
TensorFlow Extended'ın Temel Bileşenine Bir Örnek
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu örnek ortak çalışma not defteri, veri kümenizi araştırmak ve görselleştirmek için TensorFlow Veri Doğrulamasının (TFDV) nasıl kullanılabileceğini gösterir. Bu, tanımlayıcı istatistiklere bakmayı, bir şema çıkarmayı, anormallikleri kontrol etmeyi ve düzeltmeyi ve veri setimizde sapma ve çarpıklığı kontrol etmeyi içerir. Üretim hattınızda zaman içinde nasıl değişebileceği de dahil olmak üzere veri kümenizin özelliklerini anlamak önemlidir. Verilerinizdeki anormallikleri aramak ve tutarlı olduklarından emin olmak için eğitim, değerlendirme ve sunum veri kümelerinizi karşılaştırmak da önemlidir.
Chicago Şehri tarafından yayınlanan Taksi Gezileri veri setindeki verileri kullanacağız.
Google BigQuery'deki veri kümesi hakkında daha fazla bilgi edinin. BigQuery kullanıcı arayüzündeki tüm veri kümesini keşfedin.
Veri kümesindeki sütunlar şunlardır:
| pickup_community_area | Ücret | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_census_tract |
| dropoff_census_tract | ödeme şekli | şirket |
| trip_saniye | dropoff_community_area | ipuçları |
Paketleri kurun ve içe aktarın
TensorFlow Veri Doğrulaması için paketleri kurun.
Pip'i Yükselt
Yerel olarak çalışırken bir sistemde Pip'i yükseltmekten kaçınmak için Colab'da çalıştığımızdan emin olun. Yerel sistemler elbette ayrı ayrı yükseltilebilir.
try:
import colab
!pip install --upgrade pip
except:
pass
Veri Doğrulama paketlerini yükleyin
Birkaç dakika süren TensorFlow Veri Doğrulama paketlerini ve bağımlılıklarını yükleyin. Bir sonraki bölümde çözeceğiniz uyumsuz bağımlılık sürümleriyle ilgili uyarılar ve hatalar görebilirsiniz.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
TensorFlow'u içe aktarın ve güncellenmiş paketleri yeniden yükleyin
Önceki adım, Gooogle Colab ortamındaki varsayılan paketleri günceller, bu nedenle yeni bağımlılıkları çözmek için paket kaynaklarını yeniden yüklemeniz gerekir.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Devam etmeden önce TensorFlow sürümlerini ve Veri Doğrulama'yı kontrol edin.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Veri kümesini yükleyin
Veri setimizi Google Cloud Storage'dan indireceğiz.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
İstatistikleri hesaplayın ve görselleştirin
İlk olarak, eğitim verilerimizin istatistiklerini hesaplamak için tfdv.generate_statistics_from_csv kullanacağız. (hızlı uyarıları dikkate almayın)
TFDV, mevcut özellikler ve değer dağılımlarının şekilleri açısından verilere hızlı bir genel bakış sağlayan tanımlayıcı istatistikleri hesaplayabilir.
