
ژنرال
آیا یک EvalSavedModel هنوز مورد نیاز است؟
قبلاً TFMA نیاز داشت که تمام معیارها با استفاده از EvalSavedModel ویژه در یک نمودار tensorflow ذخیره شوند. اکنون، متریک ها را می توان خارج از نمودار TF با استفاده از پیاده سازی های beam.CombineFn محاسبه کرد.
برخی از تفاوت های اصلی عبارتند از:
- یک
EvalSavedModelبه یک صادرات ویژه از مربی نیاز دارد در حالی که یک مدل سرویسدهی میتواند بدون هیچ تغییری در کد آموزشی مورد استفاده قرار گیرد. - هنگامی که از
EvalSavedModelاستفاده می شود، هر معیاری که در زمان آموزش اضافه می شود، به طور خودکار در زمان ارزیابی در دسترس است. بدونEvalSavedModelاین معیارها باید دوباره اضافه شوند.- استثنای این قانون این است که اگر از یک مدل keras استفاده شود، متریک ها نیز می توانند به طور خودکار اضافه شوند زیرا keras اطلاعات متریک را در کنار مدل ذخیره شده ذخیره می کند.
آیا TFMA می تواند هم با معیارهای درون گراف و هم با معیارهای خارجی کار کند؟
TFMA اجازه می دهد تا از یک رویکرد ترکیبی استفاده شود که در آن برخی از معیارها را می توان در نمودار محاسبه کرد، در حالی که سایر معیارها را می توان در خارج محاسبه کرد. اگر در حال حاضر EvalSavedModel دارید، می توانید به استفاده از آن ادامه دهید.
دو مورد وجود دارد:
- از TFMA
EvalSavedModelهم برای استخراج ویژگی و هم برای محاسبات متریک استفاده کنید، اما معیارهای مبتنی بر ترکیب کننده اضافی را نیز اضافه کنید. در این مورد، تمام معیارهای درون گراف را ازEvalSavedModelبه همراه هر معیار دیگری از ترکیبکننده که ممکن است قبلاً پشتیبانی نمیشد، دریافت کنید. - از TFMA
EvalSavedModelبرای استخراج ویژگی/پیش بینی استفاده کنید اما از معیارهای مبتنی بر ترکیب برای همه محاسبات متریک استفاده کنید. این حالت در صورتی مفید است که درEvalSavedModelتبدیلهای ویژگی وجود داشته باشد که میخواهید از آنها برای برش استفاده کنید، اما ترجیح میدهید همه محاسبات متریک را خارج از نمودار انجام دهید.
راه اندازی
چه مدل هایی پشتیبانی می شوند؟
TFMA از مدلهای keras، مدلهای مبتنی بر APIهای عمومی امضای TF2، و همچنین مدلهای مبتنی بر برآوردگر TF پشتیبانی میکند (اگرچه بسته به مورد استفاده، مدلهای مبتنی بر برآوردگر ممکن است نیاز به استفاده از EvalSavedModel داشته باشند).
راهنمای get_started را برای لیست کامل انواع مدل های پشتیبانی شده و هرگونه محدودیت ببینید.
چگونه TFMA را برای کار با یک مدل مبتنی بر keras تنظیم کنم؟
در زیر یک نمونه پیکربندی برای یک مدل keras بر اساس مفروضات زیر است:
- مدل ذخیره شده برای سرویس است و از نام امضا
serving_defaultاستفاده می کند (این را می توان با استفاده ازmodel_specs[0].signature_nameتغییر داد). - معیارهای ساخته شده از
model.compile(...)باید ارزیابی شوند (این را می توان از طریقoptions.include_default_metricدر tfma.EvalConfig غیرفعال کرد).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
برای اطلاعات بیشتر در مورد سایر انواع معیارهای قابل پیکربندی به معیارها مراجعه کنید.
چگونه TFMA را برای کار با یک مدل عمومی مبتنی بر امضای TF2 تنظیم کنم؟
در زیر یک نمونه پیکربندی برای یک مدل عمومی TF2 آورده شده است. در زیر signature_name نام امضای خاصی است که باید برای ارزیابی استفاده شود.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
برای اطلاعات بیشتر در مورد سایر انواع معیارهای قابل پیکربندی به معیارها مراجعه کنید.
چگونه TFMA را برای کار با یک مدل مبتنی بر برآوردگر تنظیم کنم؟
در این مورد سه انتخاب وجود دارد.
