
ตัวอย่างส่วนประกอบหลักของ TensorFlow Extended
 ดูแหล่งที่มาบน GitHub
ดูแหล่งที่มาบน GitHubตัวอย่างสมุดบันทึก colab นี้แสดงให้เห็นว่าสามารถใช้ TensorFlow Data Validation (TFDV) เพื่อตรวจสอบและแสดงภาพชุดข้อมูลของคุณได้อย่างไร ซึ่งรวมถึงการดูสถิติเชิงพรรณนา การอนุมานสคีมา การตรวจสอบและแก้ไขความผิดปกติ และการตรวจสอบการเบี่ยงเบนและความเบ้ในชุดข้อมูลของเรา สิ่งสำคัญคือต้องเข้าใจลักษณะของชุดข้อมูลของคุณ ซึ่งรวมถึงการเปลี่ยนแปลงเมื่อเวลาผ่านไปในไปป์ไลน์การผลิตของคุณ นอกจากนี้ คุณควรมองหาความผิดปกติในข้อมูลของคุณ และเปรียบเทียบชุดข้อมูลการฝึกอบรม การประเมิน และการให้บริการเพื่อให้แน่ใจว่ามีความสอดคล้องกัน
เราจะใช้ข้อมูลจาก ชุดข้อมูล Taxi Trips ที่ออกโดยเมืองชิคาโก
อ่านเพิ่มเติม เกี่ยวกับชุดข้อมูลใน Google BigQuery สำรวจชุดข้อมูลทั้งหมดใน BigQuery UI
คอลัมน์ในชุดข้อมูลคือ:
| รถปิคอัพ_ชุมชน_พื้นที่ | ค่าโดยสาร | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| รถปิคอัพ_ละติจูด | รถกระบะ_ลองจิจูด | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_census_tract |
| dropoff_census_tract | ประเภทการชำระเงิน | บริษัท |
| trip_seconds | dropoff_community_area | เคล็ดลับ |
ติดตั้งและนำเข้าแพ็คเกจ
ติดตั้งแพ็คเกจสำหรับการตรวจสอบความถูกต้องของข้อมูล TensorFlow
อัพเกรด Pip
เพื่อหลีกเลี่ยงการอัพเกรด Pip ในระบบเมื่อรันในเครื่อง ให้ตรวจสอบว่าเรากำลังทำงานใน Colab แน่นอนว่าระบบในพื้นที่สามารถอัพเกรดแยกกันได้
try:
import colab
!pip install --upgrade pip
except:
pass
ติดตั้งแพ็คเกจตรวจสอบข้อมูล
ติดตั้งแพ็คเกจ TensorFlow Data Validation และการอ้างอิง ซึ่งใช้เวลาสองสามนาที คุณอาจเห็นคำเตือนและข้อผิดพลาดเกี่ยวกับเวอร์ชันการขึ้นต่อกันที่เข้ากันไม่ได้ ซึ่งคุณจะแก้ไขในส่วนถัดไป
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
