
Пример ключевого компонента TensorFlow Extended
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом примере совместной записной книжки показано, как можно использовать проверку данных TensorFlow (TFDV) для исследования и визуализации набора данных. Это включает в себя просмотр описательной статистики, вывод схемы, проверку и исправление аномалий, а также проверку дрейфа и перекоса в нашем наборе данных. Важно понимать характеристики вашего набора данных, в том числе то, как он может меняться со временем в вашем производственном конвейере. Также важно искать аномалии в ваших данных и сравнивать наборы данных для обучения, оценки и обслуживания, чтобы убедиться, что они непротиворечивы.
Мы будем использовать данные из набора данных Taxi Trips , опубликованного городом Чикаго.
Подробнее о наборе данных в Google BigQuery . Изучите полный набор данных в пользовательском интерфейсе BigQuery .
Столбцы в наборе данных:
| pickup_community_area | транспортные расходы | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | pickup_census_tract |
| dropoff_census_tract | способ оплаты | Компания |
| trip_seconds | dropoff_community_area | подсказки |
Установка и импорт пакетов
Установите пакеты для проверки данных TensorFlow.
Обновить Пип
Чтобы избежать обновления Pip в системе при локальном запуске, убедитесь, что мы работаем в Colab. Локальные системы, конечно, могут быть обновлены отдельно.
try:
import colab
!pip install --upgrade pip
except:
pass
Установите пакеты проверки данных
Установите пакеты и зависимости проверки данных TensorFlow, что займет несколько минут. Вы можете увидеть предупреждения и ошибки, касающиеся несовместимых версий зависимостей, которые вы устраните в следующем разделе.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Импортируйте TensorFlow и перезагрузите обновленные пакеты
Предыдущий шаг обновляет пакеты по умолчанию в среде Gooogle Colab, поэтому вам необходимо перезагрузить ресурсы пакета, чтобы устранить новые зависимости.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Прежде чем продолжить, проверьте версии TensorFlow и проверки данных.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Загрузите набор данных
