
Panoramica
TensorFlow Model Analysis (TFMA) è una libreria per eseguire la valutazione del modello.
- Per : ingegneri di machine learning o data scientist
- chi : vuole analizzare e comprendere i propri modelli TensorFlow
- è : una libreria autonoma o un componente di una pipeline TFX
- that : valuta modelli su grandi quantità di dati in modo distribuito sulle stesse metriche definite in training. Queste metriche vengono confrontate su porzioni di dati e visualizzate nei notebook Jupyter o Colab.
- a differenza : alcuni strumenti di introspezione del modello come tensorboard che offrono l'introspezione del modello
TFMA esegue i suoi calcoli in modo distribuito su grandi quantità di dati utilizzando Apache Beam . Le sezioni seguenti descrivono come impostare una pipeline di valutazione TFMA di base. Vedi l'architettura per maggiori dettagli sull'implementazione sottostante.
Se vuoi semplicemente entrare e iniziare, dai un'occhiata al nostro taccuino di collaborazione .
Questa pagina può essere visualizzata anche da tensorflow.org .
Tipi di modelli supportati
TFMA è progettato per supportare modelli basati su tensorflow, ma può essere facilmente esteso per supportare anche altri framework. Storicamente, TFMA richiedeva la creazione di un EvalSavedModel per utilizzare TFMA, ma l'ultima versione di TFMA supporta più tipi di modelli a seconda delle esigenze dell'utente. L'impostazione di un EvalSavedModel dovrebbe essere richiesta solo se viene utilizzato un modello basato su tf.estimator e sono necessarie metriche personalizzate relative ai tempi di addestramento.
Tieni presente che poiché TFMA ora viene eseguito in base al modello di servizio, TFMA non valuterà più automaticamente le metriche aggiunte al momento dell'addestramento. L'eccezione a questo caso si verifica se viene utilizzato un modello Keras poiché Keras salva le metriche utilizzate insieme al modello salvato. Tuttavia, se questo è un requisito difficile, l'ultimo TFMA è retrocompatibile in modo che un EvalSavedModel possa ancora essere eseguito in una pipeline TFMA.
La tabella seguente riassume i modelli supportati per impostazione predefinita:
| Tipo di modello | Metriche del tempo di formazione | Metriche post-formazione |
|---|---|---|
| TF2 (Keras) | Sì* | Y |
| TF2 (generico) | N / A | Y |
| EvalSavedModel (stimatore) | Y | Y |
| Nessuno (pd.DataFrame, ecc.) | N / A | Y |
- Le metriche del tempo di addestramento si riferiscono alle metriche definite al momento dell'addestramento e salvate con il modello (TFMA EvalSavedModel o modello salvato keras). Le metriche post-addestramento si riferiscono alle metriche aggiunte tramite
tfma.MetricConfig. - I modelli TF2 generici sono modelli personalizzati che esportano firme che possono essere utilizzate per l'inferenza e non sono basati né su Keras né sullo stimatore.
Consulta le domande frequenti per ulteriori informazioni su come impostare e configurare questi diversi tipi di modelli.
Impostare
Prima di eseguire una valutazione, è necessaria una piccola configurazione. Innanzitutto è necessario definire un oggetto tfma.EvalConfig che fornisca le specifiche per il modello, i parametri e le sezioni da valutare. In secondo luogo è necessario creare un tfma.EvalSharedModel che punti al modello (o ai modelli) effettivo (o ai modelli) da utilizzare durante la valutazione. Una volta definiti questi, la valutazione viene eseguita chiamando tfma.run_model_analysis con un set di dati appropriato. Per ulteriori dettagli, consultare la guida alla configurazione .
Se in esecuzione all'interno di una pipeline TFX, consulta la guida TFX per sapere come configurare TFMA per l'esecuzione come componente TFX Evaluator .
Esempi
Valutazione del modello singolo
Di seguito viene utilizzato tfma.run_model_analysis per eseguire la valutazione su un modello di servizio. Per una spiegazione delle diverse impostazioni necessarie consultare la guida alla configurazione .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Per la valutazione distribuita, costruisci una pipeline Apache Beam utilizzando un runner distribuito. Nella pipeline, utilizzare tfma.ExtractEvaluateAndWriteResults per la valutazione e per scrivere i risultati. I risultati possono essere caricati per la visualizzazione utilizzando tfma.load_eval_result .
Per esempio:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Convalida del modello
Per eseguire la convalida del modello rispetto a un candidato e a una baseline, aggiornare la configurazione per includere un'impostazione di soglia e passare due modelli a tfma.run_model_analysis .
Per esempio:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Visualizzazione
I risultati della valutazione TFMA possono essere visualizzati in un notebook Jupyter utilizzando i componenti frontend inclusi in TFMA. Per esempio:
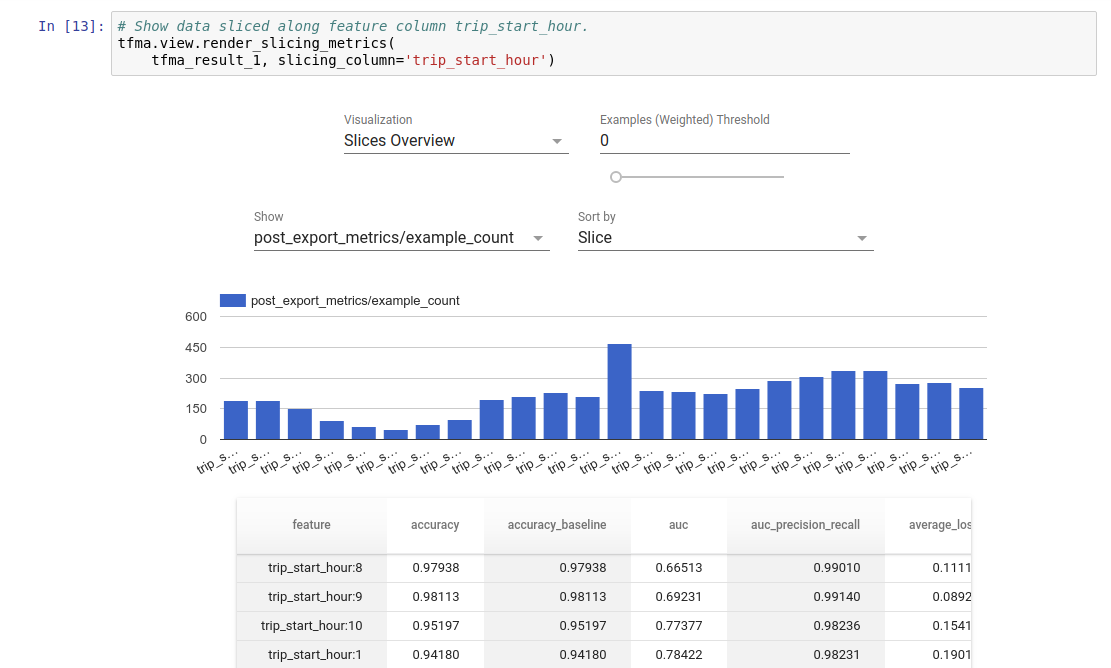 .
.