
Производительность TensorFlow Serving во многом зависит от приложения, которое оно запускает, среды, в которой оно развернуто, и другого программного обеспечения, с которым оно разделяет доступ к базовым аппаратным ресурсам. Таким образом, настройка его производительности в некоторой степени зависит от конкретного случая, и существует очень мало универсальных правил, которые гарантированно обеспечат оптимальную производительность при любых настройках. С учетом вышесказанного, этот документ призван охватить некоторые общие принципы и лучшие практики для запуска TensorFlow Serving.
Используйте руководство «Запросы на вывод профиля с TensorBoard» , чтобы понять основное поведение вычислений вашей модели при запросах на вывод, и используйте это руководство для итеративного улучшения ее производительности.
Быстрые советы
- Задержка первого запроса слишком велика? Включите прогрев модели .
- Заинтересованы в более высоком использовании ресурсов или пропускной способности? Настройка пакетной обработки
Настройка производительности: цели и параметры
При точной настройке производительности TensorFlow Serving обычно есть два типа целей и три группы параметров, которые нужно настроить для улучшения этих целей.
Цели
TensorFlow Serving — это онлайн-система обслуживания моделей с машинным обучением. Как и во многих других системах онлайн-обслуживания, ее основная цель производительности — максимизировать пропускную способность, сохраняя при этом задержку ниже определенных границ . В зависимости от деталей и зрелости вашего приложения вас может больше интересовать средняя задержка, чем хвостовая задержка , но некоторые понятия о задержке и пропускной способности обычно являются показателями, на основе которых вы устанавливаете целевые показатели производительности. Обратите внимание: в этом руководстве мы не обсуждаем доступность, поскольку это скорее функция среды развертывания.
Параметры
Мы можем грубо представить себе три группы параметров, конфигурация которых определяет наблюдаемую производительность: 1) модель TensorFlow, 2) запросы вывода и 3) сервер (аппаратный и двоичный).
1) Модель TensorFlow
Модель определяет вычисления, которые TensorFlow Serving будет выполнять при получении каждого входящего запроса.
Под капотом TensorFlow Serving использует среду выполнения TensorFlow для выполнения фактических выводов по вашим запросам. Это означает, что средняя задержка обслуживания запроса с помощью TensorFlow Serving обычно равна, как минимум, задержке выполнения вывода непосредственно с помощью TensorFlow. Это означает, что если на данной машине вывод для одного примера занимает 2 секунды, и у вас есть целевая задержка в доли секунды, вам необходимо профилировать запросы на вывод, понимать, какие операции TensorFlow и подграфики вашей модели больше всего способствуют этой задержке. и перепроектируйте свою модель, принимая во внимание задержку вывода в качестве конструктивного ограничения.
Обратите внимание: хотя средняя задержка выполнения вывода с помощью TensorFlow Serving обычно не ниже, чем при непосредственном использовании TensorFlow, преимуществом TensorFlow Serving является сокращение хвостовой задержки для многих клиентов, запрашивающих множество различных моделей, при этом эффективно используя базовое оборудование для максимизации пропускной способности. .
2) Запросы на вывод
API-поверхности
TensorFlow Serving имеет две поверхности API (HTTP и gRPC), обе из которых реализуют API PredictionService (за исключением HTTP-сервера, не предоставляющего конечную точку MultiInference ). Обе поверхности API тщательно настроены и обеспечивают минимальную задержку, но на практике поверхность gRPC оказывается немного более производительной.
Методы API
В общем, рекомендуется использовать конечные точки Classify и Regress, поскольку они принимают tf.Example , который является абстракцией более высокого уровня; однако в редких случаях больших (O(Mb)) структурированных запросов опытные пользователи могут обнаружить использование PredictRequest и прямое кодирование своих сообщений Protobuf в TensorProto, а также пропуск сериализации и десериализации из tf.Example, как источник небольшого прироста производительности.
Размер партии
Есть два основных способа, с помощью которых пакетная обработка может повысить производительность. Вы можете настроить своих клиентов на отправку пакетных запросов в TensorFlow Serving или вы можете отправлять отдельные запросы и настроить TensorFlow Serving на ожидание в течение заранее определенного периода времени и выполнять логический вывод по всем запросам, которые поступают в этот период, в одном пакете. Настройка последнего типа пакетной обработки позволяет достичь чрезвычайно высокого количества запросов в секунду при обслуживании TensorFlow, одновременно позволяя ему сублинейно масштабировать вычислительные ресурсы, необходимые для поддержания производительности. Подробнее это обсуждается в руководстве по настройке и README для пакетной обработки .
3) Сервер (аппаратный и двоичный)
Бинарный файл TensorFlow Serving довольно точно учитывает оборудование, на котором он работает. Таким образом, вам следует избегать запуска других приложений, интенсивно использующих вычислительные ресурсы или память, на одном компьютере, особенно с динамическим использованием ресурсов.
Как и во многих других типах рабочих нагрузок, обслуживание TensorFlow более эффективно при развертывании на меньшем количестве более крупных (с большим количеством ЦП и ОЗУ) компьютеров (т. е. Deployment с меньшим количеством replicas в терминах Kubernetes). Это связано с лучшим потенциалом мультитенантного развертывания для использования оборудования и меньшими фиксированными затратами (сервер RPC, среда выполнения TensorFlow и т. д.).
