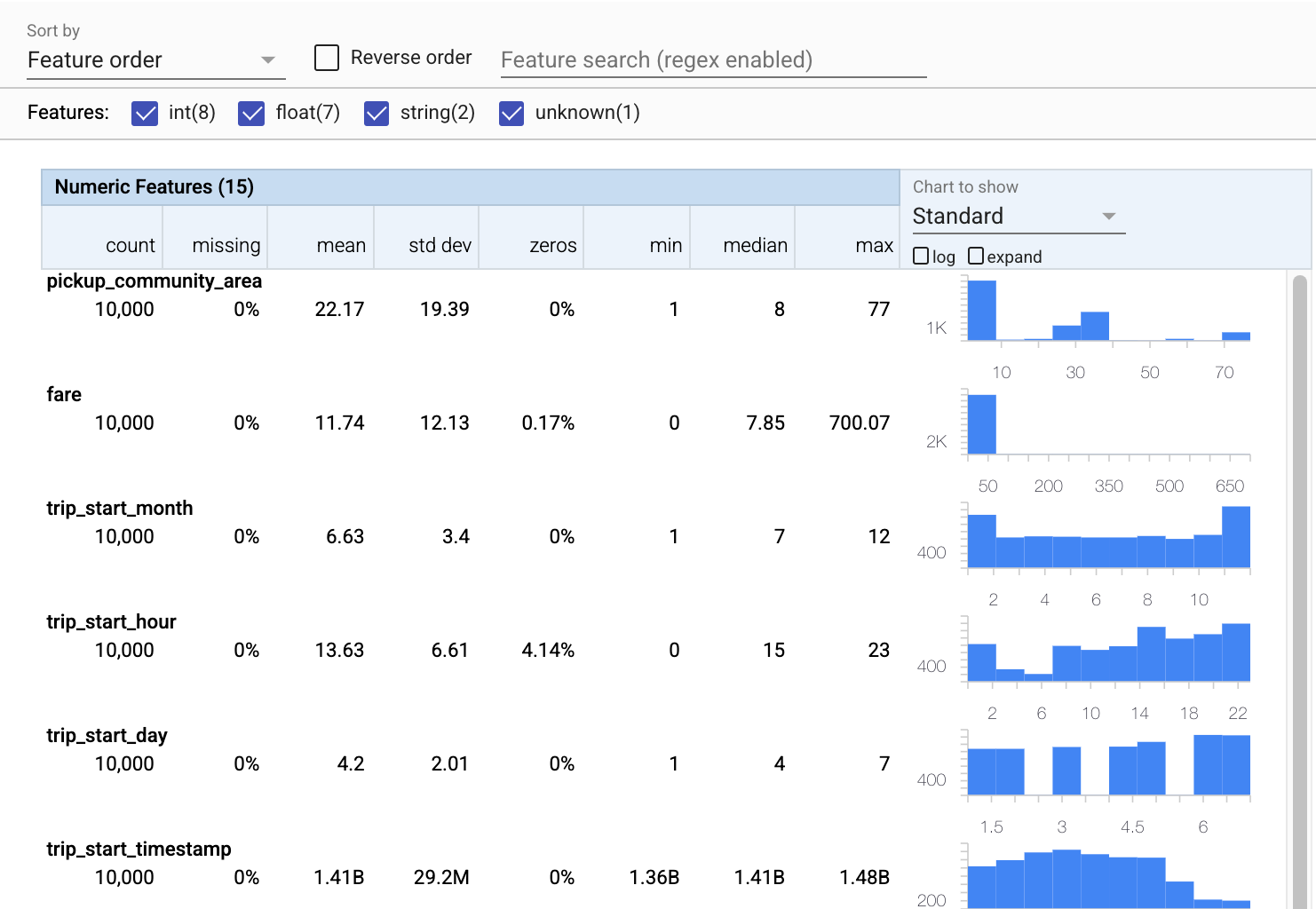
Suy ra một lược đồ
Bây giờ, hãy sử dụng tfdv.infer_schema để tạo một lược đồ cho dữ liệu của chúng ta. Một lược đồ xác định các ràng buộc cho dữ liệu có liên quan đến ML. Các ràng buộc ví dụ bao gồm kiểu dữ liệu của mỗi đối tượng địa lý, cho dù đó là số hoặc phân loại, hoặc tần suất xuất hiện của đối tượng trong dữ liệu. Đối với các đối tượng phân loại, lược đồ cũng xác định miền - danh sách các giá trị có thể chấp nhận được. Vì việc viết một lược đồ có thể là một công việc tẻ nhạt, đặc biệt là đối với các bộ dữ liệu có nhiều tính năng, TFDV cung cấp một phương pháp để tạo phiên bản ban đầu của lược đồ dựa trên thống kê mô tả.
