
Genel
EvalSavedModel hala gerekli mi?
Daha önce TFMA, tüm ölçümlerin özel bir EvalSavedModel kullanılarak bir tensor akışı grafiğinde saklanmasını gerektiriyordu. Artık ölçümler, beam.CombineFn uygulamaları kullanılarak TF grafiğinin dışında hesaplanabilir.
Temel farklılıklardan bazıları şunlardır:
-
EvalSavedModeleğiticiden özel bir dışa aktarım gerektirirken, bir sunum modeli, eğitim kodunda herhangi bir değişiklik yapılması gerekmeden kullanılabilir. -
EvalSavedModelkullanıldığında, eğitim zamanında eklenen tüm ölçümler değerlendirme zamanında otomatik olarak kullanılabilir.EvalSavedModelolmadan bu ölçümlerin yeniden eklenmesi gerekir.- Bu kuralın istisnası, eğer bir keras modeli kullanılırsa, keras metrik bilgilerini kaydedilen modelin yanında kaydettiği için metriklerin de otomatik olarak eklenebilmesidir.
TFMA hem grafik içi metriklerle hem de harici metriklerle çalışabilir mi?
TFMA, bazı metriklerin grafik içinde hesaplanabildiği, diğerlerinin ise grafik dışında hesaplanabildiği hibrit bir yaklaşımın kullanılmasına olanak tanır. Şu anda bir EvalSavedModel varsa onu kullanmaya devam edebilirsiniz.
İki durum var:
- Hem özellik çıkarma hem de metrik hesaplamalar için TFMA
EvalSavedModelkullanın, ancak aynı zamanda ek birleştirici tabanlı metrikler de ekleyin. Bu durumda,EvalSavedModeltüm grafik içi ölçümleri ve daha önce desteklenmemiş olabilecek birleştirici tabanlı ek ölçümleri alırsınız. - Özellik/tahmin çıkarma için TFMA
EvalSavedModelkullanın ancak tüm ölçüm hesaplamaları için birleştirici tabanlı ölçümleri kullanın. Bu mod,EvalSavedModeldilimleme için kullanmak istediğiniz özellik dönüşümleri mevcutsa ancak tüm metrik hesaplamaları grafiğin dışında gerçekleştirmeyi tercih ediyorsanız kullanışlıdır.
Kurmak
Hangi model türleri destekleniyor?
TFMA, keras modellerini, genel TF2 imza API'lerine dayalı modelleri ve TF tahmincisi tabanlı modelleri destekler (ancak kullanım durumuna bağlı olarak tahminci tabanlı modeller bir EvalSavedModel kullanılmasını gerektirebilir).
Desteklenen model türlerinin ve tüm kısıtlamaların tam listesi için get_started kılavuzuna bakın.
TFMA'yı yerel keras tabanlı bir modelle çalışacak şekilde nasıl ayarlayabilirim?
Aşağıda, aşağıdaki varsayımlara dayanan bir keras modeli için örnek bir yapılandırma verilmiştir:
- Kaydedilen model sunum içindir ve
serving_defaultimza adını kullanır (bumodel_specs[0].signature_namekullanılarak değiştirilebilir). -
model.compile(...)dosyasındaki yerleşik metrikler değerlendirilmelidir (bu, tfma.EvalConfig içindekioptions.include_default_metricaracılığıyla devre dışı bırakılabilir).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Yapılandırılabilecek diğer ölçüm türleri hakkında daha fazla bilgi için ölçümlere bakın.
TFMA'yı genel bir TF2 imza tabanlı modelle çalışacak şekilde nasıl ayarlayabilirim?
Aşağıda genel bir TF2 modeli için örnek bir yapılandırma verilmiştir. Aşağıda signature_name , değerlendirme için kullanılması gereken özel imzanın adıdır.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Yapılandırılabilecek diğer ölçüm türleri hakkında daha fazla bilgi için ölçümlere bakın.
Tahminci tabanlı bir modelle çalışacak şekilde TFMA'yı nasıl ayarlayabilirim?
Bu durumda üç seçenek var.
Seçenek1: Sunum Modelini Kullan
Bu seçenek kullanılırsa eğitim sırasında eklenen ölçümler değerlendirmeye dahil edilmeyecektir.
