
Generale
È ancora necessario un EvalSavedModel?
In precedenza TFMA richiedeva che tutti i parametri fossero archiviati all'interno di un grafico tensorflow utilizzando uno speciale EvalSavedModel . Ora, le metriche possono essere calcolate al di fuori del grafico TF utilizzando le implementazioni beam.CombineFn .
Alcune delle differenze principali sono:
- Un
EvalSavedModelrichiede un'esportazione speciale dal trainer mentre un modello di servizio può essere utilizzato senza alcuna modifica richiesta al codice di training. - Quando viene utilizzato un
EvalSavedModel, tutti i parametri aggiunti al momento del training sono automaticamente disponibili al momento della valutazione. Senza unEvalSavedModelqueste metriche devono essere aggiunte nuovamente.- L'eccezione a questa regola è che se viene utilizzato un modello Keras, le metriche possono anche essere aggiunte automaticamente perché Keras salva le informazioni sulle metriche insieme al modello salvato.
TFMA può funzionare sia con metriche interne al grafico che con metriche esterne?
TFMA consente di utilizzare un approccio ibrido in cui alcune metriche possono essere calcolate nel grafico mentre altre possono essere calcolate all'esterno. Se attualmente disponi di un EvalSavedModel , puoi continuare a utilizzarlo.
Ci sono due casi:
- Utilizza TFMA
EvalSavedModelsia per l'estrazione delle caratteristiche che per i calcoli delle metriche, ma aggiungi anche ulteriori metriche basate sul combinatore. In questo caso otterresti tutti i parametri nel grafico daEvalSavedModelinsieme a eventuali parametri aggiuntivi dal combinatore che potrebbero non essere stati supportati in precedenza. - Utilizzare TFMA
EvalSavedModelper l'estrazione di caratteristiche/previsioni ma utilizzare metriche basate su combinatore per tutti i calcoli delle metriche. Questa modalità è utile seEvalSavedModelsono presenti trasformazioni di funzionalità che desideri utilizzare per l'affettamento, ma preferisci eseguire tutti i calcoli metrici all'esterno del grafico.
Impostare
Quali tipi di modelli sono supportati?
TFMA supporta modelli keras, modelli basati su API di firma TF2 generiche, nonché modelli basati sullo stimatore TF (anche se, a seconda del caso d'uso, i modelli basati sullo stimatore potrebbero richiedere l'utilizzo di un EvalSavedModel ).
Consulta la guida get_started per l'elenco completo dei tipi di modelli supportati e le eventuali restrizioni.
Come posso configurare TFMA per funzionare con un modello nativo basato su Keras?
Quello che segue è un esempio di configurazione per un modello Keras basato sui seguenti presupposti:
- Il modello salvato è per la pubblicazione e utilizza il nome della firma
serving_default(questo può essere modificato utilizzandomodel_specs[0].signature_name). - Dovrebbero essere valutati i parametri incorporati da
model.compile(...)(questo può essere disabilitato tramiteoptions.include_default_metricall'interno di tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consulta le metriche per ulteriori informazioni su altri tipi di metriche che possono essere configurate.
Come posso configurare TFMA in modo che funzioni con un modello generico basato su firme TF2?
Quello che segue è un esempio di configurazione per un modello TF2 generico. Di seguito, signature_name è il nome della firma specifica da utilizzare per la valutazione.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Consulta le metriche per ulteriori informazioni su altri tipi di metriche che possono essere configurate.
Come posso impostare TFMA per lavorare con un modello basato sullo stimatore?
In questo caso ci sono tre scelte.
Opzione 1: utilizza il modello di pubblicazione
Se viene utilizzata questa opzione, eventuali metriche aggiunte durante la formazione NON verranno incluse nella valutazione.
Quello che segue è un esempio di configurazione presupponendo che serving_default sia il nome della firma utilizzato:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulta le metriche per ulteriori informazioni su altri tipi di metriche che possono essere configurate.
Opzione 2: utilizzare EvalSavedModel insieme a parametri aggiuntivi basati sul combinatore
In questo caso, utilizzare EvalSavedModel sia per l'estrazione che per la valutazione di funzionalità/previsioni e aggiungere anche ulteriori metriche basate sul combinatore.
Quello che segue è un esempio di configurazione:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Vedi metrics per ulteriori informazioni su altri tipi di parametri che possono essere configurati e EvalSavedModel per ulteriori informazioni sulla configurazione di EvalSavedModel.
