
כְּלָלִי
האם עדיין נדרש EvalSavedModel?
בעבר TFMA דרש שכל המדדים יאוחסנו בתוך גרף זרימת טנסור באמצעות EvalSavedModel מיוחד. כעת, ניתן לחשב מדדים מחוץ לגרף TF באמצעות יישומי beam.CombineFn .
כמה מההבדלים העיקריים הם:
-
EvalSavedModelדורש ייצוא מיוחד מהמאמן בעוד שניתן להשתמש במודל הגשה ללא צורך בשינויים בקוד ההדרכה. - כאשר נעשה שימוש ב-
EvalSavedModel, כל המדדים שנוספו בזמן האימון זמינים אוטומטית בזמן ההערכה. ללאEvalSavedModelיש להוסיף מחדש את המדדים הללו.- החריג לכלל זה הוא אם נעשה שימוש במודל של keras, ניתן להוסיף את המדדים גם באופן אוטומטי מכיוון ש-keras שומרת את המידע המטרי לצד המודל השמור.
האם TFMA יכול לעבוד גם עם מדדי גרף וגם עם מדדים חיצוניים?
TFMA מאפשר להשתמש בגישה היברידית שבה ניתן לחשב מדדים מסוימים בתוך הגרף, כאשר אחרים ניתן לחשב בחוץ. אם יש לך כרגע EvalSavedModel אז אתה יכול להמשיך להשתמש בו.
ישנם שני מקרים:
- השתמש ב-TFMA
EvalSavedModelגם לחילוץ תכונות וגם לחישובים מדדים, אך גם הוסף מדדים נוספים המבוססים על משלב. במקרה זה תקבל את כל מדדי הגרף מה-EvalSavedModelיחד עם כל מדדים נוספים מהמבוססים על המשלב שאולי לא נתמכו בעבר. - השתמש ב-TFMA
EvalSavedModelלחילוץ תכונה/חיזוי, אך השתמש במדדים המבוססים על משלב עבור כל חישובי המדדים. מצב זה שימושי אם קיימות טרנספורמציות של תכונה ב-EvalSavedModelשבהן תרצו להשתמש עבור חיתוך, אך מעדיפים לבצע את כל החישובים המטריים מחוץ לגרף.
הגדרה
אילו סוגי דגמים נתמכים?
TFMA תומך במודלים של keras, מודלים המבוססים על ממשקי API גנריים של חתימות TF2, וכן מודלים מבוססי מעריך TF (אם כי בהתאם למקרה השימוש, ייתכן שהמודלים מבוססי האומד ידרשו להשתמש ב- EvalSavedModel ).
עיין במדריך get_started לרשימה המלאה של סוגי הדגמים הנתמכים והגבלות כלשהן.
כיצד אוכל להגדיר את TFMA לעבוד עם מודל מקורי מבוסס Keras?
להלן תצורה לדוגמה עבור מודל keras המבוססת על ההנחות הבאות:
- המודל השמור מיועד להגשה ומשתמש בשם החתימה
serving_default(ניתן לשנות זאת באמצעותmodel_specs[0].signature_name). - יש להעריך מדדים מובנים מ-
model.compile(...)(ניתן לבטל זאת באמצעותoptions.include_default_metricבתוך ה- tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
ראה מדדים למידע נוסף על סוגים אחרים של מדדים שניתן להגדיר.
כיצד אוכל להגדיר את TFMA לעבוד עם מודל מבוסס חתימות TF2 גנרי?
להלן תצורה לדוגמה עבור מודל TF2 גנרי. להלן, signature_name הוא השם של החתימה הספציפית שיש להשתמש בה לצורך הערכה.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
ראה מדדים למידע נוסף על סוגים אחרים של מדדים שניתן להגדיר.
כיצד אוכל להגדיר את TFMA לעבוד עם מודל מבוסס אומד?
במקרה זה יש שלוש אפשרויות.
אפשרות 1: השתמש במודל הגשה
אם נעשה שימוש באפשרות זו, כל המדדים שנוספו במהלך האימון לא ייכללו בהערכה.
