
Tổng quan
Phân tích mô hình TensorFlow (TFMA) là một thư viện để thực hiện đánh giá mô hình.
- Dành cho : Kỹ sư học máy hoặc nhà khoa học dữ liệu
- ai : muốn phân tích và hiểu các mô hình TensorFlow của họ
- đó là : một thư viện hoặc thành phần độc lập của đường dẫn TFX
- that : đánh giá các mô hình trên lượng lớn dữ liệu theo cách phân tán trên cùng các số liệu được xác định trong đào tạo. Các chỉ số này được so sánh qua các phần dữ liệu và được hiển thị trong sổ ghi chép Jupyter hoặc Colab.
- không giống như : một số công cụ xem xét nội tâm mô hình như tensorboard cung cấp khả năng xem xét nội mô hình
TFMA thực hiện các tính toán của mình theo cách phân tán trên lượng lớn dữ liệu bằng cách sử dụng Apache Beam . Các phần sau đây mô tả cách thiết lập quy trình đánh giá TFMA cơ bản. Xem kiến trúc để biết thêm chi tiết về cách triển khai cơ bản.
Nếu bạn chỉ muốn tham gia và bắt đầu, hãy xem sổ tay colab của chúng tôi.
Trang này cũng có thể được xem từ tensorflow.org .
Các loại mô hình được hỗ trợ
TFMA được thiết kế để hỗ trợ các mô hình dựa trên tensorflow, nhưng cũng có thể dễ dàng mở rộng để hỗ trợ các khung công tác khác. Trước đây, TFMA yêu cầu tạo EvalSavedModel để sử dụng TFMA, nhưng phiên bản mới nhất của TFMA hỗ trợ nhiều loại mô hình tùy thuộc vào nhu cầu của người dùng. Chỉ nên thiết lập EvalSavedModel nếu sử dụng mô hình dựa trên tf.estimator và yêu cầu số liệu thời gian đào tạo tùy chỉnh.
Lưu ý rằng vì TFMA hiện chạy dựa trên mô hình phân phối nên TFMA sẽ không còn tự động đánh giá các số liệu được thêm vào thời điểm đào tạo nữa. Ngoại lệ cho trường hợp này là nếu mô hình máy ảnh được sử dụng vì máy ảnh lưu các số liệu được sử dụng cùng với mô hình đã lưu. Tuy nhiên, nếu đây là một yêu cầu khó khăn thì TFMA mới nhất có khả năng tương thích ngược sao cho EvalSavedModel vẫn có thể chạy trong đường dẫn TFMA.
Bảng sau đây tóm tắt các mô hình được hỗ trợ theo mặc định:
| Loại mô hình | Số liệu về thời gian đào tạo | Số liệu sau đào tạo |
|---|---|---|
| TF2 (máy ảnh) | Y* | Y |
| TF2 (chung) | không áp dụng | Y |
| EvalSavedModel (công cụ ước tính) | Y | Y |
| Không có (pd.DataFrame, v.v.) | không áp dụng | Y |
- Số liệu Thời gian đào tạo đề cập đến các số liệu được xác định tại thời điểm đào tạo và được lưu cùng với mô hình (mô hình đã lưu TFMA EvalSavedModel hoặc máy ảnh). Số liệu sau đào tạo đề cập đến số liệu được thêm thông qua
tfma.MetricConfig. - Các mô hình TF2 chung là các mô hình tùy chỉnh xuất chữ ký có thể được sử dụng để suy luận và không dựa trên máy ảnh hoặc công cụ ước tính.
Xem Câu hỏi thường gặp để biết thêm thông tin về cách thiết lập và định cấu hình các loại mô hình khác nhau này.
Cài đặt
Trước khi chạy đánh giá, cần phải thiết lập một chút. Đầu tiên, một đối tượng tfma.EvalConfig phải được xác định để cung cấp các thông số kỹ thuật cho mô hình, số liệu và lát cắt sẽ được đánh giá. Thứ hai, cần tạo một tfma.EvalSharedModel để trỏ đến mô hình (hoặc các mô hình) thực tế sẽ được sử dụng trong quá trình đánh giá. Khi những điều này đã được xác định, việc đánh giá sẽ được thực hiện bằng cách gọi tfma.run_model_analysis với tập dữ liệu thích hợp. Để biết thêm chi tiết, hãy xem hướng dẫn thiết lập .
