
عملکرد TensorFlow Serving به شدت به برنامهای که اجرا میکند، محیطی که در آن مستقر است و سایر نرمافزارهایی که با آن دسترسی به منابع سختافزاری زیربنایی را به اشتراک میگذارد، بستگی دارد. به این ترتیب، تنظیم عملکرد آن تا حدودی وابسته به موارد است و قوانین جهانی بسیار کمی وجود دارد که تضمین شده است عملکرد بهینه را در همه تنظیمات ارائه دهد. با این گفته، این سند قصد دارد برخی از اصول کلی و بهترین شیوه ها را برای اجرای سرویس TensorFlow به تصویر بکشد.
لطفاً از راهنمای درخواستهای استنتاج نمایه با TensorBoard برای درک رفتار اساسی محاسبات مدل خود در درخواستهای استنتاج استفاده کنید و از این راهنما برای بهبود مکرر عملکرد آن استفاده کنید.
راهنمایی سریع
- تأخیر درخواست اول خیلی زیاد است؟ گرم کردن مدل را فعال کنید.
- به استفاده از منابع بیشتر یا توان عملیاتی علاقه دارید؟ دسته بندی را پیکربندی کنید
تنظیم عملکرد: اهداف و پارامترها
هنگام تنظیم دقیق عملکرد TensorFlow Serving، معمولاً 2 نوع هدف ممکن است داشته باشید و 3 گروه از پارامترها برای بهبود این اهداف وجود دارد.
اهداف
TensorFlow Serving یک سیستم سرویس دهی آنلاین برای مدل های یادگیری ماشینی است. مانند بسیاری از سیستمهای سرویس آنلاین دیگر، هدف اصلی عملکرد آن به حداکثر رساندن توان عملیاتی و در عین حال حفظ تأخیر دنباله زیر محدودههای خاص است. بسته به جزئیات و بلوغ برنامه خود، ممکن است بیشتر به تأخیر متوسط اهمیت دهید تا تأخیر دنباله ، اما برخی از مفاهیم تأخیر و توان عملیاتی معمولاً معیارهایی هستند که اهداف عملکرد را بر اساس آنها تعیین می کنید. توجه داشته باشید که در این راهنما در مورد در دسترس بودن بحث نمی کنیم زیرا این بیشتر تابعی از محیط استقرار است.
مولفه های
میتوانیم تقریباً در مورد 3 گروه از پارامترها فکر کنیم که پیکربندی آنها عملکرد مشاهده شده را تعیین میکند: 1) مدل TensorFlow 2) درخواستهای استنتاج و 3) سرور (سختافزار و باینری).
1) مدل TensorFlow
این مدل محاسباتی را که TensorFlow Serving پس از دریافت هر درخواست دریافتی انجام می دهد، تعریف می کند.
در زیر هود، TensorFlow Serving از زمان اجرا TensorFlow برای استنتاج واقعی درخواستهای شما استفاده میکند. این بدان معناست که متوسط تأخیر ارائه یک درخواست با سرویس TensorFlow معمولاً حداقل به اندازه استنتاج مستقیم با TensorFlow است. این بدان معناست که اگر در یک ماشین معین، استنتاج در یک مثال 2 ثانیه طول بکشد، و شما یک هدف تأخیر فرعی دوم دارید، باید درخواستهای استنتاج را نمایه کنید، بدانید که چه عملیاتهای TensorFlow و زیر نمودارهای مدل شما بیشترین تأثیر را در این تأخیر دارند. و مدل خود را با تأخیر استنتاج به عنوان یک محدودیت طراحی در ذهن دوباره طراحی کنید.
لطفاً توجه داشته باشید، در حالی که میانگین تأخیر انجام استنتاج با سرویس TensorFlow معمولاً کمتر از استفاده مستقیم از TensorFlow نیست، جایی که سرویس TensorFlow میدرخشد، تأخیر انتهایی را برای بسیاری از مشتریانی که مدلهای مختلف را جستجو میکنند، پایین نگه میدارد، و در عین حال از سختافزار اصلی برای به حداکثر رساندن توان استفاده میشود. .
2) درخواست های استنباط
سطوح API
TensorFlow Serving دارای دو سطح API (HTTP و gRPC) است که هر دو API PredictionService را اجرا می کنند (به استثنای سرور HTTP که نقطه پایانی MultiInference را در معرض نمایش نمی گذارد). هر دو سطح API بسیار تنظیم شده اند و کمترین تأخیر را اضافه می کنند، اما در عمل، سطح gRPC کمی عملکرد بیشتری دارد.