Мы загрузим наш набор данных из Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Вычислять и визуализировать статистику
Сначала мы будем использовать tfdv.generate_statistics_from_csv для вычисления статистики для наших обучающих данных. (не обращайте внимания на резкие предупреждения)
TFDV может вычислять описательную статистику , которая обеспечивает быстрый обзор данных с точки зрения присутствующих признаков и форм распределения их значений.
Внутри TFDV использует структуру параллельной обработки данных Apache Beam для масштабирования вычисления статистики по большим наборам данных. Для приложений, которым требуется более глубокая интеграция с TFDV (например, присоединение генерации статистики в конце конвейера генерации данных), API также предоставляет Beam PTransform для генерации статистики.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
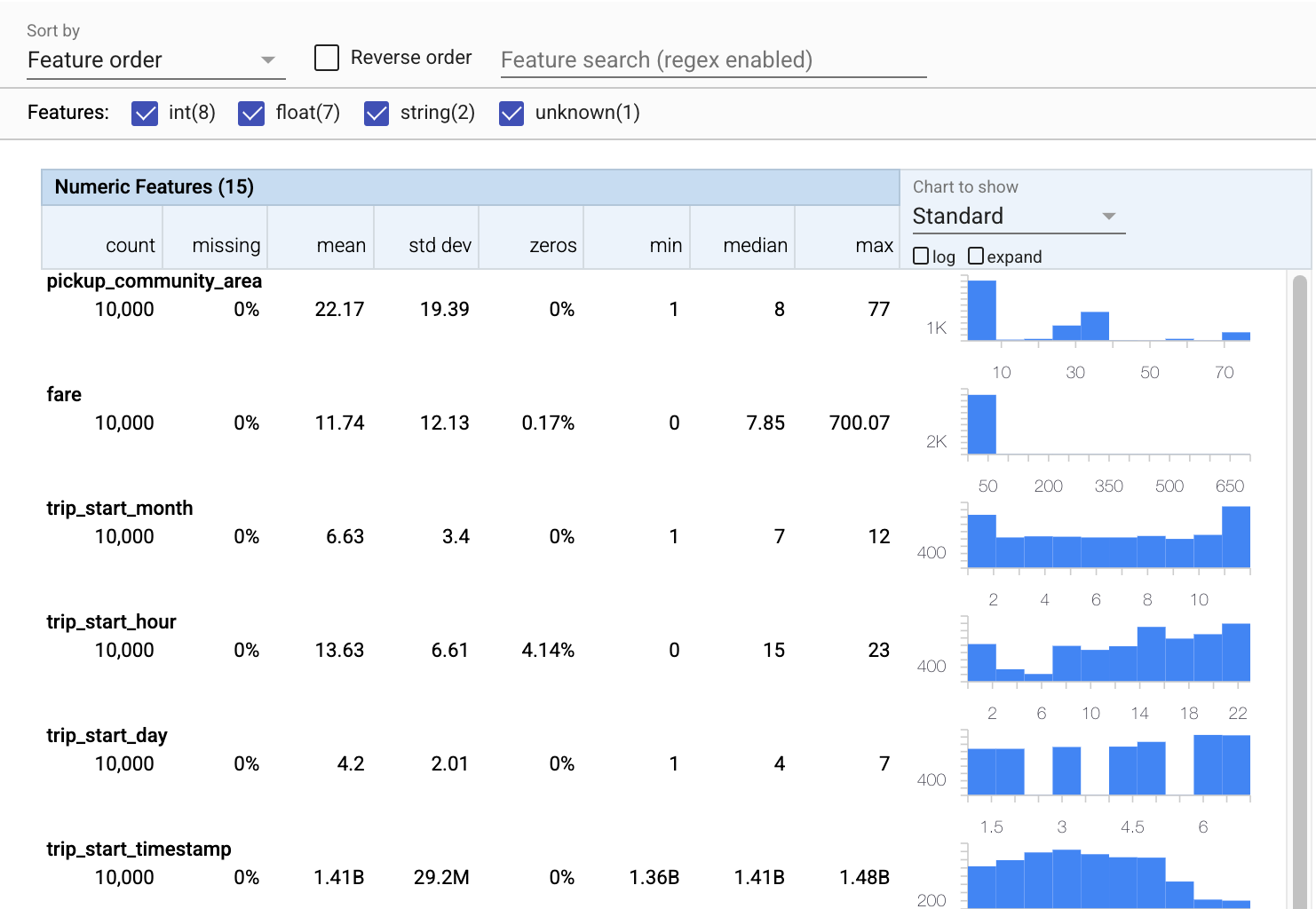
Теперь давайте воспользуемся tfdv.visualize_statistics , который использует Facets для создания краткой визуализации наших обучающих данных:
- Обратите внимание, что числовые функции и категориальные функции визуализируются отдельно, и что отображаются диаграммы, показывающие распределения для каждой функции.
- Обратите внимание, что функции с отсутствующими или нулевыми значениями отображаются красным цветом в процентах как визуальный индикатор того, что могут быть проблемы с примерами в этих функциях. Процент — это процент примеров, в которых отсутствуют или нулевые значения для этой функции.
- Обратите внимание, что нет примеров со значениями для
pickup_census_tract. Это возможность для уменьшения размерности! - Попробуйте нажать «развернуть» над диаграммами, чтобы изменить отображение
- Попробуйте навести курсор на столбцы на диаграммах, чтобы отобразить диапазоны сегментов и подсчеты.
- Попробуйте переключиться между логарифмической и линейной шкалами и обратите внимание, как логарифмическая шкала раскрывает гораздо больше деталей о категориальной функции
payment_type - Попробуйте выбрать «квантили» в меню «Диаграмма для отображения» и наведите указатель мыши на маркеры, чтобы отобразить квантили в процентах.