گزینه 1: از مدل خدمت استفاده کنید
اگر از این گزینه استفاده شود، هر معیاری که در طول آموزش اضافه شود، در ارزیابی لحاظ نخواهد شد.
شکل زیر یک نمونه پیکربندی است که فرض میکند serving_default نام امضای مورد استفاده است:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
برای اطلاعات بیشتر در مورد سایر انواع معیارهای قابل پیکربندی به معیارها مراجعه کنید.
گزینه 2: از EvalSavedModel به همراه معیارهای دیگر مبتنی بر ترکیب کننده استفاده کنید
در این مورد، از EvalSavedModel برای استخراج و ارزیابی ویژگی/پیشبینی و همچنین اضافه کردن معیارهای مبتنی بر ترکیبکننده اضافی استفاده کنید.
در زیر یک نمونه پیکربندی است:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
برای اطلاعات بیشتر در مورد انواع دیگر معیارهای قابل پیکربندی به معیارها و برای اطلاعات بیشتر در مورد راه اندازی EvalSavedModel به EvalSavedModel مراجعه کنید.
گزینه 3: از مدل EvalSavedModel فقط برای استخراج ویژگی / پیش بینی استفاده کنید
مشابه گزینه (2) است، اما فقط از EvalSavedModel برای استخراج ویژگی / پیش بینی استفاده کنید. این گزینه در صورتی مفید است که فقط معیارهای خارجی مورد نظر باشد، اما تغییرات ویژگی وجود دارد که میخواهید آنها را برش دهید. مشابه گزینه (1) هر معیاری که در طول آموزش اضافه شود در ارزیابی لحاظ نخواهد شد.
در این مورد پیکربندی مانند بالا است، فقط include_default_metrics غیرفعال است.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
برای اطلاعات بیشتر در مورد انواع دیگر معیارهای قابل پیکربندی به معیارها و برای اطلاعات بیشتر در مورد راه اندازی EvalSavedModel به EvalSavedModel مراجعه کنید.
چگونه TFMA را برای کار با مدل مبتنی بر مدل به تخمینگر keras تنظیم کنم؟
تنظیم keras model_to_estimator مشابه پیکربندی تخمینگر است. با این حال، چند تفاوت خاص در نحوه عملکرد مدل به برآوردگر وجود دارد. به طور خاص، مدل به شبیهساز خروجیهای خود را به شکل دیکت برمیگرداند که در آن کلید dict نام آخرین لایه خروجی در مدل keras مرتبط است (اگر نامی ارائه نشده باشد، keras یک نام پیشفرض برای شما انتخاب میکند. مانند dense_1 یا output_1 ). از منظر TFMA، این رفتار مشابه آنچه برای یک مدل چند خروجی خروجی میشود، است، حتی اگر مدل به تخمینگر فقط برای یک مدل باشد. برای محاسبه این تفاوت، یک مرحله اضافی برای تنظیم نام خروجی لازم است. با این حال، همان سه گزینه به عنوان برآوردگر اعمال می شود.
در زیر نمونه ای از تغییرات مورد نیاز در یک پیکربندی مبتنی بر برآوردگر آورده شده است:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
چگونه می توانم TFMA را برای کار با پیش بینی های از پیش محاسبه شده (یعنی مدل-اگنوستیک) تنظیم کنم؟ ( TFRecord و tf.Example )
برای پیکربندی TFMA برای کار با پیشبینیهای از پیش محاسبهشده، tfma.PredictExtractor پیشفرض باید غیرفعال شود و tfma.InputExtractor باید برای تجزیه پیشبینیها به همراه سایر ویژگیهای ورودی پیکربندی شود. این کار با پیکربندی tfma.ModelSpec با نام کلید ویژگی که برای پیشبینیها در کنار برچسبها و وزنها استفاده میشود، انجام میشود.
در زیر نمونه ای از تنظیمات است:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
برای اطلاعات بیشتر در مورد معیارهای قابل پیکربندی به معیارها مراجعه کنید.
توجه داشته باشید که اگرچه یک tfma.ModelSpec در حال پیکربندی است، یک مدل در واقع استفاده نمی شود (یعنی tfma.EvalSharedModel وجود ندارد). فراخوانی برای اجرای تحلیل مدل ممکن است به صورت زیر باشد:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
چگونه می توانم TFMA را برای کار با پیش بینی های از پیش محاسبه شده (یعنی مدل-اگنوستیک) تنظیم کنم؟ ( pd.DataFrame )
برای مجموعه دادههای کوچکی که میتوانند در حافظه جای بگیرند، یک جایگزین برای TFRecord یک pandas.DataFrame s است. TFMA میتواند روی pandas.DataFrame با استفاده از tfma.analyze_raw_data API کار کند. برای توضیح tfma.MetricsSpec و tfma.SlicingSpec ، راهنمای نصب را ببینید. برای اطلاعات بیشتر در مورد معیارهای قابل پیکربندی به معیارها مراجعه کنید.
