
نمونه ای از مولفه کلیدی TensorFlow Extended
 مشاهده منبع در GitHub
مشاهده منبع در GitHubاین نمونه نوت بوک colab نشان می دهد که چگونه می توان از اعتبارسنجی داده های TensorFlow (TFDV) برای بررسی و تجسم مجموعه داده شما استفاده کرد. این شامل بررسی آمار توصیفی، استنتاج یک طرحواره، بررسی و رفع ناهنجاریها، و بررسی انحراف و انحراف در مجموعه داده ما است. درک ویژگی های مجموعه داده شما، از جمله اینکه چگونه ممکن است در طول زمان در خط لوله تولید شما تغییر کند، مهم است. همچنین مهم است که به دنبال ناهنجاریها در دادههای خود باشید و آموزش، ارزیابی و ارائه مجموعههای داده را با هم مقایسه کنید تا مطمئن شوید که آنها سازگار هستند.
ما از داده های مجموعه داده سفرهای تاکسی منتشر شده توسط شهر شیکاگو استفاده خواهیم کرد.
درباره مجموعه داده در Google BigQuery بیشتر بخوانید . مجموعه داده کامل را در رابط کاربری BigQuery کاوش کنید.
ستون های مجموعه داده عبارتند از:
| pickup_community_area | کرایه | سفر_شروع_ماه |
| سفر_شروع_ساعت | سفر_شروع_روز | trip_start_timestamp |
| pickup_latitude | طول_وصول | dropoff_latitude |
| افت_طول جغرافیایی | trip_miles | پیکاپ_سرشماری_تراکت |
| dropoff_sensus_tract | نوع پرداخت | شرکت |
| سفر_ثانیه | dropoff_community_area | نکات |
بسته ها را نصب و وارد کنید
بسته های مربوط به اعتبارسنجی داده های TensorFlow را نصب کنید.
پیپ را ارتقا دهید
برای جلوگیری از ارتقاء Pip در سیستم هنگام اجرای محلی، بررسی کنید که در Colab در حال اجرا هستیم. البته سیستم های محلی را می توان به طور جداگانه ارتقا داد.
try:
import colab
!pip install --upgrade pip
except:
pass
بسته های Data Validation را نصب کنید
بسته ها و وابستگی های TensorFlow Data Validation را نصب کنید که چند دقیقه طول می کشد. ممکن است هشدارها و خطاهایی در رابطه با نسخههای وابستگی ناسازگار مشاهده کنید که در بخش بعدی آنها را برطرف خواهید کرد.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
TensorFlow را وارد کنید و بسته های به روز شده را دوباره بارگیری کنید
مرحله قبل بستههای پیشفرض را در محیط Gooogle Colab بهروزرسانی میکند، بنابراین باید منابع بسته را دوباره بارگیری کنید تا وابستگیهای جدید را برطرف کنید.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
قبل از ادامه، نسخههای TensorFlow و اعتبارسنجی دادهها را بررسی کنید.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
مجموعه داده را بارگیری کنید
ما مجموعه داده خود را از Google Cloud Storage دانلود خواهیم کرد.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
آمار را محاسبه و تجسم کنید
ابتدا از tfdv.generate_statistics_from_csv برای محاسبه آمار برای داده های آموزشی خود استفاده می کنیم. (به هشدارهای فوری توجه نکنید)
TFDV میتواند آمار توصیفی را محاسبه کند که یک نمای کلی سریع از دادهها از نظر ویژگیهای موجود و شکلهای توزیع ارزش آنها ارائه میکند.