Dahili olarak, TFDV, büyük veri kümeleri üzerinde istatistiklerin hesaplanmasını ölçeklendirmek için Apache Beam'in veri paralel işleme çerçevesini kullanır. TFDV ile daha derin entegrasyon isteyen uygulamalar için (örneğin, bir veri oluşturma hattının sonuna istatistik üretimi ekleme), API ayrıca istatistik üretimi için bir Beam PTransform'u ortaya çıkarır.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
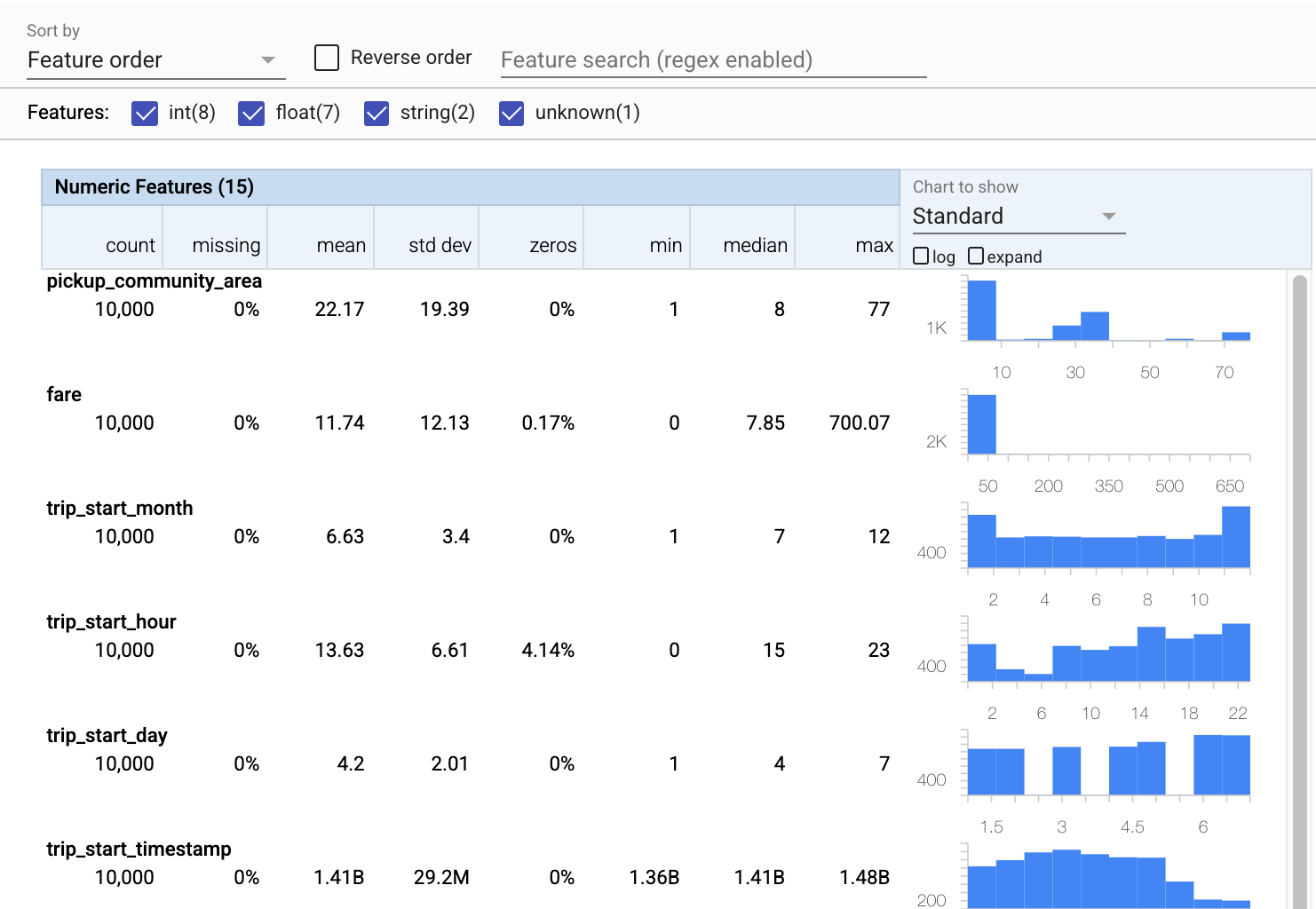
Şimdi, eğitim verilerimizin kısa ve öz bir görselleştirmesini oluşturmak için tfdv.visualize_statistics kullanan tfdv.visualize_statistics'i kullanalım:
- Sayısal özelliklerin ve kategorik özelliklerin ayrı ayrı görselleştirildiğine ve her bir özelliğin dağılımlarını gösteren çizelgelerin görüntülendiğine dikkat edin.
