
TensorFlow Serving의 성능은 실행되는 애플리케이션, 배포되는 환경, 기본 하드웨어 리소스에 대한 액세스를 공유하는 기타 소프트웨어에 따라 크게 달라집니다. 따라서 성능 조정은 사례에 따라 다소 다르며 모든 설정에서 최적의 성능을 보장하는 보편적인 규칙은 거의 없습니다. 따라서 이 문서는 TensorFlow Serving을 실행하기 위한 몇 가지 일반적인 원칙과 모범 사례를 포착하는 것을 목표로 합니다.
추론 요청에 대한 모델 계산의 기본 동작을 이해하려면 TensorBoard를 사용한 프로필 추론 요청 가이드를 사용하고, 이 가이드를 사용하여 성능을 반복적으로 개선하세요.
빠른 팁
성능 조정: 목표 및 매개변수
TensorFlow Serving의 성능을 미세 조정할 때 일반적으로 가질 수 있는 목표에는 2가지 유형이 있고 해당 목표를 개선하기 위해 조정할 매개변수 그룹은 3가지입니다.
목표
TensorFlow Serving은 기계 학습 모델을 위한 온라인 제공 시스템 입니다. 다른 많은 온라인 제공 시스템과 마찬가지로 기본 성능 목표는 처리량을 최대화하는 동시에 테일 지연 시간을 특정 범위 미만으로 유지하는 것 입니다. 애플리케이션의 세부 사항 및 성숙도에 따라 tail-latency 보다 평균 대기 시간에 더 관심을 가질 수 있지만, 대기 시간 및 처리량 에 대한 일부 개념은 일반적으로 성능 목표를 설정하는 지표입니다. 가용성은 배포 환경의 기능에 가깝기 때문에 이 가이드에서는 가용성에 대해 논의하지 않습니다.
매개변수
구성이 관찰된 성능을 결정하는 3가지 매개변수 그룹, 즉 1) TensorFlow 모델 2) 추론 요청 및 3) 서버(하드웨어 및 바이너리)에 대해 대략 생각해 볼 수 있습니다.
1) 텐서플로우 모델
모델은 TensorFlow Serving이 각 수신 요청을 수신할 때 수행할 계산을 정의합니다.
내부적으로 TensorFlow Serving은 TensorFlow 런타임을 사용하여 요청에 대한 실제 추론을 수행합니다. 이는 TensorFlow Serving으로 요청을 처리하는 평균 지연 시간이 일반적 으로 TensorFlow로 직접 추론을 수행하는 지연 시간과 비슷하다는 것을 의미합니다. 이는 특정 머신에서 단일 예시에 대한 추론이 2초가 걸리고 지연 시간 목표가 1초 미만인 경우 추론 요청을 프로파일링하고 모델의 TensorFlow 작업 및 하위 그래프가 해당 지연 시간에 가장 많이 기여하는 것이 무엇인지 이해해야 함을 의미합니다. , 설계 제약 조건을 염두에 두고 추론 지연 시간을 고려하여 모델을 다시 설계하세요.
TensorFlow Serving으로 추론을 수행하는 평균 지연 시간은 일반적으로 TensorFlow를 직접 사용하는 것보다 낮지 않지만 TensorFlow Serving의 장점은 기본 하드웨어를 효율적으로 활용하여 처리량을 최대화하는 동시에 다양한 모델을 쿼리하는 많은 클라이언트의 꼬리 지연 시간을 줄이는 것입니다. .
2) 추론 요청
API 표면
TensorFlow Serving에는 두 개의 API 표면(HTTP 및 gRPC)이 있으며 둘 다 PredictionService API를 구현합니다( MultiInference 엔드포인트를 노출하지 않는 HTTP 서버는 제외). 두 API 표면 모두 고도로 조정되어 대기 시간이 최소화되지만 실제로는 gRPC 표면의 성능이 약간 더 뛰어난 것으로 관찰됩니다.