Ускорители
Если у вашего хоста есть доступ к ускорителю, убедитесь, что вы реализовали свою модель для размещения плотных вычислений в ускорителе — это должно быть сделано автоматически, если вы использовали API-интерфейсы TensorFlow высокого уровня, но если вы создали собственные графики или хотите закрепить определенные части графиков на определенных ускорителях, вам может потребоваться вручную разместить определенные подграфы на ускорителях (т. е with tf.device('/device:GPU:0'): ... ).
Современные процессоры
Современные процессоры постоянно расширяют архитектуру набора команд x86 для улучшения поддержки SIMD (одна инструкция для нескольких данных) и других функций, критически важных для плотных вычислений (например, умножение и сложение за один такт). Однако для работы на немного более старых машинах TensorFlow и TensorFlow Serving созданы с скромным предположением, что новейшие из этих функций не поддерживаются центральным процессором.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Если вы видите эту запись журнала (возможно, расширения, отличные от двух перечисленных) при запуске TensorFlow Serving, это означает, что вы можете перестроить TensorFlow Serving и настроить таргетинг на платформу вашего конкретного хоста и добиться более высокой производительности. Создать TensorFlow Serving из исходного кода относительно легко с помощью Docker и описано здесь .
Бинарная конфигурация
TensorFlow Serving предлагает ряд настроек конфигурации, которые управляют его поведением во время выполнения, в основном задаваемые с помощью флагов командной строки . Некоторые из них (особенно tensorflow_intra_op_parallelism и tensorflow_inter_op_parallelism ) передаются для настройки среды выполнения TensorFlow и настраиваются автоматически, что опытные пользователи могут переопределить, проведя множество экспериментов и найдя правильную конфигурацию для своей конкретной рабочей нагрузки и среды.
Срок службы запроса вывода TensorFlow Serving
Давайте кратко пройдемся по жизни прототипного примера запроса на вывод TensorFlow Serving, чтобы увидеть путь, который проходит типичный запрос. В нашем примере мы углубимся в запрос прогнозирования, получаемый поверхностью API gRPC TensorFlow 2.0.0.
Давайте сначала посмотрим на диаграмму последовательности на уровне компонентов, а затем перейдем к коду, реализующему эту серию взаимодействий.
Диаграмма последовательности
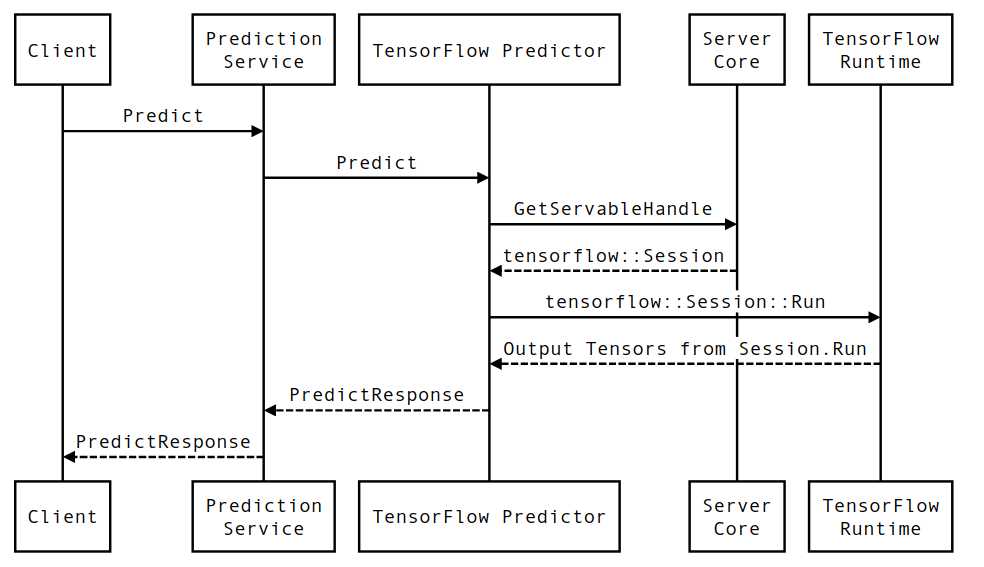
Обратите внимание, что Client — это компонент, принадлежащий пользователю, Служба прогнозирования, Servables и Server Core принадлежат TensorFlow Serving, а TensorFlow Runtime принадлежит Core TensorFlow .
Детали последовательности
-
PredictionServiceImpl::PredictполучаетPredictRequest - Мы вызываем
TensorflowPredictor::Predict, распространяя крайний срок запроса из запроса gRPC (если он был установлен). - Внутри
TensorflowPredictor::Predictмы ищем Servable (модель), для которой запрос хочет выполнить вывод, из которого мы получаем информацию о SavedModel и, что более важно, дескриптор объектаSession, в котором находится граф модели (возможно, частично). загружен. Этот объект Servable был создан и зафиксирован в памяти, когда модель была загружена с помощью TensorFlow Serving. Затем мы вызываем Internal::RunPredict для выполнения прогноза. - Во
internal::RunPredictпосле проверки и предварительной обработки запроса мы используем объектSessionдля выполнения вывода с помощью блокирующего вызова Session::Run , после чего мы входим в базовую кодовую базу TensorFlow. После того, какSession::Runвозвращается и нашиoutputsтензоры заполнены, мы преобразуем выходные данные вPredictionResponseи возвращаем результат в стек вызовов.