Nếu chạy trong đường dẫn TFX, hãy xem hướng dẫn TFX để biết cách định cấu hình TFMA để chạy dưới dạng thành phần Bộ đánh giá TFX.
Ví dụ
Đánh giá mô hình đơn
Phần sau đây sử dụng tfma.run_model_analysis để thực hiện đánh giá trên mô hình phân phát. Để biết giải thích về các cài đặt khác nhau cần thiết, hãy xem hướng dẫn thiết lập .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Để đánh giá phân tán, hãy xây dựng đường dẫn Apache Beam bằng cách sử dụng trình chạy phân tán. Trong quy trình, hãy sử dụng tfma.ExtractEvaluateAndWriteResults để đánh giá và viết ra kết quả. Kết quả có thể được tải để hiển thị bằng cách sử dụng tfma.load_eval_result .
Ví dụ:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Xác thực mô hình
Để thực hiện xác thực mô hình dựa trên ứng viên và đường cơ sở, hãy cập nhật cấu hình để bao gồm cài đặt ngưỡng và chuyển hai mô hình tới tfma.run_model_analysis .
Ví dụ:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Trực quan hóa
Kết quả đánh giá TFMA có thể được hiển thị trong sổ ghi chép Jupyter bằng cách sử dụng các thành phần giao diện người dùng có trong TFMA. Ví dụ:
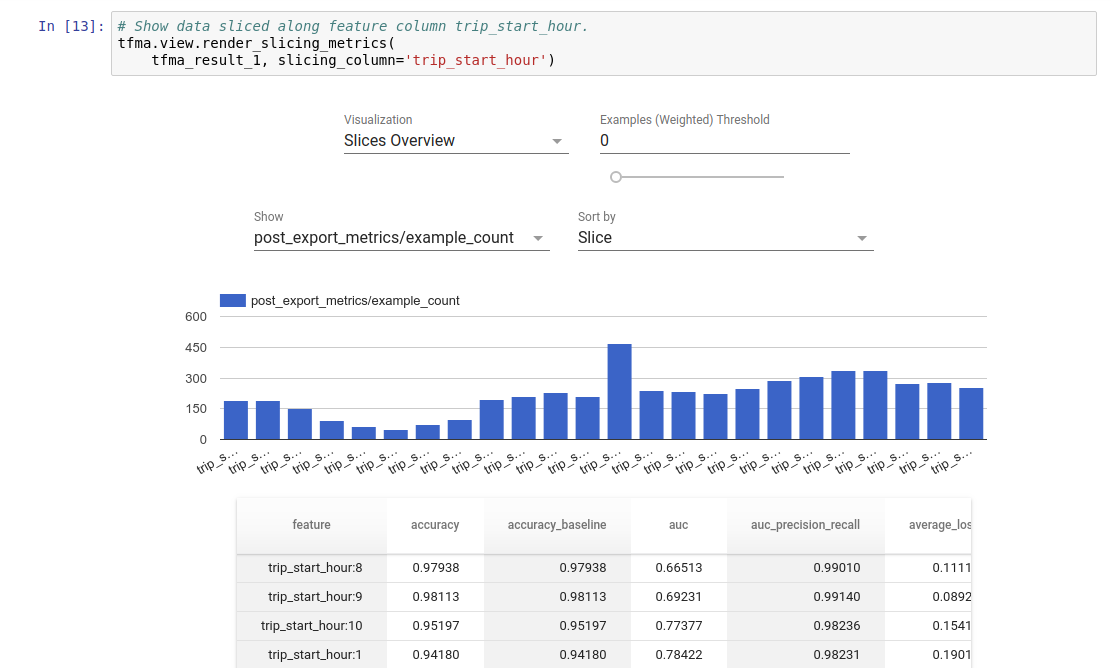 .
.