
개요
TensorFlow Model Analysis(TFMA) 파이프라인은 다음과 같이 설명됩니다.
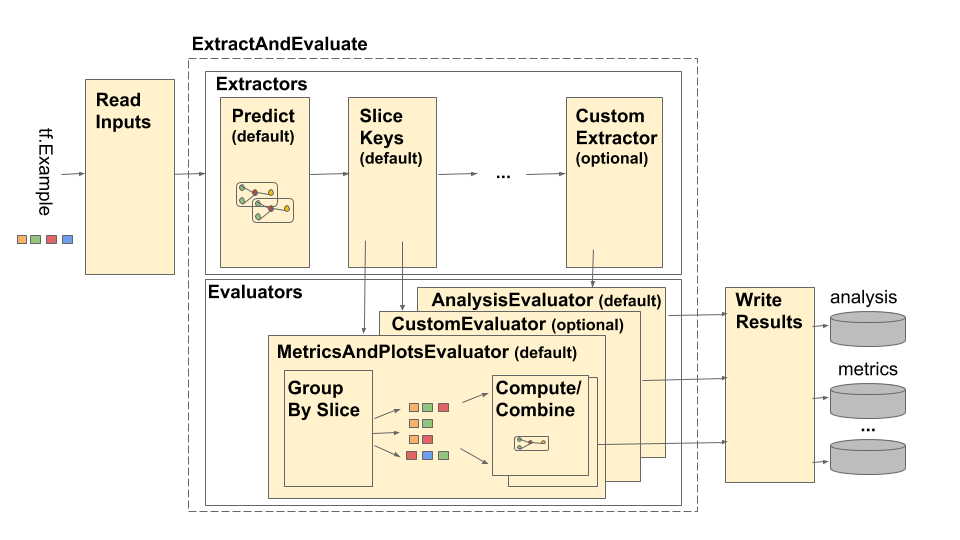
파이프라인은 네 가지 주요 구성요소로 구성됩니다.
- 입력 읽기
- 추출
- 평가
- 결과 쓰기
이러한 구성요소는 tfma.Extracts 및 tfma.evaluators.Evaluation 이라는 두 가지 기본 유형을 사용합니다. tfma.Extracts 유형은 파이프라인 처리 중에 추출되는 데이터를 나타내며 모델에 대한 하나 이상의 예에 해당할 수 있습니다. tfma.evaluators.Evaluation 추출 과정 중 다양한 지점에서 추출물을 평가한 결과를 나타냅니다. 유연한 API를 제공하기 위해 이러한 유형은 키가 다른 구현에 의해 정의되는(사용을 위해 예약된) dict일 뿐입니다. 유형은 다음과 같이 정의됩니다.
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
tfma.Extracts 는 직접 작성되지 않으며 항상 평가자를 거쳐 작성되는 tfma.evaluators.Evaluation 을 생성해야 합니다. 또한 tfma.Extracts 는 beam.pvalue.PCollection 에 저장되는 사전(즉, beam.PTransform 은 입력으로 사용됩니다 beam.pvalue.PCollection[tfma.Extracts] )인 반면 tfma.evaluators.Evaluation 은 값이 있는 사전입니다. 이것은 beam.pvalue.PCollection 입니다(즉, beam.PTransform 은 dict 자체를 beam.value.PCollection 입력에 대한 인수로 사용합니다). 즉, tfma.evaluators.Evaluation 은 파이프라인 구성 시 사용되지만 tfma.Extracts 는 파이프라인 런타임에 사용됩니다.
입력 읽기
ReadInputs 단계는 원시 입력(tf.train.Example, CSV 등)을 가져와서 추출로 변환하는 변환으로 구성됩니다. 현재 추출은 tfma.INPUT_KEY 아래에 저장된 원시 입력 바이트로 표시되지만 추출은 추출 파이프라인과 호환되는 모든 형식일 수 있습니다. 즉, tfma.Extracts 출력으로 생성하고 해당 추출이 다운스트림과 호환된다는 의미입니다. 추출기. 필요한 것을 명확하게 문서화하는 것은 다양한 추출기에 달려 있습니다.