להלן דוגמה לתצורה בהנחה ש serving_default הוא שם החתימה בשימוש:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
ראה מדדים למידע נוסף על סוגים אחרים של מדדים שניתן להגדיר.
אפשרות 2: השתמש ב-EvalSavedModel יחד עם מדדים נוספים המבוססים על משלב
במקרה זה, השתמש ב- EvalSavedModel גם לחילוץ תכונה / חיזוי וגם להערכה וגם הוסף מדדים נוספים המבוססים על משלב.
להלן תצורה לדוגמה:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
ראה מדדים למידע נוסף על סוגים אחרים של מדדים שניתן להגדיר ו- EvalSavedModel למידע נוסף על הגדרת ה-EvalSavedModel.
אפשרות 3: השתמש במודל EvalSavedModel רק עבור חילוץ תכונה / חיזוי
דומה לאופציה (2), אך השתמש רק EvalSavedModel לחילוץ תכונה/חיזוי. אפשרות זו שימושית אם רוצים רק מדדים חיצוניים, אבל יש טרנספורמציות של תכונה שתרצה לחתוך עליהן. בדומה לאפשרות (1) כל המדדים שנוספו במהלך האימון לא ייכללו בהערכה.
במקרה זה התצורה זהה לעיל, רק include_default_metrics מושבתת.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
ראה מדדים למידע נוסף על סוגים אחרים של מדדים שניתן להגדיר ו- EvalSavedModel למידע נוסף על הגדרת ה-EvalSavedModel.
כיצד אוכל להגדיר את TFMA לעבוד עם מודל מבוסס מודל-to-Keras?
הגדרת keras model_to_estimator דומה לתצורת האומד. עם זאת, ישנם כמה הבדלים ספציפיים לאופן שבו עובד מודל לאומדן. במיוחד, המודל-ל-Esimtator מחזיר את הפלטים שלו בצורה של dict כאשר מפתח dict הוא השם של שכבת הפלט האחרונה במודל ה-keras המשויך (אם לא מסופק שם, keras יבחר שם ברירת מחדל עבורך כגון dense_1 או output_1 ). מנקודת מבט של TFMA, התנהגות זו דומה למה שתוצא עבור מודל מרובה פלטים למרות שהמודל לאומד עשוי להיות רק עבור מודל בודד. כדי להסביר את ההבדל הזה, נדרש שלב נוסף להגדרת שם הפלט. עם זאת, אותן שלוש אפשרויות חלות כאומד.
להלן דוגמה לשינויים הנדרשים בתצורה מבוססת אומדן:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
כיצד אוכל להגדיר את TFMA לעבוד עם תחזיות מחושבות מראש (כלומר מודל-אגנוסטיות)? ( TFRecord ו- tf.Example )
על מנת להגדיר את TFMA לעבוד עם תחזיות מחושבות מראש, יש להשבית את ברירת המחדל tfma.PredictExtractor ויש להגדיר את tfma.InputExtractor לנתח את התחזיות יחד עם שאר תכונות הקלט. זה מושג על ידי הגדרת tfma.ModelSpec עם שם מפתח התכונה המשמש לחיזויים לצד התוויות והמשקלים.
להלן דוגמה להגדרה:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
ראה מדדים למידע נוסף על מדדים שניתן להגדיר.
שים לב שלמרות tfma.ModelSpec מוגדרת, לא נעשה שימוש בפועל במודל (כלומר אין tfma.EvalSharedModel ). הקריאה להפעיל ניתוח מודל עשויה להיראות כך:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
כיצד אוכל להגדיר את TFMA לעבוד עם תחזיות מחושבות מראש (כלומר מודל-אגנוסטיות)? ( pd.DataFrame )
עבור מערכי נתונים קטנים שיכולים להתאים לזיכרון, חלופה ל- TFRecord היא pandas.DataFrame s. TFMA יכול לפעול על s pandas.DataFrame באמצעות tfma.analyze_raw_data API. להסבר על tfma.MetricsSpec ו- tfma.SlicingSpec , עיין במדריך ההתקנה . ראה מדדים למידע נוסף על מדדים שניתן להגדיר.
