
Descripción general
La canalización del Análisis del modelo TensorFlow (TFMA) se representa de la siguiente manera:
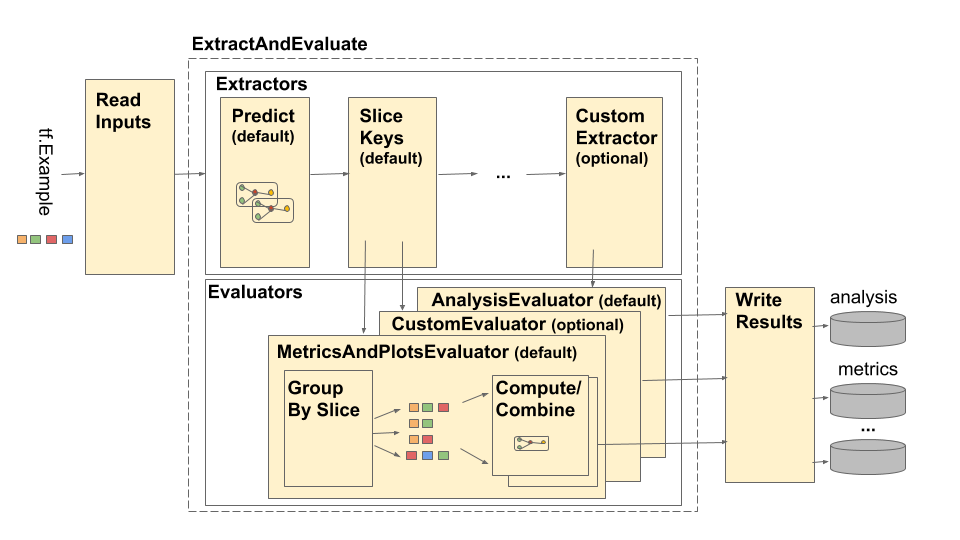
El oleoducto se compone de cuatro componentes principales:
- Leer entradas
- Extracción
- Evaluación
- Escribir resultados
Estos componentes utilizan dos tipos principales: tfma.Extracts y tfma.evaluators.Evaluation . El tipo tfma.Extracts representa datos que se extraen durante el procesamiento de la canalización y pueden corresponder a uno o más ejemplos del modelo. tfma.evaluators.Evaluation representa el resultado de la evaluación de los extractos en varios puntos durante el proceso de extracción. Para proporcionar una API flexible, estos tipos son solo dictados donde las claves están definidas (reservadas para su uso) por diferentes implementaciones. Los tipos se definen de la siguiente manera:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Tenga en cuenta que tfma.Extracts nunca se escriben directamente; siempre deben pasar por un evaluador para producir una tfma.evaluators.Evaluation que luego se escribe. También tenga en cuenta que tfma.Extracts son dictados que se almacenan en un beam.pvalue.PCollection (es decir, beam.PTransform toman como entrada beam.pvalue.PCollection[tfma.Extracts] ), mientras que un tfma.evaluators.Evaluation es un dictado cuyos valores son beam.pvalue.PCollection s (es decir, beam.PTransform s toman el propio dict como argumento para la entrada beam.value.PCollection ). En otras palabras, tfma.evaluators.Evaluation se usa en el momento de la construcción de la tubería, pero tfma.Extracts se usa en el tiempo de ejecución de la tubería.
Leer entradas
La etapa ReadInputs se compone de una transformación que toma entradas sin procesar (tf.train.Example, CSV, ...) y las convierte en extractos. Hoy en día, los extractos se representan como bytes de entrada sin procesar almacenados en tfma.INPUT_KEY ; sin embargo, los extractos pueden tener cualquier forma que sea compatible con la canalización de extracción, lo que significa que crea tfma.Extracts como salida y que esos extractos son compatibles con el flujo descendente. extractores. Corresponde a los diferentes extractores documentar claramente lo que requieren.
Extracción
El proceso de extracción es una lista de beam.PTransform que se ejecutan en serie. Los extractores toman tfma.Extracts como entrada y devuelven tfma.Extracts como salida. El extractor prototípico es tfma.extractors.PredictExtractor , que utiliza el extracto de entrada producido por la transformación de entradas de lectura y lo ejecuta a través de un modelo para producir extractos de predicciones. Se pueden insertar extractores personalizados en cualquier punto siempre que sus transformaciones se ajusten a la API tfma.Extracts in y tfma.Extracts out. Un extractor se define de la siguiente manera:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
Extractor de entrada
tfma.extractors.InputExtractor se utiliza para extraer características sin procesar, etiquetas sin procesar y pesos de ejemplo sin procesar de registros tf.train.Example para usar en cálculos y divisiones de métricas. De forma predeterminada, los valores se almacenan en las claves de extracción features , labels y example_weights respectivamente. Las etiquetas del modelo de salida única y los pesos de ejemplo se almacenan directamente como valores np.ndarray . Las etiquetas de modelos de múltiples salidas y los pesos de ejemplo se almacenan como dictados de valores np.ndarray (codificados por nombre de salida). Si se realiza una evaluación de múltiples modelos, las etiquetas y los pesos de ejemplo se incrustarán aún más en otro diccionario (codificado por el nombre del modelo).
