
סקירה כללית
הצינור של TensorFlow Model Analysis (TFMA) מתואר כדלקמן:
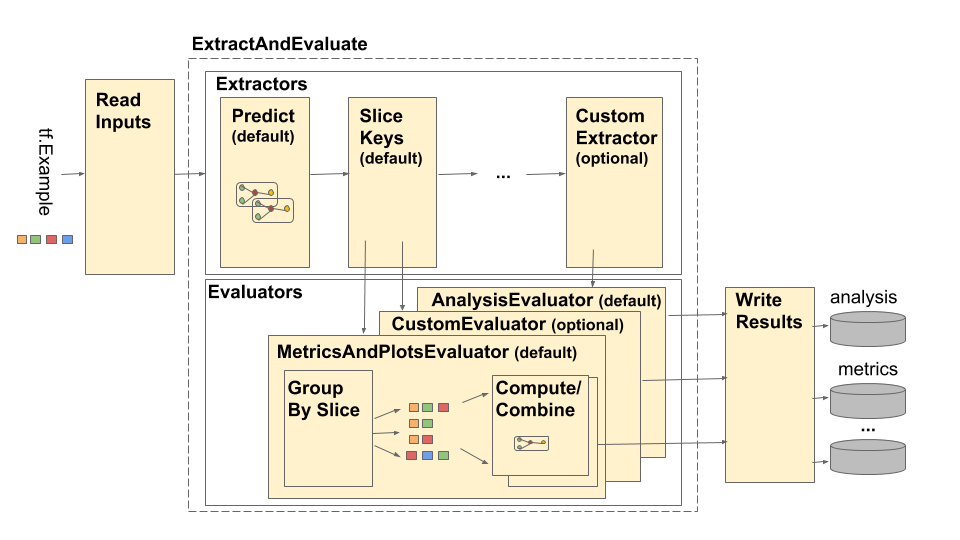
הצינור מורכב מארבעה מרכיבים עיקריים:
- קרא קלט
- הוֹצָאָה
- הַעֲרָכָה
- כתוב תוצאות
רכיבים אלו עושים שימוש בשני סוגים עיקריים: tfma.Extracts ו- tfma.evaluators.Evaluation . הסוג tfma.Extracts מייצג נתונים שחולצו במהלך עיבוד הצינור ועשויים להתאים לדוגמא אחת או יותר עבור המודל. tfma.evaluators.Evaluation מייצג את התפוקה מהערכת התמציות בנקודות שונות במהלך תהליך המיצוי. על מנת לספק API גמיש, סוגים אלה הם רק dicts שבהם המפתחות מוגדרים (שמורים לשימוש) על ידי יישומים שונים. הסוגים מוגדרים כך:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
שימו לב ש- tfma.Extracts אינן נכתבות ישירות, הן חייבות תמיד לעבור דרך מעריך כדי לייצר tfma.evaluators.Evaluation שנכתבת לאחר מכן. כמו כן, שים לב ש- tfma.Extracts הם dictates המאוחסנים ב- beam.pvalue.PCollection (כלומר, beam.PTransform s לוקחים כקלט beam.pvalue.PCollection[tfma.Extracts] ) בעוד ש- tfma.evaluators.Evaluation הוא dict שהערכים שלו הם beam.pvalue.PCollection s (כלומר beam.PTransform s לוקחים את ה-dict עצמו כארגומנט לקלט beam.value.PCollection ). במילים אחרות נעשה שימוש ב- tfma.evaluators.Evaluation בזמן בניית צינור, אבל ב- tfma.Extracts נעשה שימוש בזמן ריצה של צינור.
קרא קלט
שלב ReadInputs מורכב מתמרה שלוקחת תשומות גולמיות (tf.train.Example, CSV, ...) וממירה אותם לתמציות. כיום התמציות מיוצגות כבייטי קלט גולמיים המאוחסנים תחת tfma.INPUT_KEY , אולם התמציות יכולות להיות בכל צורה שתואמת לצינור החילוץ -- כלומר היא יוצרת tfma.Extracts כפלט, ושתמציות אלו תואמות למורד הזרם. חולצים. על המחלצים השונים לתעד בבירור מה הם דורשים.