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Вывод схемы
Теперь воспользуемся tfdv.infer_schema для создания схемы для наших данных. Схема определяет ограничения для данных, которые имеют отношение к ML. Примеры ограничений включают тип данных каждой функции, независимо от того, является ли она числовой или категориальной, или частоту ее присутствия в данных. Для категориальных признаков схема также определяет домен — список допустимых значений. Поскольку написание схемы может быть утомительной задачей, особенно для наборов данных с большим количеством функций, TFDV предоставляет метод создания начальной версии схемы на основе описательной статистики.
Правильная схема важна, потому что остальная часть нашего производственного конвейера будет полагаться на правильную схему, которую генерирует TFDV. Схема также предоставляет документацию для данных, поэтому она полезна, когда разные разработчики работают с одними и теми же данными. Давайте воспользуемся tfdv.display_schema для отображения предполагаемой схемы, чтобы мы могли ее просмотреть.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Проверить данные оценки на наличие ошибок
До сих пор мы рассматривали только тренировочные данные. Важно, чтобы наши оценочные данные соответствовали нашим обучающим данным, включая использование той же схемы. Также важно, чтобы оценочные данные включали примеры примерно тех же диапазонов значений для наших числовых признаков, что и наши обучающие данные, чтобы наше покрытие поверхности потерь во время оценки было примерно таким же, как и во время обучения. То же самое относится и к категориальным признакам. В противном случае у нас могут возникнуть проблемы с обучением, которые не будут выявлены во время оценки, поскольку мы не оценили часть нашей поверхности потерь.
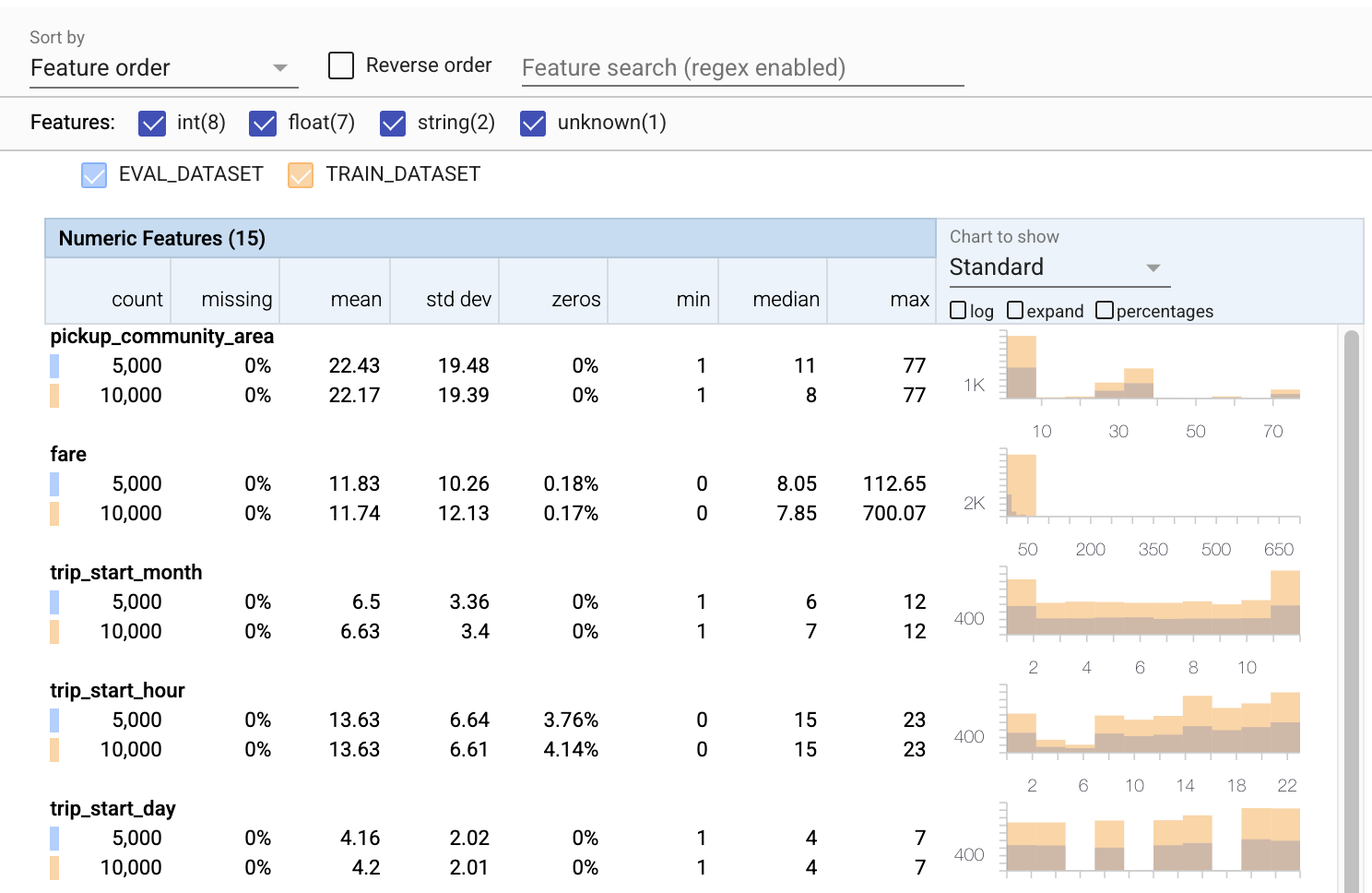
- Обратите внимание, что каждая функция теперь включает статистику как для обучающего, так и для оценочного набора данных.
- Обратите внимание, что на диаграммы теперь наложены наборы данных для обучения и оценки, что упрощает их сравнение.
- Обратите внимание, что диаграммы теперь включают представление в процентах, которое можно комбинировать с логарифмической или линейной шкалой по умолчанию.
- Обратите внимание, что среднее значение и медиана для
trip_milesразличаются для обучающих и оценочных наборов данных. Это вызовет проблемы? - Вау, максимальные