Opzione 3: utilizzare il modello EvalSavedModel solo per l'estrazione di funzionalità/previsioni
Simile all'opzione(2), ma utilizza EvalSavedModel solo per l'estrazione di funzionalità/predizioni. Questa opzione è utile se si desiderano solo metriche esterne, ma ci sono trasformazioni di funzionalità che si desidera suddividere. Analogamente all'opzione (1), qualsiasi metrica aggiunta durante la formazione NON sarà inclusa nella valutazione.
In questo caso la configurazione è la stessa di sopra, solo include_default_metrics è disabilitato.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Vedi metrics per ulteriori informazioni su altri tipi di parametri che possono essere configurati e EvalSavedModel per ulteriori informazioni sulla configurazione di EvalSavedModel.
Come posso impostare TFMA per funzionare con un modello basato su modello-stimatore Keras?
La configurazione di Keras model_to_estimator è simile alla configurazione dello stimatore. Tuttavia ci sono alcune differenze specifiche nel funzionamento del modello per la stima. In particolare, il model-to-esimtator restituisce i suoi output sotto forma di dict dove la chiave dict è il nome dell'ultimo livello di output nel modello keras associato (se non viene fornito alcun nome, keras sceglierà per te un nome predefinito come dense_1 o output_1 ). Dal punto di vista TFMA, questo comportamento è simile a quello che sarebbe l'output di un modello multi-output anche se il modello da stimare potrebbe riguardare un solo modello. Per tenere conto di questa differenza, è necessario un passaggio aggiuntivo per impostare il nome dell'output. Tuttavia, come stimatore si applicano le stesse tre opzioni.
Di seguito è riportato un esempio delle modifiche richieste a una configurazione basata sullo stimatore:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
Come posso impostare TFMA in modo che funzioni con previsioni precalcolate (ovvero indipendenti dal modello)? ( TFRecord e tf.Example )
Per configurare TFMA in modo che funzioni con previsioni precalcolate, il tfma.PredictExtractor predefinito deve essere disabilitato e tfma.InputExtractor deve essere configurato per analizzare le previsioni insieme alle altre funzionalità di input. Ciò si ottiene configurando un tfma.ModelSpec con il nome della chiave funzione utilizzata per le previsioni insieme alle etichette e ai pesi.
Di seguito è riportato un esempio di configurazione:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Consulta le metriche per ulteriori informazioni sulle metriche che possono essere configurate.
Si noti che nonostante venga configurato un tfma.ModelSpec , un modello non viene effettivamente utilizzato (ovvero non esiste tfma.EvalSharedModel ). La chiamata per eseguire l'analisi del modello potrebbe apparire come segue:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
Come posso impostare TFMA in modo che funzioni con previsioni precalcolate (ovvero indipendenti dal modello)? ( pd.DataFrame )
Per set di dati di piccole dimensioni che possono essere contenuti in memoria, un'alternativa a TFRecord è pandas.DataFrame s. TFMA può operare su pandas.DataFrame utilizzando l'API tfma.analyze_raw_data . Per una spiegazione di tfma.MetricsSpec e tfma.SlicingSpec , vedere la guida all'installazione . Consulta le metriche per ulteriori informazioni sulle metriche che possono essere configurate.
Di seguito è riportato un esempio di configurazione:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Metrica
Quali tipi di metriche sono supportate?
TFMA supporta un'ampia varietà di parametri, tra cui:
- metriche di regressione
- metriche di classificazione binaria
- metriche di classificazione multiclasse/multietichetta
- metriche micromedia/macromedia
- metriche basate su query/classifica
Sono supportati i parametri dei modelli multi-output?
SÌ. Consulta la guida alle metriche per maggiori dettagli.
Sono supportate le metriche di più modelli?
SÌ. Consulta la guida alle metriche per maggiori dettagli.
È possibile personalizzare le impostazioni metriche (nome, ecc.)?
SÌ. Le impostazioni delle metriche possono essere personalizzate (ad esempio impostando soglie specifiche, ecc.) aggiungendo impostazioni config alla configurazione della metrica. Consulta la guida alle metriche per maggiori dettagli.
Sono supportate le metriche personalizzate?
SÌ. Scrivendo un'implementazione tf.keras.metrics.Metric personalizzata o scrivendo un'implementazione beam.CombineFn personalizzata. La guida alle metriche contiene maggiori dettagli.
Quali tipi di parametri non sono supportati?