در داخل، TFDV از چارچوب پردازش موازی داده Apache Beam برای مقیاسبندی محاسبه آمار بر روی مجموعههای داده بزرگ استفاده میکند. برای برنامههایی که میخواهند عمیقتر با TFDV ادغام شوند (به عنوان مثال، تولید آمار را در انتهای خط لوله تولید داده پیوست کنید)، API همچنین یک Beam PTtransform را برای تولید آمار نشان میدهد.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
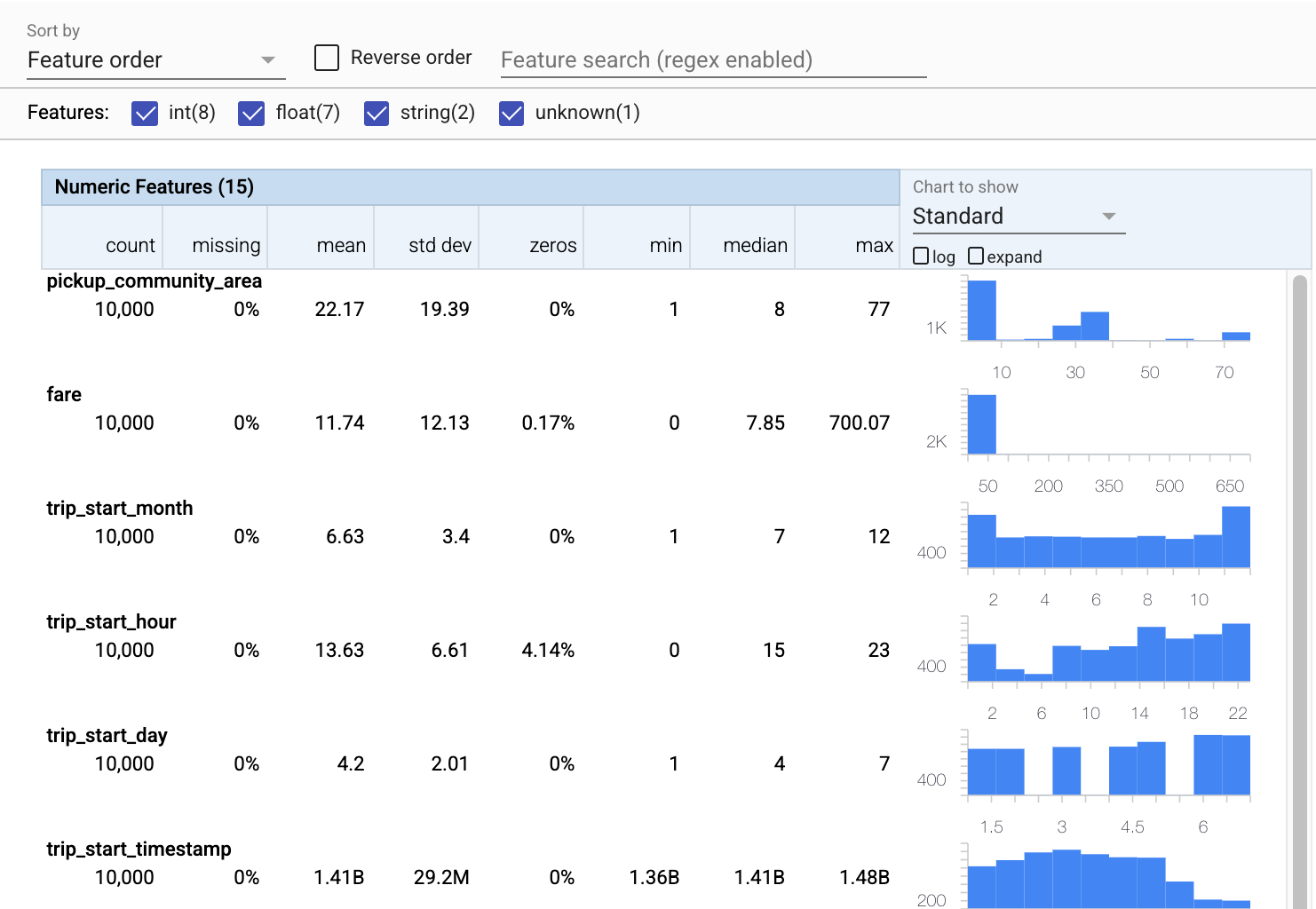
حالا بیایید از tfdv.visualize_statistics استفاده کنیم که از Facets برای ایجاد تصویری مختصر از داده های آموزشی ما استفاده می کند:
- توجه داشته باشید که ویژگیهای عددی و ویژگیهای دستهبندی به طور جداگانه به تصویر کشیده میشوند و نمودارهایی نمایش داده میشوند که توزیعهای هر ویژگی را نشان میدهند.
- توجه داشته باشید که ویژگیهایی که مقادیر از دست رفته یا صفر دارند، درصدی را به رنگ قرمز به عنوان یک نشانگر بصری نشان میدهند که ممکن است مشکلاتی در نمونههایی در آن ویژگیها وجود داشته باشد. درصد، درصد نمونههایی است که مقادیر گمشده یا صفر آن ویژگی را دارند.
