
הביצועים של TensorFlow Serving תלויים מאוד באפליקציה שהוא מריץ, בסביבה שבה הוא נפרס ובתוכנות אחרות איתם היא חולקת גישה למשאבי החומרה הבסיסיים. ככזה, כוונון הביצועים שלו תלוי במקצת, ויש מעט מאוד כללים אוניברסליים שמובטחים להניב ביצועים מיטביים בכל ההגדרות. עם זאת, מסמך זה נועד ללכוד כמה עקרונות כלליים ושיטות עבודה מומלצות להפעלת TensorFlow Serving.
אנא השתמש במדריך 'בקשות מסקנות פרופיל עם TensorBoard' כדי להבין את ההתנהגות הבסיסית של החישוב של המודל שלך בבקשות להסקה, והשתמש במדריך זה כדי לשפר באופן איטרטיבי את הביצועים שלו.
טיפים מהירים
- זמן האחזור של הבקשה הראשונה גבוה מדי? אפשר חימום לדגם .
- מעוניין בניצול או תפוקה גבוהים יותר של משאבים? הגדר אצווה
כוונון ביצועים: יעדים ופרמטרים
בעת כוונון עדין של הביצועים של TensorFlow Serving, בדרך כלל יש לך 2 סוגים של יעדים ו-3 קבוצות של פרמטרים שצריך לכוונן כדי לשפר את היעדים האלה.
מטרות
TensorFlow Serving היא מערכת הגשה מקוונת לדגמים שנלמדו על ידי מכונה. כמו בהרבה מערכות הגשה מקוונות אחרות, מטרת הביצועים העיקרית שלה היא למקסם את התפוקה תוך שמירה על אחזור זנב מתחת לגבולות מסוימים . בהתאם לפרטים ולבגרות של האפליקציה שלך, ייתכן שיהיה אכפת לך יותר מהשהייה ממוצעת מאשר זנב השהייה , אבל מושג מסוים של השהייה ותפוקה הם בדרך כלל המדדים שלגביהם אתה מגדיר יעדי ביצועים. שים לב שאנו לא דנים בזמינות במדריך זה מכיוון שזו יותר פונקציה של סביבת הפריסה.
פרמטרים
אנחנו יכולים לחשוב בערך על 3 קבוצות של פרמטרים שתצורתם קובעת את הביצועים הנצפים: 1) מודל TensorFlow 2) בקשות ההסקה ו-3) השרת (חומרה ובינארי).
1) מודל TensorFlow
המודל מגדיר את החישוב שיבצע TensorFlow Serving עם קבלת כל בקשה נכנסת.
מתחת למכסה המנוע, TensorFlow Serving משתמש בזמן הריצה של TensorFlow כדי לעשות את ההסקה בפועל על הבקשות שלך. המשמעות היא שהשהייה הממוצעת של הגשת בקשה עם TensorFlow Serving היא בדרך כלל לפחות זו של ביצוע הסקה ישירות עם TensorFlow. פירוש הדבר שאם במכונה נתונה, הסקת הסקה על דוגמה בודדת נמשכת 2 שניות, ויש לך יעד השהייה של תת-שנייה, עליך ליצור פרופיל של בקשות להסקת מסקנות, להבין אילו פעולות של TensorFlow ותת-גרפים של המודל שלך תורמים הכי הרבה לזמן האחזור הזה , ועצב מחדש את המודל שלך תוך מחשבה על זמן השהיית מסקנות כאילוץ עיצובי.
שים לב, בעוד שזמן האחזור הממוצע של ביצוע הסקת מסקנות עם TensorFlow Serving בדרך כלל אינו נמוך משימוש ישירות ב- TensorFlow, כאשר TensorFlow Serving זוהר שומר על זמן השהיית הזנב עבור לקוחות רבים המבקשים שאילתות בדגמים רבים ושונים, כל זאת תוך ניצול יעיל של החומרה הבסיסית כדי למקסם את התפוקה .
2) בקשות ההסקה
משטחי API
ל-TensorFlow Serving יש שני משטחי API (HTTP ו-gRPC), שניהם מיישמים את ה- API של PredictionService (למעט שרת HTTP שאינו חושף נקודת קצה MultiInference ). שני משטחי ה-API מכוונים מאוד ומוסיפים השהייה מינימלית, אך בפועל, משטח ה-gRPC הוא ביצועי מעט יותר.
