
General
¿Aún se requiere un EvalSavedModel?
Anteriormente, TFMA requería que todas las métricas se almacenaran dentro de un gráfico de tensorflow utilizando un EvalSavedModel especial. Ahora, las métricas se pueden calcular fuera del gráfico TF utilizando implementaciones beam.CombineFn .
Algunas de las principales diferencias son:
- Un
EvalSavedModelrequiere una exportación especial del entrenador, mientras que un modelo de entrega se puede usar sin necesidad de realizar cambios en el código de entrenamiento. - Cuando se utiliza un
EvalSavedModel, cualquier métrica agregada en el momento del entrenamiento está disponible automáticamente en el momento de la evaluación. Sin unEvalSavedModelestas métricas se deben volver a agregar.- La excepción a esta regla es que si se utiliza un modelo de Keras, las métricas también se pueden agregar automáticamente porque Keras guarda la información de las métricas junto con el modelo guardado.
¿Puede TFMA funcionar tanto con métricas en el gráfico como con métricas externas?
TFMA permite utilizar un enfoque híbrido en el que algunas métricas se pueden calcular en el gráfico mientras que otras se pueden calcular fuera. Si actualmente tiene un EvalSavedModel , puede continuar usándolo.
Hay dos casos:
- Utilice TFMA
EvalSavedModeltanto para la extracción de características como para los cálculos de métricas, pero también agregue métricas adicionales basadas en combinadores. En este caso, obtendría todas las métricas en el gráfico deEvalSavedModeljunto con cualquier métrica adicional del combinador que podría no haber sido compatible anteriormente. - Utilice TFMA
EvalSavedModelpara la extracción de características/predicciones, pero utilice métricas basadas en combinadores para todos los cálculos de métricas. Este modo es útil si hay transformaciones de características presentes enEvalSavedModelque le gustaría usar para dividir, pero prefiere realizar todos los cálculos métricos fuera del gráfico.
Configuración
¿Qué tipos de modelos son compatibles?
TFMA admite modelos keras, modelos basados en API genéricas de firma TF2, así como modelos basados en estimadores TF (aunque dependiendo del caso de uso, los modelos basados en estimadores pueden requerir el uso de un EvalSavedModel ).
Consulte la guía get_started para obtener la lista completa de tipos de modelos admitidos y sus restricciones.
¿Cómo configuro TFMA para que funcione con un modelo nativo basado en keras?
La siguiente es una configuración de ejemplo para un modelo de Keras basada en las siguientes suposiciones:
- El modelo guardado es para servir y usa el nombre de firma
serving_default(esto se puede cambiar usandomodel_specs[0].signature_name). - Se deben evaluar las métricas integradas de
model.compile(...)(esto se puede deshabilitar medianteoptions.include_default_metricdentro de tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obtener más información sobre otros tipos de métricas que se pueden configurar.
¿Cómo configuro TFMA para que funcione con un modelo genérico basado en firmas TF2?
La siguiente es una configuración de ejemplo para un modelo TF2 genérico. A continuación, signature_name es el nombre de la firma específica que se debe utilizar para la evaluación.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obtener más información sobre otros tipos de métricas que se pueden configurar.
¿Cómo configuro TFMA para que funcione con un modelo basado en estimador?
En este caso hay tres opciones.
Opción 1: utilizar el modelo de publicación
Si se utiliza esta opción, las métricas agregadas durante la capacitación NO se incluirán en la evaluación.
La siguiente es una configuración de ejemplo suponiendo que serving_default es el nombre de firma utilizado:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obtener más información sobre otros tipos de métricas que se pueden configurar.
Opción 2: utilizar EvalSavedModel junto con métricas adicionales basadas en combinadores
En este caso, utilice EvalSavedModel para la extracción y evaluación de características/predicciones y también agregue métricas adicionales basadas en combinadores.
La siguiente es una configuración de ejemplo:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obtener más información sobre otros tipos de métricas que se pueden configurar y EvalSavedModel para obtener más información sobre cómo configurar EvalSavedModel.
Opción 3: utilizar el modelo EvalSavedModel solo para extracción de características/predicciones
Similar a la opción (2), pero solo usa EvalSavedModel para la extracción de características/predicciones. Esta opción es útil si solo se desean métricas externas, pero hay transformaciones de características que le gustaría dividir. De manera similar a la opción (1), cualquier métrica agregada durante la capacitación NO se incluirá en la evaluación.