นำเข้า TensorFlow และโหลดแพ็คเกจที่อัปเดตใหม่
ขั้นตอนก่อนหน้าจะอัปเดตแพ็คเกจเริ่มต้นในสภาพแวดล้อม Gooogle Colab ดังนั้นคุณต้องโหลดทรัพยากรของแพ็คเกจซ้ำเพื่อแก้ไขการขึ้นต่อกันใหม่
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
ตรวจสอบเวอร์ชันของ TensorFlow และ Data Validation ก่อนดำเนินการต่อ
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
โหลดชุดข้อมูล
เราจะดาวน์โหลดชุดข้อมูลของเราจาก Google Cloud Storage
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
คำนวณและแสดงภาพสถิติ
อันดับแรก เราจะใช้ tfdv.generate_statistics_from_csv เพื่อคำนวณสถิติสำหรับข้อมูลการฝึกของเรา (ละเว้นคำเตือนเร็ว)
TFDV สามารถคำนวณ สถิติเชิง พรรณนาที่ให้ภาพรวมโดยย่อของข้อมูลในแง่ของคุณลักษณะที่มีอยู่และรูปร่างของการกระจายมูลค่า
ภายใน TFDV ใช้เฟรมเวิร์กการประมวลผลข้อมูลแบบคู่ขนานของ Apache Beam เพื่อปรับขนาดการคำนวณสถิติบนชุดข้อมูลขนาดใหญ่ สำหรับแอปพลิเคชันที่ต้องการผสานรวมกับ TFDV อย่างลึกซึ้งยิ่งขึ้น (เช่น แนบการสร้างสถิติที่ส่วนท้ายของไปป์ไลน์การสร้างข้อมูล) API ยังเปิดเผย Beam PTransform สำหรับการสร้างสถิติอีกด้วย
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
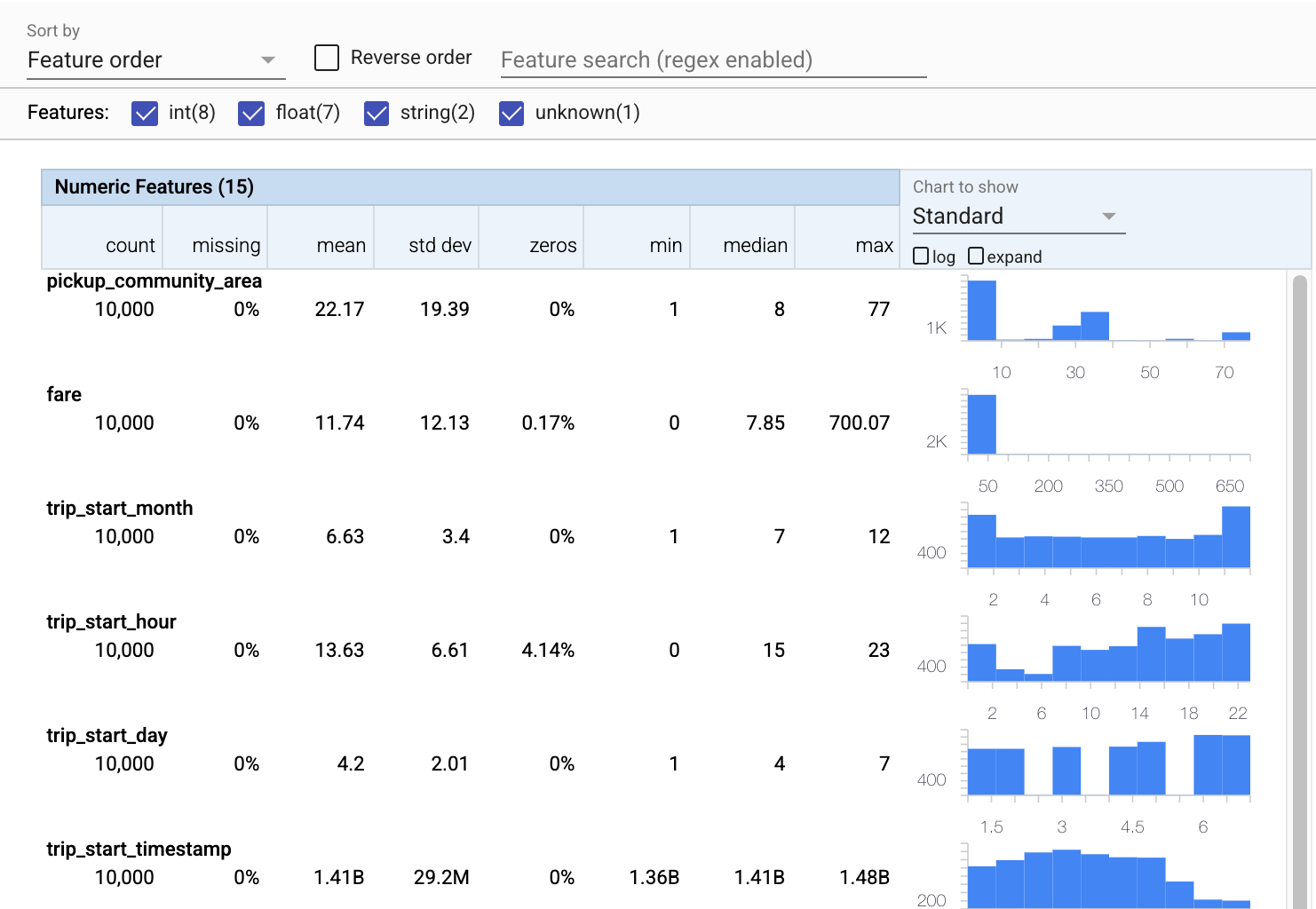
ตอนนี้ ลองใช้ tfdv.visualize_statistics ซึ่งใช้ Facets เพื่อสร้างภาพข้อมูลการฝึกของเราอย่างกระชับ:
- โปรดสังเกตว่าคุณลักษณะตัวเลขและคุณลักษณะตามหมวดหมู่มีการแสดงภาพแยกกัน และแผนภูมิจะแสดงขึ้นเพื่อแสดงการแจกแจงสำหรับแต่ละคุณลักษณะ
- โปรดสังเกตว่าคุณลักษณะที่มีค่าขาดหายไปหรือเป็นศูนย์จะแสดงเปอร์เซ็นต์เป็นสีแดงเป็นตัวบ่งชี้ที่มองเห็นได้ว่าอาจมีปัญหากับตัวอย่างในคุณลักษณะเหล่านั้น เปอร์เซ็นต์คือเปอร์เซ็นต์ของตัวอย่างที่มีค่าขาดหายไปหรือเป็นศูนย์สำหรับคุณลักษณะนั้น
- โปรดสังเกตว่าไม่มีตัวอย่างที่มีค่าสำหรับ