Finché la metrica può essere calcolata utilizzando beam.CombineFn , non esistono restrizioni sui tipi di metriche che possono essere calcolate in base a tfma.metrics.Metric . Se si lavora con una metrica derivata da tf.keras.metrics.Metric , è necessario soddisfare i seguenti criteri:
- Dovrebbe essere possibile calcolare statistiche sufficienti per la metrica su ciascun esempio in modo indipendente, quindi combinare queste statistiche sufficienti sommandole a tutti gli esempi e determinare il valore della metrica esclusivamente da queste statistiche sufficienti.
- Ad esempio, per la precisione le statistiche sufficienti sono "totale corretto" e "totale esempi". È possibile calcolare questi due numeri per singoli esempi e sommarli per un gruppo di esempi per ottenere i valori corretti per quegli esempi. La precisione finale può essere calcolata utilizzando "totale corretto/totale esempi".
Componenti aggiuntivi
Posso utilizzare TFMA per valutare l'equità o la distorsione del mio modello?
TFMA include un componente aggiuntivo FairnessIndicators che fornisce parametri post-esportazione per valutare gli effetti di distorsioni involontarie nei modelli di classificazione.
Personalizzazione
Cosa succede se ho bisogno di maggiore personalizzazione?
TFMA è molto flessibile e consente di personalizzare quasi tutte le parti della pipeline utilizzando Extractors , Evaluators e/o Writers personalizzati. Queste astrazioni sono discusse in maggior dettaglio nel documento sull'architettura .
Risoluzione dei problemi, debug e assistenza
Perché i parametri MultiClassConfusionMatrix non corrispondono ai parametri ConfusionMatrix binarizzati
In realtà si tratta di calcoli diversi. La binarizzazione esegue un confronto per ciascun ID di classe in modo indipendente (ovvero la previsione per ciascuna classe viene confrontata separatamente con le soglie fornite). In questo caso è possibile che due o più classi indichino tutte che corrispondono alla previsione perché il loro valore previsto era maggiore della soglia (questo sarà ancora più evidente a soglie inferiori). Nel caso della matrice di confusione multiclasse, esiste ancora un solo vero valore previsto e corrisponde al valore effettivo oppure no. La soglia viene utilizzata solo per forzare una previsione a non corrispondere a nessuna classe se è inferiore alla soglia. Più alta è la soglia, più difficile sarà che la previsione di una classe binarizzata corrisponda. Allo stesso modo, più bassa è la soglia, più facile sarà che le previsioni di una classe binarizzata corrispondano. Ciò significa che a soglie > 0,5 i valori binarizzati e i valori della matrice multiclasse saranno più allineati e a soglie < 0,5 saranno più distanti.
Ad esempio, supponiamo di avere 10 classi in cui è stata prevista la classe 2 con una probabilità di 0,8, ma la classe effettiva era la classe 1 con una probabilità di 0,15. Se binarizzi sulla classe 1 e utilizzi una soglia di 0,1, la classe 1 sarà considerata corretta (0,15 > 0,1) quindi verrà conteggiata come TP, tuttavia, per il caso multiclasse, la classe 2 sarà considerata corretta (0,8 > 0.1) e poiché la classe 1 era quella effettiva, questa verrà conteggiata come FN. Poiché a soglie inferiori più valori saranno considerati positivi, in generale ci saranno conteggi TP e FP più elevati per la matrice di confusione binarizzata rispetto alla matrice di confusione multiclasse, e similmente TN e FN inferiori.
Di seguito è riportato un esempio delle differenze osservate tra MultiClassConfusionMatrixAtThresholds e i conteggi corrispondenti dalla binarizzazione di una delle classi.
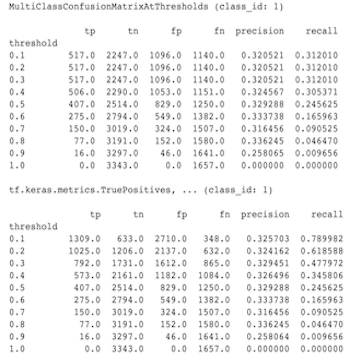
Perché le mie metriche Precision@1 e Recall@1 hanno lo stesso valore?
Con un valore k superiore pari a 1, precisione e richiamo sono la stessa cosa. La precisione è pari a TP / (TP + FP) e il richiamo è pari a TP / (TP + FN) . La previsione principale è sempre positiva e corrisponderà o meno all'etichetta. In altre parole, con N esempi, TP + FP = N . Tuttavia, se l'etichetta non corrisponde alla previsione in alto, ciò implica anche che è stata soddisfatta una previsione non in alto k e con il k in alto impostato su 1, tutte le previsioni non in alto 1 saranno 0. Ciò implica che FN deve essere (N - TP) o N = TP + FN . Il risultato finale è precision@1 = TP / N = recall@1 . Tieni presente che ciò si applica solo quando è presente un'unica etichetta per esempio, non per più etichette.
