
TensorFlow Serving をデプロイし、クライアントからリクエストを発行した後、リクエストに予想よりも時間がかかるか、期待していたスループットが達成されていないことに気づく場合があります。
このガイドでは、モデル トレーニングのプロファイリングにすでに使用している TensorBoard のプロファイラーを使用して、推論リクエストを追跡し、デバッグと推論パフォーマンスの向上に役立てます。
モデル、リクエスト、TensorFlow Serving インスタンスを最適化するには、このガイドをパフォーマンス ガイドに記載されているベスト プラクティスと組み合わせて使用する必要があります。
概要
大まかに言うと、TensorBoard のプロファイリング ツールを TensorFlow Serving の gRPC サーバーに向けます。 Tensorflow Serving に推論リクエストを送信するとき、同時に TensorBoard UI を使用して、このリクエストのトレースをキャプチャするように要求します。 TensorBoard は舞台裏で gRPC 経由で TensorFlow Serving と通信し、推論リクエストの存続期間の詳細なトレースを提供するように依頼します。 TensorBoard は、TensorBoard UI 上のリクエストの有効期間全体にわたって、すべてのコンピューティング デバイス上のすべてのスレッド ( profiler::TraceMeと統合されたコードを実行している) のアクティビティを視覚化し、利用できるようにします。
前提条件
Tensorflow>=2.0.0- TensorBoard (TF が
pip経由でインストールされた場合にインストールする必要があります) - Docker (TF Serving>=2.1.0 イメージをダウンロードして実行するために使用します)
TensorFlow Serving を使用してモデルをデプロイする
この例では、Tensorflow Serving のデプロイに推奨される方法である Docker を使用して、 Tensorflow Serving Github リポジトリにあるf(x) = x / 2 + 2を計算するおもちゃのモデルをホストします。
TensorFlow Serving ソースをダウンロードします。
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Docker 経由で TensorFlow Serving を起動し、half_plus_two モデルをデプロイします。
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
別のターミナルでモデルをクエリして、モデルが正しくデプロイされていることを確認します。
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
TensorBoard のプロファイラーをセットアップする
別のターミナルで、マシン上の TensorBoard ツールを起動し、推論トレース イベントを保存するディレクトリを提供します。
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
http://localhost:6006/ に移動して TensorBoard UI を表示します。上部のドロップダウン メニューを使用して、[プロファイル] タブに移動します。 [Capture Profile] をクリックし、Tensorflow Serving の gRPC サーバーのアドレスを指定します。
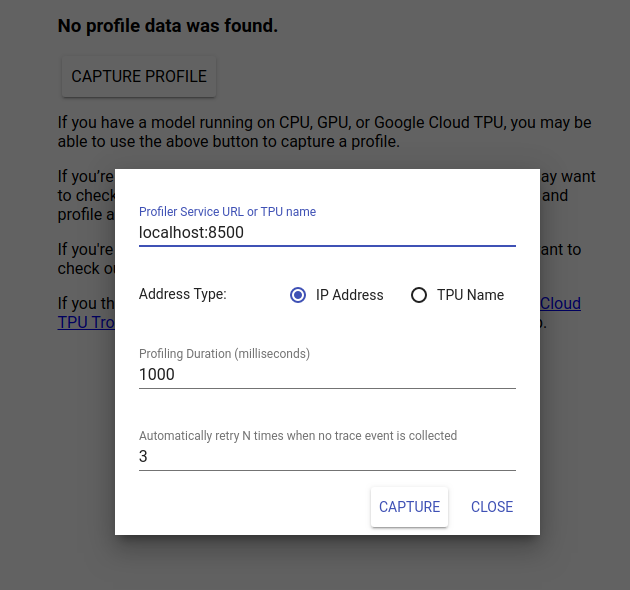
「Capture」を押すとすぐに、TensorBoard はモデル サーバーへのプロファイル リクエストの送信を開始します。上のダイアログでは、各リクエストの期限と、トレース イベントが収集されなかった場合に Tensorboard が再試行する合計回数の両方を設定できます。高価なモデルをプロファイリングしている場合は、推論リクエストが完了する前にプロファイル リクエストがタイムアウトしないように、期限を長くすることができます。
推論リクエストの送信とプロファイリング
TensorBoard UI で Capture を押し、その後すぐに推論リクエストを TF Serving に送信します。
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
「プロファイルが正常にキャプチャされました。更新してください。」というメッセージが表示されます。画面の下部にトーストが表示されます。これは、TensorBoard が TensorFlow Serving からトレース イベントを取得し、それらをlogdirに保存できたことを意味します。次のセクションで説明するように、ページを更新して、プロファイラーのトレース ビューアーを使用して推論リクエストを視覚化します。
推論リクエストトレースを分析する

推論リクエストの結果としてどのような計算が行われているかを簡単に確認できるようになりました。任意の四角形 (イベントのトレース) をズームしてクリックすると、正確な開始時間や壁の継続時間などの詳細情報を取得できます。
高レベルでは、TensorFlow ランタイムに属する 2 つのスレッドと、REST サーバーに属する 3 番目のスレッドが、HTTP リクエストの受信を処理して TensorFlow セッションを作成していることがわかります。
ズームインして、SessionRun 内で何が起こっているかを確認できます。

2 番目のスレッドでは、TensorFlow 演算は実行されませんが、初期化ステップが実行される最初の ExecutorState::Process 呼び出しが見られます。
最初のスレッドでは、最初の変数を読み取る呼び出しが表示され、2 番目の変数も使用可能になると、乗算が実行され、カーネルが順番に追加されます。最後に、Executor は、DoneCallback を呼び出して計算が完了し、セッションを閉じることができることを通知します。
次のステップ
これは単純な例ですが、同じプロセスを使用してさらに複雑なモデルをプロファイリングすることができ、モデル アーキテクチャ内の遅い操作やボトルネックを特定してパフォーマンスを向上させることができます。
TensorBoard のプロファイラーの機能に関するより完全なチュートリアルについてはTensorBoard Profiler Guideを、推論パフォーマンスの最適化の詳細についてはTensorFlow Serving Performance Guideを参照してください。