tipsсильно отличаются для обучающих и оценочных наборов данных. Это вызовет проблемы? - Нажмите «Развернуть» на диаграмме «Числовые признаки» и выберите логарифмическую шкалу. Просмотрите функцию
trip_secondsи обратите внимание на разницу в макс. Не пропустит ли оценка части поверхности потерь?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Проверка на аномалии оценки
Соответствует ли наш оценочный набор данных схеме из нашего обучающего набора данных? Это особенно важно для категориальных функций, где мы хотим определить диапазон допустимых значений.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Исправление аномалий оценки в схеме
Ой! Похоже, у нас есть некоторые новые значения для company в наших оценочных данных, которых у нас не было в наших обучающих данных. У нас также есть новое значение для payment_type . Их следует рассматривать как аномалии, но то, что мы решаем с ними делать, зависит от нашего знания предметной области данных. Если аномалия действительно указывает на ошибку данных, то основные данные должны быть исправлены. В противном случае мы можем просто обновить схему, чтобы включить значения в набор данных eval.
Если мы не изменим наш оценочный набор данных, мы не сможем исправить все, но мы можем исправить то, что нам удобно принять в схеме. Это включает в себя смягчение нашего взгляда на то, что является аномалией, а что нет, для определенных функций, а также обновление нашей схемы, чтобы включить пропущенные значения для категориальных функций. TFDV позволил нам обнаружить, что нам нужно исправить.
Давайте внесем эти исправления сейчас, а затем просмотрим еще раз.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Эй, посмотри на это! Мы убедились, что данные обучения и оценки теперь согласуются! Спасибо ТДВ ;)
Среды схемы
Мы также выделили «обслуживающий» набор данных для этого примера, поэтому мы должны проверить и это. По умолчанию все наборы данных в конвейере должны использовать одну и ту же схему, но часто бывают исключения. Например, при обучении с учителем нам нужно включить метки в наш набор данных, но когда мы используем модель для вывода, метки не будут включены. В некоторых случаях необходимо внести небольшие изменения в схему.
Среды могут использоваться для выражения таких требований. В частности, функции в схеме могут быть связаны с набором сред с помощью default_environment , in_environment и not_in_environment .