API 메소드
일반적으로 더 높은 수준의 추상화인 tf.Example 을 허용하는 Classify 및 Regress 엔드포인트를 사용하는 것이 좋습니다. 그러나 드물게 대규모(O(Mb)) 구조적 요청의 경우 숙련된 사용자는 PredictRequest를 사용하고 Protobuf 메시지를 TensorProto로 직접 인코딩하고 tf.Example에서 직렬화 및 역직렬화를 건너뛰는 것이 약간의 성능 향상의 원인이라는 것을 알 수 있습니다.
배치 크기
일괄 처리가 성능에 도움이 되는 두 가지 기본 방법이 있습니다. TensorFlow Serving에 일괄 요청을 보내도록 클라이언트를 구성할 수도 있고, 개별 요청을 보내고 사전에 결정된 기간까지 대기하도록 TensorFlow Serving을 구성한 다음 해당 기간에 도착하는 모든 요청에 대해 하나의 일괄 처리로 추론을 수행하도록 구성할 수도 있습니다. 후자 종류의 일괄 처리를 구성하면 매우 높은 QPS에서 TensorFlow Serving을 달성하는 동시에 이를 유지하는 데 필요한 컴퓨팅 리소스를 준선형적으로 확장할 수 있습니다. 이에 대해서는 구성 가이드 및 일괄 처리 README 에서 자세히 설명합니다.
3) 서버(하드웨어 및 바이너리)
TensorFlow Serving 바이너리는 실행되는 하드웨어를 상당히 정확하게 계산합니다. 따라서 동일한 시스템에서 다른 컴퓨팅 또는 메모리 집약적 애플리케이션, 특히 동적 리소스 사용량이 있는 애플리케이션을 실행하지 않아야 합니다.
다른 많은 유형의 워크로드와 마찬가지로 TensorFlow Serving은 더 적고 더 큰(더 많은 CPU 및 RAM) 머신에 배포될 때(예: Kubernetes 용어로 replicas 더 적은 Deployment ) 더 효율적입니다. 이는 하드웨어를 활용하고 고정 비용(RPC 서버, TensorFlow 런타임 등)을 낮추기 위한 다중 테넌트 배포의 더 나은 잠재력 때문입니다.
가속기
호스트가 가속기에 액세스할 수 있는 경우 가속기에 밀도 높은 계산을 배치하도록 모델을 구현했는지 확인하세요. 이는 고급 TensorFlow API를 사용한 경우 자동으로 수행되어야 하지만 사용자 정의 그래프를 작성했거나 고정하려는 경우 특정 가속기에 있는 그래프의 특정 부분을 가속기에 수동으로 배치해야 할 수도 있습니다(예: with tf.device('/device:GPU:0'): ... 사용).
최신 CPU
최신 CPU는 SIMD (Single Instruction Multiple Data) 및 조밀한 계산에 중요한 기타 기능(예: 한 클럭 주기의 곱셈 및 덧셈)에 대한 지원을 개선하기 위해 x86 명령어 세트 아키텍처를 지속적으로 확장해 왔습니다. 그러나 약간 오래된 시스템에서 실행하기 위해 TensorFlow 및 TensorFlow Serving은 이러한 기능 중 최신 기능이 호스트 CPU에서 지원되지 않는다는 적당한 가정을 바탕으로 구축되었습니다.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
TensorFlow Serving 시작 시 이 로그 항목(나열된 2개와 다른 확장명일 수 있음)이 표시되면 TensorFlow Serving을 다시 빌드하고 특정 호스트 플랫폼을 대상으로 하며 더 나은 성능을 누릴 수 있다는 의미입니다. Docker를 사용하면 소스에서 TensorFlow Serving을 구축하는 것이 상대적으로 쉽고 여기에 문서화되어 있습니다.
바이너리 구성
TensorFlow Serving은 대부분 명령줄 플래그를 통해 설정되는 런타임 동작을 제어하는 다양한 구성 손잡이를 제공합니다. 이들 중 일부(특히 tensorflow_intra_op_parallelism 및 tensorflow_inter_op_parallelism )는 TensorFlow 런타임을 구성하기 위해 전달되고 자동 구성되며, 숙련된 사용자는 많은 실험을 수행하고 특정 워크로드 및 환경에 적합한 구성을 찾아 재정의할 수 있습니다.
