
ওভারভিউ
TensorFlow মডেল বিশ্লেষণ (TFMA) পাইপলাইন নিম্নরূপ চিত্রিত করা হয়েছে:
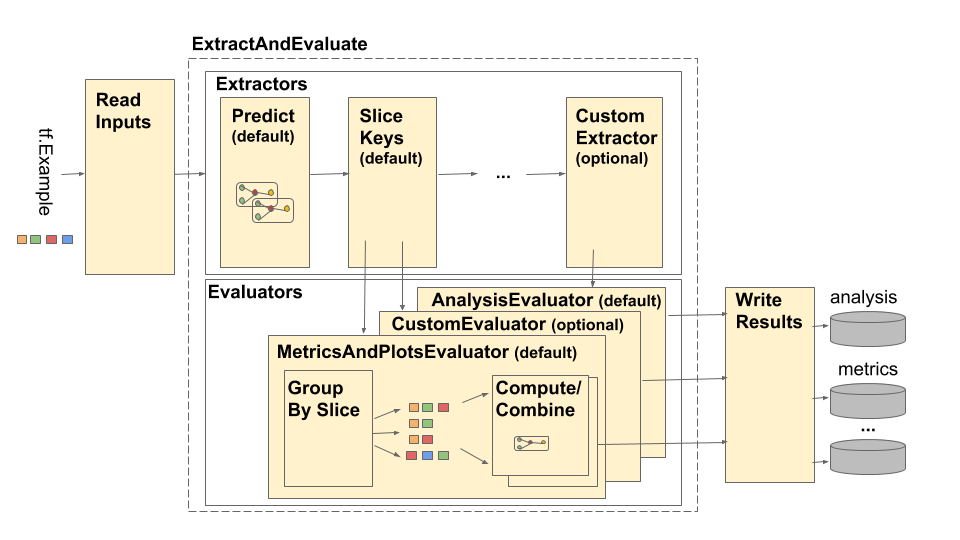
পাইপলাইন চারটি প্রধান উপাদান নিয়ে গঠিত:
- ইনপুট পড়ুন
- নিষ্কাশন
- মূল্যায়ন
- ফলাফল লিখুন
এই উপাদান দুটি প্রাথমিক প্রকার ব্যবহার করে: tfma.Extracts এবং tfma.evaluators.Evaluation । tfma.Extracts প্রকারটি এমন ডেটা উপস্থাপন করে যা পাইপলাইন প্রক্রিয়াকরণের সময় বের করা হয় এবং মডেলের জন্য এক বা একাধিক উদাহরণের সাথে মিল থাকতে পারে। tfma.evaluators.Evaluation নিষ্কাশন প্রক্রিয়া চলাকালীন বিভিন্ন পয়েন্টে নির্যাস মূল্যায়ন থেকে আউটপুট প্রতিনিধিত্ব করে। একটি নমনীয় API প্রদান করার জন্য, এই ধরনেরগুলি শুধুমাত্র নির্দেশাবলী যেখানে কীগুলি বিভিন্ন বাস্তবায়নের দ্বারা সংজ্ঞায়িত (ব্যবহারের জন্য সংরক্ষিত) হয়। প্রকারগুলি নিম্নরূপ সংজ্ঞায়িত করা হয়:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
মনে রাখবেন যে tfma.Extracts কখনও সরাসরি লেখা হয় না তাদের অবশ্যই একটি tfma.evaluators.Evaluation তৈরি করার জন্য একটি মূল্যায়নকারীর মাধ্যমে যেতে হবে। তারপরে লিখিত মূল্যায়ন। এছাড়াও মনে রাখবেন যে tfma.Extracts হল ডিক্ট যা একটি beam.pvalue.PCollection এ সংরক্ষিত থাকে (যেমন beam.PTransform s input beam.pvalue.PCollection[tfma.Extracts] হিসাবে নেয়) যেখানে একটি tfma.evaluators.Evaluation হল একটি ডিক্ট যার মান beam.pvalue.PCollection s (অর্থাৎ beam.PTransform s গুলিকে beam.value.PCollection ইনপুটের যুক্তি হিসাবে গ্রহণ করে)। অন্য কথায় tfma.evaluators.Evaluation পাইপলাইন নির্মাণের সময় ব্যবহার করা হয়, কিন্তু tfma.Extracts পাইপলাইন রানটাইমে ব্যবহার করা হয়।
ইনপুট পড়ুন
ReadInputs পর্যায়টি একটি রূপান্তর দ্বারা গঠিত যা কাঁচা ইনপুট (tf.train.Example, CSV, ...) নেয় এবং সেগুলিকে এক্সট্রাক্টে রূপান্তর করে। আজ নির্যাসগুলিকে tfma.INPUT_KEY অধীনে সংরক্ষিত কাঁচা ইনপুট বাইট হিসাবে উপস্থাপন করা হয়, তবে নির্যাসগুলি নিষ্কাশন পাইপলাইনের সাথে সামঞ্জস্যপূর্ণ যে কোনও আকারে হতে পারে -- যার অর্থ এটি tfma.Extracts তৈরি করে। নিষ্কাশনকারী এটি বিভিন্ন এক্সট্র্যাক্টরদের উপর নির্ভর করে যে তাদের কী প্রয়োজন তা স্পষ্টভাবে নথিভুক্ত করা।
নিষ্কাশন