שיטות API
באופן כללי, מומלץ להשתמש בנקודות הקצה Classify ו-Regress שכן הם מקבלים את tf.Example , שהיא הפשטה ברמה גבוהה יותר; עם זאת, במקרים נדירים של בקשות מובנות גדולות (O(Mb)), משתמשים מנוסים עשויים למצוא שימוש ב-PredictRequest ובקידוד ישיר של הודעות ה-Protobuf שלהם ל-TensorProto, ודילוג על ההמשכה וההסידרה מ-tf. לדוגמה, מקור לשיפור קל בביצועים.
גודל אצווה
ישנן שתי דרכים עיקריות שבהן אצווה יכולה לעזור לביצועים שלך. אתה יכול להגדיר את הלקוחות שלך לשלוח בקשות אצווה ל- TensorFlow Serving, או שאתה יכול לשלוח בקשות בודדות ולהגדיר את TensorFlow Serving להמתין עד פרק זמן קבוע מראש, ולבצע הסקה על כל הבקשות שמגיעות באותה תקופה באצווה אחת. קביעת תצורה של אצווה מהסוג האחרון מאפשרת לך להגיע ל- TensorFlow Serving ב-QPS גבוה במיוחד, תוך שהוא מאפשר לה להתאים באופן תת-ליניארי את משאבי המחשוב הדרושים כדי לעמוד בקצב. זה נדון עוד במדריך התצורה וב- README האצווה .
3) השרת (חומרה ובינארי)
הקובץ הבינארי של TensorFlow Serving מבצע חשבונות די מדויקים של החומרה שעליה הוא פועל. ככזה, עליך להימנע מהפעלת יישומים אחרים עתירי מחשוב או זיכרון על אותו מחשב, במיוחד כאלה עם שימוש דינמי במשאבים.
בדומה לסוגים רבים אחרים של עומסי עבודה, TensorFlow Serving יעיל יותר כאשר הוא נפרס על פחות, יותר מכונות (יותר CPU ו-RAM) (כלומר Deployment עם replicas נמוכים יותר במונחי Kubernetes). זה נובע מפוטנציאל טוב יותר לפריסה מרובת דיירים לניצול החומרה ועלויות קבועות נמוכות יותר (שרת RPC, זמן ריצה של TensorFlow וכו').
מאיצים
אם למארח שלך יש גישה למאיץ, ודא שיישמת את המודל שלך כדי למקם חישובים צפופים על המאיץ - זה צריך להיעשות באופן אוטומטי אם השתמשת בממשקי API של TensorFlow ברמה גבוהה, אבל אם בנית גרפים מותאמים אישית, או אם אתה רוצה להצמיד חלקים ספציפיים של גרפים על מאיצים ספציפיים, ייתכן שיהיה עליך למקם באופן ידני תת-גרפים מסוימים על מאיצים (כלומר with tf.device('/device:GPU:0'): ... ).
מעבדים מודרניים
מעבדים מודרניים הרחיבו ללא הרף את ארכיטקטורת ערכת ההוראות x86 כדי לשפר את התמיכה ב- SIMD (Single Instruction Multiple Data) ותכונות אחרות קריטיות לחישובים צפופים (למשל, כפל וחיבור במחזור שעון אחד). עם זאת, על מנת להפעיל על מכונות מעט ישנות יותר, TensorFlow ו- TensorFlow Serving בנויים בהנחה צנועה שהחדשות מבין התכונות הללו אינן נתמכות על ידי ה-CPU המארח.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
אם אתה רואה את הרשומה הזו ביומן (ייתכן שהרחבות שונות מאלו המפורטות) בסטארט-אפ של TensorFlow Serving, זה אומר שאתה יכול לבנות מחדש את TensorFlow Serving ולמקד לפלטפורמה הספציפית של המארח שלך וליהנות מביצועים טובים יותר. בניית TensorFlow Serving ממקור קלה יחסית באמצעות Docker והיא מתועדת כאן .
תצורה בינארית
TensorFlow Serving מציעה מספר כפתורי תצורה השולטים בהתנהגות זמן הריצה שלו, המוגדרים בעיקר באמצעות דגלים בשורת הפקודה . חלק מאלה (בעיקר tensorflow_intra_op_parallelism ו- tensorflow_inter_op_parallelism ) מועברים כדי להגדיר את זמן הריצה של TensorFlow ומוגדרים אוטומטית, שמשתמשים מנוסים עשויים לעקוף אותם על ידי ביצוע ניסויים רבים ומציאת התצורה הנכונה עבור עומס העבודה והסביבה הספציפיים שלהם.