pickup_census_tractนี่คือโอกาสในการลดมิติ! - ลองคลิก "ขยาย" เหนือแผนภูมิเพื่อเปลี่ยนการแสดงผล
- ลองวางเมาส์เหนือแท่งในแผนภูมิเพื่อแสดงช่วงถังและการนับ
- ลองสลับไปมาระหว่างมาตราส่วนบันทึกและมาตราส่วนเชิงเส้น และสังเกตว่ามาตราส่วนบันทึกแสดงรายละเอียดเพิ่มเติมเกี่ยวกับคุณลักษณะการจัดหมวดหมู่ของ
payment_typeได้อย่างไร - ลองเลือก "ปริมาณ" จากเมนู "แผนภูมิที่จะแสดง" แล้ววางเมาส์เหนือเครื่องหมายเพื่อแสดงเปอร์เซ็นต์ของปริมาณ
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
อนุมานสคีมา
ตอนนี้ ลองใช้ tfdv.infer_schema เพื่อสร้างสคีมาสำหรับข้อมูลของเรา สคีมากำหนดข้อจำกัดสำหรับข้อมูลที่เกี่ยวข้องกับ ML ตัวอย่างข้อจำกัดรวมถึงชนิดข้อมูลของคุณลักษณะแต่ละอย่าง ไม่ว่าจะเป็นตัวเลขหรือหมวดหมู่ หรือความถี่ของการมีอยู่ของมันในข้อมูล สำหรับคุณสมบัติการจัดหมวดหมู่ สคีมายังกำหนดโดเมน - รายการค่าที่ยอมรับได้ เนื่องจากการเขียนสคีมาอาจเป็นงานที่น่าเบื่อ โดยเฉพาะสำหรับชุดข้อมูลที่มีคุณสมบัติมากมาย TFDV จึงมีวิธีการสร้างเวอร์ชันเริ่มต้นของสคีมาตามสถิติเชิงพรรณนา
การทำให้สคีมาถูกต้องเป็นสิ่งสำคัญ เนื่องจากไพพ์ไลน์การผลิตที่เหลือของเราจะขึ้นอยู่กับสคีมาที่ TFDV สร้างขึ้นเพื่อให้ถูกต้อง สคีมายังมีเอกสารประกอบสำหรับข้อมูล และดังนั้นจึงมีประโยชน์เมื่อนักพัฒนาที่แตกต่างกันทำงานบนข้อมูลเดียวกัน ลองใช้ tfdv.display_schema เพื่อแสดง schema ที่อนุมาน เพื่อให้เราสามารถตรวจทานได้
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
ตรวจสอบข้อมูลการประเมินเพื่อหาข้อผิดพลาด
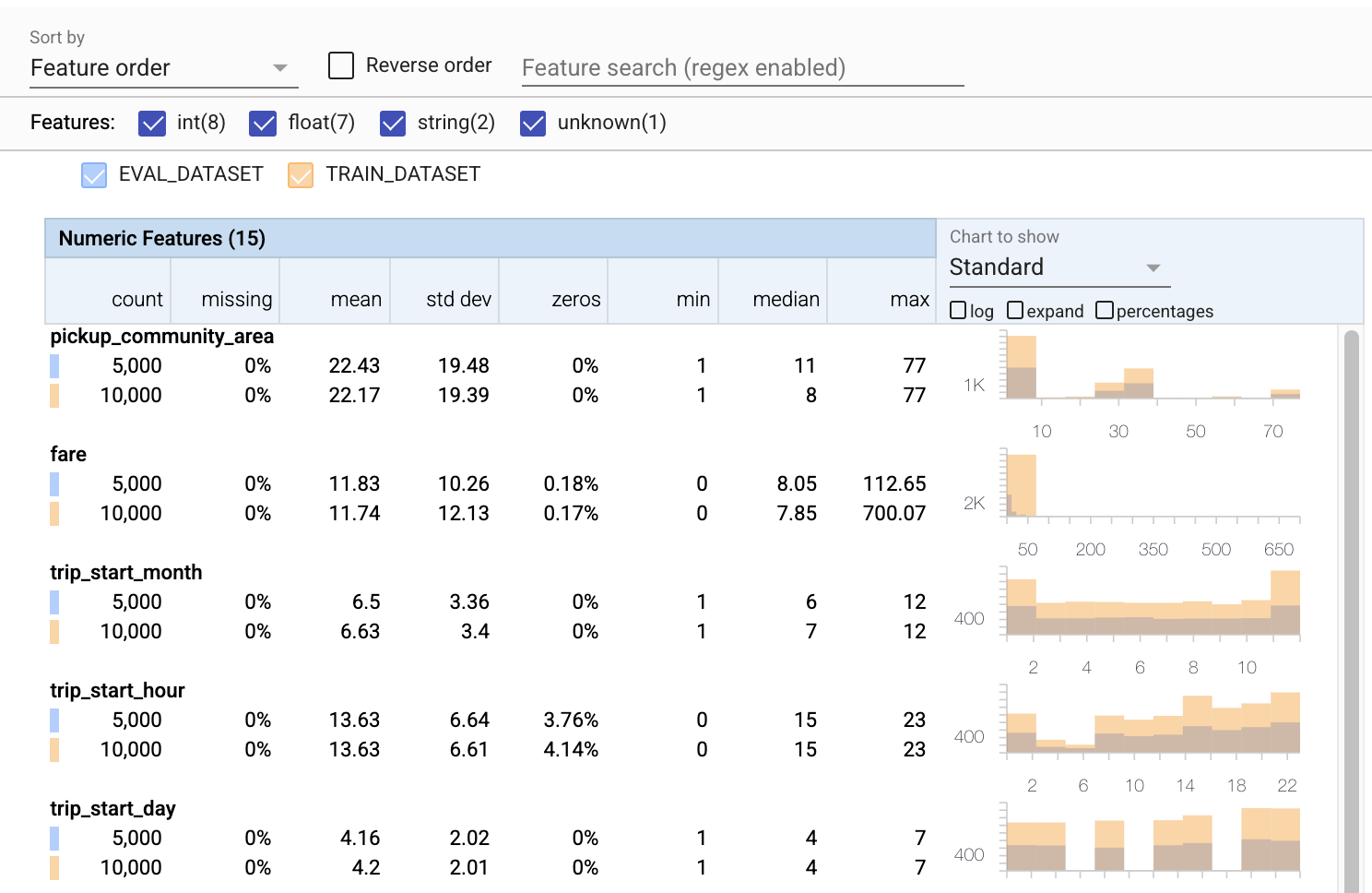
จนถึงตอนนี้เราเพิ่งดูข้อมูลการฝึกเท่านั้น ข้อมูลการประเมินของเราจะต้องสอดคล้องกับข้อมูลการฝึกอบรมของเรา ซึ่งรวมถึงข้อมูลที่ใช้สคีมาเดียวกันเป็นสิ่งสำคัญ ข้อมูลการประเมินจะต้องรวมตัวอย่างของช่วงค่าเดียวกันโดยประมาณสำหรับคุณลักษณะเชิงตัวเลขของเราเป็นข้อมูลการฝึกอบรม