Aşağıda, kullanılan imza adının serving_default olduğunu varsayan örnek bir yapılandırma verilmiştir:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Yapılandırılabilecek diğer ölçüm türleri hakkında daha fazla bilgi için ölçümlere bakın.
Seçenek2: EvalSavedModel'i ek birleştirici tabanlı ölçümlerle birlikte kullanın
Bu durumda, hem özellik/tahmin çıkarma hem de değerlendirme için EvalSavedModel kullanın ve ayrıca ek birleştirici tabanlı ölçümler ekleyin.
Aşağıda örnek bir yapılandırma verilmiştir:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Yapılandırılabilecek diğer ölçüm türleri hakkında daha fazla bilgi için ölçümlere bakın ve EvalSavedModel'i ayarlama hakkında daha fazla bilgi için EvalSavedModel'e bakın .
Seçenek3: EvalSavedModel Modelini yalnızca Özellik / Tahmin Çıkarma için kullanın
Seçenek(2)'ye benzer, ancak özellik/tahmin çıkarma için yalnızca EvalSavedModel kullanın. Bu seçenek yalnızca harici ölçümler isteniyorsa kullanışlıdır ancak dilimlemek istediğiniz özellik dönüşümleri vardır. Seçenek (1)'e benzer şekilde, eğitim sırasında eklenen herhangi bir ölçüm değerlendirmeye dahil edilmeyecektir.
Bu durumda yapılandırma yukarıdakiyle aynıdır, yalnızca include_default_metrics devre dışıdır.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Yapılandırılabilecek diğer ölçüm türleri hakkında daha fazla bilgi için ölçümlere bakın ve EvalSavedModel'i ayarlama hakkında daha fazla bilgi için EvalSavedModel'e bakın .
TFMA'yı keras modelden tahminciye dayalı bir modelle çalışacak şekilde nasıl ayarlayabilirim?
Keras model_to_estimator kurulumu, tahmin edici yapılandırmasına benzer. Ancak modelden tahminciye çalışma şekline özgü birkaç farklılık vardır. Özellikle, model-tahmin edici, çıktılarını bir dict biçiminde döndürür; burada dict anahtarı, ilişkili keras modelindeki son çıktı katmanının adıdır (hiçbir ad belirtilmezse, keras sizin için varsayılan bir ad seçecektir) dense_1 veya output_1 gibi). TFMA perspektifinden bakıldığında bu davranış, tahminciye yönelik model yalnızca tek bir model için olsa bile, çok çıkışlı bir model için çıktıya benzer. Bu farkı hesaba katmak için çıkış adını ayarlamak için ek bir adım gerekir. Ancak tahmin edici olarak da aynı üç seçenek geçerlidir.
Tahminci tabanlı bir yapılandırmada gerekli değişikliklerin bir örneği aşağıdadır:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
TFMA'yı önceden hesaplanmış (örn. modelden bağımsız) tahminlerle çalışacak şekilde nasıl ayarlayabilirim? ( TFRecord ve tf.Example )
TFMA'yı önceden hesaplanmış tahminlerle çalışacak şekilde yapılandırmak için, varsayılan tfma.PredictExtractor devre dışı bırakılmalı ve tfma.InputExtractor diğer giriş özellikleriyle birlikte tahminleri ayrıştıracak şekilde yapılandırılmalıdır. Bu, etiketler ve ağırlıkların yanı sıra tahminler için kullanılan özellik anahtarının adıyla bir tfma.ModelSpec yapılandırılarak gerçekleştirilir.
Aşağıda örnek bir kurulum verilmiştir:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Yapılandırılabilecek ölçümler hakkında daha fazla bilgi için ölçümlere bakın.
Bir tfma.ModelSpec yapılandırılıyor olsa da aslında bir modelin kullanılmadığını unutmayın (yani tfma.EvalSharedModel yok). Model analizini çalıştırma çağrısı aşağıdaki gibi görünebilir:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
TFMA'yı önceden hesaplanmış (örn. modelden bağımsız) tahminlerle çalışacak şekilde nasıl ayarlayabilirim? ( pd.DataFrame )
Belleğe sığabilecek küçük veri kümeleri için TFRecord alternatifi pandas.DataFrame . TFMA, tfma.analyze_raw_data API'sini kullanarak pandas.DataFrame üzerinde çalışabilir. tfma.MetricsSpec ve tfma.SlicingSpec açıklaması için kurulum kılavuzuna bakın. Yapılandırılabilecek ölçümler hakkında daha fazla bilgi için ölçümlere bakın.