Làm cho đúng lược đồ là rất quan trọng vì phần còn lại của quy trình sản xuất của chúng tôi sẽ dựa vào lược đồ mà TFDV tạo ra là đúng. Lược đồ cũng cung cấp tài liệu cho dữ liệu và do đó rất hữu ích khi các nhà phát triển khác nhau làm việc trên cùng một dữ liệu. Hãy sử dụng tfdv.display_schema để hiển thị lược đồ được suy ra để chúng ta có thể xem xét nó.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Kiểm tra dữ liệu đánh giá để tìm lỗi
Cho đến nay, chúng tôi chỉ xem xét dữ liệu đào tạo. Điều quan trọng là dữ liệu đánh giá của chúng tôi phải nhất quán với dữ liệu đào tạo của chúng tôi, bao gồm cả việc dữ liệu này sử dụng cùng một lược đồ. Điều quan trọng là dữ liệu đánh giá bao gồm các ví dụ về các phạm vi giá trị gần như tương tự cho các đối tượng số của chúng tôi như dữ liệu đào tạo của chúng tôi, để mức độ bao phủ của chúng tôi về bề mặt tổn thất trong quá trình đánh giá gần giống như trong quá trình đào tạo. Điều này cũng đúng đối với các đối tượng địa lý phân loại. Nếu không, chúng tôi có thể gặp các vấn đề đào tạo không được xác định trong quá trình đánh giá, vì chúng tôi đã không đánh giá một phần bề mặt tổn thất của chúng tôi.
- Lưu ý rằng mỗi tính năng hiện bao gồm số liệu thống kê cho cả tập dữ liệu đào tạo và đánh giá.
- Lưu ý rằng các biểu đồ hiện có cả tập dữ liệu đào tạo và đánh giá được xếp chồng lên nhau, giúp dễ dàng so sánh chúng.
- Lưu ý rằng các biểu đồ hiện bao gồm chế độ xem tỷ lệ phần trăm, có thể được kết hợp với nhật ký hoặc tỷ lệ tuyến tính mặc định.