להלן דוגמה להגדרה:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
מדדים
אילו סוגי מדדים נתמכים?
TFMA תומך במגוון רחב של מדדים כולל:
- מדדי רגרסיה
- מדדי סיווג בינאריים
- מדדי סיווג רב-מעמדי/רב-תווית
- מדדי מיקרו ממוצע / מאקרו ממוצע
- מדדים מבוססי שאילתה/דירוג
האם נתמכים מדדים ממודלים מרובי פלט?
כֵּן. ראה מדריך מדדים לפרטים נוספים.
האם נתמכים מדדים ממספר דגמים?
כֵּן. ראה מדריך מדדים לפרטים נוספים.
האם ניתן להתאים את הגדרות המדד (שם וכו')?
כֵּן. ניתן להתאים אישית את הגדרות המדדים (למשל הגדרת סף ספציפי וכו') על ידי הוספת הגדרות config לתצורת המדד. ראה מדריך מדדים כולל פרטים נוספים.
האם נתמכים מדדים מותאמים אישית?
כֵּן. או על ידי כתיבת יישום tf.keras.metrics.Metric מותאם אישית או על ידי כתיבת יישום beam.CombineFn מותאם אישית. במדריך המדדים יש פרטים נוספים.
אילו סוגי מדדים אינם נתמכים?
כל עוד ניתן לחשב את המדד שלך באמצעות beam.CombineFn , אין הגבלות על סוגי המדדים שניתן לחשב על סמך tfma.metrics.Metric . אם עובדים עם מדד שנגזר מ- tf.keras.metrics.Metric אז יש לעמוד בקריטריונים הבאים:
- זה אמור להיות אפשרי לחשב מספיק נתונים סטטיסטיים עבור המדד על כל דוגמה באופן עצמאי, ולאחר מכן לשלב את הנתונים הסטטיסטיים המספיקים הללו על ידי הוספתם על פני כל הדוגמאות, ולקבוע את ערך המדד אך ורק מתוך הסטטיסטיקה המספיקה הללו.
- לדוגמה, לדיוק הסטטיסטיקה המספיקה היא "נכון לחלוטין" ו"סה"כ דוגמאות". אפשר לחשב את שני המספרים הללו עבור דוגמאות בודדות, ולצרף אותם לקבוצת דוגמאות כדי לקבל את הערכים הנכונים עבור הדוגמאות הללו. ניתן לחשב את הדיוק הסופי באמצעות "סך הכל נכון / סך הדוגמאות".
תוספות
האם אני יכול להשתמש ב-TFMA כדי להעריך הוגנות או הטיה במודל שלי?
TFMA כולל תוסף FairnessIndicators המספק מדדים שלאחר היצוא להערכת ההשפעות של הטיה לא מכוונת במודלים של סיווג.
התאמה אישית
מה אם אני צריך יותר התאמה אישית?
TFMA מאוד גמיש ומאפשר לך להתאים אישית כמעט את כל חלקי הצינור באמצעות Extractors מותאמים אישית, Evaluators ו/או Writers . הפשטות אלו נדונות ביתר פירוט במסמך האדריכלות .
פתרון בעיות, איתור באגים וקבלת עזרה
מדוע מדדי MultiClassConfusionMatrix אינם תואמים מדדי ConfusionMatrix בינאריים
אלו למעשה חישובים שונים. בינאריזציה מבצעת השוואה עבור כל מזהה מחלקה באופן עצמאי (כלומר, התחזית עבור כל מחלקה מושווה בנפרד מול הספים שסופקו). במקרה זה יתכן ששתי מחלקות או יותר יציינו כולן שהן תואמות את החיזוי מכיוון שהערך החזוי שלהן היה גדול מהסף (זה יהיה ברור עוד יותר בסף נמוך יותר). במקרה של מטריצת הבלבול מרובה המחלקות, עדיין יש רק ערך חזוי אמיתי אחד והוא תואם את הערך בפועל או שלא. הסף משמש רק כדי לאלץ חיזוי להתאים לאף מחלקה אם הוא נמוך מהסף. ככל שהסף גבוה יותר כך קשה יותר לתחזית של מחלקה בינארית להתאים. כמו כן ככל שהסף נמוך יותר כך קל יותר לתחזיות של מחלקה בינארית להתאים. המשמעות היא שבסף > 0.5 הערכים הבינאריים וערכי המטריצה הרב-מחלקה יהיו קרובים יותר ובסף < 0.5 הם יהיו רחוקים יותר זה מזה.