در زیر نمونه ای از تنظیمات است:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
معیارها
چه نوع معیارهایی پشتیبانی می شوند؟
TFMA طیف گسترده ای از معیارها را پشتیبانی می کند از جمله:
- معیارهای رگرسیون
- معیارهای طبقه بندی باینری
- معیارهای طبقه بندی چند کلاسه/چند برچسبی
- معیارهای میانگین میکرو / میانگین کلان
- معیارهای مبتنی بر پرس و جو / رتبه بندی
آیا معیارهای مدلهای چند خروجی پشتیبانی میشوند؟
بله. برای جزئیات بیشتر به راهنمای معیارها مراجعه کنید.
آیا معیارهای چند مدل پشتیبانی می شود؟
بله. برای جزئیات بیشتر به راهنمای معیارها مراجعه کنید.
آیا می توان تنظیمات متریک (نام و غیره) را سفارشی کرد؟
بله. تنظیمات متریک را می توان با افزودن تنظیمات config به پیکربندی متریک سفارشی کرد (مثلاً تعیین آستانه های خاص و غیره). راهنمای معیارها را ببینید جزئیات بیشتری دارد.
آیا معیارهای سفارشی پشتیبانی می شوند؟
بله. یا با نوشتن یک پیاده سازی سفارشی tf.keras.metrics.Metric یا با نوشتن یک پیاده سازی سفارشی beam.CombineFn . راهنمای متریک جزئیات بیشتری دارد.
چه نوع معیارهایی پشتیبانی نمی شوند؟
تا زمانی که می توان متریک شما را با استفاده از beam.CombineFn محاسبه کرد، هیچ محدودیتی برای انواع معیارهایی که می توان بر اساس tfma.metrics.Metric محاسبه کرد وجود ندارد. اگر با متریک مشتق شده از tf.keras.metrics.Metric کار کنید، باید معیارهای زیر رعایت شود:
- باید بتوان آمار کافی برای متریک را در هر مثال به طور مستقل محاسبه کرد، سپس این آمارهای کافی را با جمع کردن آنها در تمام مثالها ترکیب کرد و مقدار متریک را تنها از روی این آمار کافی تعیین کرد.
- به عنوان مثال، برای صحت، آمار کافی عبارتند از «کل صحیح» و «مثال کل». میتوان این دو عدد را برای مثالهای جداگانه محاسبه کرد و آنها را برای گروهی از مثالها جمع کرد تا مقادیر مناسب برای آن مثالها به دست آید. دقت نهایی را می توان با استفاده از "مجموع صحیح / نمونه کل" محاسبه کرد.
افزونه ها
آیا می توانم از TFMA برای ارزیابی عدالت یا سوگیری در مدل خود استفاده کنم؟
TFMA شامل یک افزونه FairnessIndicators است که معیارهای پس از صادرات را برای ارزیابی اثرات سوگیری ناخواسته در مدلهای طبقهبندی ارائه میکند.
سفارشی سازی
اگر به سفارشی سازی بیشتری نیاز داشته باشم چه می شود؟
TFMA بسیار انعطافپذیر است و به شما امکان میدهد تقریباً تمام قسمتهای خط لوله را با استفاده از Extractors ، Evaluators ، و/یا Writers سفارشیسازی کنید. این انتزاعات با جزئیات بیشتری در سند معماری مورد بحث قرار گرفته است.