- Lưu ý rằng giá trị trung bình và giá trị trung bình cho
trip_milesđối với khóa đào tạo là khác nhau so với tập dữ liệu đánh giá. Điều đó sẽ gây ra vấn đề? - Chà, các
tipstối đa rất khác nhau cho quá trình đào tạo so với các bộ dữ liệu đánh giá. Điều đó sẽ gây ra vấn đề? - Nhấp vào mở rộng trên biểu đồ Tính năng số và chọn tỷ lệ nhật ký. Xem lại tính năng
trip_secondsvà nhận thấy sự khác biệt trong giá thầu CPC Đánh giá có bỏ sót các phần của bề mặt mất mát không?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
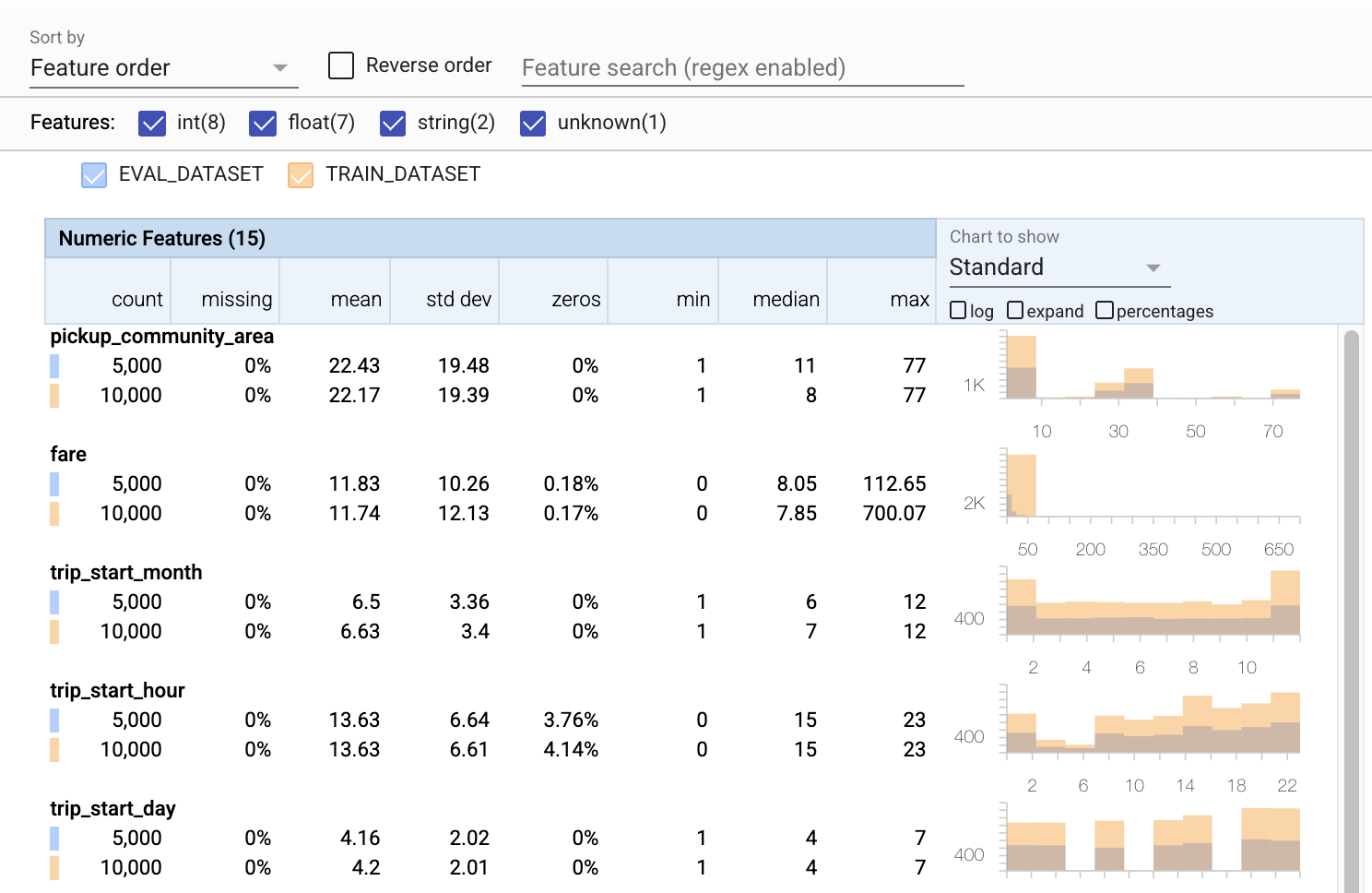
Kiểm tra các bất thường trong đánh giá
Tập dữ liệu đánh giá của chúng tôi có khớp với lược đồ từ tập dữ liệu đào tạo của chúng tôi không? Điều này đặc biệt quan trọng đối với các đối tượng địa lý phân loại, nơi chúng tôi muốn xác định phạm vi giá trị có thể chấp nhận được.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Khắc phục các dị thường đánh giá trong lược đồ
Giáo sư! Có vẻ như chúng tôi có một số giá trị mới cho company trong dữ liệu đánh giá của chúng tôi, mà chúng tôi không có trong dữ liệu đào tạo của mình. Chúng tôi cũng có một giá trị mới cho payment_type . Đây nên được coi là những điểm bất thường, nhưng những gì chúng tôi quyết định làm với chúng phụ thuộc vào kiến thức miền của chúng tôi về dữ liệu. Nếu sự bất thường thực sự chỉ ra lỗi dữ liệu, thì dữ liệu cơ bản sẽ được sửa. Nếu không, chúng ta có thể chỉ cần cập nhật giản đồ để bao gồm các giá trị trong tập dữ liệu eval.