לדוגמה, נניח שיש לנו 10 מחלקות שבהן מחלקה 2 נחזה בהסתברות של 0.8, אבל המחלקה בפועל הייתה מחלקה 1 שהייתה לה הסתברות של 0.15. אם תבצע בינאריות על מחלקה 1 ותשתמש בסף של 0.1, אזי מחלקה 1 תיחשב כנכונה (0.15 > 0.1) ולכן היא תיספר כ-TP, עם זאת, במקרה של ריבוי מחלקות, מחלקה 2 תיחשב נכונה (0.8 > 0.1) ומכיוון שמחלקה 1 הייתה בפועל, זה ייספר כ-FN. מכיוון שבספים נמוכים יותר, יותר ערכים ייחשבו כחיוביים, באופן כללי יהיו ספירות TP ו-FP גבוהות יותר עבור מטריצת בלבול בינארית מאשר עבור מטריצת הבלבול הרב-מעמדית, ובאופן דומה TN ו-FN נמוכים יותר.
להלן דוגמה להבדלים שנצפו בין MultiClassConfusionMatrixAtThresholds לבין הספירות המתאימות מבינאריזציה של אחת המחלקות.
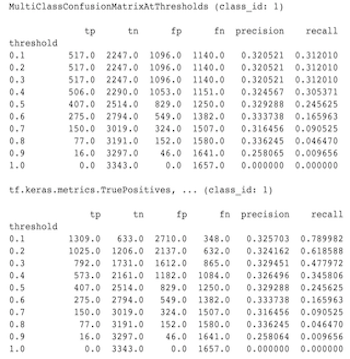
מדוע למדדי precision@1 ו-recall@1 שלי יש אותו ערך?
בערך k עליון של 1 דיוק וזיכרונות הם אותו הדבר. דיוק שווה ל- TP / (TP + FP) והחזרה שווה ל- TP / (TP + FN) . התחזית העליונה תמיד חיובית ותתאים או לא תתאים לתווית. במילים אחרות, עם N דוגמאות, TP + FP = N . עם זאת, אם התווית לא תואמת את החיזוי העליון, אז זה מרמז גם על חיזוי לא העליון k הותאם וכאשר top k מוגדר ל-1, כל החיזויים שאינם בראש 1 יהיו 0. זה מרמז על FN חייב להיות (N - TP) או N = TP + FN . התוצאה הסופית היא precision@1 = TP / N = recall@1 . שים לב שזה חל רק כאשר יש תווית בודדת לכל דוגמה, לא עבור ריבוי תווית.
מדוע מדדי הממוצע_תווית והממוצע_חיזוי שלי הם תמיד 0.5?
סביר להניח שזה נגרם בגלל שהמדדים מוגדרים לבעיית סיווג בינארי, אבל המודל מוציא הסתברויות עבור שתי המחלקות במקום רק אחת. זה נפוץ כאשר משתמשים בממשק API לסיווג של tensorflow . הפתרון הוא לבחור את המחלקה שאתה רוצה שהתחזיות יתבססו עליה ולאחר מכן לבצע בינאריות על המחלקה הזו. לְדוּגמָה:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
כיצד לפרש את MultiLabelConfusionMatrixPlot?