عیب یابی، اشکال زدایی و دریافت کمک
چرا معیارهای MultiClassConfusionMatrix با معیارهای ConfusionMatrix باینریزه مطابقت ندارند
اینها در واقع محاسبات متفاوتی هستند. Binarization یک مقایسه را برای هر ID کلاس به طور مستقل انجام می دهد (یعنی پیش بینی برای هر کلاس به طور جداگانه با آستانه های ارائه شده مقایسه می شود). در این حالت ممکن است دو یا چند کلاس همه نشان دهند که با پیشبینی مطابقت دارند زیرا مقدار پیشبینیشدهشان از آستانه بزرگتر است (این در آستانههای پایینتر حتی بیشتر آشکار خواهد شد). در مورد ماتریس سردرگمی چند کلاسه، هنوز فقط یک مقدار پیشبینیشده واقعی وجود دارد و یا با مقدار واقعی مطابقت دارد یا نه. آستانه فقط برای وادار کردن یک پیشبینی برای مطابقت با هیچ کلاسی در صورتی استفاده میشود که کمتر از آستانه باشد. هر چه آستانه بالاتر باشد، تطبیق پیشبینی کلاس باینریزه سختتر است. به همین ترتیب، هرچه آستانه پایینتر باشد، تطبیق پیشبینیهای یک کلاس باینریزه آسانتر است. به این معنی که در آستانه های > 0.5 مقادیر باینریزه شده و مقادیر ماتریس چند کلاسه تراز بیشتری خواهند داشت و در آستانه های <0.5 از هم دورتر خواهند بود.
برای مثال، فرض کنید 10 کلاس داریم که کلاس 2 با احتمال 0.8 پیش بینی شده بود، اما کلاس واقعی کلاس 1 بود که احتمال 0.15 داشت. اگر در کلاس 1 باینریزه کنید و از آستانه 0.1 استفاده کنید، کلاس 1 صحیح در نظر گرفته می شود (0.15 > 0.1) بنابراین به عنوان یک TP حساب می شود، اما برای حالت چند کلاسه، کلاس 2 صحیح در نظر گرفته می شود (0.8 > 0.1) و از آنجایی که کلاس 1 واقعی بود، به عنوان یک FN محاسبه می شود. از آنجایی که در آستانههای پایینتر مقادیر بیشتری مثبت در نظر گرفته میشوند، به طور کلی تعداد TP و FP بالاتری برای ماتریس سردرگمی بایناریزه نسبت به ماتریس سردرگمی چند کلاسه و به طور مشابه TN و FN پایینتری وجود خواهد داشت.
در زیر نمونه ای از تفاوت های مشاهده شده بین MultiClassConfusionMatrixAtThresholds و تعداد مربوطه از باینری شدن یکی از کلاس ها آمده است.
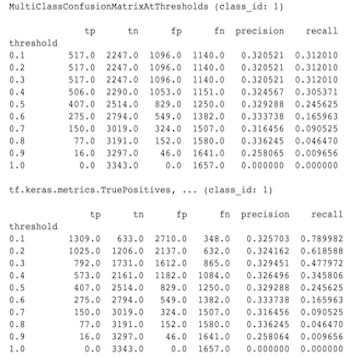
چرا معیارهای precision@1 و recall@1 من ارزش یکسانی دارند؟
در مقدار بالای k 1 دقت و فراخوانی یکسان هستند. دقت برابر با TP / (TP + FP) و فراخوانی برابر با TP / (TP + FN) است. پیشبینی برتر همیشه مثبت است و یا مطابقت دارد یا با برچسب مطابقت ندارد. به عبارت دیگر، با N مثال، TP + FP = N . با این حال، اگر برچسب با پیشبینی بالا مطابقت نداشته باشد، این نشان میدهد که یک پیشبینی غیر بالای k مطابقت داده شده است و با k بالای 1 تنظیم شده است، همه پیشبینیهای غیربالا 1 0 خواهند بود. این نشان میدهد که FN باید (N - TP) باشد. (N - TP) یا N = TP + FN . نتیجه نهایی precision@1 = TP / N = recall@1 است. توجه داشته باشید که این فقط زمانی اعمال می شود که در هر نمونه یک برچسب وجود داشته باشد، نه برای چند برچسب.