En este caso, la configuración es la misma que la anterior, solo que include_default_metrics está deshabilitado.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Consulte métricas para obtener más información sobre otros tipos de métricas que se pueden configurar y EvalSavedModel para obtener más información sobre cómo configurar EvalSavedModel.
¿Cómo configuro TFMA para que funcione con un modelo basado en modelo a estimador de Keras?
La configuración de keras model_to_estimator es similar a la configuración del estimador. Sin embargo, existen algunas diferencias específicas en el funcionamiento del modelo al estimador. En particular, el model-to-esimtator devuelve sus resultados en forma de un dict donde la clave dict es el nombre de la última capa de salida en el modelo keras asociado (si no se proporciona ningún nombre, keras elegirá un nombre predeterminado para usted). como dense_1 o output_1 ). Desde la perspectiva de TFMA, este comportamiento es similar a lo que sería el resultado de un modelo de múltiples resultados, aunque el modelo a estimar puede ser solo para un modelo único. Para tener en cuenta esta diferencia, se requiere un paso adicional para configurar el nombre de salida. Sin embargo, se aplican las mismas tres opciones como estimador.
El siguiente es un ejemplo de los cambios necesarios en una configuración basada en estimador:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
¿Cómo configuro TFMA para que funcione con predicciones precalculadas (es decir, independientes del modelo)? ( TFRecord y tf.Example )
Para configurar TFMA para que funcione con predicciones precalculadas, el tfma.PredictExtractor predeterminado debe estar deshabilitado y el tfma.InputExtractor debe configurarse para analizar las predicciones junto con las otras funciones de entrada. Esto se logra configurando tfma.ModelSpec con el nombre de la clave de función utilizada para las predicciones junto con las etiquetas y los pesos.
El siguiente es un ejemplo de configuración:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulte métricas para obtener más información sobre las métricas que se pueden configurar.
Tenga en cuenta que, aunque se está configurando un tfma.ModelSpec , en realidad no se está utilizando un modelo (es decir, no hay ningún tfma.EvalSharedModel ). La llamada para ejecutar el análisis del modelo podría tener el siguiente aspecto:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
¿Cómo configuro TFMA para que funcione con predicciones precalculadas (es decir, independientes del modelo)? ( pd.DataFrame )
Para conjuntos de datos pequeños que caben en la memoria, una alternativa a TFRecord es pandas.DataFrame s. TFMA puede operar en pandas.DataFrame usando la API tfma.analyze_raw_data . Para obtener una explicación de tfma.MetricsSpec y tfma.SlicingSpec , consulte la guía de configuración . Consulte métricas para obtener más información sobre las métricas que se pueden configurar.
El siguiente es un ejemplo de configuración:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Métrica
¿Qué tipos de métricas se admiten?
TFMA admite una amplia variedad de métricas que incluyen:
- métricas de regresión
- métricas de clasificación binaria
- métricas de clasificación de múltiples clases/múltiples etiquetas
- Métricas micropromedio/macropromedio
- Métricas basadas en consultas/clasificaciones
¿Se admiten métricas de modelos de múltiples salidas?
Sí. Consulte la guía de métricas para obtener más detalles.
¿Se admiten métricas de múltiples modelos?
Sí. Consulte la guía de métricas para obtener más detalles.
¿Se pueden personalizar las configuraciones de métricas (nombre, etc.)?
Sí. La configuración de las métricas se puede personalizar (por ejemplo, estableciendo umbrales específicos, etc.) agregando ajustes config a la configuración de la métrica. Ver guía de métricas tiene más detalles.
¿Se admiten métricas personalizadas?
Sí. Ya sea escribiendo una implementación personalizada tf.keras.metrics.Metric o escribiendo una implementación personalizada beam.CombineFn . La guía de métricas tiene más detalles.
¿Qué tipos de métricas no se admiten?