নিষ্কাশন প্রক্রিয়াটি beam.PTransform একটি তালিকা। এক্সট্রাক্টররা ইনপুট হিসাবে tfma.Extracts নেয় এবং আউটপুট হিসাবে tfma.Extracts ফেরত দেয়। প্রোটো-টাইপিক্যাল এক্সট্র্যাক্টর হল tfma.extractors.PredictExtractor যা রিড ইনপুট ট্রান্সফর্ম দ্বারা উত্পাদিত ইনপুট এক্সট্র্যাক্ট ব্যবহার করে এবং ভবিষ্যদ্বাণীর নির্যাস তৈরি করতে একটি মডেলের মাধ্যমে এটি চালায়। কাস্টমাইজড এক্সট্র্যাক্টর যেকোন সময়ে সন্নিবেশ করা যেতে পারে যদি তাদের ট্রান্সফর্মগুলি tfma.Extracts tfma.Extracts সাথে সামঞ্জস্যপূর্ণ হয়। একটি নিষ্কাশনকারী নিম্নরূপ সংজ্ঞায়িত করা হয়:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
ইনপুট এক্সট্র্যাক্টর
tfma.extractors.InputExtractor টি tf.train.Example থেকে কাঁচা বৈশিষ্ট্য, কাঁচা লেবেল এবং কাঁচা উদাহরণ ওজন বের করতে ব্যবহৃত হয়। মেট্রিক্স স্লাইসিং এবং গণনাতে ব্যবহারের জন্য উদাহরণ রেকর্ড। ডিফল্টরূপে মানগুলি যথাক্রমে এক্সট্র্যাক্ট কী features , labels এবং example_weights এর অধীনে সংরক্ষণ করা হয়। একক-আউটপুট মডেল লেবেল এবং উদাহরণ ওজন সরাসরি np.ndarray মান হিসাবে সংরক্ষণ করা হয়। মাল্টি-আউটপুট মডেল লেবেল এবং উদাহরণ ওজন np.ndarray মানের নির্দেশ হিসাবে সংরক্ষণ করা হয় (আউটপুট নাম দ্বারা চাবি করা)। মাল্টি-মডেল মূল্যায়ন করা হলে লেবেল এবং উদাহরণের ওজনগুলি আরও একটি ডিক্টের মধ্যে এমবেড করা হবে (মডেলের নাম দ্বারা চাবি করা)।
PredictExtractor
tfma.extractors.PredictExtractor মডেল ভবিষ্যদ্বাণী চালায় এবং tfma.Extracts ডিক্টে মূল predictions অধীনে সেগুলি সংরক্ষণ করে৷ একক-আউটপুট মডেলের পূর্বাভাস সরাসরি ভবিষ্যদ্বাণীকৃত আউটপুট মান হিসাবে সংরক্ষণ করা হয়। মাল্টি-আউটপুট মডেলের ভবিষ্যদ্বাণীগুলি আউটপুট মানগুলির একটি নির্দেশ হিসাবে সংরক্ষণ করা হয় (আউটপুট নাম দ্বারা চাবি করা)। যদি মাল্টি-মডেল মূল্যায়ন করা হয় তবে ভবিষ্যদ্বাণীটি আরও একটি ডিক্টের মধ্যে এমবেড করা হবে (মডেলের নাম দ্বারা চাবি করা)। ব্যবহৃত প্রকৃত আউটপুট মান মডেলের উপর নির্ভর করে (যেমন TF অনুমানকারীর রিটার্ন আউটপুট ডিক্ট আকারে যেখানে কেরাস np.ndarray মান প্রদান করে)।
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor নিষ্কাশিত বৈশিষ্ট্যের উপর ভিত্তি করে প্রতিটি উদাহরণের ইনপুটে কোন স্লাইস প্রযোজ্য হবে তা নির্ধারণ করতে স্লাইসিং স্পেস ব্যবহার করে এবং মূল্যায়নকারীদের দ্বারা পরবর্তীতে ব্যবহারের জন্য নির্যাসের সাথে সংশ্লিষ্ট স্লাইসিং মান যোগ করে।
মূল্যায়ন
মূল্যায়ন হল একটি নির্যাস গ্রহণ এবং মূল্যায়ন করার প্রক্রিয়া। যদিও নিষ্কাশন পাইপলাইনের শেষে মূল্যায়ন করা সাধারণ, তবে এমন কিছু ব্যবহার আছে যেগুলি নিষ্কাশন প্রক্রিয়ার আগে মূল্যায়নের প্রয়োজন হয়। যেমন মূল্যায়নকারীরা নিষ্কাশনকারীদের সাথে যুক্ত থাকে যাদের আউটপুট তাদের বিরুদ্ধে মূল্যায়ন করা উচিত। একজন মূল্যায়নকারীকে নিম্নরূপ সংজ্ঞায়িত করা হয়েছে:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
