
Général
Un EvalSavedModel est-il toujours requis ?
Auparavant, TFMA exigeait que toutes les métriques soient stockées dans un graphique Tensorflow à l'aide d'un EvalSavedModel spécial. Désormais, les métriques peuvent être calculées en dehors du graphe TF à l'aide des implémentations beam.CombineFn .
Certaines des principales différences sont :
- Un
EvalSavedModelnécessite une exportation spéciale de la part du formateur alors qu'un modèle de diffusion peut être utilisé sans aucune modification requise dans le code de formation. - Lorsqu'un
EvalSavedModelest utilisé, toutes les métriques ajoutées au moment de la formation sont automatiquement disponibles au moment de l'évaluation. SansEvalSavedModelces métriques doivent être rajoutées.- L'exception à cette règle est que si un modèle keras est utilisé, les métriques peuvent également être ajoutées automatiquement car keras enregistre les informations métriques à côté du modèle enregistré.
TFMA peut-il fonctionner à la fois avec des métriques intégrées au graphique et des métriques externes ?
TFMA permet d'utiliser une approche hybride dans laquelle certaines métriques peuvent être calculées dans le graphique alors que d'autres peuvent être calculées à l'extérieur. Si vous disposez actuellement d'un EvalSavedModel , vous pouvez continuer à l'utiliser.
Il y a deux cas :
- Utilisez TFMA
EvalSavedModelpour l'extraction de fonctionnalités et les calculs de métriques, mais ajoutez également des métriques supplémentaires basées sur un combinateur. Dans ce cas, vous obtiendrez toutes les métriques intégrées au graphique d'EvalSavedModelainsi que toutes les métriques supplémentaires basées sur le combinateur qui n'auraient peut-être pas été prises en charge auparavant. - Utilisez TFMA
EvalSavedModelpour l'extraction de fonctionnalités/prédictions, mais utilisez des métriques basées sur un combinateur pour tous les calculs de métriques. Ce mode est utile si des transformations de fonctionnalités sont présentes dansEvalSavedModelque vous souhaitez utiliser pour le découpage, mais que vous préférez effectuer tous les calculs de métriques en dehors du graphique.
Installation
Quels types de modèles sont pris en charge ?
TFMA prend en charge les modèles keras, les modèles basés sur les API génériques de signature TF2, ainsi que les modèles basés sur l'estimateur TF (bien que, selon le cas d'utilisation, les modèles basés sur l'estimateur puissent nécessiter l'utilisation d'un EvalSavedModel ).
Consultez le guide get_started pour la liste complète des types de modèles pris en charge et les éventuelles restrictions.
Comment configurer TFMA pour qu'il fonctionne avec un modèle natif basé sur Keras ?
Voici un exemple de configuration pour un modèle keras basé sur les hypothèses suivantes :
- Le modèle enregistré est destiné au service et utilise le nom de signature
serving_default(cela peut être modifié à l'aidemodel_specs[0].signature_name). - Les métriques intégrées de
model.compile(...)doivent être évaluées (cela peut être désactivé viaoptions.include_default_metricdans le tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consultez les métriques pour plus d’informations sur les autres types de métriques pouvant être configurées.
Comment configurer TFMA pour qu'il fonctionne avec un modèle générique basé sur les signatures TF2 ?
Ce qui suit est un exemple de configuration pour un modèle TF2 générique. Ci-dessous, signature_name est le nom de la signature spécifique qui doit être utilisée pour l'évaluation.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consultez les métriques pour plus d’informations sur les autres types de métriques pouvant être configurées.
Comment configurer TFMA pour qu'il fonctionne avec un modèle basé sur un estimateur ?
Dans ce cas, il y a trois choix.
Option 1 : Utiliser le modèle de diffusion
Si cette option est utilisée, les mesures ajoutées pendant la formation ne seront PAS incluses dans l'évaluation.
Voici un exemple de configuration en supposant que serving_default est le nom de signature utilisé :
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consultez les métriques pour plus d’informations sur les autres types de métriques pouvant être configurées.
Option 2 : utilisez EvalSavedModel avec des métriques supplémentaires basées sur un combinateur
Dans ce cas, utilisez EvalSavedModel pour l'extraction et l'évaluation des fonctionnalités/prédictions et ajoutez également des métriques supplémentaires basées sur un combinateur.
Voici un exemple de configuration :
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Voir métriques pour plus d'informations sur les autres types de métriques pouvant être configurées et EvalSavedModel pour plus d'informations sur la configuration d'EvalSavedModel.