- Eksik veya sıfır değerleri olan özelliklerin, bu özelliklerdeki örneklerle ilgili sorunlar olabileceğinin görsel bir göstergesi olarak kırmızı yüzde gösterdiğine dikkat edin. Yüzde, o özellik için eksik veya sıfır değerleri olan örneklerin yüzdesidir.
-
pickup_census_tractdeğerlerine sahip hiçbir örnek olmadığına dikkat edin. Bu, boyutsallığı azaltmak için bir fırsattır! - Görüntüyü değiştirmek için çizelgelerin üzerindeki "genişlet"i tıklamayı deneyin
- Kova aralıklarını ve sayılarını görüntülemek için grafiklerdeki çubukların üzerine gelmeyi deneyin
- Günlük ve doğrusal ölçekler arasında geçiş yapmayı deneyin ve günlük ölçeğinin
payment_typekategorik özelliği hakkında çok daha fazla ayrıntıyı nasıl ortaya koyduğuna dikkat edin. - "Gösterilecek grafik" menüsünden "miktarları" seçmeyi deneyin ve nicelik yüzdelerini göstermek için işaretçilerin üzerine gelin
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Bir şema çıkar
Şimdi verilerimiz için bir şema oluşturmak için tfdv.infer_schema . Bir şema, ML ile ilgili veriler için kısıtlamaları tanımlar. Örnek kısıtlamalar, sayısal veya kategorik olsun, her özelliğin veri türünü veya verilerdeki varlığının sıklığını içerir. Kategorik özellikler için şema, etki alanını da tanımlar - kabul edilebilir değerler listesi. Bir şema yazmak, özellikle çok sayıda özelliğe sahip veri kümeleri için sıkıcı bir iş olabileceğinden, TFDV, tanımlayıcı istatistiklere dayalı olarak şemanın ilk sürümünü oluşturmak için bir yöntem sağlar.
Şemayı doğru yapmak önemlidir çünkü üretim hattımızın geri kalanı TFDV'nin oluşturduğu şemanın doğru olmasına güvenecektir. Şema ayrıca veriler için belgeler sağlar ve bu nedenle, farklı geliştiriciler aynı veriler üzerinde çalışırken kullanışlıdır. Çıkarsanan şemayı görüntülemek için tfdv.display_schema , böylece gözden geçirebiliriz.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Hatalar için değerlendirme verilerini kontrol edin
Şimdiye kadar sadece eğitim verilerine bakıyorduk. Değerlendirme verilerimizin, aynı şemayı kullanması da dahil olmak üzere, eğitim verilerimizle tutarlı olması önemlidir. Değerlendirme verilerinin, eğitim verilerimizle sayısal özelliklerimiz için kabaca aynı değer aralıklarının örneklerini içermesi de önemlidir, böylece değerlendirme sırasındaki kayıp yüzeyi kapsamımız eğitim sırasındakiyle kabaca aynı olur. Aynı şey kategorik özellikler için de geçerlidir. Aksi takdirde, kayıp yüzeyimizin bir kısmını değerlendirmediğimiz için değerlendirme sırasında belirlenmeyen eğitim sorunları yaşayabiliriz.