লক্ষ্য করুন যে একজন মূল্যায়নকারী হল একটি beam.PTransform যা tfma.Extracts নেয়। ইনপুট হিসাবে এক্সট্রাক্ট করে। মূল্যায়ন প্রক্রিয়ার অংশ হিসাবে নির্যাসগুলিতে অতিরিক্ত রূপান্তর সম্পাদন করা থেকে একটি বাস্তবায়নকে বাধা দেওয়ার কিছু নেই। এক্সট্রাক্টরদের বিপরীতে যেগুলিকে অবশ্যই একটি tfma.Extracts dict ফেরত দিতে হবে, একজন মূল্যায়নকারী যে ধরনের আউটপুট তৈরি করতে পারে তার উপর কোন বিধিনিষেধ নেই যদিও অধিকাংশ মূল্যায়নকারীও একটি ডিক্ট (যেমন মেট্রিক নাম এবং মান) প্রদান করে।
মেট্রিক্স এবং প্লট মূল্যায়নকারী
tfma.evaluators.MetricsAndPlotsEvaluator features , labels এবং predictions ইনপুট হিসাবে নেয়, tfma.slicer.FanoutSlices এর মাধ্যমে সেগুলিকে স্লাইস দ্বারা গোষ্ঠীবদ্ধ করতে চালায় এবং তারপর মেট্রিক্স এবং প্লট গণনা করে৷ এটি মেট্রিক্স এবং প্লট কী এবং মানগুলির অভিধান আকারে আউটপুট তৈরি করে (এগুলি পরে tfma.writers.MetricsAndPlotsWriter দ্বারা আউটপুটের জন্য ক্রমিক প্রোটোতে রূপান্তরিত হয়)।
ফলাফল লিখুন
WriteResults পর্যায় হল যেখানে মূল্যায়ন আউটপুট ডিস্কে লেখা হয়। WriteResults আউটপুট কীগুলির উপর ভিত্তি করে ডেটা লিখতে লেখকদের ব্যবহার করে। উদাহরণস্বরূপ, একটি tfma.evaluators.Evaluation metrics এবং plots কী থাকতে পারে। এগুলি তখন 'মেট্রিক্স' এবং 'প্লট' নামক মেট্রিক্স এবং প্লট অভিধানগুলির সাথে যুক্ত হবে। লেখকরা প্রতিটি ফাইল কীভাবে লিখবেন তা নির্দিষ্ট করে:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
মেট্রিক্স এবং প্লট রাইটার
আমরা একটি tfma.writers.MetricsAndPlotsWriter প্রদান করি যা মেট্রিক্স এবং প্লট অভিধানকে ক্রমিক প্রোটোতে রূপান্তর করে এবং সেগুলিকে ডিস্কে লেখে।
আপনি যদি একটি ভিন্ন ক্রমিক বিন্যাস ব্যবহার করতে চান, আপনি একটি কাস্টম লেখক তৈরি করতে পারেন এবং পরিবর্তে এটি ব্যবহার করতে পারেন। যেহেতু লেখকদের কাছে পাঠানো tfma.evaluators.Evaluation এ সমস্ত মূল্যায়নকারীদের সম্মিলিত আউটপুট রয়েছে, তাই একটি tfma.writers.Write সহায়ক রূপান্তর প্রদান করা হয়েছে যা লেখকরা তাদের ptransform বাস্তবায়নে উপযুক্ত beam.PCollection নির্বাচন করতে ব্যবহার করতে পারেন। আউটপুট কী (একটি উদাহরণের জন্য নীচে দেখুন)।
কাস্টমাইজেশন
tfma.run_model_analysis পদ্ধতিটি পাইপলাইনের দ্বারা ব্যবহৃত এক্সট্রাক্টর, evaluators এবং লেখকদের কাস্টমাইজ করার জন্য extractors , মূল্যায়নকারী এবং writers আর্গুমেন্ট নেয়। যদি কোনো আর্গুমেন্ট না দেওয়া হয় তাহলে tfma.default_extractors , tfma.default_evaluators , এবং tfma.default_writers ডিফল্টরূপে ব্যবহার করা হয়।