روش های API
به طور کلی، توصیه می شود از نقاط پایانی Classify و Regress استفاده کنید زیرا tf.Example را می پذیرند، که یک انتزاع سطح بالاتر است. با این حال، در موارد نادر درخواستهای ساختاری بزرگ (O(Mb))، کاربران باهوش ممکن است از PredictRequest استفاده کنند و پیامهای Protobuf خود را مستقیماً در یک TensorProto رمزگذاری کنند، و از سریالسازی و سریالزدایی از tf صرفنظر کنند. مثال، منبعی برای افزایش عملکرد جزئی است.
اندازه دسته
دو راه اصلی وجود دارد که دسته بندی می تواند به عملکرد شما کمک کند. میتوانید مشتریان خود را برای ارسال درخواستهای دستهای به سرویس TensorFlow پیکربندی کنید، یا میتوانید درخواستهای جداگانه ارسال کنید و سرویس TensorFlow را پیکربندی کنید تا تا یک دوره زمانی از پیش تعیینشده منتظر بماند و استنتاج همه درخواستهایی را که در آن دوره در یک دسته به دست میآیند، انجام دهید. پیکربندی نوع دوم دستهبندی به شما امکان میدهد تا TensorFlow Serving را با QPS بسیار بالا بزنید، در حالی که به آن اجازه میدهد منابع محاسباتی مورد نیاز برای ادامهدادن را به صورت زیرخطی مقیاسبندی کند. این بیشتر در راهنمای پیکربندی و دسته بندی README مورد بحث قرار گرفته است.
3) سرور (سخت افزار و باینری)
باینری TensorFlow Serving حسابداری نسبتاً دقیقی از سخت افزاری که بر روی آن اجرا می شود انجام می دهد. به این ترتیب، باید از اجرای سایر برنامههای محاسباتی یا حافظه فشرده روی یک دستگاه خودداری کنید، بهویژه برنامههایی که از منابع پویا استفاده میکنند.
مانند بسیاری از انواع بارهای کاری دیگر، سرویس TensorFlow زمانی کارآمدتر است که بر روی ماشینهای کمتر و بزرگتر (CPU و RAM بیشتر) مستقر شود (یعنی یک Deployment با replicas کمتر در اصطلاح Kubernetes). این به دلیل پتانسیل بهتر برای استقرار چند مستاجر برای استفاده از سخت افزار و کاهش هزینه های ثابت (سرور RPC، زمان اجرا TensorFlow و غیره) است.
شتاب دهنده ها
اگر هاست شما به یک شتاب دهنده دسترسی دارد، مطمئن شوید که مدل خود را برای قرار دادن محاسبات متراکم روی شتاب دهنده پیاده سازی کرده اید - اگر از API های سطح بالای TensorFlow استفاده کرده اید، اما اگر نمودارهای سفارشی ساخته اید یا می خواهید پین کنید، این کار باید به طور خودکار انجام شود. بخشهای خاصی از نمودارها در شتابدهندههای خاص، ممکن است لازم باشد زیرگرافهای خاصی را به صورت دستی روی شتابدهندهها قرار دهید (یعنی استفاده with tf.device('/device:GPU:0'): ... ).
سی پی یو های مدرن
CPU های مدرن به طور مداوم معماری مجموعه دستورات x86 را برای بهبود پشتیبانی از SIMD (داده های چندگانه دستورالعمل تکی) و سایر ویژگی های حیاتی برای محاسبات متراکم (مانند ضرب و جمع در یک چرخه ساعت) توسعه داده اند. با این حال، برای اجرا بر روی ماشینهای کمی قدیمیتر، TensorFlow و TensorFlow Serving با این فرض ساده ساخته شدهاند که جدیدترین این ویژگیها توسط CPU میزبان پشتیبانی نمیشوند.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
اگر در راه اندازی TensorFlow Serving این ورودی گزارش (احتمالاً برنامه های افزودنی متفاوت از 2 مورد ذکر شده) را مشاهده کردید، به این معنی است که می توانید TensorFlow Serving را بازسازی کنید و پلت فرم میزبان خاص خود را هدف قرار دهید و از عملکرد بهتری لذت ببرید. ایجاد سرویس TensorFlow از منبع با استفاده از Docker نسبتا آسان است و در اینجا مستند شده است.