- توجه داشته باشید که هیچ نمونه ای با مقادیر برای
pickup_census_tractوجود ندارد. این فرصتی برای کاهش ابعاد است! - برای تغییر صفحه نمایش، روی «گسترش» در بالای نمودارها کلیک کنید
- سعی کنید ماوس را روی میلهها در نمودارها نگه دارید تا محدوده و تعداد سطل نمایش داده شود
- سعی کنید بین مقیاس گزارش و مقیاس خطی
payment_typeشوید و توجه کنید که چگونه مقیاس گزارش جزئیات بسیار بیشتری را در مورد ویژگی طبقه بندی نوع پرداخت نشان می دهد. - سعی کنید از منوی "Chart to show" "quantiles" را انتخاب کنید و روی نشانگرها نگه دارید تا درصدهای کمی را نشان دهید.
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
استنباط طرحواره
حالا بیایید از tfdv.infer_schema برای ایجاد یک طرح برای داده های خود استفاده کنیم. یک طرح واره، محدودیت هایی را برای داده های مرتبط با ML تعریف می کند. محدودیتهای مثال شامل نوع داده هر ویژگی، عددی یا مقولهای بودن یا فراوانی حضور آن در دادهها است. برای ویژگی های طبقه بندی، طرح واره همچنین دامنه را تعریف می کند - لیست مقادیر قابل قبول. از آنجایی که نوشتن یک طرحواره می تواند یک کار خسته کننده باشد، به ویژه برای مجموعه داده هایی با ویژگی های زیاد، TFDV روشی را برای تولید نسخه اولیه طرحواره بر اساس آمار توصیفی ارائه می دهد.