เพื่อให้ความครอบคลุมของพื้นผิวการสูญเสียระหว่างการประเมินจะเหมือนกับในระหว่างการฝึกอบรม เช่นเดียวกับคุณสมบัติหมวดหมู่ มิฉะนั้น เราอาจมีปัญหาด้านการฝึกอบรมที่ไม่ได้ระบุในระหว่างการประเมิน เนื่องจากเราไม่ได้ประเมินส่วนหนึ่งของการสูญเสียของเรา
- โปรดสังเกตว่าตอนนี้แต่ละฟีเจอร์มีสถิติสำหรับทั้งชุดข้อมูลการฝึกอบรมและการประเมิน
- โปรดสังเกตว่าตอนนี้แผนภูมิมีทั้งชุดข้อมูลการฝึกอบรมและการประเมินซ้อนทับ ทำให้ง่ายต่อการเปรียบเทียบ
- โปรดสังเกตว่าตอนนี้แผนภูมิมีมุมมองแบบเปอร์เซ็นต์ ซึ่งสามารถใช้ร่วมกับบันทึกหรือมาตราส่วนเชิงเส้นที่เป็นค่าเริ่มต้นได้
- โปรดสังเกตว่าค่าเฉลี่ยและค่ามัธยฐานสำหรับ
trip_milesสำหรับการฝึกอบรมเทียบกับชุดข้อมูลการประเมินต่างกัน จะทำให้เกิดปัญหาหรือไม่? - ว้าว
tipsสูงสุดสำหรับการฝึกอบรมกับชุดข้อมูลการประเมินแตกต่างกันมาก จะทำให้เกิดปัญหาหรือไม่? - คลิกขยายบนแผนภูมิคุณสมบัติตัวเลข และเลือกมาตราส่วนบันทึก ตรวจสอบคุณสมบัติ
trip_secondsและสังเกตเห็นความแตกต่างในค่าสูงสุด การประเมินจะพลาดชิ้นส่วนของพื้นผิวที่สูญเสียหรือไม่?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
ตรวจสอบความผิดปกติของการประเมิน
ชุดข้อมูลการประเมินของเราตรงกับสคีมาจากชุดข้อมูลการฝึกอบรมหรือไม่ นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับคุณสมบัติการจัดหมวดหมู่ ซึ่งเราต้องการระบุช่วงของค่าที่ยอมรับได้
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
แก้ไขความผิดปกติของการประเมินในสคีมา
อ๊ะ! ดูเหมือนว่าเรามีค่านิยมใหม่ๆ สำหรับ company ในข้อมูลการประเมิน ซึ่งเราไม่มีในข้อมูลการฝึกอบรม เรายังมีค่าใหม่สำหรับ payment_type สิ่งเหล่านี้ควรถือเป็นความผิดปกติ แต่สิ่งที่เราตัดสินใจทำกับสิ่งเหล่านี้ขึ้นอยู่กับความรู้ในโดเมนของเรา หากความผิดปกติบ่งชี้ถึงข้อผิดพลาดของข้อมูลจริงๆ ข้อมูลพื้นฐานควรได้รับการแก้ไข มิฉะนั้น เราสามารถอัปเดตสคีมาเพื่อรวมค่าในชุดข้อมูล eval ได้ง่ายๆ