Aşağıda örnek bir kurulum verilmiştir:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Metrikler
Ne tür metrikler destekleniyor?
TFMA aşağıdakiler de dahil olmak üzere çok çeşitli ölçümleri destekler:
- regresyon metrikleri
- ikili sınıflandırma metrikleri
- çok sınıflı/çok etiketli sınıflandırma metrikleri
- mikro ortalama / makro ortalama metrikleri
- sorgu / sıralamaya dayalı metrikler
Çok çıkışlı modellerden alınan ölçümler destekleniyor mu?
Evet. Daha fazla ayrıntı için ölçüm kılavuzuna bakın.
Birden fazla modelden alınan ölçümler destekleniyor mu?
Evet. Daha fazla ayrıntı için ölçüm kılavuzuna bakın.
Metrik ayarları (isim vb.) özelleştirilebilir mi?
Evet. Metrik ayarları, metrik yapılandırmasına config ayarları eklenerek özelleştirilebilir (örneğin, belirli eşiklerin ayarlanması vb.). Metrik kılavuzunun daha fazla ayrıntıya sahip olduğuna bakın.
Özel metrikler destekleniyor mu?
Evet. Özel bir tf.keras.metrics.Metric uygulaması yazarak veya özel bir beam.CombineFn uygulaması yazarak. Metrik kılavuzunda daha fazla ayrıntı bulunmaktadır.
Hangi tür metrikler desteklenmiyor?
Metriğiniz bir beam.CombineFn kullanılarak hesaplanabildiği sürece, tfma.metrics.Metric temel alınarak hesaplanabilecek ölçüm türlerinde herhangi bir kısıtlama yoktur. tf.keras.metrics.Metric türetilen bir metrikle çalışıyorsanız aşağıdaki kriterlerin karşılanması gerekir:
- Her örnekte metrik için yeterli istatistikleri bağımsız olarak hesaplamak, ardından bu yeterli istatistikleri tüm örneklere ekleyerek birleştirmek ve metrik değerini yalnızca bu yeterli istatistiklerden belirlemek mümkün olmalıdır.
- Örneğin, doğruluk için yeterli istatistikler "tamamen doğru" ve "toplam örnekler"dir. Bireysel örnekler için bu iki sayıyı hesaplamak ve bu örnekler için doğru değerleri elde etmek amacıyla bunları bir grup örnek için toplamak mümkündür. Nihai doğruluk, "toplam doğru / toplam örnekler" kullanılarak hesaplanabilir.
Eklentiler
Modelimde adaleti veya önyargıyı değerlendirmek için TFMA'yı kullanabilir miyim?
TFMA, sınıflandırma modellerinde istenmeyen önyargıların etkilerini değerlendirmek için dışa aktarma sonrası ölçümler sağlayan bir FairnessIndicators eklentisi içerir.
Özelleştirme
Daha fazla özelleştirmeye ihtiyacım olursa ne olur?
TFMA çok esnektir ve özel Extractors , Evaluators ve/veya Writers kullanarak işlem hattının hemen hemen tüm bölümlerini özelleştirmenize olanak tanır. Bu soyutlamalar mimari belgesinde daha ayrıntılı olarak tartışılmaktadır.
Sorun giderme, hata ayıklama ve yardım alma
MultiClassConfusionMatrix ölçümleri neden ikili ConfusionMatrix ölçümleriyle eşleşmiyor?