추출
추출 프로세스는 연속적으로 실행되는 beam.PTransform 목록입니다. 추출기는 tfma.Extracts 입력으로 사용하고 tfma.Extracts 출력으로 반환합니다. 전형적인 추출기는 tfma.extractors.PredictExtractor 입니다. 이는 읽기 입력 변환에 의해 생성된 입력 추출을 사용하고 이를 모델을 통해 실행하여 예측 추출을 생성합니다. 변환이 tfma.Extracts in 및 tfma.Extracts out API를 준수하는 경우 사용자 정의된 추출기를 언제든지 삽입할 수 있습니다. 추출기는 다음과 같이 정의됩니다.
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
입력추출기
tfma.extractors.InputExtractor 는 메트릭 슬라이싱 및 계산에 사용하기 위해 tf.train.Example 레코드에서 원시 기능, 원시 레이블 및 원시 예제 가중치를 추출하는 데 사용됩니다. 기본적으로 값은 각각 추출 키 features , labels 및 example_weights 아래에 저장됩니다. 단일 출력 모델 레이블과 예제 가중치는 np.ndarray 값으로 직접 저장됩니다. 다중 출력 모델 레이블과 예제 가중치는 np.ndarray 값의 사전(출력 이름으로 입력)으로 저장됩니다. 다중 모델 평가가 수행되면 레이블과 예제 가중치가 다른 사전(모델 이름으로 입력됨)에 추가로 포함됩니다.
예측추출기
tfma.extractors.PredictExtractor 모델 예측을 실행하고 이를 tfma.Extracts dict의 주요 predictions 아래에 저장합니다. 단일 출력 모델 예측은 예측된 출력 값으로 직접 저장됩니다. 다중 출력 모델 예측은 출력 값의 사전(출력 이름으로 입력)으로 저장됩니다. 다중 모델 평가가 수행되면 예측은 다른 사전(모델 이름으로 입력) 내에 추가로 포함됩니다. 사용되는 실제 출력 값은 모델에 따라 다릅니다(예: TF 추정기의 반환 출력은 dict 형식인 반면 keras는 np.ndarray 값을 반환함).
슬라이스키 추출기
tfma.extractors.SliceKeyExtractor 는 슬라이싱 사양을 사용하여 추출된 특징을 기반으로 각 예시 입력에 어떤 슬라이스를 적용할지 결정하고 평가자가 나중에 사용할 수 있도록 해당 슬라이싱 값을 추출에 추가합니다.
평가
평가는 추출물을 채취하여 평가하는 과정입니다. 추출 파이프라인이 끝날 때 평가를 수행하는 것이 일반적이지만 추출 프로세스 초기에 평가가 필요한 사용 사례가 있습니다. 따라서 평가자는 평가해야 하는 출력의 추출기와 연관됩니다. 평가자는 다음과 같이 정의됩니다.
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
평가자는 tfma.Extracts 입력으로 사용하는 beam.PTransform 입니다. 구현이 평가 프로세스의 일부로 추출에 대한 추가 변환을 수행하는 것을 막을 수는 없습니다. tfma.Extracts 사전을 반환해야 하는 추출기와 달리 평가자가 생성할 수 있는 출력 유형에는 제한이 없지만 대부분의 평가자는 사전(예: 지표 이름 및 값)도 반환합니다.
MetricsAndPlotsEvaluator
tfma.evaluators.MetricsAndPlotsEvaluator features , labels 및 predictions 입력으로 사용하고 tfma.slicer.FanoutSlices 통해 이를 실행하여 슬라이스별로 그룹화한 다음 측정항목 및 플롯 계산을 수행합니다. 이는 메트릭 사전 형태로 출력을 생성하고 키와 값을 표시합니다(이러한 출력은 나중에 tfma.writers.MetricsAndPlotsWriter 에 의해 출력을 위해 직렬화된 proto로 변환됩니다).