درست کردن طرحواره مهم است زیرا بقیه خط لوله تولید ما بر روی طرحواره ای که TFDV ایجاد می کند تکیه می کند تا درست باشد. این طرح همچنین اسنادی را برای داده ها فراهم می کند، و بنابراین زمانی مفید است که توسعه دهندگان مختلف روی داده های مشابه کار می کنند. بیایید از tfdv.display_schema برای نمایش طرح استنباط شده استفاده کنیم تا بتوانیم آن را بررسی کنیم.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
داده های ارزیابی را برای خطاها بررسی کنید
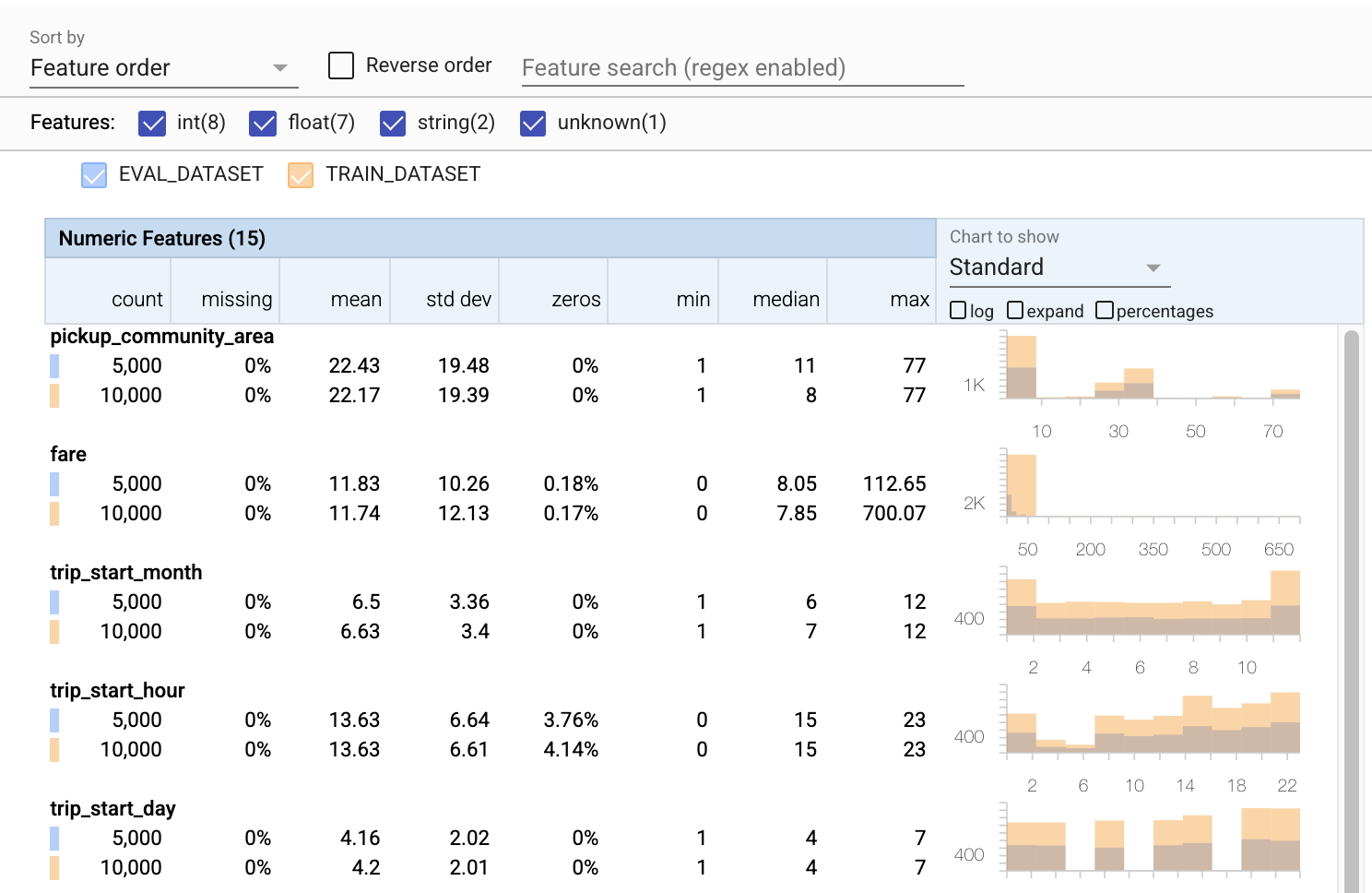
تا کنون ما فقط به داده های آموزشی نگاه کرده ایم. مهم است که دادههای ارزیابی ما با دادههای آموزشی ما مطابقت داشته باشد، از جمله اینکه از همان طرح واره استفاده میکند. همچنین مهم است که دادههای ارزیابی شامل نمونههایی از محدودههای تقریباً یکسانی از مقادیر برای ویژگیهای عددی ما با دادههای آموزشی ما باشد، به طوری که پوشش سطح ضرر در طول ارزیابی تقریباً مشابه هنگام آموزش باشد. همین امر در مورد ویژگی های طبقه بندی نیز صادق است. در غیر این صورت، ممکن است مسائل آموزشی داشته باشیم که در هنگام ارزیابی مشخص نشود، زیرا بخشی از سطح ضرر خود را ارزیابی نکرده ایم.
- توجه داشته باشید که اکنون هر ویژگی شامل آماری برای مجموعه داده های آموزشی و ارزیابی است.
- توجه داشته باشید که نمودارها اکنون دارای هر دو مجموعه داده آموزشی و ارزیابی هستند که مقایسه آنها را آسان می کند.
- توجه داشته باشید که نمودارها اکنون شامل نمای درصدی هستند که میتواند با log یا مقیاسهای خطی پیشفرض ترکیب شود.
