
Depois de implantar o TensorFlow Serving e emitir solicitações do seu cliente, você poderá perceber que as solicitações demoram mais do que o esperado ou você não está atingindo a taxa de transferência desejada.
Neste guia, usaremos o Profiler do TensorBoard, que você já pode usar para criar perfil de treinamento de modelo , para rastrear solicitações de inferência para nos ajudar a depurar e melhorar o desempenho da inferência.
Você deve usar este guia em conjunto com as práticas recomendadas indicadas no Guia de desempenho para otimizar seu modelo, solicitações e instância do TensorFlow Serving.
Visão geral
Em um nível superior, apontaremos a ferramenta de criação de perfil do TensorBoard para o servidor gRPC do TensorFlow Serving. Quando enviamos uma solicitação de inferência para o Tensorflow Serving, também usaremos simultaneamente a IU do TensorBoard para solicitar a captura dos rastreamentos dessa solicitação. Nos bastidores, o TensorBoard conversará com o TensorFlow Serving por meio de gRPC e solicitará que ele forneça um rastreamento detalhado do tempo de vida da solicitação de inferência. O TensorBoard irá então visualizar a atividade de cada thread em cada dispositivo de computação (executando código integrado com profiler::TraceMe ) ao longo do tempo de vida da solicitação na UI do TensorBoard para consumirmos.
Pré-requisitos
-
Tensorflow>=2.0.0 - TensorBoard (deve ser instalado se o TF foi instalado via
pip) - Docker (que usaremos para baixar e executar TF servindo>=imagem 2.1.0)
Implantar modelo com TensorFlow Serving
Para este exemplo, usaremos o Docker, a maneira recomendada de implantar o Tensorflow Serving, para hospedar um modelo de brinquedo que calcula f(x) = x / 2 + 2 encontrado no repositório Tensorflow Serving Github .
Baixe a fonte do TensorFlow Serving.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Inicie o TensorFlow Serving via Docker e implante o modelo half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
Em outro terminal, consulte o modelo para garantir que o modelo seja implantado corretamente
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
Configure o perfil do TensorBoard
Em outro terminal, inicie a ferramenta TensorBoard em sua máquina, fornecendo um diretório para salvar os eventos de rastreamento de inferência em:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
Navegue para http://localhost:6006/ para visualizar a IU do TensorBoard. Use o menu suspenso na parte superior para navegar até a guia Perfil. Clique em Capturar perfil e forneça o endereço do servidor gRPC do Tensorflow Serving.
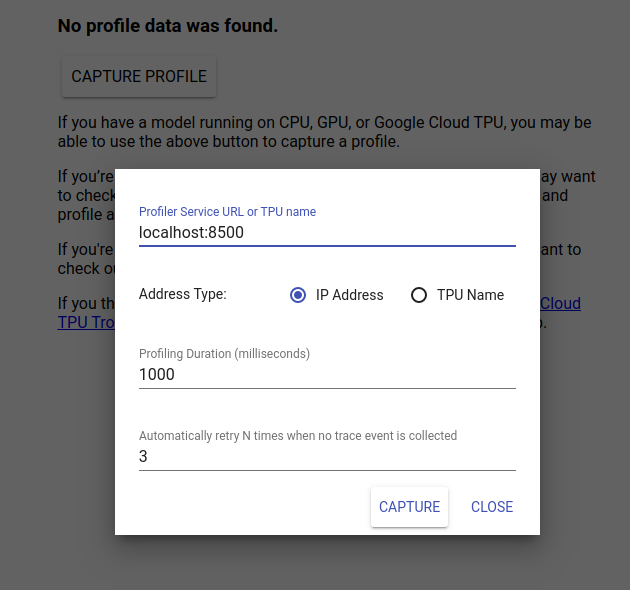
Assim que você pressionar “Capturar”, o TensorBoard começará a enviar solicitações de perfil ao servidor modelo. Na caixa de diálogo acima, você pode definir o prazo para cada solicitação e o número total de vezes que o Tensorboard tentará novamente se nenhum evento de rastreamento for coletado. Se você estiver criando o perfil de um modelo caro, talvez queira aumentar o prazo para garantir que a solicitação de perfil não expire antes da conclusão da solicitação de inferência.
Enviar e traçar o perfil de uma solicitação de inferência
Pressione Capturar na IU do TensorBoard e envie uma solicitação de inferência para o TF Serving rapidamente depois disso.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
Você deverá ver a mensagem "Capturar perfil com sucesso. Atualize". brinde aparece na parte inferior da tela. Isso significa que o TensorBoard foi capaz de recuperar eventos de rastreamento do TensorFlow Serving e salvá-los em seu logdir . Atualize a página para visualizar a solicitação de inferência com o Trace Viewer do Profiler, conforme visto na próxima seção.
Analise o rastreamento da solicitação de inferência

Agora você pode ver facilmente qual cálculo está ocorrendo como resultado de sua solicitação de inferência. Você pode ampliar e clicar em qualquer um dos retângulos (eventos de rastreamento) para obter mais informações, como hora exata de início e duração da parede.
Em alto nível, vemos dois threads pertencentes ao tempo de execução do TensorFlow e um terceiro que pertence ao servidor REST, manipulando o recebimento da solicitação HTTP e criando uma sessão do TensorFlow.
Podemos ampliar para ver o que acontece dentro do SessionRun.

No segundo thread, vemos uma chamada ExecutorState::Process inicial na qual nenhuma operação do TensorFlow é executada, mas as etapas de inicialização são executadas.
No primeiro thread, vemos a chamada para ler a primeira variável, e uma vez que a segunda variável também esteja disponível, executa a multiplicação e adiciona os kernels em sequência. Finalmente, o Executor sinaliza que seu cálculo foi feito chamando DoneCallback e a Sessão pode ser encerrada.
Próximas etapas
Embora este seja um exemplo simples, você pode usar o mesmo processo para criar o perfil de modelos muito mais complexos, permitindo identificar operações lentas ou gargalos na arquitetura do seu modelo para melhorar seu desempenho.
Consulte o TensorBoard Profiler Guide para obter um tutorial mais completo sobre os recursos do TensorBoard Profiler e do TensorFlow Serving Performance Guide para saber mais sobre como otimizar o desempenho de inferência.