
Visão geral
O pipeline do TensorFlow Model Analysis (TFMA) é representado da seguinte forma:
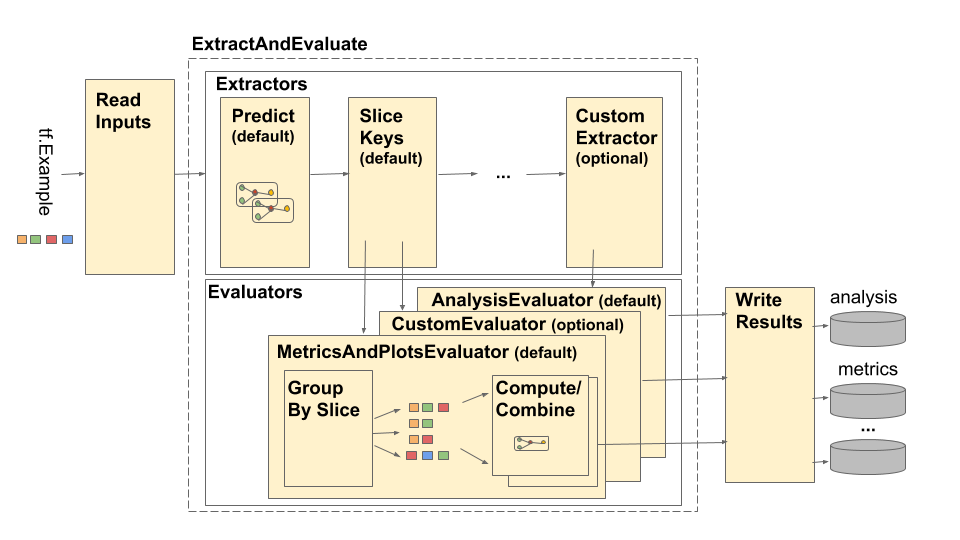
O pipeline é composto por quatro componentes principais:
- Ler entradas
- Extração
- Avaliação
- Escrever resultados
Esses componentes fazem uso de dois tipos principais: tfma.Extracts e tfma.evaluators.Evaluation . O tipo tfma.Extracts representa dados extraídos durante o processamento do pipeline e pode corresponder a um ou mais exemplos do modelo. tfma.evaluators.Evaluation representa o resultado da avaliação dos extratos em vários pontos durante o processo de extração. Para fornecer uma API flexível, esses tipos são apenas dictos onde as chaves são definidas (reservadas para uso) por diferentes implementações. Os tipos são definidos da seguinte forma:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Observe que tfma.Extracts nunca são escritos diretamente; eles devem sempre passar por um avaliador para produzir um tfma.evaluators.Evaluation que é então escrito. Observe também que tfma.Extracts são dictos armazenados em um beam.pvalue.PCollection (ou seja, beam.PTransform s são tomados como entrada beam.pvalue.PCollection[tfma.Extracts] ), enquanto um tfma.evaluators.Evaluation é um dict cujos valores são beam.pvalue.PCollection s (ou seja, beam.PTransform s tomam o próprio dict como argumento para a entrada beam.value.PCollection ). Em outras palavras, tfma.evaluators.Evaluation é usado no tempo de construção do pipeline, mas tfma.Extracts é usado no tempo de execução do pipeline.
Ler entradas
O estágio ReadInputs é composto por uma transformação que pega entradas brutas (tf.train.Example, CSV, ...) e as converte em extrações. Hoje, as extrações são representadas como bytes de entrada brutos armazenados em tfma.INPUT_KEY , no entanto, as extrações podem estar em qualquer formato que seja compatível com o pipeline de extração - o que significa que ele cria tfma.Extracts como saída e que essas extrações são compatíveis com downstream extratores. Cabe aos diferentes extratores documentar claramente o que necessitam.
Extração
O processo de extração é uma lista de beam.PTransform s que são executados em série. Os extratores pegam tfma.Extracts como entrada e retornam tfma.Extracts como saída. O extrator prototípico é o tfma.extractors.PredictExtractor que usa a extração de entrada produzida pela transformação de entradas de leitura e a executa por meio de um modelo para produzir extrações de predições. Extratores personalizados podem ser inseridos a qualquer momento, desde que suas transformações estejam em conformidade com a API tfma.Extracts in e tfma.Extracts out. Um extrator é definido da seguinte forma:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
Extrator de entrada
O tfma.extractors.InputExtractor é usado para extrair recursos brutos, rótulos brutos e pesos de exemplo brutos de registros tf.train.Example para uso em fatiamento e cálculos de métricas. Por padrão, os valores são armazenados nas chaves de extração features , labels e example_weights respectivamente. Rótulos de modelo de saída única e pesos de exemplo são armazenados diretamente como valores np.ndarray . Rótulos de modelo de múltiplas saídas e pesos de exemplo são armazenados como dictos de valores np.ndarray (digitados pelo nome de saída). Se a avaliação de vários modelos for realizada, os rótulos e os pesos dos exemplos serão incorporados em outro dict (digitado pelo nome do modelo).