Option 3 : utiliser le modèle EvalSavedModel uniquement pour l'extraction de fonctionnalités/prédictions
Similaire à l'option (2), mais utilisez uniquement EvalSavedModel pour l'extraction de fonctionnalités/prédictions. Cette option est utile si seules des métriques externes sont souhaitées, mais que vous souhaitez découper certaines transformations de fonctionnalités. Semblable à l'option (1), les mesures ajoutées pendant la formation ne seront PAS incluses dans l'évaluation.
Dans ce cas, la configuration est la même que ci-dessus, seul include_default_metrics est désactivé.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Voir métriques pour plus d'informations sur les autres types de métriques pouvant être configurées et EvalSavedModel pour plus d'informations sur la configuration d'EvalSavedModel.
Comment configurer TFMA pour qu'il fonctionne avec un modèle basé sur un modèle vers un estimateur Keras ?
La configuration keras model_to_estimator est similaire à la configuration de l'estimateur. Il existe cependant quelques différences spécifiques au fonctionnement du modèle vers l’estimateur. En particulier, le modèle vers l'esimtateur renvoie ses sorties sous la forme d'un dict où la clé dict est le nom de la dernière couche de sortie dans le modèle keras associé (si aucun nom n'est fourni, keras choisira un nom par défaut pour vous comme dense_1 ou output_1 ). Du point de vue TFMA, ce comportement est similaire à ce qui serait produit par un modèle à sorties multiples, même si le modèle à estimateur ne peut concerner qu'un seul modèle. Pour tenir compte de cette différence, une étape supplémentaire est requise pour configurer le nom de sortie. Cependant, les trois mêmes options s’appliquent comme estimateur.
Voici un exemple des modifications requises pour une configuration basée sur un estimateur :
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
Comment configurer TFMA pour qu'il fonctionne avec des prédictions pré-calculées (c'est-à-dire indépendantes du modèle) ? ( TFRecord et tf.Example )
Afin de configurer TFMA pour qu'il fonctionne avec des prédictions précalculées, le tfma.PredictExtractor par défaut doit être désactivé et le tfma.InputExtractor doit être configuré pour analyser les prédictions avec les autres fonctionnalités d'entrée. Ceci est accompli en configurant un tfma.ModelSpec avec le nom de la clé de fonctionnalité utilisée pour les prédictions, à côté des étiquettes et des poids.
Voici un exemple de configuration :
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Voir métriques pour plus d’informations sur les métriques pouvant être configurées.
Notez que bien qu'un tfma.ModelSpec soit en cours de configuration, un modèle n'est pas réellement utilisé (c'est-à-dire qu'il n'y a pas de tfma.EvalSharedModel ). L'appel pour exécuter une analyse de modèle peut ressembler à ceci :
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
Comment configurer TFMA pour qu'il fonctionne avec des prédictions pré-calculées (c'est-à-dire indépendantes du modèle) ? ( pd.DataFrame )
Pour les petits ensembles de données pouvant tenir en mémoire, une alternative à un TFRecord est un pandas.DataFrame s. TFMA peut fonctionner sur pandas.DataFrame à l'aide de l'API tfma.analyze_raw_data . Pour une explication de tfma.MetricsSpec et tfma.SlicingSpec , consultez le guide de configuration . Voir métriques pour plus d’informations sur les métriques pouvant être configurées.
Voici un exemple de configuration :
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Métrique
Quels types de métriques sont pris en charge ?
TFMA prend en charge une grande variété de mesures, notamment :
- métriques de régression
- métriques de classification binaire
- métriques de classification multi-classes/multi-étiquettes
- métriques micro-moyenne/macro-moyenne
- métriques basées sur les requêtes/classements
Les métriques des modèles multi-sorties sont-elles prises en charge ?
Oui. Consultez le guide des métriques pour plus de détails.
Les métriques de plusieurs modèles sont-elles prises en charge ?
Oui. Consultez le guide des métriques pour plus de détails.
Les paramètres des métriques (nom, etc.) peuvent-ils être personnalisés ?
Oui. Les paramètres des métriques peuvent être personnalisés (par exemple, définition de seuils spécifiques, etc.) en ajoutant des paramètres config à la configuration des métriques. Voir le guide des métriques pour plus de détails.
Les métriques personnalisées sont-elles prises en charge ?
Oui. Soit en écrivant une implémentation tf.keras.metrics.Metric personnalisée, soit en écrivant une implémentation beam.CombineFn personnalisée. Le guide des métriques contient plus de détails.
Quels types de métriques ne sont pas pris en charge ?