הוֹצָאָה
תהליך החילוץ הוא רשימה של beam.PTransform s המופעלות בסדרה. המחלצים לוקחים tfma.Extracts כקלט ומחזירים tfma.Extracts כפלט. מחלץ האב-טיפוס הוא ה- tfma.extractors.PredictExtractor אשר משתמש בתמצית הקלט המופקת על ידי טרנספורמציה של קלט הקריאה ומריץ אותו דרך מודל להפקת תמציות חיזוי. ניתן להכניס מחלצים מותאמים אישית בכל נקודה בתנאי שהטרנספורמציות שלהם תואמות את ה-API של tfma.Extracts in ו- tfma.Extracts out. חולץ מוגדר כדלקמן:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
InputExtractor
ה- tfma.extractors.InputExtractor משמש לחילוץ תכונות גולמיות, תוויות גולמיות ומשקולות לדוגמה גולמיות מרשומות tf.train.Example לשימוש בחיתוך מדדים וחישובים. כברירת מחדל, הערכים מאוחסנים תחת features מפתחות חילוץ , labels ו- example_weights בהתאמה. תוויות מודל פלט בודד ומשקולות לדוגמה מאוחסנות ישירות כערכי np.ndarray . תוויות מודל מרובות פלט ומשקולות לדוגמה מאוחסנות ככתבים של ערכי np.ndarray (מקודדים לפי שם הפלט). אם מבוצעת הערכה מרובת מודלים, התוויות ומשקולות הדוגמאות יוטמעו עוד יותר בתוך הכתבה אחרת (מקודדת לפי שם הדגם).
PredictExtractor
ה- tfma.extractors.PredictExtractor מריץ תחזיות מודל ומאחסן אותם תחת predictions המפתח ב- tfma.Extracts dict. תחזיות מודל פלט יחיד מאוחסנות ישירות כערכי הפלט החזויים. תחזיות מודל ריבוי פלט מאוחסנות כהכתבה של ערכי פלט (מקודדים לפי שם הפלט). אם מבוצעת הערכת ריבוי מודלים, החיזוי יוטמע עוד יותר בתוך דיקציה אחרת (מפתח לפי שם הדגם). ערך הפלט בפועל בשימוש תלוי במודל (לדוגמה, תפוקות ההחזר של מעריך TF בצורה של dict ואילו keras מחזירה ערכי np.ndarray ).
SliceKeyExtractor
ה- tfma.extractors.SliceKeyExtractor משתמש במפרט החיתוך כדי לקבוע אילו פרוסות חלות על כל קלט לדוגמה בהתבסס על התכונות שחולצו ומוסיף את ערכי החיתוך התואמים לתמציות לשימוש מאוחר יותר על ידי המעריכים.
הַעֲרָכָה
הערכה היא תהליך של נטילת תמצית והערכתה. אמנם מקובל לבצע הערכה בסוף צינור המיצוי, אך ישנם מקרי שימוש הדורשים הערכה מוקדם יותר בתהליך המיצוי. כיוון שמעריכים כאלה משויכים למחלצים שמולם יש להעריך את התפוקה שלהם. מעריך מוגדר כדלקמן:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
שימו לב שמעריך הוא beam.PTransform שלוקח tfma.Extracts כקלט. אין שום דבר שמפריע למימוש לבצע טרנספורמציות נוספות על התמציות כחלק מתהליך ההערכה. בניגוד למחלצים שחייבים להחזיר dict tfma.Extracts , אין הגבלות על סוגי התפוקות שמעריך יכול להפיק אם כי רוב המעריכים גם מחזירים dict (למשל של שמות וערכים מדדים).
MetricsAndPlotsEvaluator
ה- tfma.evaluators.MetricsAndPlotsEvaluator לוקח features , labels predictions כקלט, מריץ אותם דרך tfma.slicer.FanoutSlices כדי לקבץ אותם לפי פרוסות, ולאחר מכן מבצע חישובי מדדים וערימות. הוא מייצר פלטים בצורה של מילונים של מדדים ומפתחות וערכים עלילה (אלה מומרים מאוחר יותר לפרוטוטוס סידורי לפלט על ידי tfma.writers.MetricsAndPlotsWriter ).