เว้นแต่เราจะเปลี่ยนชุดข้อมูลการประเมิน เราไม่สามารถแก้ไขทุกอย่างได้ แต่เราสามารถแก้ไขสิ่งต่างๆ ในสคีมาที่เรายินดีรับได้ ซึ่งรวมถึงการผ่อนคลายมุมมองของเราเกี่ยวกับสิ่งที่เป็นและสิ่งที่ไม่ผิดปกติสำหรับคุณลักษณะเฉพาะ ตลอดจนการอัปเดตสคีมาของเราเพื่อรวมค่าที่ขาดหายไปสำหรับคุณลักษณะตามหมวดหมู่ TFDV ช่วยให้เราค้นพบสิ่งที่เราต้องแก้ไข
มาทำการแก้ไขเหล่านี้กัน แล้วทบทวนอีกครั้ง
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
เฮ้ ดูนั่นสิ! เราตรวจสอบแล้วว่าข้อมูลการฝึกอบรมและการประเมินมีความสอดคล้องกันในขณะนี้! ขอบคุณ TFDV ;)
สภาพแวดล้อมสคีมา
นอกจากนี้เรายังแยกชุดข้อมูล 'การให้บริการ' สำหรับตัวอย่างนี้ ดังนั้นเราควรตรวจสอบด้วย ตามค่าเริ่มต้น ชุดข้อมูลทั้งหมดในไปป์ไลน์ควรใช้สคีมาเดียวกัน แต่มักจะมีข้อยกเว้น ตัวอย่างเช่น ในการเรียนรู้ภายใต้การดูแล เราจำเป็นต้องรวมป้ายกำกับในชุดข้อมูลของเรา แต่เมื่อเราให้บริการแบบจำลองสำหรับการอนุมาน ป้ายกำกับจะไม่รวมอยู่ด้วย ในบางกรณีจำเป็นต้องมีการแนะนำรูปแบบสคีมาเล็กน้อย
สภาพแวดล้อม สามารถใช้เพื่อแสดงข้อกำหนดดังกล่าวได้ โดยเฉพาะอย่างยิ่ง คุณลักษณะในสคีมาสามารถเชื่อมโยงกับชุดของสภาพแวดล้อมได้โดยใช้ default_environment , in_environment และ not_in_environment
ตัวอย่างเช่น ในชุดข้อมูลนี้ คุณลักษณะ tips จะรวมเป็นป้ายกำกับสำหรับการฝึกอบรม แต่ไม่มีข้อมูลการให้บริการ หากไม่มีการระบุสภาพแวดล้อม ระบบจะแสดงขึ้นเป็นความผิดปกติ
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
เราจะจัดการกับคุณลักษณะ tips ด้านล่าง นอกจากนี้เรายังมีค่า INT ในวินาทีการเดินทางของเรา โดยที่สคีมาของเราคาดว่าจะ FLOAT การทำให้เราตระหนักถึงความแตกต่างนั้น TFDV ช่วยเปิดเผยความไม่สอดคล้องกันในวิธีการสร้างข้อมูลสำหรับการฝึกอบรมและการให้บริการ เป็นเรื่องง่ายมากที่จะไม่ทราบถึงปัญหาเช่นนั้น จนกว่าประสิทธิภาพของโมเดลจะได้รับผลกระทบ และบางครั้งก็เกิดความหายนะ อาจเป็นปัญหาสำคัญหรือไม่ก็ได้ แต่ในกรณีใดก็ตาม เรื่องนี้ควรเป็นสาเหตุให้มีการตรวจสอบเพิ่มเติม