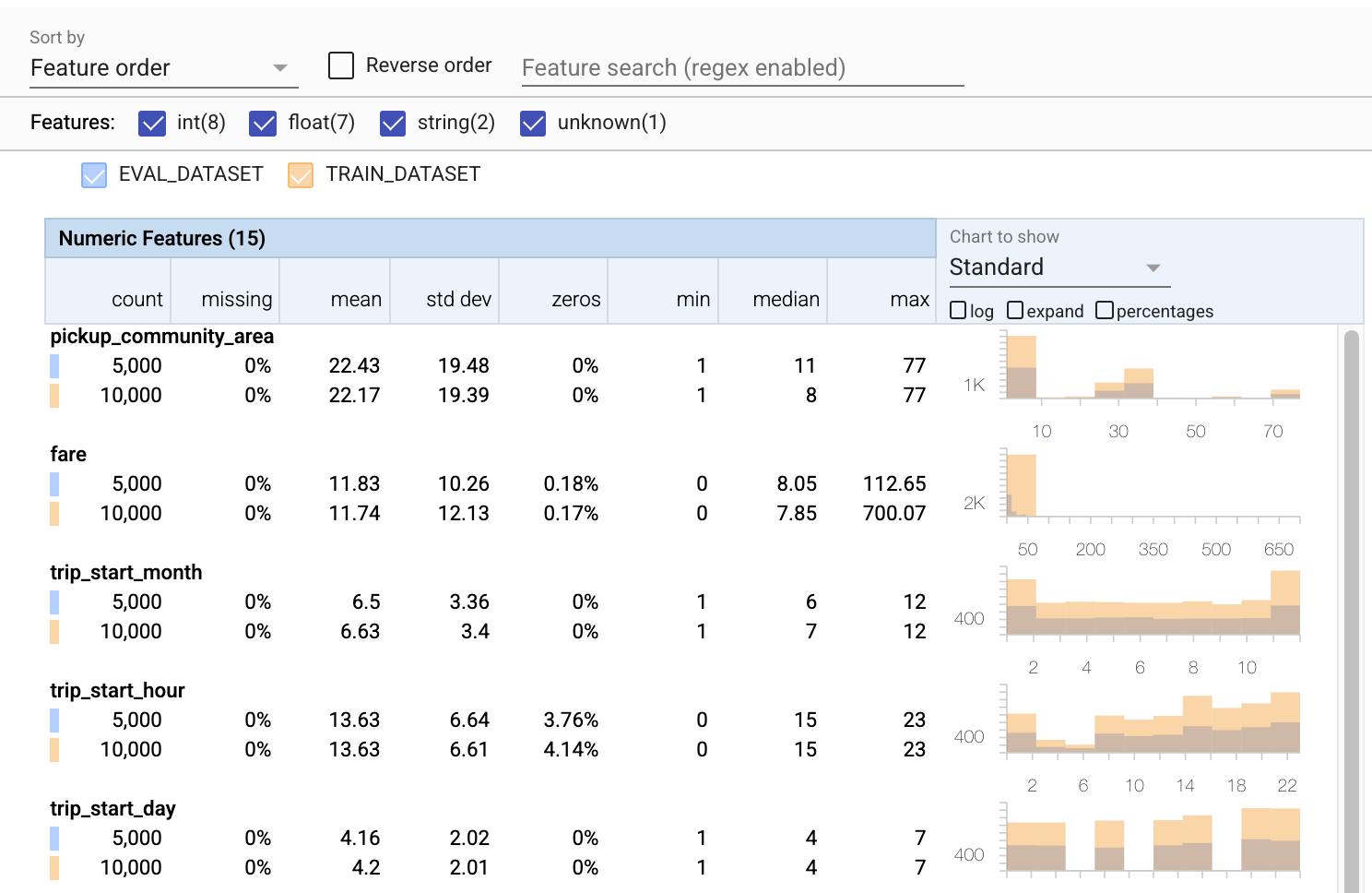
- Her özelliğin artık hem eğitim hem de değerlendirme veri kümeleri için istatistikler içerdiğine dikkat edin.
- Grafiklerin artık hem eğitim hem de değerlendirme veri kümelerinin üst üste bindirilmiş olduğuna dikkat edin, bu da onları karşılaştırmayı kolaylaştırır.
- Grafiklerin artık günlük veya varsayılan doğrusal ölçeklerle birleştirilebilen bir yüzde görünümü içerdiğine dikkat edin.
