
TensorFlow Serving'i dağıttıktan ve istemcinizden istekler yayınladıktan sonra, isteklerin beklediğinizden daha uzun sürdüğünü veya istediğiniz aktarım hızına ulaşamadığınızı fark edebilirsiniz.
Bu kılavuzda, çıkarım performansını hata ayıklamamıza ve geliştirmemize yardımcı olacak çıkarım isteklerini izlemek için profil modeli eğitimi için zaten kullanabileceğiniz TensorBoard Profiler'ı kullanacağız.
Modelinizi, isteklerinizi ve TensorFlow Sunum örneğinizi optimize etmek için bu kılavuzu Performans Kılavuzunda belirtilen en iyi uygulamalarla birlikte kullanmalısınız.
Genel Bakış
Yüksek düzeyde, TensorBoard'un Profil Oluşturma aracını TensorFlow Serving'in gRPC sunucusuna yönlendireceğiz. Tensorflow Serving'e bir çıkarım isteği gönderdiğimizde, aynı zamanda bu isteğin izlerini yakalamasını istemek için TensorBoard UI'yi de kullanacağız. Perde arkasında TensorBoard, gRPC üzerinden TensorFlow Serving ile konuşacak ve ondan çıkarım isteğinin ömrüne ilişkin ayrıntılı bir izleme sağlamasını isteyecek. TensorBoard daha sonra TensorBoard kullanıcı arayüzündeki isteğin kullanım ömrü boyunca her hesaplama cihazındaki ( profiler::TraceMe ile entegre kod çalıştıran) her iş parçacığının etkinliğini bizim için görselleştirecektir.
Önkoşullar
-
Tensorflow>=2.0.0 - TensorBoard (TF
piparacılığıyla kurulmuşsa kurulmalıdır) - Docker (TF sunumunu indirmek ve çalıştırmak için kullanacağımız>=2.1.0 görüntüsü)
Modeli TensorFlow Sunumu ile dağıtma
Bu örnekte, Tensorflow Hizmetini dağıtmanın önerilen yolu olan Docker'ı, Tensorflow Hizmet Github deposunda bulunan f(x) = x / 2 + 2 hesaplayan bir oyuncak modelini barındırmak için kullanacağız.
TensorFlow Hizmet kaynağını indirin.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Docker aracılığıyla TensorFlow Serving'i başlatın ve half_plus_two modelini dağıtın.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
Başka bir terminalde, modelin doğru şekilde dağıtıldığından emin olmak için modeli sorgulayın
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
TensorBoard Profiler'ı kurun
Başka bir terminalde, makinenizde TensorBoard aracını başlatın ve çıkarım izleme olaylarını şuraya kaydedeceğiniz bir dizin sağlayın:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
TensorBoard kullanıcı arayüzünü görüntülemek için http://localhost:6006/ adresine gidin. Profil sekmesine gitmek için üstteki açılır menüyü kullanın. Profili Yakala'ya tıklayın ve Tensorflow Sunumunun gRPC sunucusunun adresini girin.
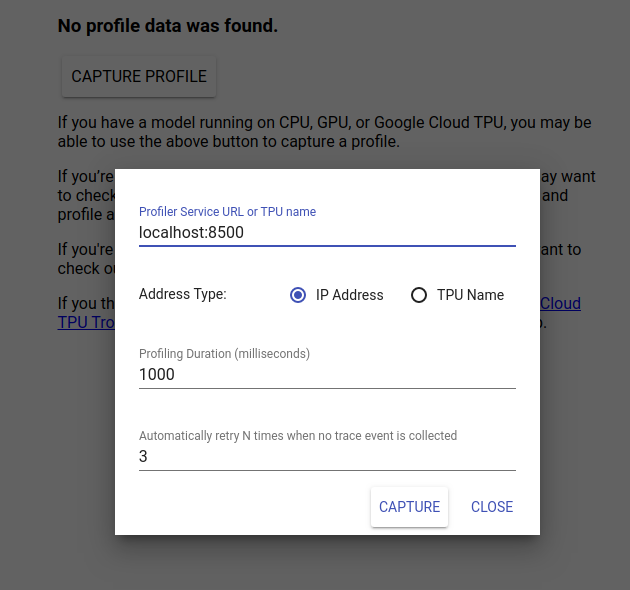
"Yakala" tuşuna bastığınız anda TensorBoard, model sunucusuna profil istekleri göndermeye başlayacaktır. Yukarıdaki iletişim kutusunda, hem her istek için son tarihi hem de hiçbir izleme olayı toplanmadığı takdirde Tensorboard'un toplam yeniden deneme sayısını ayarlayabilirsiniz. Pahalı bir modelin profilini çıkarıyorsanız profil isteğinin, çıkarım isteği tamamlanmadan önce zaman aşımına uğramamasını sağlamak için son tarihi artırmak isteyebilirsiniz.
Çıkarım İsteği Gönderin ve Profilini Oluşturun
TensorBoard kullanıcı arayüzünde Yakala'ya basın ve ardından hızlı bir şekilde TF Hizmetine bir çıkarım isteği gönderin.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
"Profili başarıyla yakaladı. Lütfen yenileyin" mesajını görmelisiniz. Tost ekranın alt kısmında görünür. Bu, TensorBoard'un TensorFlow Serving'den izleme olaylarını alabildiği ve bunları logdir kaydedebildiği anlamına gelir. Bir sonraki bölümde görüldüğü gibi, The Profiler's Trace Viewer ile çıkarım isteğini görselleştirmek için sayfayı yenileyin.
Çıkarım İsteği İzlemesini Analiz Etme

Çıkarım isteğiniz sonucunda hangi hesaplamanın gerçekleştiğini artık kolayca görebilirsiniz. Kesin başlangıç zamanı ve duvar süresi gibi daha fazla bilgi almak için dikdörtgenlerden herhangi birini (izleme olayları) yakınlaştırıp tıklayabilirsiniz.
Yüksek düzeyde, TensorFlow çalışma zamanına ait iki iş parçacığı ve REST sunucusuna ait olan üçüncü bir iş parçacığının HTTP isteğinin alınmasını ele aldığını ve bir TensorFlow Oturumu oluşturduğunu görüyoruz.
SessionRun'un içinde neler olduğunu görmek için yakınlaştırabiliriz.

İkinci iş parçacığında, hiçbir TensorFlow işleminin çalıştırılmadığı ancak başlatma adımlarının yürütüldüğü bir başlangıç ExecutorState::Process çağrısı görüyoruz.
İlk başlıkta, ilk değişkeni okuma çağrısını görüyoruz ve ikinci değişken de mevcut olduğunda, çarpma işlemini gerçekleştiriyor ve sırayla çekirdekleri ekliyor. Son olarak Yürütücü, DoneCallback'i çağırarak hesaplamasının yapıldığını ve Oturumun kapatılabileceğini bildirir.
Sonraki Adımlar
Bu basit bir örnek olsa da, çok daha karmaşık modellerin profilini çıkarmak için aynı işlemi kullanabilirsiniz; bu, model mimarinizdeki yavaş işlemleri veya darboğazları belirleyerek performansını artırmanıza olanak tanır.
Çıkarım performansını optimize etme hakkında daha fazla bilgi edinmek için lütfen TensorBoard Profiler'ın özellikleri hakkında daha kapsamlı bir eğitim için TensorBoard Profiler Kılavuzu'na ve TensorFlow Hizmet Performansı Kılavuzu'na bakın.