
TensorFlow सर्विंग को तैनात करने और अपने क्लाइंट से अनुरोध जारी करने के बाद, आप देख सकते हैं कि अनुरोधों में आपकी अपेक्षा से अधिक समय लग रहा है, या आप वह थ्रूपुट प्राप्त नहीं कर रहे हैं जो आप चाहते थे।
इस गाइड में, हम डिबग करने और अनुमान प्रदर्शन को बेहतर बनाने में मदद करने के लिए अनुमान अनुरोधों का पता लगाने के लिए, टेन्सरबोर्ड के प्रोफाइलर का उपयोग करेंगे, जिसका उपयोग आप पहले से ही प्रोफाइल मॉडल प्रशिक्षण के लिए कर सकते हैं।
आपको अपने मॉडल, अनुरोधों और TensorFlow सर्विंग इंस्टेंस को अनुकूलित करने के लिए प्रदर्शन गाइड में बताई गई सर्वोत्तम प्रथाओं के साथ इस गाइड का उपयोग करना चाहिए।
सिंहावलोकन
उच्च स्तर पर, हम TensorBoard के प्रोफाइलिंग टूल को TensorFlow सर्विंग के gRPC सर्वर पर इंगित करेंगे। जब हम Tensorflow सर्विंग के लिए एक अनुमान अनुरोध भेजते हैं, तो हम साथ ही TensorBoard UI का उपयोग करके उसे इस अनुरोध के निशान कैप्चर करने के लिए कहेंगे। पर्दे के पीछे, TensorBoard gRPC पर TensorFlow सर्विंग से बात करेगा और उसे अनुमान अनुरोध के जीवनकाल का विस्तृत विवरण प्रदान करने के लिए कहेगा। फिर TensorBoard हमारे उपभोग के लिए TensorBoard UI पर अनुरोध के जीवनकाल के दौरान प्रत्येक कंप्यूट डिवाइस ( profiler::TraceMe के साथ एकीकृत रनिंग कोड) पर प्रत्येक थ्रेड की गतिविधि की कल्पना करेगा।
आवश्यक शर्तें
-
Tensorflow>=2.0.0 - TensorBoard (यदि TF को
pipके माध्यम से स्थापित किया गया था तो स्थापित किया जाना चाहिए) - डॉकर (जिसका उपयोग हम टीएफ सर्विंग>=2.1.0 छवि को डाउनलोड करने और चलाने के लिए करेंगे)
TensorFlow सर्विंग के साथ मॉडल परिनियोजित करें
इस उदाहरण के लिए, हम एक खिलौना मॉडल को होस्ट करने के लिए, टेन्सरफ़्लो सर्विंग को तैनात करने के लिए अनुशंसित तरीके डॉकर का उपयोग करेंगे, जो टेन्सरफ़्लो सर्विंग जीथब रिपॉजिटरी में पाए जाने वाले f(x) = x / 2 + 2 की गणना करता है।
TensorFlow सर्विंग स्रोत डाउनलोड करें।
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
डॉकर के माध्यम से टेन्सरफ्लो सर्विंग लॉन्च करें और हाफ_प्लस_टू मॉडल को तैनात करें।
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
दूसरे टर्मिनल में, यह सुनिश्चित करने के लिए मॉडल को क्वेरी करें कि मॉडल सही ढंग से तैनात है
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
TensorBoard का प्रोफाइलर सेट करें
दूसरे टर्मिनल में, अपनी मशीन पर टेन्सरबोर्ड टूल लॉन्च करें, जो अनुमान ट्रेस घटनाओं को सहेजने के लिए एक निर्देशिका प्रदान करता है:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
TensorBoard UI देखने के लिए http://localhost:6006/ पर जाएँ। प्रोफ़ाइल टैब पर नेविगेट करने के लिए शीर्ष पर ड्रॉप-डाउन मेनू का उपयोग करें। प्रोफ़ाइल कैप्चर करें पर क्लिक करें और Tensorflow सर्विंग के gRPC सर्वर का पता प्रदान करें।