PredecirExtractor
tfma.extractors.PredictExtractor ejecuta predicciones del modelo y las almacena bajo las predictions clave en el dictado tfma.Extracts . Las predicciones del modelo de salida única se almacenan directamente como los valores de salida predichos. Las predicciones del modelo de múltiples salidas se almacenan como un dictado de los valores de salida (codificados por nombre de salida). Si se realiza una evaluación de múltiples modelos, la predicción se incrustará aún más en otro dictado (codificado por el nombre del modelo). El valor de salida real utilizado depende del modelo (por ejemplo, los resultados de retorno del estimador TF en forma de dict mientras que keras devuelve valores np.ndarray ).
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor utiliza la especificación de corte para determinar qué cortes se aplican a cada entrada de ejemplo en función de las características extraídas y agrega los valores de corte correspondientes a los extractos para su uso posterior por parte de los evaluadores.
Evaluación
La evaluación es el proceso de tomar un extracto y evaluarlo. Si bien es común realizar la evaluación al final del proceso de extracción, hay casos de uso que requieren una evaluación más temprana en el proceso de extracción. Como tales, los evaluadores están asociados con los extractores cuyo resultado deben ser evaluados. Un evaluador se define de la siguiente manera:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Observe que un evaluador es un beam.PTransform que toma tfma.Extracts como entradas. No hay nada que impida que una implementación realice transformaciones adicionales en los extractos como parte del proceso de evaluación. A diferencia de los extractores que deben devolver un dictado tfma.Extracts , no hay restricciones sobre los tipos de resultados que un evaluador puede producir, aunque la mayoría de los evaluadores también devuelven un dictado (por ejemplo, de nombres y valores de métricas).
MetricsAndPlotsEvaluador
tfma.evaluators.MetricsAndPlotsEvaluator toma features , labels y predictions como entrada, las ejecuta a través de tfma.slicer.FanoutSlices para agruparlas por sectores y luego realiza métricas y traza cálculos. Produce resultados en forma de diccionarios de métricas y traza claves y valores (estos luego se convierten en protos serializados para su salida mediante tfma.writers.MetricsAndPlotsWriter ).
Escribir resultados
La etapa WriteResults es donde el resultado de la evaluación se escribe en el disco. WriteResults utiliza escritores para escribir los datos según las claves de salida. Por ejemplo, un tfma.evaluators.Evaluation puede contener claves para metrics y plots . Luego, estos se asociarían con los diccionarios de métricas y gráficos denominados "métricas" y "gráficos". Los escritores especifican cómo escribir cada archivo:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
Proporcionamos un tfma.writers.MetricsAndPlotsWriter que convierte las métricas y traza diccionarios en protos serializados y los escribe en el disco.
Si desea utilizar un formato de serialización diferente, puede crear un escritor personalizado y usarlo en su lugar. Dado que tfma.evaluators.Evaluation pasada a los escritores contiene la salida de todos los evaluadores combinados, se proporciona una transformación auxiliar tfma.writers.Write que los escritores pueden usar en sus implementaciones ptransform para seleccionar los beam.PCollection apropiados basados en un clave de salida (consulte un ejemplo a continuación).
Personalización
El método tfma.run_model_analysis toma extractors , evaluators y writers argumentos para personalizar los extractores, evaluadores y escritores utilizados por la canalización. Si no se proporcionan argumentos, tfma.default_extractors , tfma.default_evaluators y tfma.default_writers se utilizan de forma predeterminada.
Extractores personalizados
Para crear un extractor personalizado, cree un tipo tfma.extractors.Extractor que envuelva un beam.PTransform tomando tfma.Extracts como entrada y devolviendo tfma.Extracts como salida. Hay ejemplos de extractores disponibles en tfma.extractors .
Evaluadores personalizados
Para crear un evaluador personalizado, cree un tipo tfma.evaluators.Evaluator que envuelva un beam.PTransform tomando tfma.Extracts como entrada y devolviendo tfma.evaluators.Evaluation como salida. Un evaluador muy básico podría simplemente tomar los tfma.Extracts entrantes y generarlos para almacenarlos en una tabla. Esto es exactamente lo que hace tfma.evaluators.AnalysisTableEvaluator . Un evaluador más complicado podría realizar procesamiento adicional y agregación de datos. Vea tfma.evaluators.MetricsAndPlotsEvaluator como ejemplo.
Tenga en cuenta que el propio tfma.evaluators.MetricsAndPlotsEvaluator se puede personalizar para admitir métricas personalizadas (consulte métricas para obtener más detalles).
Escritores personalizados
Para crear un escritor personalizado, cree un tipo tfma.writers.Writer que envuelva un beam.PTransform tomando tfma.evaluators.Evaluation como entrada y devolviendo beam.pvalue.PDone como salida. El siguiente es un ejemplo básico de un escritor para escribir TFRecords que contienen métricas:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
Las aportaciones de un escritor dependen de los resultados del evaluador asociado. Para el ejemplo anterior, la salida es un prototipo serializado producido por tfma.evaluators.MetricsAndPlotsEvaluator . Un escritor de tfma.evaluators.AnalysisTableEvaluator sería responsable de escribir un beam.pvalue.PCollection de tfma.Extracts .
Tenga en cuenta que un escritor está asociado con la salida de un evaluador a través de la clave de salida utilizada (por ejemplo, tfma.METRICS_KEY , tfma.ANALYSIS_KEY , etc.).
Ejemplo paso a paso
El siguiente es un ejemplo de los pasos involucrados en el proceso de extracción y evaluación cuando se utilizan tfma.evaluators.MetricsAndPlotsEvaluator y tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files