Например, в этом наборе данных функция tips включена в качестве метки для обучения, но отсутствует в данных обслуживания. Без указания среды это будет отображаться как аномалия.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Мы рассмотрим функцию tips ниже. У нас также есть значение INT в секундах поездки, где наша схема ожидала FLOAT. Сообщая нам об этой разнице, TFDV помогает выявить несоответствия в том, как генерируются данные для обучения и обслуживания. Очень легко не знать о подобных проблемах до тех пор, пока производительность модели не пострадает, иногда катастрофически. Это может быть или не быть серьезной проблемой, но в любом случае это должно стать поводом для дальнейшего расследования.
В этом случае мы можем безопасно конвертировать значения INT в FLOAT, поэтому мы хотим указать TFDV использовать нашу схему для вывода типа. Давайте сделаем это сейчас.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Теперь у нас просто есть функция tips (которая является нашей меткой), отображаемая как аномалия («Столбец удален»). Конечно, мы не ожидаем наличия меток в данных о показе, поэтому давайте скажем TFDV игнорировать это.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Проверка на дрейф и перекос
В дополнение к проверке того, соответствует ли набор данных ожиданиям, установленным в схеме, TFDV также предоставляет функции для обнаружения дрейфа и перекоса. TFDV выполняет эту проверку, сравнивая статистику различных наборов данных на основе компараторов дрейфа/перекоса, указанных в схеме.
Дрейф
Обнаружение дрейфа поддерживается для категориальных признаков и между последовательными интервалами данных (т. е. между интервалом N и интервалом N+1), например, между разными днями обучающих данных. Мы выражаем дрейф в терминах L-бесконечного расстояния , и вы можете установить пороговое расстояние, чтобы получать предупреждения, когда дрейф превышает допустимое значение. Установка правильного расстояния обычно представляет собой повторяющийся процесс, требующий знаний предметной области и экспериментов.
перекос
TFDV может обнаруживать три различных вида асимметрии в ваших данных — асимметрию схемы, асимметрию функций и асимметрию распределения.
Перекос схемы
Перекос схемы возникает, когда обучающие и обслуживающие данные не соответствуют одной и той же схеме. Ожидается, что данные обучения и обслуживания будут придерживаться одной и той же схемы. Любые ожидаемые отклонения между ними (например, функция метки присутствует только в обучающих данных, но не в обслуживании) должны быть указаны в поле среды в схеме.
Перекос функции
Перекос функций возникает, когда значения функций, на которых обучается модель, отличаются от значений функций, которые она видит во время обслуживания. Например, это может произойти, когда:
- Источник данных, который предоставляет некоторые значения функций, изменяется между обучением и обслуживанием.
- Существует разная логика создания функций между обучением и обслуживанием. Например, если вы применяете какое-то преобразование только в одном из двух путей кода.
Перекос распределения
Перекос распределения возникает, когда распределение обучающего набора данных значительно отличается от распределения обслуживающего набора данных. Одной из основных причин перекоса распределения является использование другого кода или разных источников данных для создания набора обучающих данных. Другая причина — неправильный механизм выборки, который выбирает нерепрезентативную подвыборку обслуживающих данных для обучения.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
В этом примере мы видим некоторый дрейф, но он намного ниже установленного нами порога.
Заморозить схему
Теперь, когда схема проверена и проверена, мы сохраним ее в файле, чтобы отразить ее «замороженное» состояние.
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Когда использовать TFDV
Легко думать, что TFDV применим только к началу вашего учебного конвейера, как мы сделали здесь, но на самом деле у него много применений. Вот еще несколько:
- Проверка новых данных для вывода, чтобы убедиться, что мы не начали внезапно получать плохие функции
- Проверка новых данных для вывода, чтобы убедиться, что наша модель обучена этой части поверхности принятия решений.
- Проверка наших данных после того, как мы преобразовали их и выполнили разработку функций (вероятно, с использованием TensorFlow Transform ), чтобы убедиться, что мы не сделали что-то не так.