Siempre que su métrica se pueda calcular utilizando beam.CombineFn , no existen restricciones sobre los tipos de métricas que se pueden calcular en función de tfma.metrics.Metric . Si trabaja con una métrica derivada de tf.keras.metrics.Metric , se deben cumplir los siguientes criterios:
- Debería ser posible calcular estadísticas suficientes para la métrica en cada ejemplo de forma independiente, luego combinar estas estadísticas suficientes sumándolas en todos los ejemplos y determinar el valor de la métrica únicamente a partir de estas estadísticas suficientes.
- Por ejemplo, para mayor precisión, las estadísticas suficientes son "totalmente correctas" y "totalmente ejemplos". Es posible calcular estos dos números para ejemplos individuales y sumarlos para un grupo de ejemplos para obtener los valores correctos para esos ejemplos. La precisión final se puede calcular utilizando "ejemplos totales correctos / totales".
Complementos
¿Puedo usar TFMA para evaluar la equidad o el sesgo en mi modelo?
TFMA incluye un complemento FairnessIndicators que proporciona métricas posteriores a la exportación para evaluar los efectos del sesgo no deseado en los modelos de clasificación.
Personalización
¿Qué pasa si necesito más personalización?
TFMA es muy flexible y le permite personalizar casi todas las partes de la canalización utilizando Extractors , Evaluators y/o Writers personalizados. Estas abstracciones se analizan con más detalle en el documento de arquitectura .
Solución de problemas, depuración y obtención de ayuda
¿Por qué las métricas de MultiClassConfusionMatrix no coinciden con las métricas binarizadas de ConfusionMatrix?
En realidad, estos son cálculos diferentes. La binarización realiza una comparación para cada ID de clase de forma independiente (es decir, la predicción para cada clase se compara por separado con los umbrales proporcionados). En este caso, es posible que dos o más clases indiquen que coincidieron con la predicción porque su valor predicho fue mayor que el umbral (esto será aún más evidente en umbrales más bajos). En el caso de la matriz de confusión multiclase, todavía hay un solo valor predicho verdadero y coincide con el valor real o no. El umbral solo se utiliza para forzar que una predicción no coincida con ninguna clase si es menor que el umbral. Cuanto mayor sea el umbral, más difícil será igualar la predicción de una clase binarizada. Del mismo modo, cuanto más bajo sea el umbral, más fácil será que coincidan las predicciones de una clase binarizada. Esto significa que en umbrales > 0,5 los valores binarizados y los valores de la matriz multiclase estarán más alineados y en umbrales < 0,5 estarán más separados.
Por ejemplo, digamos que tenemos 10 clases donde la clase 2 se predijo con una probabilidad de 0,8, pero la clase real era la clase 1, que tenía una probabilidad de 0,15. Si binariza en la clase 1 y utiliza un umbral de 0,1, entonces la clase 1 se considerará correcta (0,15 > 0,1), por lo que se contará como TP. Sin embargo, para el caso multiclase, la clase 2 se considerará correcta (0,8 > 0.1) y dado que la clase 1 era la real, esto se contará como FN. Debido a que en umbrales más bajos se considerarán más valores positivos, en general habrá recuentos de TP y FP más altos para la matriz de confusión binarizada que para la matriz de confusión multiclase, y de manera similar, TN y FN serán más bajos.
El siguiente es un ejemplo de las diferencias observadas entre MultiClassConfusionMatrixAtThresholds y los recuentos correspondientes de la binarización de una de las clases.
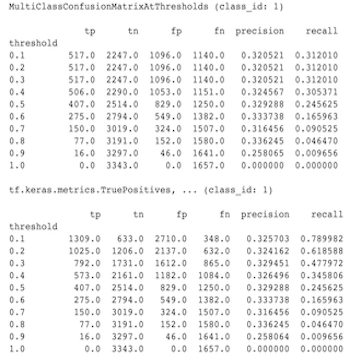
¿Por qué mis métricas precisión@1 y recuperación@1 tienen el mismo valor?
En un valor k superior de 1, la precisión y la recuperación son lo mismo. La precisión es igual a TP / (TP + FP) y la recuperación es igual a TP / (TP + FN) . La predicción superior siempre es positiva y coincidirá o no con la etiqueta. En otras palabras, con N ejemplos, TP + FP = N Sin embargo, si la etiqueta no coincide con la predicción principal, esto también implica que se coincidió con una predicción k no superior y con k superior establecido en 1, todas las predicciones 1 no principales serán 0. Esto implica que FN debe ser (N - TP) o N = TP + FN . El resultado final es precision@1 = TP / N = recall@1 . Tenga en cuenta que esto solo se aplica cuando hay una sola etiqueta por ejemplo, no para etiquetas múltiples.