ในกรณีนี้ เราสามารถแปลงค่า INT เป็น FLOAT ได้อย่างปลอดภัย ดังนั้นเราจึงต้องการบอกให้ TFDV ใช้สคีมาของเราในการอนุมานประเภท มาทำกันตอนนี้เลย
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
ตอนนี้เราเพิ่งมีคุณลักษณะ tips (ซึ่งเป็นป้ายกำกับของเรา) แสดงเป็นความผิดปกติ ('คอลัมน์หลุด') แน่นอน เราไม่ได้คาดหวังว่าจะมีป้ายกำกับในข้อมูลการให้บริการ ดังนั้นขอให้ TFDV เพิกเฉยต่อสิ่งนั้น
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
ตรวจสอบการดริฟท์และเอียง
นอกเหนือจากการตรวจสอบว่าชุดข้อมูลเป็นไปตามความคาดหวังที่กำหนดไว้ในสคีมาหรือไม่ TFDV ยังมีฟังก์ชันสำหรับตรวจจับการเลื่อนและการเอียง TFDV ดำเนินการตรวจสอบนี้โดยการเปรียบเทียบสถิติของชุดข้อมูลต่างๆ ตามตัวเปรียบเทียบการเลื่อน/เอียงที่ระบุในสคีมา
ดริฟท์
การตรวจจับการดริฟท์ได้รับการสนับสนุนสำหรับคุณสมบัติตามหมวดหมู่และระหว่างช่วงข้อมูลที่ต่อเนื่องกัน (เช่น ระหว่างช่วง N และช่วง N+1) เช่น ระหว่างวันที่ข้อมูลการฝึกต่างกัน เราแสดงการดริฟท์ในแง่ของ ระยะทาง L-อินฟินิตี้ และคุณสามารถตั้งค่าระยะห่างเกณฑ์เพื่อให้คุณได้รับคำเตือนเมื่อดริฟท์สูงกว่าที่ยอมรับได้ การกำหนดระยะทางที่ถูกต้องมักจะเป็นกระบวนการที่ต้องทำซ้ำซึ่งต้องใช้ความรู้และการทดลองในโดเมน
ลาด
TFDV สามารถตรวจจับความเบ้ที่แตกต่างกันสามแบบในข้อมูลของคุณ - สคีมาเบ้ คุณสมบัติเบ้ และการกระจายแบบเบ้
สคีมา Skew
สคีมาเอียงเกิดขึ้นเมื่อข้อมูลการฝึกอบรมและการให้บริการไม่สอดคล้องกับสคีมาเดียวกัน ข้อมูลการฝึกอบรมและการให้บริการคาดว่าจะเป็นไปตามสคีมาเดียวกัน ควรระบุความเบี่ยงเบนที่คาดหวังระหว่างทั้งสอง (เช่น คุณลักษณะป้ายกำกับที่มีอยู่ในข้อมูลการฝึกอบรมเท่านั้น แต่ไม่อยู่ในการให้บริการ) ผ่านฟิลด์สภาพแวดล้อมในสคีมา