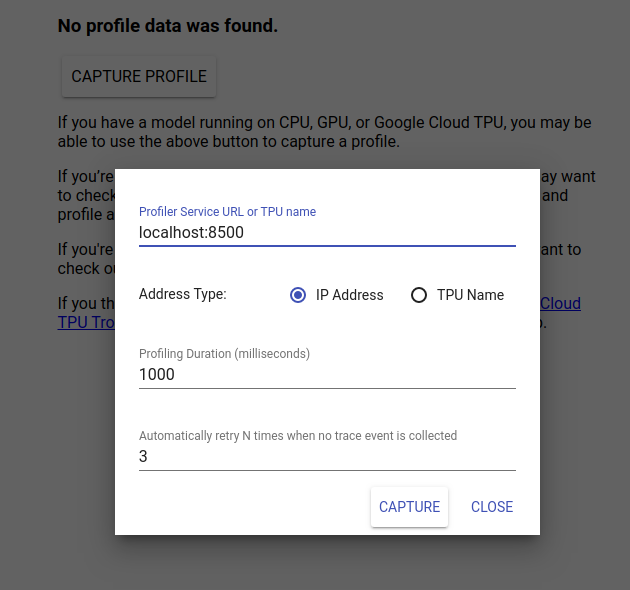
जैसे ही आप "कैप्चर" दबाते हैं, TensorBoard मॉडल सर्वर पर प्रोफ़ाइल अनुरोध भेजना शुरू कर देगा। ऊपर दिए गए संवाद में, आप प्रत्येक अनुरोध के लिए समय सीमा और कोई ट्रेस इवेंट एकत्र नहीं होने पर टेन्सरबोर्ड द्वारा पुनः प्रयास किए जाने की कुल संख्या दोनों निर्धारित कर सकते हैं। यदि आप एक महंगे मॉडल की प्रोफाइलिंग कर रहे हैं, तो आप यह सुनिश्चित करने के लिए समय सीमा बढ़ाना चाह सकते हैं कि प्रोफाइल अनुरोध का समय अनुमान अनुरोध पूरा होने से पहले समाप्त न हो जाए।
एक अनुमान अनुरोध भेजें और प्रोफाइल करें
TensorBoard UI पर कैप्चर दबाएँ और उसके तुरंत बाद TF सर्विंग को एक अनुमान अनुरोध भेजें।
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
आपको "प्रोफ़ाइल सफलतापूर्वक कैप्चर करें। कृपया ताज़ा करें" देखना चाहिए। टोस्ट स्क्रीन के नीचे दिखाई देता है। इसका मतलब है कि TensorBoard TensorFlow सर्विंग से ट्रेस इवेंट को पुनः प्राप्त करने में सक्षम था और उन्हें आपके logdir में सहेजा था। द प्रोफाइलर ट्रेस व्यूअर के साथ अनुमान अनुरोध को देखने के लिए पेज को रीफ्रेश करें, जैसा कि अगले भाग में देखा गया है।
अनुमान अनुरोध ट्रेस का विश्लेषण करें

अब आप आसानी से देख सकते हैं कि आपके अनुमान अनुरोध के परिणामस्वरूप क्या गणना हो रही है। सटीक प्रारंभ समय और दीवार अवधि जैसी अधिक जानकारी प्राप्त करने के लिए आप किसी भी आयत पर ज़ूम और क्लिक कर सकते हैं (घटनाओं का पता लगा सकते हैं)।
उच्च-स्तर पर, हम TensorFlow रनटाइम से संबंधित दो थ्रेड देखते हैं और तीसरा REST सर्वर से संबंधित होता है, जो HTTP अनुरोध प्राप्त करने और TensorFlow सत्र बनाने का प्रबंधन करता है।
हम यह देखने के लिए ज़ूम इन कर सकते हैं कि सेशन रन के अंदर क्या होता है।

दूसरे थ्रेड में, हम एक प्रारंभिक ExecutorState::Process कॉल देखते हैं जिसमें कोई TensorFlow ऑप्स नहीं चलता है लेकिन आरंभीकरण चरण निष्पादित होते हैं।
पहले थ्रेड में, हम पहले वेरिएबल को पढ़ने के लिए कॉल देखते हैं, और एक बार दूसरा वेरिएबल भी उपलब्ध होने पर, गुणन निष्पादित करता है और क्रम में कर्नेल जोड़ता है। अंत में, निष्पादक संकेत देता है कि इसकी गणना DoneCallback को कॉल करके की गई है और सत्र को बंद किया जा सकता है।
अगले कदम
हालांकि यह एक सरल उदाहरण है, आप अधिक जटिल मॉडलों को प्रोफाइल करने के लिए उसी प्रक्रिया का उपयोग कर सकते हैं, जिससे आप अपने मॉडल आर्किटेक्चर में धीमे ऑप्स या बाधाओं की पहचान करके इसके प्रदर्शन को बेहतर बना सकते हैं।
कृपया अनुमान प्रदर्शन को अनुकूलित करने के बारे में अधिक जानने के लिए TensorBoard के प्रोफाइलर और TensorFlow सर्विंग प्रदर्शन गाइड की विशेषताओं पर अधिक संपूर्ण ट्यूटोरियल के लिए TensorBoard प्रोफाइलर गाइड देखें।