
TensorFlow Serving을 배포하고 클라이언트에서 요청을 실행한 후 요청이 예상보다 오래 걸리거나 원하는 처리량을 달성하지 못하는 것을 확인할 수 있습니다.
이 가이드에서는 이미 모델 교육을 프로파일링 하는 데 사용할 수 있는 TensorBoard의 프로파일러를 사용하여 추론 요청을 추적하여 추론 성능을 디버그하고 개선하는 데 도움을 드립니다.
모델, 요청 및 TensorFlow Serving 인스턴스를 최적화하려면 성능 가이드 에 표시된 모범 사례와 함께 이 가이드를 사용해야 합니다.
개요
높은 수준에서는 TensorFlow Serving의 gRPC 서버에서 TensorBoard의 프로파일링 도구를 가리킵니다. Tensorflow Serving에 추론 요청을 보낼 때 동시에 TensorBoard UI를 사용하여 이 요청의 추적을 캡처하도록 요청합니다. 뒤에서 TensorBoard는 gRPC를 통해 TensorFlow Serving과 통신하고 추론 요청의 수명에 대한 자세한 추적을 제공하도록 요청합니다. 그런 다음 TensorBoard는 우리가 사용할 TensorBoard UI의 요청 수명 동안 모든 컴퓨팅 장치( profiler::TraceMe 와 통합된 코드 실행)의 모든 스레드 활동을 시각화합니다.
전제 조건
-
Tensorflow>=2.0.0 - TensorBoard(TF가
pip통해 설치된 경우 설치되어야 함) - Docker(TF 제공>=2.1.0 이미지를 다운로드하고 실행하는 데 사용)
TensorFlow Serving을 사용하여 모델 배포
이 예에서는 Tensorflow Serving을 배포하는 권장 방법인 Docker를 사용하여 Tensorflow Serving Github 저장소 에 있는 f(x) = x / 2 + 2 계산하는 장난감 모델을 호스팅합니다.
TensorFlow Serving 소스를 다운로드하세요.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Docker를 통해 TensorFlow Serving을 시작하고 half_plus_two 모델을 배포하세요.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
다른 터미널에서 모델을 쿼리하여 모델이 올바르게 배포되었는지 확인하세요.
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
TensorBoard의 프로파일러 설정
다른 터미널에서 머신의 TensorBoard 도구를 실행하여 추론 추적 이벤트를 저장할 디렉터리를 제공합니다.
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
TensorBoard UI를 보려면 http://localhost:6006/으로 이동하세요. 상단의 드롭다운 메뉴를 사용하여 프로필 탭으로 이동합니다. 프로필 캡처를 클릭하고 Tensorflow Serving의 gRPC 서버 주소를 제공하세요.
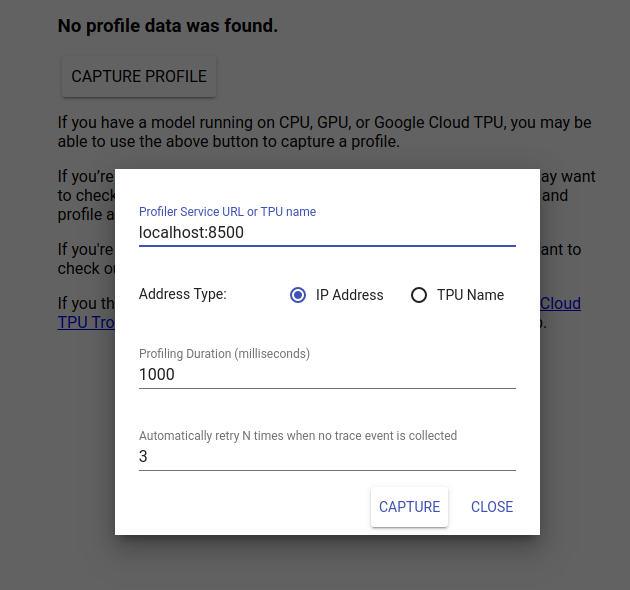
"캡처"를 누르자마자 TensorBoard는 모델 서버에 프로필 요청을 보내기 시작합니다. 위 대화 상자에서는 각 요청의 기한과 추적 이벤트가 수집되지 않을 경우 Tensorboard가 재시도할 총 횟수를 모두 설정할 수 있습니다. 비용이 많이 드는 모델을 프로파일링하는 경우 추론 요청이 완료되기 전에 프로파일 요청 시간이 초과되지 않도록 기한을 늘릴 수 있습니다.
추론 요청 보내기 및 프로파일링
TensorBoard UI에서 Capture를 누르고 그 후 빠르게 TF Serving에 추론 요청을 보냅니다.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
"프로필을 성공적으로 캡처했습니다. 새로 고치십시오."라는 메시지가 표시됩니다. 화면 하단에 토스트가 나타납니다. 이는 TensorBoard가 TensorFlow Serving에서 추적 이벤트를 검색하여 logdir 에 저장할 수 있음을 의미합니다. 다음 섹션에 표시된 대로 페이지를 새로 고쳐 프로파일러의 추적 뷰어로 추론 요청을 시각화합니다.
추론 요청 추적 분석

이제 추론 요청의 결과로 어떤 계산이 진행되고 있는지 쉽게 확인할 수 있습니다. 직사각형(추적 이벤트) 중 하나를 확대/축소하고 클릭하면 정확한 시작 시간 및 벽 지속 시간과 같은 추가 정보를 얻을 수 있습니다.
상위 수준에서 우리는 TensorFlow 런타임에 속하는 두 개의 스레드와 REST 서버에 속하는 세 번째 스레드를 볼 수 있으며, HTTP 요청 수신을 처리하고 TensorFlow 세션을 생성합니다.
SessionRun 내부에서 무슨 일이 일어나는지 확대해서 볼 수 있습니다.

두 번째 스레드에서는 TensorFlow 작업이 실행되지 않지만 초기화 단계가 실행되는 초기 ExecutorState::Process 호출을 볼 수 있습니다.
첫 번째 스레드에서는 첫 번째 변수를 읽는 호출을 볼 수 있으며 두 번째 변수도 사용할 수 있게 되면 곱셈을 실행하고 순서대로 커널을 추가합니다. 마지막으로 Executor는 DoneCallback을 호출하여 계산이 완료되고 세션을 닫을 수 있다는 신호를 보냅니다.
다음 단계
이는 단순한 예이지만 동일한 프로세스를 사용하여 훨씬 더 복잡한 모델을 프로파일링할 수 있으므로 모델 아키텍처에서 느린 작업이나 병목 현상을 식별하여 성능을 향상시킬 수 있습니다.
추론 성능 최적화에 대해 자세히 알아보려면 TensorBoard의 프로파일러 및 TensorFlow Serving Performance Guide 기능에 대한 보다 완전한 튜토리얼을 보려면 TensorBoard Profiler Guide 를 참조하세요.