Bunlar aslında farklı hesaplamalardır. İkilileştirme, her sınıf kimliği için bağımsız olarak bir karşılaştırma gerçekleştirir (yani her sınıfa yönelik tahmin, sağlanan eşik değerleriyle ayrı ayrı karşılaştırılır). Bu durumda, iki veya daha fazla sınıfın hepsinin tahminle eşleştiklerini belirtmeleri mümkündür çünkü tahmin edilen değerleri eşik değerinden daha yüksektir (bu, daha düşük eşik değerlerinde daha da belirgin olacaktır). Çok sınıflı karışıklık matrisi durumunda, hala yalnızca tek bir gerçek tahmin değeri vardır ve bu, gerçek değerle ya eşleşir ya da eşleşmez. Eşik yalnızca eşikten küçükse bir tahminin hiçbir sınıfla eşleşmemesini sağlamak için kullanılır. Eşik ne kadar yüksek olursa ikilileştirilmiş bir sınıfın tahmininin eşleşmesi o kadar zor olur. Benzer şekilde, eşik ne kadar düşük olursa, ikilileştirilmiş bir sınıfın tahminlerinin eşleşmesi o kadar kolay olur. Bu, > 0,5 eşik değerlerinde ikilileştirilmiş değerlerin ve çok sınıflı matris değerlerinin daha yakın hizalanacağı ve < 0,5 eşik değerlerinde ise birbirlerinden daha uzak olacağı anlamına gelir.
Örneğin, diyelim ki, sınıf 2'nin 0,8 olasılıkla tahmin edildiği, ancak gerçek sınıfın 0,15 olasılıkla sınıf 1 olduğu 10 sınıfımız olduğunu varsayalım. Sınıf 1'i ikilileştirirseniz ve 0,1'lik bir eşik kullanırsanız, sınıf 1 doğru kabul edilir (0,15 > 0,1), dolayısıyla TP olarak sayılır. Bununla birlikte, çoklu sınıf durumunda sınıf 2 doğru kabul edilir (0,8 > 0.1) ve sınıf 1 gerçek olduğundan bu bir FN olarak sayılacaktır. Daha düşük eşiklerde daha fazla değer pozitif olarak kabul edileceğinden, genel olarak ikilileştirilmiş karışıklık matrisi için çok sınıflı karışıklık matrisine göre daha yüksek TP ve FP sayıları ve benzer şekilde daha düşük TN ve FN olacaktır.
Aşağıda MultiClassConfusionMatrixAtThresholds ile sınıflardan birinin ikilileştirilmesinden elde edilen karşılık gelen sayımlar arasında gözlemlenen farkların bir örneği bulunmaktadır.
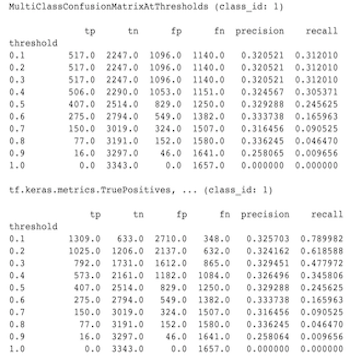
Precision@1 ve recall@1 ölçümlerim neden aynı değere sahip?
En üst k değeri olan 1'de kesinlik ve geri çağırma aynı şeydir. Hassasiyet TP / (TP + FP) ye eşittir ve geri çağırma TP / (TP + FN) ye eşittir. En iyi tahmin her zaman pozitiftir ve etiketle eşleşir veya eşleşmez. Başka bir deyişle, N örnekle TP + FP = N Bununla birlikte, etiket en iyi tahminle eşleşmezse, bu aynı zamanda en iyi k olmayan tahminin de eşleştiği anlamına gelir ve en iyi k 1'e ayarlandığında en iyi 1 olmayan tüm tahminler 0 olacaktır. Bu, FN'nin (N - TP) olması gerektiği anlamına gelir. (N - TP) veya N = TP + FN . Nihai sonuç precision@1 = TP / N = recall@1 olur. Bunun yalnızca örnek başına tek bir etiket olduğunda geçerli olduğunu, çoklu etiket için geçerli olmadığını unutmayın.
Ortalama_etiket ve ortalama_tahmin ölçümlerim neden her zaman 0,5?
Bunun nedeni büyük olasılıkla metriklerin ikili sınıflandırma problemi için yapılandırılmış olmasıdır, ancak model yalnızca bir sınıf yerine her iki sınıf için de olasılıklar çıkarmaktadır. Tensorflow'un sınıflandırma API'si kullanıldığında bu yaygındır. Çözüm, tahminlerin temel alınmasını istediğiniz sınıfı seçmek ve ardından o sınıfa göre ikili hale getirmektir. Örneğin:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
MultiLabelConfusionMatrixPlot nasıl yorumlanır?