결과 쓰기
WriteResults 단계는 평가 출력이 디스크에 기록되는 곳입니다. WriteResults는 기록기를 사용하여 출력 키를 기반으로 데이터를 작성합니다. 예를 들어 tfma.evaluators.Evaluation metrics 및 plots 에 대한 키가 포함될 수 있습니다. 그런 다음 이는 '메트릭' 및 '플롯'이라는 메트릭 및 플롯 사전과 연결됩니다. 작성자는 각 파일을 작성하는 방법을 지정합니다.
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
우리는 메트릭과 플롯 사전을 직렬화된 proto로 변환하고 디스크에 쓰는 tfma.writers.MetricsAndPlotsWriter 를 제공합니다.
다른 직렬화 형식을 사용하려면 사용자 정의 작성기를 만들어 대신 사용할 수 있습니다. 작성자에게 전달된 tfma.evaluators.Evaluation 에는 결합된 모든 평가자에 대한 출력이 포함되어 있으므로 작성자가 ptransform 구현에서 적절한 beam.PCollection 을 기반으로 선택하는 데 사용할 수 있는 tfma.writers.Write 도우미 변환이 제공됩니다. 출력 키(예는 아래 참조)
맞춤화
tfma.run_model_analysis 메소드는 파이프라인에서 사용되는 extractors , evaluators 및 writers 사용자 정의하기 위해 추출기, 평가자 및 기록기 인수를 사용합니다. 인수가 제공되지 않으면 tfma.default_extractors , tfma.default_evaluators 및 tfma.default_writers 가 기본적으로 사용됩니다.
맞춤형 추출기
사용자 정의 추출기를 생성하려면 tfma.Extracts 입력으로 사용하고 tfma.Extracts 출력으로 반환하는 beam.PTransform 을 래핑하는 tfma.extractors.Extractor 유형을 생성합니다. 추출기의 예는 tfma.extractors 아래에서 확인할 수 있습니다.
맞춤 평가자
사용자 정의 평가자를 생성하려면 tfma.Extracts 입력으로 사용하고 tfma.evaluators.Evaluation 출력으로 반환하는 beam.PTransform 을 래핑하는 tfma.evaluators.Evaluator 유형을 생성합니다. 매우 기본적인 평가자는 들어오는 tfma.Extracts 가져와 테이블에 저장하기 위해 출력할 수 있습니다. 이것이 바로 tfma.evaluators.AnalysisTableEvaluator 수행하는 작업입니다. 더 복잡한 평가자는 추가 처리 및 데이터 집계를 수행할 수 있습니다. 예를 들어 tfma.evaluators.MetricsAndPlotsEvaluator 를 참조하세요.
tfma.evaluators.MetricsAndPlotsEvaluator 자체는 사용자 정의 메트릭을 지원하도록 사용자 정의할 수 있습니다(자세한 내용은 메트릭 참조).
맞춤형 작가
사용자 정의 작성기를 생성하려면 tfma.evaluators.Evaluation 입력으로 사용하고 beam.pvalue.PDone 출력으로 반환하는 beam.PTransform 을 래핑하는 tfma.writers.Writer 유형을 생성합니다. 다음은 지표가 포함된 TFRecord를 작성하는 작성자의 기본 예입니다.
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
작성자의 입력은 관련 평가자의 출력에 따라 달라집니다. 위의 예에서 출력은 tfma.evaluators.MetricsAndPlotsEvaluator 에 의해 생성된 직렬화된 proto입니다. tfma.evaluators.AnalysisTableEvaluator 의 작성자는 tfma.Extracts 의 beam.pvalue.PCollection 작성을 담당합니다.
기록기는 사용된 출력 키(예: tfma.METRICS_KEY , tfma.ANALYSIS_KEY 등)를 통해 평가기의 출력과 연결됩니다.
단계별 예
다음은 tfma.evaluators.MetricsAndPlotsEvaluator 및 tfma.evaluators.AnalysisTableEvaluator 가 모두 사용될 때 추출 및 평가 파이프라인과 관련된 단계의 예입니다.
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files