בהינתן תווית מסוימת, ניתן להשתמש ב- MultiLabelConfusionMatrixPlot (וב- MultiLabelConfusionMatrix המשויך) כדי להשוות את התוצאות של תוויות אחרות והתחזיות שלהן כאשר התווית שנבחרה הייתה אמיתית. לדוגמה, נניח שיש לנו שלוש מחלקות bird , plane superman ואנו מסווגים תמונות כדי לציין אם הן מכילות אחת או יותר מאחת מהמחלקות הללו. MultiLabelConfusionMatrix תחשב את המכפלה הקרטזיאנית של כל מחלקה בפועל מול מחלקה אחרת (הנקראת המחלקה החזויה). שימו לב שבעוד שהזיווג הוא (actual, predicted) , המחלקה predicted לא בהכרח מרמזת על חיזוי חיובי, היא רק מייצגת את העמודה החזויה במטריצה הממשית לעומת החזויה. לדוגמה, נניח שחישבנו את המטריצות הבאות:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
ל- MultiLabelConfusionMatrixPlot יש שלוש דרכים להציג נתונים אלה. בכל המקרים הדרך לקרוא את הטבלה היא שורה אחר שורה מנקודת המבט של הכיתה בפועל.
1) ספירת חיזוי כוללת
במקרה זה, עבור שורה נתונה (כלומר מחלקה בפועל) מה היו ספירות ה- TP + FP עבור המחלקות האחרות. עבור הספירות לעיל, התצוגה שלנו תהיה כדלקמן:
| ציפור חזויה | מטוס חזוי | סופרמן חזוי | |
|---|---|---|---|
| ציפור אמיתית | 6 | 4 | 2 |
| מטוס בפועל | 4 | 4 | 4 |
| סופרמן אמיתי | 5 | 5 | 4 |
כשהתמונות בעצם הכילו bird חזינו נכון 6 מהן. במקביל גם חזינו plane (או נכון או לא נכון) 4 פעמים superman (או נכון או לא נכון) 2 פעמים.
2) ספירת חיזוי שגויה
במקרה זה, עבור שורה נתונה (כלומר מחלקה בפועל) מה היו ספירות ה- FP עבור המחלקות האחרות. עבור הספירות לעיל, התצוגה שלנו תהיה כדלקמן:
| ציפור חזויה | מטוס חזוי | סופרמן חזוי | |
|---|---|---|---|
| ציפור אמיתית | 0 | 2 | 1 |
| מטוס בפועל | 1 | 0 | 3 |
| סופרמן אמיתי | 2 | 3 | 0 |
כאשר התמונות בעצם הכילו bird חזינו בטעות plane פעמיים ואת superman פעם אחת.
3) ספירה שלילית כוזבת
במקרה זה, עבור שורה נתונה (כלומר מחלקה בפועל) מה היו ספירות FN עבור המחלקות האחרות. עבור הספירות לעיל, התצוגה שלנו תהיה כדלקמן:
| ציפור חזויה | מטוס חזוי | סופרמן חזוי | |
|---|---|---|---|
| ציפור אמיתית | 2 | 2 | 4 |
| מטוס בפועל | 1 | 4 | 3 |
| סופרמן אמיתי | 2 | 2 | 5 |
כשהתמונות בעצם הכילו bird לא הצלחנו לחזות אותה 2 פעמים. יחד עם זאת, לא הצלחנו לחזות plane 2 פעמים superman 4 פעמים.
מדוע אני מקבל הודעת שגיאה לגבי מפתח חיזוי לא נמצא?
חלק מהמודלים מוציאים את התחזית שלהם בצורה של מילון. לדוגמה, מעריך TF לבעיית סיווג בינארי מוציא מילון המכיל probabilities , class_ids וכו'. ברוב המקרים ל-TFMA יש ברירות מחדל למציאת שמות מפתח בשימוש נפוץ כגון predictions , probabilities וכו'. עם זאת, אם המודל שלך מותאם מאוד, הוא עשוי מפתחות פלט תחת שמות שאינם ידועים על ידי TFMA. במקרים אלו יש להוסיף הגדרת prediciton_key ל- tfma.ModelSpec כדי לזהות את שם המפתח תחתיו מאוחסן הפלט.