چرا معیارهای mean_label و mean_prediction همیشه 0.5 هستند؟
این به احتمال زیاد به این دلیل است که معیارها برای یک مشکل طبقهبندی باینری پیکربندی شدهاند، اما مدل بهجای تنها یک، احتمالات را برای هر دو کلاس خروجی میدهد. زمانی که از API طبقهبندی تنسورفلو استفاده میشود، این امر رایج است. راه حل این است که کلاسی را انتخاب کنید که می خواهید پیش بینی ها بر اساس آن باشد و سپس روی آن کلاس باینریزه کنید. به عنوان مثال:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
چگونه MultiLabelConfusionMatrixPlot را تفسیر کنیم؟
با توجه به یک برچسب خاص، MultiLabelConfusionMatrixPlot (و MultiLabelConfusionMatrix مربوطه) را می توان برای مقایسه نتایج سایر برچسب ها و پیش بینی های آنها در زمانی که برچسب انتخابی واقعاً درست بود استفاده کرد. به عنوان مثال، فرض کنید که ما سه کلاس bird ، plane و superman داریم و در حال طبقه بندی تصاویر هستیم تا مشخص کنیم که آیا آنها شامل یک یا چند کلاس از این کلاس ها هستند یا خیر. MultiLabelConfusionMatrix حاصل ضرب دکارتی هر کلاس واقعی را در مقابل یک کلاس دیگر (به نام کلاس پیش بینی شده) محاسبه می کند. توجه داشته باشید که در حالی که جفتسازی (actual, predicted) است، کلاس predicted لزوماً متضمن پیشبینی مثبت نیست، بلکه صرفاً ستون پیشبینیشده را در ماتریس واقعی در مقابل پیشبینیشده نشان میدهد. به عنوان مثال، فرض کنید ماتریس های زیر را محاسبه کرده ایم:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot سه راه برای نمایش این داده ها دارد. در همه موارد، روش خواندن جدول، سطر به سطر از دیدگاه کلاس واقعی است.
1) تعداد کل پیش بینی
در این مورد، برای یک ردیف معین (یعنی کلاس واقعی) تعداد TP + FP برای کلاس های دیگر چقدر بود. برای شمارش های بالا، نمایش ما به صورت زیر خواهد بود:
| پرنده پیش بینی شده | هواپیمای پیش بینی شده | سوپرمن را پیش بینی کرد | |
|---|---|---|---|
| پرنده واقعی | 6 | 4 | 2 |
| هواپیمای واقعی | 4 | 4 | 4 |
| سوپرمن واقعی | 5 | 5 | 4 |
هنگامی که تصاویر واقعاً حاوی یک bird بود، 6 مورد از آنها را به درستی پیشبینی کردیم. در همان زمان plane (به درستی یا اشتباه) را 4 بار و superman (به درستی یا اشتباه) را 2 بار پیش بینی کردیم.
2) تعداد پیش بینی نادرست
در این مورد، برای یک ردیف معین (یعنی کلاس واقعی) تعداد FP برای کلاس های دیگر چقدر بود. برای شمارش های بالا، نمایش ما به صورت زیر خواهد بود:
| پرنده پیش بینی شده | هواپیمای پیش بینی شده | سوپرمن را پیش بینی کرد | |
|---|---|---|---|
| پرنده واقعی | 0 | 2 | 1 |
| هواپیمای واقعی | 1 | 0 | 3 |
| سوپرمن واقعی | 2 | 3 | 0 |
هنگامی که تصاویر واقعاً حاوی یک bird بود، ما plane 2 بار و superman 1 بار به اشتباه پیش بینی کردیم.
3) شمارش منفی کاذب
در این مورد، برای یک ردیف معین (یعنی کلاس واقعی) تعداد FN برای کلاس های دیگر چقدر بود. برای شمارش های بالا، نمایش ما به صورت زیر خواهد بود:
| پرنده پیش بینی شده | هواپیمای پیش بینی شده | سوپرمن را پیش بینی کرد | |
|---|---|---|---|
| پرنده واقعی | 2 | 2 | 4 |
| هواپیمای واقعی | 1 | 4 | 3 |
| سوپرمن واقعی | 2 | 2 | 5 |
هنگامی که تصاویر واقعاً حاوی یک bird بود، ما 2 بار نتوانستیم آن را پیش بینی کنیم. در عین حال 2 بار plane و 4 بار superman را پیش بینی نکردیم.
چرا با خطای کلید پیش بینی یافت نشد مواجه می شوم؟
برخی از مدل ها پیش بینی خود را در قالب یک دیکشنری خروجی می دهند. به عنوان مثال، یک برآوردگر TF برای مشکل طبقهبندی باینری، فرهنگ لغت حاوی probabilities ، class_ids و غیره را خروجی میدهد. در بیشتر موارد TFMA دارای پیشفرضهایی برای یافتن نامهای کلیدی رایج مانند predictions ، probabilities ، و غیره است. با این حال، اگر مدل شما بسیار سفارشیسازی شده باشد، ممکن است کلیدهای خروجی تحت نام هایی که توسط TFMA شناخته نشده اند. در این موارد یک تنظیم prediciton_key باید به tfma.ModelSpec اضافه شود تا نام کلیدی که خروجی در آن ذخیره میشود مشخص شود.