কাস্টম এক্সট্র্যাক্টর
একটি কাস্টম এক্সট্র্যাক্টর তৈরি করতে, একটি tfma.extractors.Extractor টাইপ তৈরি করুন যা একটি beam.PTransform নিয়ে tfma.Extracts ইনপুট হিসেবে নেয় এবং tfma.Extracts আউটপুট হিসেবে ফিরিয়ে দেয়। এক্সট্রাক্টরের উদাহরণ tfma.extractors এর অধীনে পাওয়া যায়।
কাস্টম মূল্যায়নকারী
একটি কাস্টম মূল্যায়নকারী তৈরি করতে, একটি tfma.evaluators.Evaluator টাইপ তৈরি করুন যা একটি beam.PTransform করে tfma.Extracts ইনপুট হিসেবে নেয় এবং tfma.evaluators.Evaluation আউটপুট হিসেবে ফেরত দেয়। একটি খুব মৌলিক মূল্যায়নকারী শুধুমাত্র আগত tfma.Extracts নিতে পারে এবং একটি টেবিলে সংরক্ষণ করার জন্য আউটপুট করতে পারে। tfma.evaluators.AnalysisTableEvaluator ঠিক এটাই করে। একটি আরও জটিল মূল্যায়নকারী অতিরিক্ত প্রক্রিয়াকরণ এবং ডেটা একত্রীকরণ করতে পারে। উদাহরণ হিসেবে tfma.evaluators.MetricsAndPlotsEvaluator দেখুন।
মনে রাখবেন tfma.evaluators.MetricsAndPlotsEvaluator নিজেই কাস্টম মেট্রিক্স সমর্থন করার জন্য কাস্টমাইজ করা যেতে পারে (আরো বিশদ বিবরণের জন্য মেট্রিক্স দেখুন)।
কাস্টম লেখক
একটি কাস্টম লেখক তৈরি করতে, একটি tfma.writers.Writer টাইপ তৈরি করুন যা একটি beam.PTransform মোড়ানো হয়। PT ট্রান্সফর্ম tfma.evaluators.Evaluation ইনপুট হিসাবে মূল্যায়ন এবং আউটপুট হিসাবে beam.pvalue.PDone প্রদান করে। নিম্নলিখিতটি মেট্রিক্স ধারণকারী TFRrecords লেখার জন্য একজন লেখকের একটি মৌলিক উদাহরণ:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
একজন লেখকের ইনপুট নির্ভর করে সংশ্লিষ্ট মূল্যায়নকারীর আউটপুটের উপর। উপরের উদাহরণের জন্য, আউটপুট হল একটি ক্রমিক প্রোটো যা tfma.evaluators.MetricsAndPlotsEvaluator দ্বারা উত্পাদিত হয়। tfma.evaluators.AnalysisTableEvaluator এর একজন লেখক tfma.Extracts এর একটি beam.pvalue.PCollection লেখার জন্য দায়ী থাকবেন।
উল্লেখ্য যে একজন লেখক ব্যবহার করা আউটপুট কী (যেমন tfma.METRICS_KEY , tfma.ANALYSIS_KEY , ইত্যাদি) মাধ্যমে মূল্যায়নকারীর আউটপুটের সাথে যুক্ত।
ধাপে ধাপে উদাহরণ
যখন tfma.evaluators.MetricsAndPlotsEvaluator এবং tfma.evaluators.AnalysisTableEvaluator উভয়ই ব্যবহার করা হয় তখন নিষ্কাশন এবং মূল্যায়ন পাইপলাইনের সাথে জড়িত পদক্ষেপগুলির একটি উদাহরণ নিচে দেওয়া হল:
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files