Belirli bir etiket verildiğinde, MultiLabelConfusionMatrixPlot (ve ilişkili MultiLabelConfusionMatrix ), seçilen etiket gerçekten doğru olduğunda diğer etiketlerin sonuçlarını ve tahminlerini karşılaştırmak için kullanılabilir. Örneğin, bird , plane ve superman olmak üzere üç sınıfımız olduğunu ve resimleri bu sınıflardan birini veya birkaçını içerip içermediğini belirtmek için sınıflandırdığımızı varsayalım. MultiLabelConfusionMatrix her gerçek sınıfın diğer sınıfa (tahmin edilen sınıf olarak adlandırılır) karşı kartezyen çarpımını hesaplayacaktır. Eşleştirme (actual, predicted) olmasına rağmen, predicted sınıfın mutlaka pozitif bir tahmin anlamına gelmediğini, yalnızca fiili ve tahmin edilen matristeki tahmin edilen sütunu temsil ettiğini unutmayın. Örneğin aşağıdaki matrisleri hesapladığımızı varsayalım:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot bu verileri görüntülemenin üç yolu vardır. Her durumda tabloyu okumanın yolu, gerçek sınıfın perspektifinden satır satır okumaktır.
1) Toplam Tahmin Sayısı
Bu durumda, belirli bir satır için (yani gerçek sınıf), diğer sınıflar için TP + FP sayıları neydi? Yukarıdaki sayımlar için görüntümüz aşağıdaki gibi olacaktır:
| Tahmin edilen kuş | Tahmin edilen düzlem | Tahmin edilen süpermen | |
|---|---|---|---|
| Gerçek kuş | 6 | 4 | 2 |
| Gerçek uçak | 4 | 4 | 4 |
| Gerçek süpermen | 5 | 5 | 4 |
Resimler aslında bir bird içerdiğinde 6 tanesini doğru tahmin ettik. Aynı zamanda plane (doğru ya da yanlış) 4 kez, superman (doğru ya da yanlış) 2 kez tahmin ettik.
2) Yanlış Tahmin Sayısı
Bu durumda, belirli bir satır için (yani gerçek sınıf), diğer sınıflar için FP sayıları neydi? Yukarıdaki sayımlar için görüntümüz aşağıdaki gibi olacaktır:
| Tahmin edilen kuş | Tahmin edilen düzlem | Tahmin edilen süpermen | |
|---|---|---|---|
| Gerçek kuş | 0 | 2 | 1 |
| Gerçek uçak | 1 | 0 | 3 |
| Gerçek süpermen | 2 | 3 | 0 |
Resimler aslında bird içerdiğinde 2 kez plane , 1 kez de superman yanlış tahmin ettik.
3) Yanlış Negatif Sayım
Bu durumda, belirli bir satır için (yani gerçek sınıf), diğer sınıflar için FN sayıları neydi? Yukarıdaki sayımlar için görüntümüz aşağıdaki gibi olacaktır:
| Tahmin edilen kuş | Tahmin edilen düzlem | Tahmin edilen süpermen | |
|---|---|---|---|
| Gerçek kuş | 2 | 2 | 4 |
| Gerçek uçak | 1 | 4 | 3 |
| Gerçek süpermen | 2 | 2 | 5 |
Resimlerde aslında bir bird yer aldığında bunu 2 kez tahmin edemedik. Aynı zamanda 2 kez plane , 4 kez de superman tahmininde başarısız olduk.
Neden tahmin anahtarının bulunamadığına ilişkin bir hata alıyorum?
Bazı modellerin tahminleri bir sözlük biçiminde çıktı olarak verilmektedir. Örneğin, ikili sınıflandırma problemi için bir TF tahmincisi, probabilities , class_ids vb. içeren bir sözlüğün çıktısını verir. Çoğu durumda TFMA'nın predictions , probabilities vb. gibi yaygın olarak kullanılan anahtar adlarını bulmak için varsayılanları vardır. Bununla birlikte, eğer modeliniz çok özelleştirilmişse, TFMA tarafından bilinmeyen adlar altındaki çıkış anahtarları. Bu durumlarda çıktının saklandığı anahtarın adını tanımlamak için tfma.ModelSpec dosyasına bir prediciton_key ayarı eklenmelidir.