پیکربندی باینری
TensorFlow Serving تعدادی دستگیره پیکربندی را ارائه می دهد که بر رفتار زمان اجرا آن حاکم است، که عمدتاً از طریق پرچم های خط فرمان تنظیم می شوند. برخی از اینها (به ویژه tensorflow_intra_op_parallelism و tensorflow_inter_op_parallelism ) برای پیکربندی زمان اجرا TensorFlow منتقل میشوند و به صورت خودکار پیکربندی میشوند، که کاربران باهوش ممکن است با انجام آزمایشهای زیاد و یافتن پیکربندی مناسب برای حجم کاری و محیط خاص خود، آنها را لغو کنند.
عمر درخواست استنتاج سرویس TensorFlow
اجازه دهید به طور خلاصه به زندگی یک نمونه اولیه از درخواست استنتاج TensorFlow Serving بپردازیم تا سفری را که یک درخواست معمولی طی میکند ببینیم. برای مثال، ما به یک درخواست پیشبینی میپردازیم که توسط سطح 2.0.0 TensorFlow Serving gRPC API دریافت میشود.
بیایید ابتدا به نمودار توالی سطح مؤلفه نگاه کنیم، و سپس به کدی که این سری از تعاملات را پیاده سازی می کند، بپردازیم.
نمودار توالی
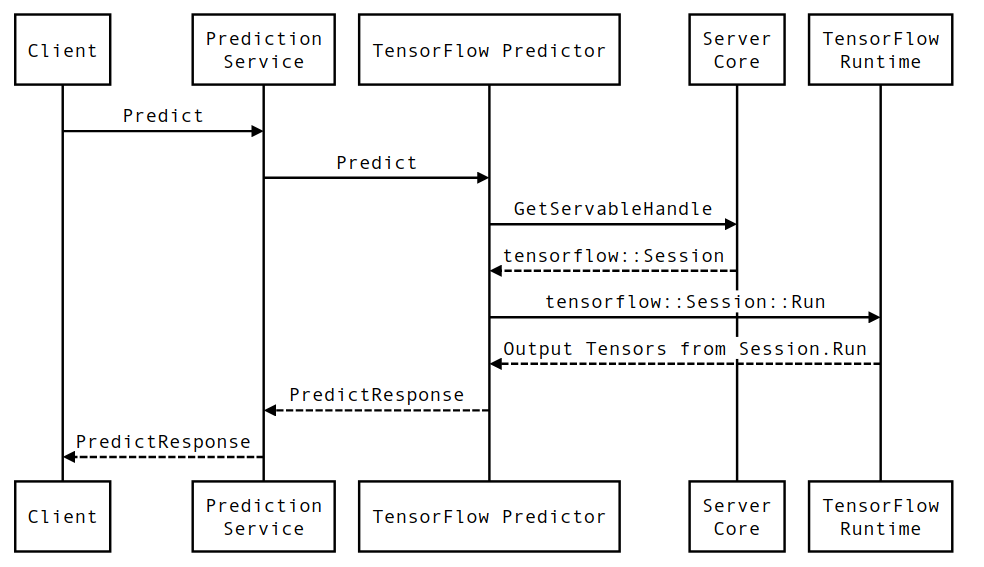
توجه داشته باشید که Client یک مؤلفه متعلق به کاربر است، Prediction Service، Servables و Server Core متعلق به TensorFlow Serving و TensorFlow Runtime متعلق به Core TensorFlow است.
جزئیات دنباله
-
PredictionServiceImpl::PredictPredictRequestدریافت می کند - ما
TensorflowPredictor::Predictفراخوانی می کنیم و مهلت درخواست را از درخواست gRPC منتشر می کنیم (اگر یکی تنظیم شده بود). - در داخل
TensorflowPredictor::Predict، Servable (مدل) مورد درخواست برای انجام استنتاج را جستجو می کنیم، که از آن اطلاعات مربوط به SavedModel و مهمتر از آن، یک دسته برای شیSessionکه گراف مدل در آن است (احتمالاً تا حدی) است. لود شده. این شیء Servable زمانی که مدل توسط TensorFlow Serving بارگذاری شد، در حافظه ایجاد و متعهد شد. سپس داخلی::RunPredict را برای انجام پیش بینی فراخوانی می کنیم. - در
internal::RunPredict، پس از تأیید اعتبار و پیش پردازش درخواست، از شیSessionبرای انجام استنتاج با استفاده از یک فراخوانی مسدودکننده به Session::Run استفاده می کنیم، در این مرحله، پایگاه کد TensorFlow را وارد می کنیم. بعد از اینکهSession::Runبرگشت و تانسورهایoutputsما پر شد، خروجی ها را بهPredictionResponseتبدیل می کنیم و نتیجه را به پشته تماس برمی گردانیم.