Tant que votre métrique peut être calculée à l'aide d'un beam.CombineFn , il n'y a aucune restriction sur les types de métriques qui peuvent être calculées sur la base de tfma.metrics.Metric . Si vous travaillez avec une métrique dérivée de tf.keras.metrics.Metric , les critères suivants doivent être satisfaits :
- Il devrait être possible de calculer indépendamment des statistiques suffisantes pour la métrique sur chaque exemple, puis de combiner ces statistiques suffisantes en les ajoutant à tous les exemples, et de déterminer la valeur de la métrique uniquement à partir de ces statistiques suffisantes.
- Par exemple, pour l'exactitude, les statistiques suffisantes sont « totalement correct » et « total d'exemples ». Il est possible de calculer ces deux nombres pour des exemples individuels et de les additionner pour un groupe d'exemples afin d'obtenir les bonnes valeurs pour ces exemples. La précision finale peut être calculée à l'aide de « total correct / total d'exemples ».
Modules complémentaires
Puis-je utiliser TFMA pour évaluer l’équité ou les biais de mon modèle ?
TFMA comprend un module complémentaire FairnessIndicators qui fournit des mesures post-exportation pour évaluer les effets des biais involontaires dans les modèles de classification.
Personnalisation
Et si j'ai besoin de plus de personnalisation ?
TFMA est très flexible et vous permet de personnaliser presque toutes les parties du pipeline à l'aide Extractors , Evaluators et/ou Writers personnalisés. Ces abstractions sont discutées plus en détail dans le document d'architecture .
Dépannage, débogage et obtention d'aide
Pourquoi les métriques MultiClassConfusionMatrix ne correspondent-elles pas aux métriques ConfusionMatrix binarisées
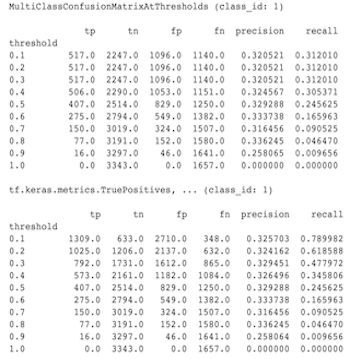
Ce sont en fait des calculs différents. La binarisation effectue une comparaison pour chaque ID de classe indépendamment (c'est-à-dire que la prédiction pour chaque classe est comparée séparément aux seuils fournis). Dans ce cas, il est possible que deux classes ou plus indiquent toutes qu'elles correspondent à la prédiction parce que leur valeur prédite était supérieure au seuil (cela sera encore plus évident à des seuils inférieurs). Dans le cas de la matrice de confusion multiclasse, il n'y a toujours qu'une seule vraie valeur prédite et soit elle correspond à la valeur réelle, soit elle ne correspond pas. Le seuil n'est utilisé que pour forcer une prédiction à ne correspondre à aucune classe si elle est inférieure au seuil. Plus le seuil est élevé, plus il est difficile pour la prédiction d'une classe binarisée de correspondre. De même, plus le seuil est bas, plus il est facile pour les prédictions d'une classe binarisée de correspondre. Cela signifie qu'aux seuils > 0,5, les valeurs binarisées et les valeurs de la matrice multiclasse seront plus rapprochées et aux seuils < 0,5, elles seront plus éloignées.
Par exemple, disons que nous avons 10 classes dans lesquelles la classe 2 a été prédite avec une probabilité de 0,8, mais la classe réelle était la classe 1 avec une probabilité de 0,15. Si vous binarisez sur la classe 1 et utilisez un seuil de 0,1, alors la classe 1 sera considérée comme correcte (0,15 > 0,1) donc elle sera comptée comme un TP. Cependant, pour le cas multiclasse, la classe 2 sera considérée comme correcte (0,8 > 0,1) et puisque la classe 1 était la classe réelle, cela sera compté comme un FN. Étant donné qu'à des seuils inférieurs, plus de valeurs seront considérées comme positives, en général, les comptes de TP et de FP seront plus élevés pour la matrice de confusion binarisée que pour la matrice de confusion multiclasse, et de même, les comptes TN et FN seront plus faibles.
Voici un exemple des différences observées entre MultiClassConfusionMatrixAtThresholds et les décomptes correspondants issus de la binarisation de l'une des classes.
Pourquoi mes métriques précision@1 et rappel@1 ont-elles la même valeur ?
À une valeur k supérieure de 1, la précision et le rappel sont la même chose. La précision est égale à TP / (TP + FP) et le rappel est égal à TP / (TP + FN) . La prédiction la plus élevée est toujours positive et correspondra ou non à l'étiquette. Autrement dit, avec N exemples, TP + FP = N . Cependant, si l'étiquette ne correspond pas à la prédiction supérieure, cela implique également qu'une prédiction k non supérieure a été mise en correspondance et avec k supérieur défini sur 1, toutes les prédictions non supérieures 1 seront 0. Cela implique que FN doit être (N - TP) ou N = TP + FN . Le résultat final est precision@1 = TP / N = recall@1 . Notez que cela ne s'applique que lorsqu'il y a une seule étiquette par exemple, pas pour plusieurs étiquettes.
