
Panoramica
La pipeline TensorFlow Model Analysis (TFMA) è rappresentata come segue:
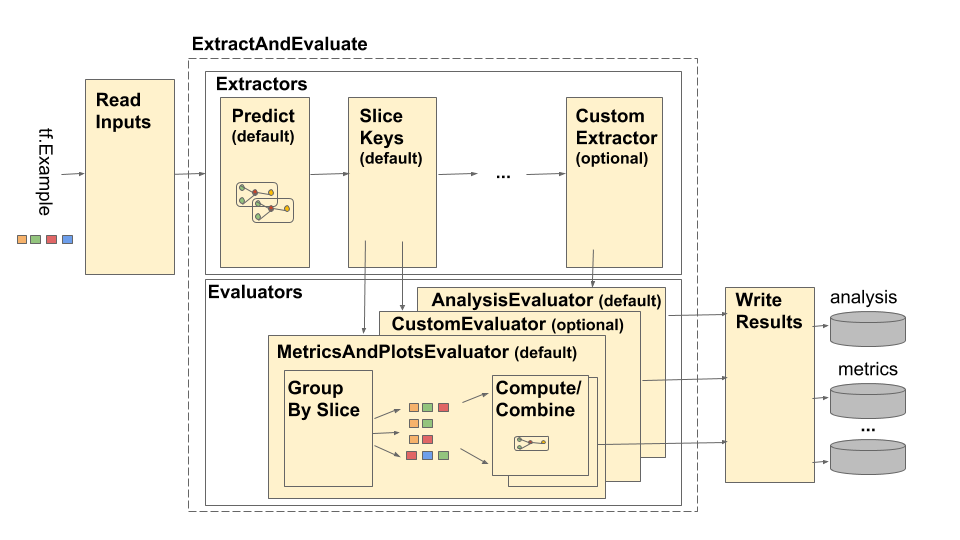
La pipeline è composta da quattro componenti principali:
- Leggi gli input
- Estrazione
- Valutazione
- Scrivi i risultati
Questi componenti utilizzano due tipi principali: tfma.Extracts e tfma.evaluators.Evaluation . Il tipo tfma.Extracts rappresenta i dati estratti durante l'elaborazione della pipeline e può corrispondere a uno o più esempi per il modello. tfma.evaluators.Evaluation rappresenta l'output della valutazione degli estratti in vari punti durante il processo di estrazione. Per fornire un'API flessibile, questi tipi sono semplicemente dei dettami in cui le chiavi sono definite (riservate per l'uso) da diverse implementazioni. I tipi sono definiti come segue:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Tieni presente che tfma.Extracts non vengono mai scritti direttamente, devono sempre passare attraverso un valutatore per produrre un tfma.evaluators.Evaluation che viene poi scritto. Si noti inoltre che tfma.Extracts sono dict memorizzati in un beam.pvalue.PCollection (ovvero beam.PTransform prendono come input beam.pvalue.PCollection[tfma.Extracts] ) mentre un tfma.evaluators.Evaluation è un dict i cui valori sono beam.pvalue.PCollection s (cioè beam.PTransform s prendono il dict stesso come argomento per l'input beam.value.PCollection ). In altre parole, tfma.evaluators.Evaluation viene utilizzato in fase di costruzione della pipeline, ma tfma.Extracts viene utilizzato in fase di esecuzione della pipeline.
Leggi gli input
La fase ReadInputs è costituita da una trasformazione che accetta input grezzi (tf.train.Example, CSV, ...) e li converte in estratti. Oggi gli estratti sono rappresentati come byte di input non elaborati archiviati in tfma.INPUT_KEY , tuttavia gli estratti possono essere in qualsiasi forma compatibile con la pipeline di estrazione, il che significa che crea tfma.Extracts come output e che tali estratti sono compatibili con downstream estrattori. Spetta ai diversi estrattori documentare chiaramente ciò di cui hanno bisogno.
Estrazione
Il processo di estrazione è un elenco di beam.PTransform eseguiti in serie. Gli estrattori accettano tfma.Extracts come input e restituiscono tfma.Extracts come output. L'estrattore prototipo è tfma.extractors.PredictExtractor che utilizza l'estratto di input prodotto dalla trasformazione degli input di lettura e lo esegue attraverso un modello per produrre estratti di previsioni. È possibile inserire estrattori personalizzati in qualsiasi momento, a condizione che le relative trasformazioni siano conformi alle API tfma.Extracts in e tfma.Extracts out. Un estrattore è definito come segue:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
InputExtractor
tfma.extractors.InputExtractor viene utilizzato per estrarre caratteristiche grezze, etichette grezze e pesi di esempio grezzi dai record tf.train.Example da utilizzare nell'affettamento e nei calcoli delle metriche. Per impostazione predefinita, i valori vengono archiviati rispettivamente nelle chiavi di estrazione features , labels e example_weights . Le etichette del modello a output singolo e i pesi di esempio vengono archiviati direttamente come valori np.ndarray . Le etichette del modello a più output e i pesi di esempio vengono archiviati come dettami dei valori np.ndarray (chiavi in base al nome dell'output). Se viene eseguita la valutazione multi-modello, le etichette e i pesi di esempio verranno ulteriormente incorporati in un altro dict (chiavi in base al nome del modello).