-
trip_milesiçin ortalama ve medyanın, eğitim ile değerlendirme veri kümeleri için farklı olduğuna dikkat edin. Bu sorunlara neden olur mu? - Vay canına, maksimum
tips, eğitim ve değerlendirme veri kümeleri için çok farklıdır. Bu sorunlara neden olur mu? - Sayısal Özellikler tablosunda genişlet'e tıklayın ve günlük ölçeğini seçin.
trip_secondsözelliğini inceleyin ve maks. Değerlendirme, kayıp yüzeyinin bazı kısımlarını gözden kaçıracak mı?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.-yer tutucu14 l10n-yer
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Değerlendirme anormalliklerini kontrol edin
Değerlendirme veri kümemiz, eğitim veri kümemizdeki şemayla eşleşiyor mu? Bu, özellikle kabul edilebilir değerler aralığını belirlemek istediğimiz kategorik özellikler için önemlidir.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Şemadaki değerlendirme anormalliklerini düzeltin
Hata! Değerlendirme verilerimizde company için eğitim verilerimizde olmayan bazı yeni değerlerimiz var gibi görünüyor. Ayrıca payment_type için yeni bir değerimiz var. Bunlar anormal olarak kabul edilmelidir, ancak onlar hakkında ne yapmaya karar verdiğimiz, verilerle ilgili alan bilgimize bağlıdır. Bir anormallik gerçekten bir veri hatasını gösteriyorsa, temel alınan veriler düzeltilmelidir. Aksi takdirde, değerleri değerlendirme veri setine dahil etmek için şemayı basitçe güncelleyebiliriz.
Değerlendirme veri setimizi değiştirmedikçe her şeyi düzeltemeyiz, ancak şemada kabul etmekten çekindiğimiz şeyleri düzeltebiliriz. Bu, belirli özellikler için neyin anormal olup olmadığına dair görüşümüzü gevşetmeyi ve kategorik özellikler için eksik değerleri içerecek şekilde şemamızı güncellemeyi içerir. TFDV, neyi düzeltmemiz gerektiğini keşfetmemizi sağladı.
Şimdi bu düzeltmeleri yapalım ve ardından bir kez daha gözden geçirelim.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Şuna bak! Eğitim ve değerlendirme verilerinin artık tutarlı olduğunu doğruladık! Teşekkürler TFDV ;)
Şema Ortamları
Ayrıca bu örnek için bir 'servis' veri setini ayırdık, bu yüzden onu da kontrol etmeliyiz. Varsayılan olarak, bir işlem hattındaki tüm veri kümeleri aynı şemayı kullanmalıdır, ancak genellikle istisnalar vardır. Örneğin, denetimli öğrenmede veri kümemize etiketleri dahil etmemiz gerekir, ancak modeli çıkarım için sunduğumuzda etiketler dahil edilmeyecektir. Bazı durumlarda, hafif şema varyasyonlarının tanıtılması gereklidir.
Bu tür gereksinimleri ifade etmek için ortamlar kullanılabilir. Özellikle, şemadaki özellikler default_environment , in_environment ve not_in_environment kullanan bir dizi ortamla ilişkilendirilebilir.
Örneğin, bu veri kümesinde tips özelliği eğitim etiketi olarak dahil edilmiştir, ancak sunum verilerinde bu özellik eksiktir. Ortam belirtilmeden, bir anormallik olarak görünecektir.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Aşağıdaki tips özelliği ile ilgileneceğiz. Ayrıca, şemamızın bir FLOAT beklediği yolculuk saniyelerimizde bir INT değerimiz var. TFDV, bu farkın farkına varmamızı sağlayarak, verilerin eğitim ve sunum için oluşturulma biçimindeki tutarsızlıkların ortaya çıkarılmasına yardımcı olur. Model performansı bazen felaketle sonuçlanana kadar böyle sorunlardan habersiz olmak çok kolaydır. Önemli bir konu olabilir veya olmayabilir, ancak her durumda bu daha fazla araştırma için neden olmalıdır.