Trừ khi chúng tôi thay đổi tập dữ liệu đánh giá của mình, chúng tôi không thể sửa mọi thứ, nhưng chúng tôi có thể sửa những thứ trong lược đồ mà chúng tôi thoải mái chấp nhận. Điều đó bao gồm việc thư giãn quan điểm của chúng tôi về những gì có và những gì không phải là bất thường đối với các đối tượng địa lý cụ thể, cũng như cập nhật giản đồ của chúng tôi để bao gồm các giá trị còn thiếu cho các đối tượng địa lý phân loại. TFDV đã cho phép chúng tôi khám phá những gì chúng tôi cần khắc phục.
Hãy thực hiện các bản sửa lỗi đó ngay bây giờ và sau đó xem xét lại một lần nữa.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Này, nhìn kìa! Chúng tôi đã xác minh rằng dữ liệu đào tạo và đánh giá hiện đã nhất quán! Cảm ơn TFDV;)
Môi trường giản đồ
Chúng tôi cũng tách tập dữ liệu 'phục vụ' cho ví dụ này, vì vậy chúng tôi cũng nên kiểm tra tập dữ liệu đó. Theo mặc định, tất cả các tập dữ liệu trong một đường ống phải sử dụng cùng một lược đồ, nhưng thường có những ngoại lệ. Ví dụ: trong học tập có giám sát, chúng tôi cần đưa các nhãn vào tập dữ liệu của mình, nhưng khi chúng tôi cung cấp mô hình để suy luận, các nhãn sẽ không được đưa vào. Trong một số trường hợp, việc giới thiệu các biến thể giản đồ nhỏ là cần thiết.
Các môi trường có thể được sử dụng để thể hiện các yêu cầu đó. Đặc biệt, các tính năng trong lược đồ có thể được liên kết với một tập hợp các môi trường sử dụng default_environment , in_environment và not_in_environment .
Ví dụ: trong tập dữ liệu này, tính năng tips được bao gồm dưới dạng nhãn dành cho đào tạo, nhưng nó bị thiếu trong dữ liệu phục vụ. Nếu không có môi trường được chỉ định, nó sẽ hiển thị như một sự bất thường.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Chúng tôi sẽ giải quyết các tính năng tips bên dưới. Chúng tôi cũng có một giá trị INT trong số giây chuyến đi của chúng tôi, trong đó giản đồ của chúng tôi mong đợi một FLOAT. Bằng cách làm cho chúng tôi nhận thức được sự khác biệt đó, TFDV giúp phát hiện ra sự mâu thuẫn trong cách dữ liệu được tạo ra để đào tạo và phục vụ. Rất dễ dàng không nhận thức được các vấn đề như vậy cho đến khi hiệu suất của mô hình bị ảnh hưởng, đôi khi là thảm khốc. Nó có thể là một vấn đề quan trọng hoặc không, nhưng trong mọi trường hợp, điều này cần được điều tra thêm.
Trong trường hợp này, chúng tôi có thể chuyển đổi các giá trị INT thành FLOAT một cách an toàn, vì vậy chúng tôi muốn yêu cầu TFDV sử dụng lược đồ của chúng tôi để suy ra loại. Hãy làm điều đó ngay bây giờ.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Bây giờ chúng tôi chỉ có tính năng tips (là nhãn của chúng tôi) hiển thị dưới dạng bất thường ('Cột bị giảm'). Tất nhiên, chúng tôi không mong đợi có nhãn trong dữ liệu phục vụ của mình, vì vậy hãy yêu cầu TFDV bỏ qua điều đó.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Kiểm tra độ lệch và độ lệch
Ngoài việc kiểm tra xem tập dữ liệu có tuân theo các kỳ vọng được đặt trong lược đồ hay không, TFDV cũng cung cấp các chức năng để phát hiện độ lệch và độ lệch. TFDV thực hiện việc kiểm tra này bằng cách so sánh số liệu thống kê của các bộ dữ liệu khác nhau dựa trên các bộ so sánh độ lệch / độ lệch được chỉ định trong lược đồ.