TensorFlow Serving 추론 요청의 수명
일반적인 요청이 거치는 여정을 살펴보기 위해 TensorFlow Serving 추론 요청의 프로토타입 예제를 간략하게 살펴보겠습니다. 이 예에서는 2.0.0 TensorFlow Serving gRPC API 표면에서 수신되는 예측 요청을 자세히 살펴보겠습니다.
먼저 구성 요소 수준 시퀀스 다이어그램을 살펴본 다음 이러한 일련의 상호 작용을 구현하는 코드로 이동해 보겠습니다.
시퀀스 다이어그램
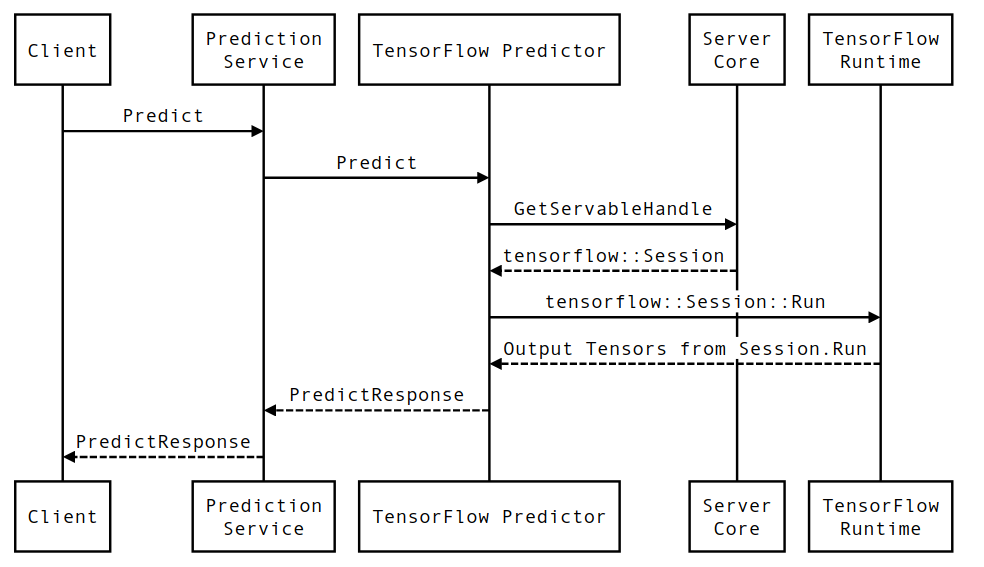
Client는 사용자가 소유한 구성 요소이고 Prediction Service, Servables 및 Server Core는 TensorFlow Serving이 소유하고 TensorFlow Runtime은 Core TensorFlow 가 소유합니다.
시퀀스 세부정보
-
PredictionServiceImpl::PredictPredictRequest수신합니다. -
TensorflowPredictor::Predict호출하여 gRPC 요청(설정된 경우)에서 요청 기한을 전파합니다. -
TensorflowPredictor::Predict내부에서 요청이 추론을 수행하려는 Servable(모델)을 조회하고 , 여기에서 SavedModel에 대한 정보를 검색하며, 더 중요하게는 모델 그래프가 있는Session객체에 대한 핸들(아마도 부분적으로)을 검색합니다. 짐을 실은. 이 Servable 객체는 TensorFlow Serving에 의해 모델이 로드될 때 생성되어 메모리에 커밋되었습니다. 그런 다음 내부::RunPredict를 호출하여 예측을 수행합니다. -
internal::RunPredict에서는 요청을 검증하고 사전 처리한 후Session개체를 사용하여 Session::Run 에 대한 차단 호출을 사용하여 추론을 수행합니다. 이때 핵심 TensorFlow의 코드베이스를 입력합니다.Session::Run반환되고outputs텐서가 채워진 후 출력을PredictionResponse로 변환 하고 결과를 호출 스택에 반환합니다.