¿Por qué mis métricas de etiqueta media y predicción media son siempre 0,5?
Lo más probable es que esto se deba a que las métricas están configuradas para un problema de clasificación binaria, pero el modelo genera probabilidades para ambas clases en lugar de solo una. Esto es común cuando se utiliza la API de clasificación de tensorflow . La solución es elegir la clase en la que desea que se basen las predicciones y luego binarizar esa clase. Por ejemplo:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
¿Cómo interpretar MultiLabelConfusionMatrixPlot?
Dada una etiqueta particular, MultiLabelConfusionMatrixPlot (y MultiLabelConfusionMatrix asociada) se pueden usar para comparar los resultados de otras etiquetas y sus predicciones cuando la etiqueta elegida era realmente cierta. Por ejemplo, digamos que tenemos tres clases bird , plane y superman y estamos clasificando imágenes para indicar si contienen una o más de cualquiera de estas clases. MultiLabelConfusionMatrix calculará el producto cartesiano de cada clase real frente a cada otra clase (llamada clase predicha). Tenga en cuenta que, si bien el emparejamiento es (actual, predicted) , la clase predicted no implica necesariamente una predicción positiva, simplemente representa la columna prevista en la matriz real frente a la prevista. Por ejemplo, digamos que hemos calculado las siguientes matrices:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot tiene tres formas de mostrar estos datos. En todos los casos la forma de leer la tabla es fila por fila desde la perspectiva de la clase real.
1) Recuento total de predicciones
En este caso, para una fila determinada (es decir, clase real), ¿cuáles fueron los recuentos TP + FP para las otras clases? Para los conteos anteriores, nuestra visualización sería la siguiente:
| pájaro predicho | Avión previsto | Superman predicho | |
|---|---|---|---|
| pájaro real | 6 | 4 | 2 |
| Avión real | 4 | 4 | 4 |
| superhombre real | 5 | 5 | 4 |
Cuando las imágenes en realidad contenían un bird predijimos correctamente 6 de ellos. Al mismo tiempo, también predijimos plane (correcta o incorrectamente) 4 veces y superman (correcta o incorrectamente) 2 veces.
2) Recuento de predicciones incorrecto
En este caso, para una fila determinada (es decir, clase real), ¿cuáles fueron los recuentos FP para las otras clases? Para los conteos anteriores, nuestra visualización sería la siguiente:
| pájaro predicho | Avión previsto | Superman predicho | |
|---|---|---|---|
| pájaro real | 0 | 2 | 1 |
| Avión real | 1 | 0 | 3 |
| superhombre real | 2 | 3 | 0 |
Cuando las imágenes en realidad contenían un bird , predijimos incorrectamente plane 2 veces y superman 1 vez.
3) Conteo falso negativo
En este caso, para una fila determinada (es decir, clase real), ¿cuáles fueron los recuentos FN para las otras clases? Para los conteos anteriores, nuestra visualización sería la siguiente:
| pájaro predicho | Avión previsto | Superman predicho | |
|---|---|---|---|
| pájaro real | 2 | 2 | 4 |
| Avión real | 1 | 4 | 3 |
| superhombre real | 2 | 2 | 5 |
Cuando las imágenes en realidad contenían un bird no pudimos predecirlo 2 veces. Al mismo tiempo, no pudimos predecir plane 2 veces y superman 4 veces.
¿Por qué recibo un error acerca de que no se encontró la clave de predicción?
Algunos modelos generan su predicción en forma de diccionario. Por ejemplo, un estimador TF para un problema de clasificación binaria genera un diccionario que contiene probabilities , class_ids , etc. En la mayoría de los casos, TFMA tiene valores predeterminados para encontrar nombres clave de uso común, como predictions , probabilities , etc. Sin embargo, si su modelo es muy personalizado, puede claves de salida con nombres desconocidos por TFMA. En estos casos, se debe agregar una configuración prediciton_key a tfma.ModelSpec para identificar el nombre de la clave bajo la cual se almacena la salida.