Trôi dạt
Tính năng phát hiện độ lệch được hỗ trợ cho các đối tượng phân loại và giữa các khoảng dữ liệu liên tiếp (tức là giữa khoảng N và khoảng N + 1), chẳng hạn như giữa các ngày dữ liệu huấn luyện khác nhau. Chúng tôi thể hiện độ lệch theo khoảng cách vô cực L và bạn có thể đặt khoảng cách ngưỡng để bạn nhận được cảnh báo khi độ lệch cao hơn mức có thể chấp nhận được. Đặt khoảng cách chính xác thường là một quá trình lặp đi lặp lại đòi hỏi kiến thức và thử nghiệm miền.
Nghiêng
TFDV có thể phát hiện ba loại sai lệch khác nhau trong dữ liệu của bạn - độ lệch giản đồ, độ lệch đối tượng và độ lệch phân phối.
Lược đồ Skew
Sai lệch lược đồ xảy ra khi dữ liệu đào tạo và cung cấp không tuân theo cùng một lược đồ. Cả dữ liệu đào tạo và dữ liệu cung cấp đều phải tuân theo cùng một lược đồ. Bất kỳ sai lệch dự kiến nào giữa hai điều này (chẳng hạn như đặc điểm nhãn chỉ hiện diện trong dữ liệu đào tạo nhưng không được cung cấp) phải được chỉ định thông qua trường môi trường trong lược đồ.
Tính năng Skew
Sự lệch đối tượng xảy ra khi các giá trị đối tượng mà một mô hình đào tạo khác với các giá trị đối tượng mà nó nhìn thấy tại thời điểm cung cấp. Ví dụ: điều này có thể xảy ra khi:
- Nguồn dữ liệu cung cấp một số giá trị tính năng được sửa đổi giữa thời gian đào tạo và phục vụ
- Có logic khác nhau để tạo ra các tính năng giữa đào tạo và phục vụ. Ví dụ: nếu bạn chỉ áp dụng một số chuyển đổi trong một trong hai đường dẫn mã.
Phân phối Skew
Sự lệch phân phối xảy ra khi phân phối của tập dữ liệu đào tạo khác biệt đáng kể với phân phối của tập dữ liệu phục vụ. Một trong những nguyên nhân chính gây ra lệch phân phối là sử dụng mã khác nhau hoặc các nguồn dữ liệu khác nhau để tạo tập dữ liệu đào tạo. Một lý do khác là cơ chế lấy mẫu bị lỗi chọn một mẫu con không đại diện của dữ liệu phục vụ để đào tạo.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
Trong ví dụ này, chúng tôi thấy có một số sai lệch, nhưng nó thấp hơn nhiều so với ngưỡng mà chúng tôi đã đặt.
Cố định lược đồ
Bây giờ, lược đồ đã được xem xét và sắp xếp, chúng tôi sẽ lưu trữ nó trong một tệp để phản ánh trạng thái "đóng băng" của nó.
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Khi nào sử dụng TFDV
Thật dễ dàng để nghĩ về TFDV chỉ áp dụng cho phần bắt đầu của quá trình đào tạo của bạn, như chúng tôi đã làm ở đây, nhưng trên thực tế, nó có rất nhiều công dụng. Đây là một số khác:
- Xác thực dữ liệu mới để suy luận để đảm bảo rằng chúng tôi không đột nhiên bắt đầu nhận được các tính năng xấu
- Xác thực dữ liệu mới để suy luận để đảm bảo rằng mô hình của chúng tôi đã được đào tạo trên phần đó của bề mặt quyết định
- Xác thực dữ liệu của chúng tôi sau khi chúng tôi đã chuyển đổi nó và thực hiện kỹ thuật tính năng (có thể sử dụng TensorFlow Transform ) để đảm bảo rằng chúng tôi không làm sai điều gì đó