PreverExtrator
O tfma.extractors.PredictExtractor executa previsões de modelo e as armazena nas principais predictions no ditado tfma.Extracts . As previsões do modelo de saída única são armazenadas diretamente como os valores de saída previstos. As previsões do modelo de múltiplas saídas são armazenadas como um ditado de valores de saída (digitados pelo nome da saída). Se a avaliação multimodelo for realizada, a previsão será incorporada em outro dict (digitado pelo nome do modelo). O valor de saída real usado depende do modelo (por exemplo, as saídas de retorno do estimador TF na forma de um ditado, enquanto keras retorna valores np.ndarray ).
SliceKeyExtractor
O tfma.extractors.SliceKeyExtractor usa a especificação de fatiamento para determinar quais fatias se aplicam a cada entrada de exemplo com base nos recursos extraídos e adiciona os valores de fatiamento correspondentes às extrações para uso posterior pelos avaliadores.
Avaliação
Avaliação é o processo de obter um extrato e avaliá-lo. Embora seja comum realizar a avaliação no final do pipeline de extração, há casos de uso que exigem avaliação no início do processo de extração. Como tais avaliadores estão associados aos extratores cujos resultados devem ser avaliados. Um avaliador é definido da seguinte forma:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Observe que um avaliador é um beam.PTransform que usa tfma.Extracts como entradas. Não há nada que impeça uma implementação de realizar transformações adicionais nas extrações como parte do processo de avaliação. Ao contrário dos extratores que devem retornar um dict tfma.Extracts , não há restrições sobre os tipos de saídas que um avaliador pode produzir, embora a maioria dos avaliadores também retorne um dict (por exemplo, nomes e valores de métricas).
Avaliador de métricas e gráficos
O tfma.evaluators.MetricsAndPlotsEvaluator pega features , labels e predictions como entrada, executa-os por meio de tfma.slicer.FanoutSlices para agrupá-los por fatias e, em seguida, executa cálculos de métricas e gráficos. Ele produz resultados na forma de dicionários de métricas e plota chaves e valores (estes são posteriormente convertidos em protos serializados para saída por tfma.writers.MetricsAndPlotsWriter ).
Escrever resultados
O estágio WriteResults é onde a saída da avaliação é gravada no disco. WriteResults usa gravadores para gravar os dados com base nas chaves de saída. Por exemplo, um tfma.evaluators.Evaluation pode conter chaves para metrics e plots . Estes seriam então associados aos dicionários de métricas e gráficos chamados 'métricas' e 'plots'. Os escritores especificam como escrever cada arquivo:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
Fornecemos um tfma.writers.MetricsAndPlotsWriter que converte as métricas e plota dicionários em protos serializados e os grava no disco.
Se desejar usar um formato de serialização diferente, você pode criar um gravador personalizado e usá-lo. Como o tfma.evaluators.Evaluation passado para os gravadores contém a saída de todos os avaliadores combinados, uma transformação auxiliar tfma.writers.Write é fornecida que os gravadores podem usar em suas implementações ptransform para selecionar os beam.PCollection s apropriados com base em um chave de saída (veja um exemplo abaixo).
Personalização
O método tfma.run_model_analysis usa argumentos extractors , evaluators e writers para personalizar os extratores, avaliadores e escritores usados pelo pipeline. Se nenhum argumento for fornecido, tfma.default_extractors , tfma.default_evaluators e tfma.default_writers serão usados por padrão.
Extratores personalizados
Para criar um extrator personalizado, crie um tipo tfma.extractors.Extractor que envolva um beam.PTransform tomando tfma.Extracts como entrada e retornando tfma.Extracts como saída. Exemplos de extratores estão disponíveis em tfma.extractors .
Avaliadores personalizados
Para criar um avaliador personalizado, crie um tipo tfma.evaluators.Evaluator que envolva um beam.PTransform tomando tfma.Extracts como entrada e retornando tfma.evaluators.Evaluation como saída. Um avaliador muito básico pode simplesmente pegar o tfma.Extracts recebido e enviá-lo para armazenamento em uma tabela. Isso é exatamente o que tfma.evaluators.AnalysisTableEvaluator faz. Um avaliador mais complicado pode realizar processamento adicional e agregação de dados. Consulte tfma.evaluators.MetricsAndPlotsEvaluator como exemplo.
Observe que o próprio tfma.evaluators.MetricsAndPlotsEvaluator pode ser personalizado para oferecer suporte a métricas personalizadas (consulte métricas para obter mais detalhes).
Escritores personalizados
Para criar um gravador personalizado, crie um tipo tfma.writers.Writer que envolva um beam.PTransform tomando tfma.evaluators.Evaluation como entrada e retornando beam.pvalue.PDone como saída. A seguir está um exemplo básico de um escritor para escrever TFRecords contendo métricas:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
As contribuições de um redator dependem da produção do avaliador associado. Para o exemplo acima, a saída é um proto serializado produzido pelo tfma.evaluators.MetricsAndPlotsEvaluator . Um redator do tfma.evaluators.AnalysisTableEvaluator seria responsável por escrever um beam.pvalue.PCollection de tfma.Extracts .
Observe que um escritor está associado à saída de um avaliador através da chave de saída usada (por exemplo, tfma.METRICS_KEY , tfma.ANALYSIS_KEY , etc).
Exemplo passo a passo
A seguir está um exemplo das etapas envolvidas no pipeline de extração e avaliação quando tfma.evaluators.MetricsAndPlotsEvaluator e tfma.evaluators.AnalysisTableEvaluator são usados:
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files