
Обзор
TensorFlow Model Analysis (TFMA) — это библиотека для выполнения оценки модели.
- Для : инженеров по машинному обучению или специалистов по данным.
- кто : хочет проанализировать и понять свои модели TensorFlow
- это : отдельная библиотека или компонент конвейера TFX.
- that : оценивает модели на больших объемах данных распределенным образом по тем же метрикам, которые определены при обучении. Эти показатели сравниваются с фрагментами данных и визуализируются в блокнотах Jupyter или Colab.
- в отличие от : некоторые инструменты самоанализа модели, такие как тензорная доска, которые предлагают самоанализ модели
TFMA выполняет свои вычисления распределенным образом над большими объемами данных с помощью Apache Beam . В следующих разделах описывается, как настроить базовый конвейер оценки TFMA. См. более подробную информацию об архитектуре базовой реализации.
Если вы просто хотите приступить к делу и начать, ознакомьтесь с нашим блокнотом Colab .
Эту страницу также можно просмотреть на сайте tensorflow.org .
Поддерживаемые типы моделей
TFMA предназначен для поддержки моделей на основе тензорного потока, но его можно легко расширить для поддержки других платформ. Исторически TFMA требовала создания EvalSavedModel для использования TFMA, но последняя версия TFMA поддерживает несколько типов моделей в зависимости от потребностей пользователя. Настройка EvalSavedModel требуется только в том случае, если используется модель на основе tf.estimator и требуются пользовательские метрики времени обучения.
Обратите внимание: поскольку TFMA теперь работает на основе модели обслуживания, TFMA больше не будет автоматически оценивать метрики, добавленные во время обучения. Исключением из этого случая является использование модели keras, поскольку keras сохраняет метрики, используемые вместе с сохраненной моделью. Однако если это жесткое требование, последняя версия TFMA обратно совместима, так что EvalSavedModel по-прежнему можно запускать в конвейере TFMA.
В следующей таблице приведены модели, поддерживаемые по умолчанию:
| Тип модели | Показатели времени обучения | Показатели после обучения |
|---|---|---|
| TF2 (керас) | Д* | Да |
| TF2 (общий) | Н/Д | Да |
| EvalSavedModel (оценщик) | Да | Да |
| Нет (pd.DataFrame и т. д.) | Н/Д | Да |
- Метрики времени обучения относятся к метрикам, определенным во время обучения и сохраненным вместе с моделью (либо TFMA EvalSavedModel, либо сохраненной моделью keras). Метрики после обучения относятся к метрикам, добавленным через
tfma.MetricConfig. - Общие модели TF2 — это пользовательские модели, которые экспортируют сигнатуры, которые можно использовать для вывода и не основаны ни на керасе, ни на оценщике.
См. раздел Часто задаваемые вопросы для получения дополнительной информации о том, как установить и настроить эти различные типы моделей.
Настраивать
Перед запуском оценки необходимо выполнить небольшую настройку. Сначала необходимо определить объект tfma.EvalConfig , который предоставляет спецификации модели, метрик и срезов, которые необходимо оценить. Во-вторых, необходимо создать tfma.EvalSharedModel , указывающий на фактическую модель (или модели), которая будет использоваться во время оценки. После того как они определены, оценка выполняется путем вызова tfma.run_model_analysis с соответствующим набором данных. Более подробную информацию смотрите в руководстве по настройке .
При работе в конвейере TFX см. руководство TFX, чтобы узнать, как настроить TFMA для работы в качестве компонента TFX Evaluator .
Примеры
Оценка одной модели
В следующем примере используется tfma.run_model_analysis для выполнения оценки модели обслуживания. Объяснение различных необходимых настроек см. в руководстве по установке .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Для распределенной оценки создайте конвейер Apache Beam с помощью распределенного исполнителя. В конвейере используйте tfma.ExtractEvaluateAndWriteResults для оценки и записи результатов. Результаты можно загрузить для визуализации с помощью tfma.load_eval_result .
Например:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Проверка модели
Чтобы выполнить проверку модели по кандидату и базовому состоянию, обновите конфигурацию, включив в нее пороговый параметр, и передайте две модели в tfma.run_model_analysis .
Например:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Визуализация
Результаты оценки TFMA можно визуализировать в блокноте Jupyter с помощью внешних компонентов, включенных в TFMA. Например:
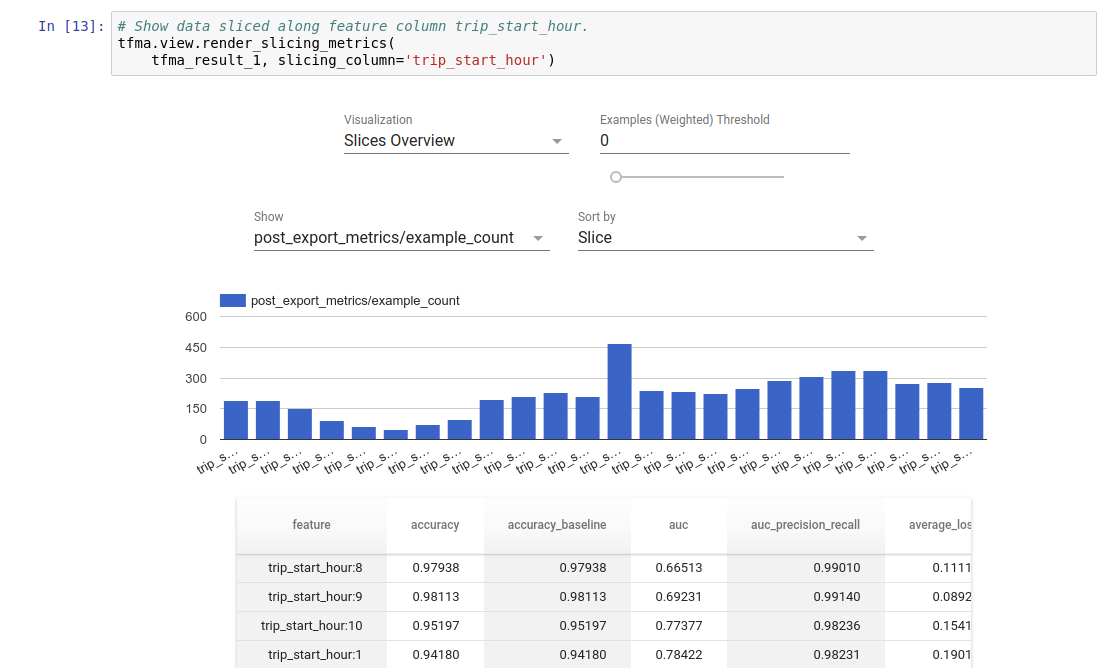 .
.