Bu durumda, INT değerlerini güvenli bir şekilde FLOAT'lara dönüştürebiliriz, bu nedenle TFDV'ye, tür çıkarımı için şemamızı kullanmasını söylemek istiyoruz. Şimdi yapalım.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Şimdi sadece bir anormallik ('Sütun düştü') olarak görünen tips özelliğine sahibiz (ki bu bizim etiketimizdir). Tabii ki sunum verilerimizde etiketlerin olmasını beklemiyoruz, o yüzden TFDV'ye bunu görmezden gelmesini söyleyelim.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Sürüklenme ve eğriliği kontrol edin
TFDV, bir veri kümesinin şemada belirlenen beklentilere uyup uymadığını kontrol etmenin yanı sıra, kayma ve çarpıklığı tespit etme işlevleri de sağlar. TFDV, şemada belirtilen sapma/skew karşılaştırıcılarına dayalı olarak farklı veri kümelerinin istatistiklerini karşılaştırarak bu kontrolü gerçekleştirir.
sürüklenme
Sürüklenme algılama, kategorik özellikler için ve ardışık veri aralıkları arasında (yani, aralık N ve aralık N+1 arasında), örneğin farklı eğitim verileri günleri arasında desteklenir. Sürüklenmeyi L-sonsuz mesafe olarak ifade ediyoruz ve eşik mesafesini, sapma kabul edilebilir olandan daha yüksek olduğunda uyarı alacak şekilde ayarlayabilirsiniz. Doğru mesafeyi ayarlamak, tipik olarak, alan bilgisi ve deney gerektiren yinelemeli bir süreçtir.
eğmek
TFDV, verilerinizdeki üç farklı türde çarpıklığı algılayabilir - şema çarpıklığı, özellik çarpıklığı ve dağıtım çarpıklığı.
Şema Eğriliği
Şema eğriliği, eğitim ve hizmet verileri aynı şemaya uymadığında oluşur. Hem eğitim hem de sunum verilerinin aynı şemaya bağlı kalması beklenir. İkisi arasında beklenen herhangi bir sapma (etiket özelliğinin yalnızca eğitim verilerinde bulunması ancak hizmet vermemesi gibi) şemadaki ortamlar alanında belirtilmelidir.
Özellik Eğriliği
Özellik eğriliği, bir modelin üzerinde eğittiği özellik değerleri, sunum sırasında gördüğü özellik değerlerinden farklı olduğunda oluşur. Örneğin, bu şu durumlarda olabilir:
- Bazı özellik değerleri sağlayan bir veri kaynağı, eğitim ve sunum süresi arasında değiştirilir
- Eğitim ve sunum arasında özellik oluşturmanın farklı bir mantığı vardır. Örneğin, iki kod yolundan yalnızca birinde bazı dönüşümler uygularsanız.
dağıtım çarpıklığı
Dağıtım çarpıklığı, eğitim veri kümesinin dağılımı, hizmet veren veri kümesinin dağılımından önemli ölçüde farklı olduğunda meydana gelir. Dağılım çarpıklığının temel nedenlerinden biri, eğitim veri kümesini oluşturmak için farklı kod veya farklı veri kaynakları kullanmaktır. Diğer bir neden, üzerinde eğitim verilecek hizmet verisinin temsili olmayan bir alt örneğini seçen hatalı bir örnekleme mekanizmasıdır.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
Bu örnekte bir miktar sapma görüyoruz, ancak bu bizim belirlediğimiz eşiğin oldukça altında.
Şemayı dondur
Şema incelenip küratörlüğünü yaptığına göre, "donmuş" durumunu yansıtmak için onu bir dosyada saklayacağız.
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
TFDV ne zaman kullanılır?
TFDV'yi burada yaptığımız gibi yalnızca eğitim hattınızın başlangıcı için geçerli olarak düşünmek kolaydır, ancak aslında birçok kullanımı vardır. İşte birkaç tane daha:
- Aniden kötü özellikler almaya başlamadığımızdan emin olmak için yeni verileri çıkarım için doğrulama
- Modelimizin karar yüzeyinin o kısmında eğitim aldığından emin olmak için yeni verileri çıkarım için doğrulama
- Verilerimizi dönüştürdükten ve özellik mühendisliği yaptıktan sonra (muhtemelen TensorFlow Transform kullanarak) yanlış bir şey yapmadığımızdan emin olmak için doğrulama