- توجه داشته باشید که میانگین و میانه برای
trip_milesبرای آموزش در مقابل مجموعه داده های ارزیابی متفاوت است. آیا این مشکل ایجاد خواهد کرد؟ - وای، حداکثر
tipsبرای آموزش در مقابل مجموعه داده های ارزیابی بسیار متفاوت است. آیا این مشکل ایجاد خواهد کرد؟ - روی گسترش نمودار ویژگی های عددی کلیک کنید و مقیاس گزارش را انتخاب کنید. ویژگی
trip_secondsرا مرور کنید و تفاوت را در حداکثر مشاهده کنید. آیا ارزیابی بخش هایی از سطح ضرر را از دست می دهد؟
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
ناهنجاری های ارزیابی را بررسی کنید
آیا مجموعه داده ارزیابی ما با طرح مجموعه داده آموزشی ما مطابقت دارد؟ این به ویژه برای ویژگیهای طبقهبندی مهم است، جایی که میخواهیم محدوده مقادیر قابل قبول را شناسایی کنیم.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
رفع ناهنجاری های ارزیابی در طرحواره
اوه! به نظر می رسد در داده های ارزیابی خود مقادیر جدیدی برای company داریم که در داده های آموزشی خود نداشتیم. ما همچنین یک مقدار جدید برای payment_type . اینها باید به عنوان ناهنجاری در نظر گرفته شوند، اما تصمیم ما برای انجام دادن آنها به دانش دامنه ما از داده ها بستگی دارد. اگر یک ناهنجاری واقعاً نشان دهنده یک خطای داده باشد، داده های اساسی باید اصلاح شوند. در غیر این صورت، می توانیم به سادگی طرحواره را به روز کنیم تا مقادیر را در مجموعه داده eval قرار دهیم.
تا زمانی که مجموعه داده ارزیابی خود را تغییر ندهیم، نمیتوانیم همه چیز را اصلاح کنیم، اما میتوانیم مواردی را در طرحواره اصلاح کنیم که راحت قبول کنیم. این شامل آرام کردن دیدگاه ما در مورد اینکه چه چیزی برای ویژگیهای خاص یک ناهنجاری است و چه چیزی نیست، و همچنین بهروزرسانی طرح ما برای گنجاندن مقادیر گمشده برای ویژگیهای طبقهبندی میشود. TFDV ما را قادر می سازد تا آنچه را که باید اصلاح کنیم کشف کنیم.
بیایید اکنون آن اصلاحات را انجام دهیم و سپس یک بار دیگر مرور کنیم.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
هی، به آن نگاه کن! ما تأیید کردیم که دادههای آموزش و ارزیابی اکنون سازگار هستند! با تشکر TFDV ;)
محیط های طرحواره
ما همچنین یک مجموعه داده "سرویس" را برای این مثال جدا کردیم، بنابراین باید آن را نیز بررسی کنیم. بهطور پیشفرض، همه مجموعههای داده در خط لوله باید از یک طرح استفاده کنند، اما اغلب استثنائاتی وجود دارد. به عنوان مثال، در یادگیری نظارت شده، ما نیاز داریم که برچسبها را در مجموعه داده خود بگنجانیم، اما زمانی که مدل را برای استنتاج ارائه میکنیم، برچسبها گنجانده نمیشوند. در برخی موارد، ارائه تغییرات جزئی طرحواره ضروری است.
برای بیان چنین الزاماتی می توان از محیط ها استفاده کرد. به طور خاص، ویژگیهای موجود در طرحواره را میتوان با مجموعهای از محیطها با استفاده از default_environment ، in_environment و not_in_environment کرد.
به عنوان مثال، در این مجموعه داده، ویژگی tips به عنوان برچسب آموزش گنجانده شده است، اما در داده های ارائه شده وجود ندارد. بدون محیط مشخص شده، به عنوان یک ناهنجاری نشان داده می شود.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
در زیر به ویژگی tips می پردازیم. ما همچنین یک مقدار INT در ثانیه های سفر خود داریم، جایی که طرح ما انتظار یک FLOAT را داشت. با آگاه کردن ما از این تفاوت، TFDV به کشف تناقضات در نحوه تولید داده ها برای آموزش و ارائه کمک می کند. بسیار آسان است که از چنین مشکلاتی آگاه نباشید تا زمانی که عملکرد مدل آسیب ببیند، گاهی اوقات به طور فاجعه بار. ممکن است موضوع مهمی باشد یا نباشد، اما در هر صورت باید دلیلی برای بررسی بیشتر باشد.
در این حالت، میتوانیم با خیال راحت مقادیر INT را به FLOAT تبدیل کنیم، بنابراین میخواهیم به TFDV بگوییم که از طرح ما برای استنباط نوع استفاده کند. حالا این کار را بکنیم.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
اکنون فقط ویژگی tips (که برچسب ما است) به عنوان یک ناهنجاری نشان داده می شود ("ستون حذف شد"). البته ما انتظار نداریم که برچسب هایی در داده های ارائه شده خود داشته باشیم، بنابراین بیایید به TFDV بگوییم که آن را نادیده بگیرد.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
رانش و انحراف را بررسی کنید
علاوه بر بررسی اینکه آیا یک مجموعه داده با انتظارات تعیین شده در طرح مطابقت دارد یا خیر، TFDV همچنین عملکردهایی را برای تشخیص انحراف و انحراف ارائه می دهد. TFDV این بررسی را با مقایسه آمار مجموعه داده های مختلف بر اساس مقایسه کننده های drift/skew مشخص شده در طرح انجام می دهد.