Perché le mie metriche mean_label e mean_prediction sono sempre 0,5?
Ciò è molto probabilmente causato dal fatto che le metriche sono configurate per un problema di classificazione binaria, ma il modello restituisce probabilità per entrambe le classi anziché solo per una. Questo è comune quando viene utilizzata l'API di classificazione di tensorflow . La soluzione è scegliere la classe su cui si desidera che siano basate le previsioni e quindi binarizzare su quella classe. Per esempio:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
Come interpretare il MultiLabelConfusionMatrixPlot?
Data una particolare etichetta, MultiLabelConfusionMatrixPlot (e MultiLabelConfusionMatrix associato) può essere utilizzato per confrontare i risultati di altre etichette e le loro previsioni quando l'etichetta scelta era effettivamente vera. Ad esempio, supponiamo di avere tre classi bird , plane e superman e stiamo classificando le immagini per indicare se contengono una o più di queste classi. MultiLabelConfusionMatrix calcolerà il prodotto cartesiano di ciascuna classe effettiva rispetto a ciascuna altra classe (chiamata classe prevista). Si noti che mentre l'abbinamento è (actual, predicted) , la classe predicted non implica necessariamente una previsione positiva, ma rappresenta semplicemente la colonna prevista nella matrice effettiva rispetto a quella prevista. Ad esempio, supponiamo di aver calcolato le seguenti matrici:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot ha tre modi per visualizzare questi dati. In tutti i casi il modo di leggere la tabella è riga per riga dal punto di vista della classe reale.
1) Conteggio totale delle previsioni
In questo caso, per una determinata riga (cioè la classe effettiva) quali erano i conteggi TP + FP per le altre classi. Per i conteggi di cui sopra, la nostra visualizzazione sarebbe la seguente:
| Uccello predetto | Piano previsto | Il superuomo previsto | |
|---|---|---|---|
| Vero uccello | 6 | 4 | 2 |
| Piano reale | 4 | 4 | 4 |
| Il vero superuomo | 5 | 5 | 4 |
Quando le immagini contenevano effettivamente un bird ne abbiamo predetti correttamente 6. Allo stesso tempo abbiamo anche previsto plane (correttamente o erroneamente) 4 volte e superman (correttamente o erroneamente) 2 volte.
2) Conteggio delle previsioni errato
In questo caso, per una data riga (cioè la classe effettiva) quali erano i conteggi FP per le altre classi. Per i conteggi di cui sopra, la nostra visualizzazione sarebbe la seguente:
| Uccello predetto | Piano previsto | Il superuomo previsto | |
|---|---|---|---|
| Uccello reale | 0 | 2 | 1 |
| Piano reale | 1 | 0 | 3 |
| Il vero superuomo | 2 | 3 | 0 |
Quando le immagini contenevano effettivamente un bird abbiamo erroneamente previsto plane 2 volte e superman 1 volta.
3) Conteggio dei falsi negativi
In questo caso, per una determinata riga (cioè la classe effettiva) quali erano i conteggi FN per le altre classi. Per i conteggi di cui sopra, la nostra visualizzazione sarebbe la seguente:
| Uccello predetto | Piano previsto | Il superuomo previsto | |
|---|---|---|---|
| Uccello reale | 2 | 2 | 4 |
| Piano reale | 1 | 4 | 3 |
| Il vero superuomo | 2 | 2 | 5 |
Quando le immagini contenevano effettivamente un bird non siamo riusciti a prevederlo 2 volte. Allo stesso tempo, non siamo riusciti a prevedere plane 2 volte e superman 4 volte.
Perché ricevo un errore relativo alla chiave di previsione non trovata?
Alcuni modelli trasmettono la loro previsione sotto forma di dizionario. Ad esempio, uno stimatore TF per un problema di classificazione binaria restituisce un dizionario contenente probabilities , class_ids , ecc. Nella maggior parte dei casi TFMA ha impostazioni predefinite per trovare nomi chiave comunemente utilizzati come predictions , probabilities , ecc. Tuttavia, se il modello è molto personalizzato, potrebbe chiavi di output con nomi non conosciuti da TFMA. In questi casi è necessario aggiungere un'impostazione prediciton_key a tfma.ModelSpec per identificare il nome della chiave in cui è archiviato l'output.