Pourquoi mes métriques Mean_label et Mean_prediction sont-elles toujours égales à 0,5 ?
Cela est probablement dû au fait que les métriques sont configurées pour un problème de classification binaire, mais que le modèle génère des probabilités pour les deux classes au lieu d'une seule. Ceci est courant lorsque l'API de classification de Tensorflow est utilisée. La solution consiste à choisir la classe sur laquelle vous souhaitez que les prédictions soient basées, puis à les binariser sur cette classe. Par exemple:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
Comment interpréter le MultiLabelConfusionMatrixPlot ?
Étant donné une étiquette particulière, le MultiLabelConfusionMatrixPlot (et MultiLabelConfusionMatrix associé) peuvent être utilisés pour comparer les résultats d'autres étiquettes et leurs prédictions lorsque l'étiquette choisie était réellement vraie. Par exemple, disons que nous avons trois classes bird , plane et superman et que nous classons les images pour indiquer si elles contiennent une ou plusieurs de ces classes. Le MultiLabelConfusionMatrix calculera le produit cartésien de chaque classe réelle par rapport à chaque autre classe (appelée classe prédite). Notez que même si l'appariement est (actual, predicted) , la classe predicted n'implique pas nécessairement une prédiction positive, elle représente simplement la colonne prédite dans la matrice réel vs prédit. Par exemple, disons que nous avons calculé les matrices suivantes :
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
Le MultiLabelConfusionMatrixPlot propose trois manières d'afficher ces données. Dans tous les cas, la manière de lire le tableau se fait ligne par ligne du point de vue de la classe elle-même.
1) Nombre total de prédictions
Dans ce cas, pour une ligne donnée (c'est-à-dire une classe réelle), quels étaient les comptes TP + FP pour les autres classes. Pour les décomptes ci-dessus, notre affichage serait le suivant :
| Oiseau prédit | Avion prévu | Surhomme prédit | |
|---|---|---|---|
| Oiseau réel | 6 | 4 | 2 |
| Avion réel | 4 | 4 | 4 |
| Un vrai surhomme | 5 | 5 | 4 |
Lorsque les images contenaient réellement un bird , nous en avions correctement prédit 6. Dans le même temps, nous avons également prédit plane (à tort ou à raison) 4 fois et superman (à tort ou à raison) 2 fois.
2) Nombre de prédictions incorrectes
Dans ce cas, pour une ligne donnée (c'est-à-dire une classe réelle), quels étaient les comptes FP pour les autres classes. Pour les décomptes ci-dessus, notre affichage serait le suivant :
| Oiseau prédit | Avion prévu | Surhomme prédit | |
|---|---|---|---|
| Oiseau réel | 0 | 2 | 1 |
| Avion réel | 1 | 0 | 3 |
| Un vrai surhomme | 2 | 3 | 0 |
Lorsque les images contenaient en réalité un bird nous avions prédit à tort plane 2 fois et superman 1 fois.
3) Nombre de faux négatifs
Dans ce cas, pour une ligne donnée (c'est-à-dire une classe réelle), quels étaient les comptes FN pour les autres classes. Pour les décomptes ci-dessus, notre affichage serait le suivant :
| Oiseau prédit | Avion prévu | Surhomme prédit | |
|---|---|---|---|
| Oiseau réel | 2 | 2 | 4 |
| Avion réel | 1 | 4 | 3 |
| Un vrai surhomme | 2 | 2 | 5 |
Lorsque les images contenaient réellement un bird nous n'avons pas réussi à le prédire à deux reprises. Dans le même temps, nous n’avons pas réussi à prédire plane 2 fois et superman 4 fois.
Pourquoi est-ce que je reçois une erreur concernant la clé de prédiction introuvable ?
Certains modèles génèrent leur prédiction sous la forme d’un dictionnaire. Par exemple, un estimateur TF pour un problème de classification binaire génère un dictionnaire contenant probabilities , class_ids , etc. Dans la plupart des cas, TFMA a des valeurs par défaut pour trouver les noms de clés couramment utilisés tels que predictions , probabilities , etc. Cependant, si votre modèle est très personnalisé, il peut clés de sortie sous des noms inconnus de TFMA. Dans ces cas, un paramètre prediciton_key doit être ajouté à tfma.ModelSpec pour identifier le nom de la clé sous laquelle la sortie est stockée.