חיי בקשת הסקת מסקנות של TensorFlow
בואו נעבור בקצרה על חייה של דוגמה אב טיפוסית של בקשת הסקת מסקנות של TensorFlow Serving כדי לראות את המסע שעוברת בקשה טיפוסית. לדוגמה שלנו, נצלול לתוך בקשת חיזוי המתקבלת על ידי משטח 2.0.0 TensorFlow Serving gRPC API.
בואו נסתכל תחילה על דיאגרמת רצף ברמת הרכיב, ולאחר מכן נקפוץ לקוד שמיישם את סדרת האינטראקציות הזו.
תרשים רצף
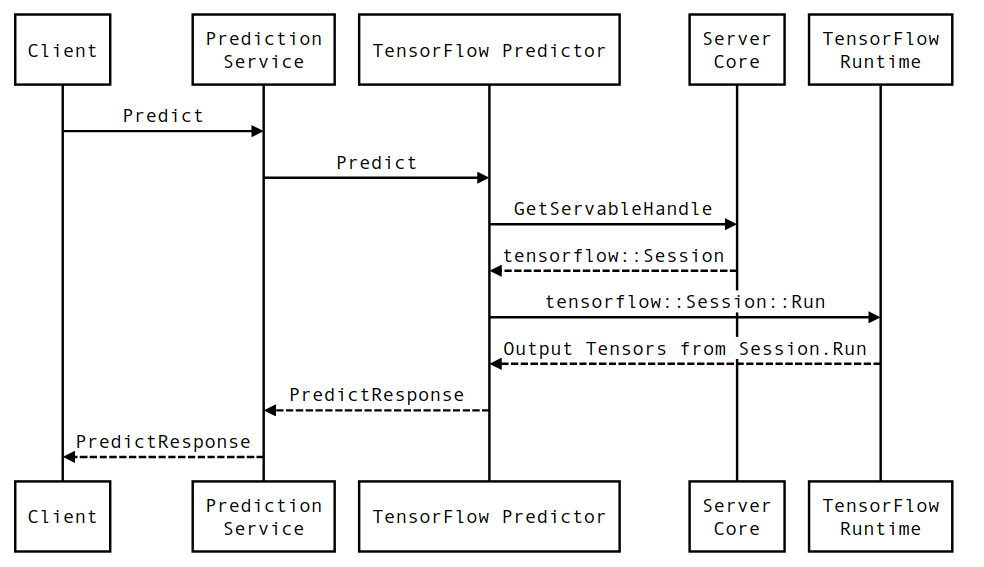
שים לב שהלקוח הוא רכיב בבעלות המשתמש, Prediction Service, Servables ו- Server Core הם בבעלות TensorFlow Serving ו- TensorFlow Runtime נמצאת בבעלות Core TensorFlow .
פרטי רצף
-
PredictionServiceImpl::Predictמקבל אתPredictRequest - אנו מפעילים את
TensorflowPredictor::Predict, ומפיצים את מועד הבקשה מבקשת ה-gRPC (אם הוגדרה כזו). - בתוך
TensorflowPredictor::Predict, אנו מחפשים את ה-Servable (מודל) שהבקשה מבקשת לבצע עליו הסקה, ממנו אנו שואבים מידע על SavedModel וחשוב מכך, ידית לאובייקטSessionשבו נמצא גרף המודל (אולי חלקית) עמוס. האובייקט הניתן להגשה הזה נוצר והוכנס לזיכרון כאשר המודל נטען על ידי TensorFlow Serving. לאחר מכן אנו מפעילים את internal::RunPredict כדי לבצע את החיזוי. - ב-
internal::RunPredict, לאחר אימות ועיבוד מקדים של הבקשה, אנו משתמשים באובייקטSessionכדי לבצע את ההסקה באמצעות קריאה חוסמת ל- Session::Run , בשלב זה, אנו נכנסים לבסיס הקוד של TensorFlow הליבה. לאחר החזרת ה-Session::Runוטנסוריoutputsשלנו אוכלסו, אנו ממירים את הפלטים ל-PredictionResponseומחזירים את התוצאה במעלה המחסנית.