כתוב תוצאות
שלב WriteResults הוא המקום שבו פלט ההערכה נכתב לדיסק. WriteResults משתמש בסופרים כדי לכתוב את הנתונים על סמך מפתחות הפלט. לדוגמה, קובץ tfma.evaluators.Evaluation עשוי להכיל מפתחות metrics plots . אלה ישויכו אז למילוני המדדים והעלילות המכונים 'מטרים' ו'עלילות'. הכותבים מציינים כיצד לכתוב כל קובץ:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
אנו מספקים tfma.writers.MetricsAndPlotsWriter הממיר את המדדים ומילוני העלילה לפרוטואים מסודרים וכותב אותם לדיסק.
אם ברצונך להשתמש בפורמט סריאליזציה אחר, תוכל ליצור כותב מותאם אישית ולהשתמש בו במקום זאת. מכיוון שההערכה של tfma.evaluators.Evaluation שהועברה לכותבים מכילה את הפלט עבור כל המעריכים גם יחד, ניתנת טרנספורמציה של tfma.writers.Write מסייעת שכותבים יכולים להשתמש בה ביישום ptransform שלהם כדי לבחור את beam.PCollection המתאימה. PCollection s מבוסס על מפתח פלט (ראה למטה לדוגמא).
התאמה אישית
שיטת tfma.run_model_analysis לוקחת טיעונים extractors , evaluators writers להתאמה אישית של המחלצים, המעריכים והכותבים המשמשים את הצינור. אם לא סופקו ארגומנטים, tfma.default_extractors , tfma.default_evaluators ו- tfma.default_writers משמשים כברירת מחדל.
חולצים מותאמים אישית
כדי ליצור מחלץ מותאם אישית, צור סוג tfma.extractors.Extractor שעוטף beam.PTransform לוקח tfma.Extracts כקלט והחזרת tfma.Extracts כפלט. דוגמאות למחלצים זמינות תחת tfma.extractors .
מעריכים מותאמים אישית
כדי ליצור מעריך מותאם אישית, צור סוג tfma.evaluators.Evaluator שעוטף beam.PTransform לוקח tfma.Extracts כקלט והחזרת tfma.evaluators.Evaluation כפלט. מעריך בסיסי מאוד יכול לקחת את ה- tfma.Extracts הנכנסים ולהוציא אותם לאחסון בטבלה. זה בדיוק מה שעושה tfma.evaluators.AnalysisTableEvaluator . מעריך מסובך יותר עשוי לבצע עיבוד נוסף וצבירת נתונים. ראה את tfma.evaluators.MetricsAndPlotsEvaluator כדוגמה.
שימו לב שניתן להתאים את ה- tfma.evaluators.MetricsAndPlotsEvaluator עצמו לתמיכה במדדים מותאמים אישית (ראה מדדים לפרטים נוספים).
כותבים מותאמים אישית
כדי ליצור כותב מותאם אישית, צור סוג tfma.writers.Writer שעוטף beam.PTransform לוקח tfma.evaluators.Evaluation כקלט והחזרת beam.pvalue.PDone כפלט. להלן דוגמה בסיסית לכותב לכתיבת רשומות TFRecords המכילות מדדים:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
הקלט של סופר תלוי בפלט של המעריך המשויך. עבור הדוגמה שלעיל, הפלט הוא פרוטו מסודר המיוצר על ידי ה- tfma.evaluators.MetricsAndPlotsEvaluator . כותב עבור tfma.evaluators.AnalysisTableEvaluator יהיה אחראי לכתיבת beam.pvalue.PCollection של tfma.Extracts .
שימו לב שכותב משויך לפלט של מעריך באמצעות מפתח הפלט שבו נעשה שימוש (למשל tfma.METRICS_KEY , tfma.ANALYSIS_KEY וכו').
דוגמה שלב אחר שלב
להלן דוגמה לשלבים המעורבים בצינור החילוץ וההערכה כאשר נעשה שימוש גם ב- tfma.evaluators.MetricsAndPlotsEvaluator וגם tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(ריצה_אחרי:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(ריצה_אחרי:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files