رانش
تشخیص دریفت برای ویژگیهای طبقهبندی و بین بازههای متوالی دادهها (یعنی بین دهانه N و دهانه N+1)، مانند بین روزهای مختلف دادههای آموزشی، پشتیبانی میشود. ما دریفت را بر حسب فاصله L-infinity بیان میکنیم و میتوانید فاصله آستانه را طوری تنظیم کنید که وقتی دریفت بالاتر از حد قابل قبول است، هشدار دریافت کنید. تنظیم فاصله صحیح معمولاً یک فرآیند تکراری است که به دانش و آزمایش دامنه نیاز دارد.
کج شدن
TFDV می تواند سه نوع انحراف مختلف را در داده های شما تشخیص دهد - چولگی طرحواره، انحراف ویژگی و انحراف توزیع.
طرحواره کج
انحراف طرحواره زمانی اتفاق میافتد که دادههای آموزشی و ارائهدهی با همان طرح مطابقت نداشته باشند. انتظار میرود که دادههای آموزشی و ارائهدهی هر دو به طرح یکسانی پایبند باشند. هر گونه انحراف مورد انتظار بین این دو (مانند ویژگی برچسب که فقط در داده های آموزشی وجود دارد اما در ارائه نیست) باید از طریق فیلد محیط ها در طرح مشخص شود.
ویژگی Skew
انحراف ویژگی زمانی اتفاق میافتد که مقادیر ویژگیهایی که مدل آموزش میدهد با مقادیر ویژگیهایی که در زمان ارائه میبیند متفاوت باشد. به عنوان مثال، این ممکن است زمانی اتفاق بیفتد که:
- منبع داده ای که مقادیری از ویژگی ها را ارائه می دهد، بین زمان آموزش و سرویس دهی اصلاح می شود
- منطق متفاوتی برای ایجاد ویژگی بین آموزش و خدمت وجود دارد. برای مثال، اگر مقداری تبدیل را فقط در یکی از دو مسیر کد اعمال کنید.
انحراف توزیع
انحراف توزیع زمانی اتفاق می افتد که توزیع مجموعه داده آموزشی به طور قابل توجهی با توزیع مجموعه داده ارائه شده متفاوت باشد. یکی از دلایل اصلی انحراف توزیع، استفاده از کدهای مختلف یا منابع داده مختلف برای تولید مجموعه داده آموزشی است. دلیل دیگر یک مکانیسم نمونه گیری معیوب است که یک نمونه فرعی غیرنماینده از داده های ارائه شده را برای آموزش انتخاب می کند.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
در این مثال ما مقداری دریفت را می بینیم، اما بسیار پایین تر از آستانه ای است که ما تعیین کرده ایم.
طرحواره را فریز کنید
اکنون که طرحواره بررسی و مدیریت شده است، آن را در یک فایل ذخیره می کنیم تا حالت "یخ زده" آن را منعکس کند.
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
زمان استفاده از TFDV
به راحتی می توان تصور کرد که TFDV فقط برای شروع خط لوله آموزشی شما کاربرد دارد، همانطور که در اینجا انجام دادیم، اما در واقع کاربردهای زیادی دارد. در اینجا چند مورد دیگر وجود دارد:
- اعتبارسنجی دادههای جدید برای استنباط برای اطمینان از اینکه ما ناگهان شروع به دریافت ویژگیهای بد نکردهایم
- اعتبار سنجی داده های جدید برای استنتاج برای اطمینان از اینکه مدل ما در آن قسمت از سطح تصمیم آموزش دیده است
- اعتبارسنجی دادههایمان پس از تبدیل آنها و انجام مهندسی ویژگی (احتمالاً با استفاده از TensorFlow Transform ) برای اطمینان از اینکه کار اشتباهی انجام ندادهایم