PredictExtractor
tfma.extractors.PredictExtractor esegue le previsioni del modello e le memorizza sotto le predictions chiave nel dict tfma.Extracts . Le previsioni del modello a output singolo vengono archiviate direttamente come valori di output previsti. Le previsioni del modello a più output vengono archiviate come un dettato di valori di output (chiavi in base al nome dell'output). Se viene eseguita una valutazione multimodello, la previsione verrà ulteriormente incorporata all'interno di un altro dettato (chiavilizzato in base al nome del modello). Il valore di output effettivo utilizzato dipende dal modello (ad esempio, gli output restituiti dallo stimatore TF sotto forma di dict mentre Keras restituisce valori np.ndarray ).
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor utilizza le specifiche di slicing per determinare quali sezioni si applicano a ciascun input di esempio in base alle funzionalità estratte e aggiunge i valori di slicing corrispondenti agli estratti per un utilizzo successivo da parte dei valutatori.
Valutazione
La valutazione è il processo di prendere un estratto e valutarlo. Sebbene sia comune eseguire la valutazione alla fine della pipeline di estrazione, esistono casi d'uso che richiedono una valutazione nelle prime fasi del processo di estrazione. Poiché tali valutatori sono associati agli estrattori rispetto al cui output dovrebbero essere valutati. Un valutatore è definito come segue:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Si noti che un valutatore è un beam.PTransform che accetta tfma.Extracts come input. Non c'è nulla che impedisca a un'implementazione di eseguire ulteriori trasformazioni sugli estratti come parte del processo di valutazione. A differenza degli estrattori che devono restituire un dict tfma.Extracts , non ci sono restrizioni sui tipi di output che un valutatore può produrre sebbene la maggior parte dei valutatori restituisca anche un dict (ad esempio nomi e valori di metriche).
MetricsAndPlotsEvaluator
tfma.evaluators.MetricsAndPlotsEvaluator accetta features , labels e predictions come input, li esegue attraverso tfma.slicer.FanoutSlices per raggrupparli per sezioni, quindi esegue calcoli di parametri e grafici. Produce output sotto forma di dizionari di metriche e traccia chiavi e valori (questi vengono successivamente convertiti in prototipi serializzati per l'output da tfma.writers.MetricsAndPlotsWriter ).
Scrivi i risultati
La fase WriteResults è il punto in cui l'output della valutazione viene scritto su disco. WriteResults utilizza gli scrittori per scrivere i dati in base alle chiavi di output. Ad esempio, un tfma.evaluators.Evaluation può contenere chiavi per metrics e plots . Questi verrebbero quindi associati ai dizionari di metriche e grafici chiamati "metriche" e "grafici". Gli autori specificano come scrivere ciascun file:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
Forniamo un tfma.writers.MetricsAndPlotsWriter che converte le metriche e traccia i dizionari in prototipi serializzati e li scrive su disco.
Se desideri utilizzare un formato di serializzazione diverso, puoi creare un writer personalizzato e utilizzare quello. Poiché tfma.evaluators.Evaluation passato agli scrittori contiene l'output per tutti i valutatori combinati, viene fornita una trasformazione helper tfma.writers.Write che gli scrittori possono utilizzare nelle loro implementazioni ptransform per selezionare le beam.PCollection appropriate in base a un tasto output (vedi sotto per un esempio).
Personalizzazione
Il metodo tfma.run_model_analysis accetta argomenti extractors , evaluators e writers per personalizzare gli estrattori, i valutatori e i writer utilizzati dalla pipeline. Se non vengono forniti argomenti, tfma.default_extractors , tfma.default_evaluators e tfma.default_writers vengono utilizzati per impostazione predefinita.
Estrattori personalizzati
Per creare un estrattore personalizzato, crea un tipo tfma.extractors.Extractor che avvolge un beam.PTransform prendendo tfma.Extracts come input e restituendo tfma.Extracts come output. Esempi di estrattori sono disponibili in tfma.extractors .
Valutatori personalizzati
Per creare un valutatore personalizzato, crea un tipo tfma.evaluators.Evaluator che avvolga un beam.PTransform prendendo tfma.Extracts come input e restituendo tfma.evaluators.Evaluation come output. Un valutatore molto semplice potrebbe semplicemente prendere i tfma.Extracts in entrata e produrli per memorizzarli in una tabella. Questo è esattamente ciò che fa tfma.evaluators.AnalysisTableEvaluator . Un valutatore più complicato potrebbe eseguire ulteriori elaborazioni e aggregazioni di dati. Vedi tfma.evaluators.MetricsAndPlotsEvaluator come esempio.
Tieni presente che tfma.evaluators.MetricsAndPlotsEvaluator stesso può essere personalizzato per supportare parametri personalizzati (vedi parametri per maggiori dettagli).
Scrittori personalizzati
Per creare un writer personalizzato, crea un tipo tfma.writers.Writer che esegue il wrapper di un beam.PTransform prendendo tfma.evaluators.Evaluation come input e restituendo beam.pvalue.PDone come output. Quello che segue è un esempio di base di uno scrittore per scrivere TFRecord contenenti metriche:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
Gli input di uno scrittore dipendono dall'output del valutatore associato. Per l'esempio precedente, l'output è un prototipo serializzato prodotto da tfma.evaluators.MetricsAndPlotsEvaluator . Uno scrittore per tfma.evaluators.AnalysisTableEvaluator sarebbe responsabile della scrittura di un beam.pvalue.PCollection di tfma.Extracts .
Si noti che uno scrittore è associato all'output di un valutatore tramite la chiave di output utilizzata (ad esempio tfma.METRICS_KEY , tfma.ANALYSIS_KEY , ecc.).
Esempio passo dopo passo
Di seguito è riportato un esempio dei passaggi coinvolti nella pipeline di estrazione e valutazione quando vengono utilizzati sia tfma.evaluators.MetricsAndPlotsEvaluator che tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(esegui_dopo:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(esegui_dopo:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files