ฟีเจอร์ Skew
ความเอียงของคุณลักษณะเกิดขึ้นเมื่อค่าคุณลักษณะที่โมเดลฝึกใช้แตกต่างจากค่าคุณลักษณะที่เห็นในเวลาที่ให้บริการ ตัวอย่างเช่น สิ่งนี้สามารถเกิดขึ้นได้เมื่อ:
- แหล่งข้อมูลที่มีค่าคุณลักษณะบางอย่างจะได้รับการแก้ไขระหว่างการฝึกอบรมและเวลาให้บริการ
- มีตรรกะที่แตกต่างกันสำหรับการสร้างคุณลักษณะระหว่างการฝึกอบรมและการให้บริการ ตัวอย่างเช่น หากคุณใช้การแปลงบางอย่างในหนึ่งในสองเส้นทางของโค้ด
การกระจายตัวเอียง
ความเบ้ในการกระจายเกิดขึ้นเมื่อการกระจายชุดข้อมูลการฝึกแตกต่างอย่างมากจากการกระจายชุดข้อมูลที่ให้บริการ สาเหตุสำคัญประการหนึ่งสำหรับการกระจายความเอียงคือการใช้รหัสหรือแหล่งข้อมูลที่แตกต่างกันเพื่อสร้างชุดข้อมูลการฝึกอบรม อีกเหตุผลหนึ่งคือกลไกการสุ่มตัวอย่างที่ผิดพลาดซึ่งเลือกตัวอย่างย่อยที่ไม่ใช่ตัวแทนของข้อมูลที่ให้บริการเพื่อฝึก
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
ในตัวอย่างนี้ เราเห็นการดริฟท์บางส่วน แต่อยู่ต่ำกว่าเกณฑ์ที่เรากำหนดไว้
ตรึงสคีมา
ตอนนี้ schema ได้รับการตรวจสอบและดูแล เราจะจัดเก็บไว้ในไฟล์เพื่อแสดงสถานะ "หยุดนิ่ง"
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
เมื่อใดควรใช้ TFDV
ง่ายที่จะคิดว่า TFDV มีผลกับช่วงเริ่มต้นของไปป์ไลน์การฝึกเท่านั้น เช่นเดียวกับที่เราทำที่นี่ แต่จริงๆ แล้วมีประโยชน์หลายอย่าง นี่คืออีกสองสาม:
- ตรวจสอบข้อมูลใหม่สำหรับการอนุมานเพื่อให้แน่ใจว่าเราไม่ได้เริ่มได้รับคุณสมบัติที่ไม่ดีอย่างกะทันหัน
- การตรวจสอบความถูกต้องของข้อมูลใหม่สำหรับการอนุมานเพื่อให้แน่ใจว่าแบบจำลองของเราได้รับการฝึกอบรมในส่วนนั้นของพื้นผิวการตัดสินใจ
- ตรวจสอบข้อมูลของเราหลังจากที่เราแปลงและทำวิศวกรรมคุณลักษณะ (อาจใช้ TensorFlow Transform ) เพื่อให้แน่ใจว่าเราไม่ได้ทำอะไรผิด