
Введение
TFX — это платформа машинного обучения (ML) промышленного масштаба Google, основанная на TensorFlow. Он предоставляет структуру конфигурации и общие библиотеки для интеграции общих компонентов, необходимых для определения, запуска и мониторинга вашей системы машинного обучения.
ТФХ 1.0
Мы рады сообщить о доступности TFX 1.0.0 . Это первый выпуск TFX после бета-тестирования, который предоставляет стабильные общедоступные API и артефакты. Вы можете быть уверены, что ваши будущие конвейеры TFX будут продолжать работать после обновления в пределах области совместимости, определенной в этом RFC .
Установка

![]()
pip install tfx
Ночные пакеты
TFX также размещает ночные пакеты по адресу https://pypi-nightly.tensorflow.org в Google Cloud. Чтобы установить последний ночной пакет, используйте следующую команду:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
При этом будут установлены ночные пакеты для основных зависимостей TFX, таких как анализ модели TensorFlow (TFMA), проверка данных TensorFlow (TFDV), преобразование TensorFlow (TFT), базовые общие библиотеки TFX (TFX-BSL), метаданные ML (MLMD).
О ТФХ
TFX — это платформа для создания и управления рабочими процессами машинного обучения в производственной среде. TFX обеспечивает следующее:
Набор инструментов для построения конвейеров машинного обучения. Конвейеры TFX позволяют организовать рабочий процесс машинного обучения на нескольких платформах, таких как Apache Airflow, Apache Beam и Kubeflow Pipelines.
Набор стандартных компонентов, которые вы можете использовать как часть конвейера или как часть сценария обучения ML. Стандартные компоненты TFX обеспечивают проверенную функциональность, которая поможет вам легко приступить к созданию процесса машинного обучения.
Библиотеки, которые обеспечивают базовую функциональность для многих стандартных компонентов. Вы можете использовать библиотеки TFX, чтобы добавить эту функциональность в свои собственные пользовательские компоненты, или использовать их отдельно.
TFX — это набор инструментов машинного обучения промышленного масштаба, основанный на TensorFlow. Он предоставляет структуру конфигурации и общие библиотеки для интеграции общих компонентов, необходимых для определения, запуска и мониторинга вашей системы машинного обучения.
Стандартные компоненты TFX
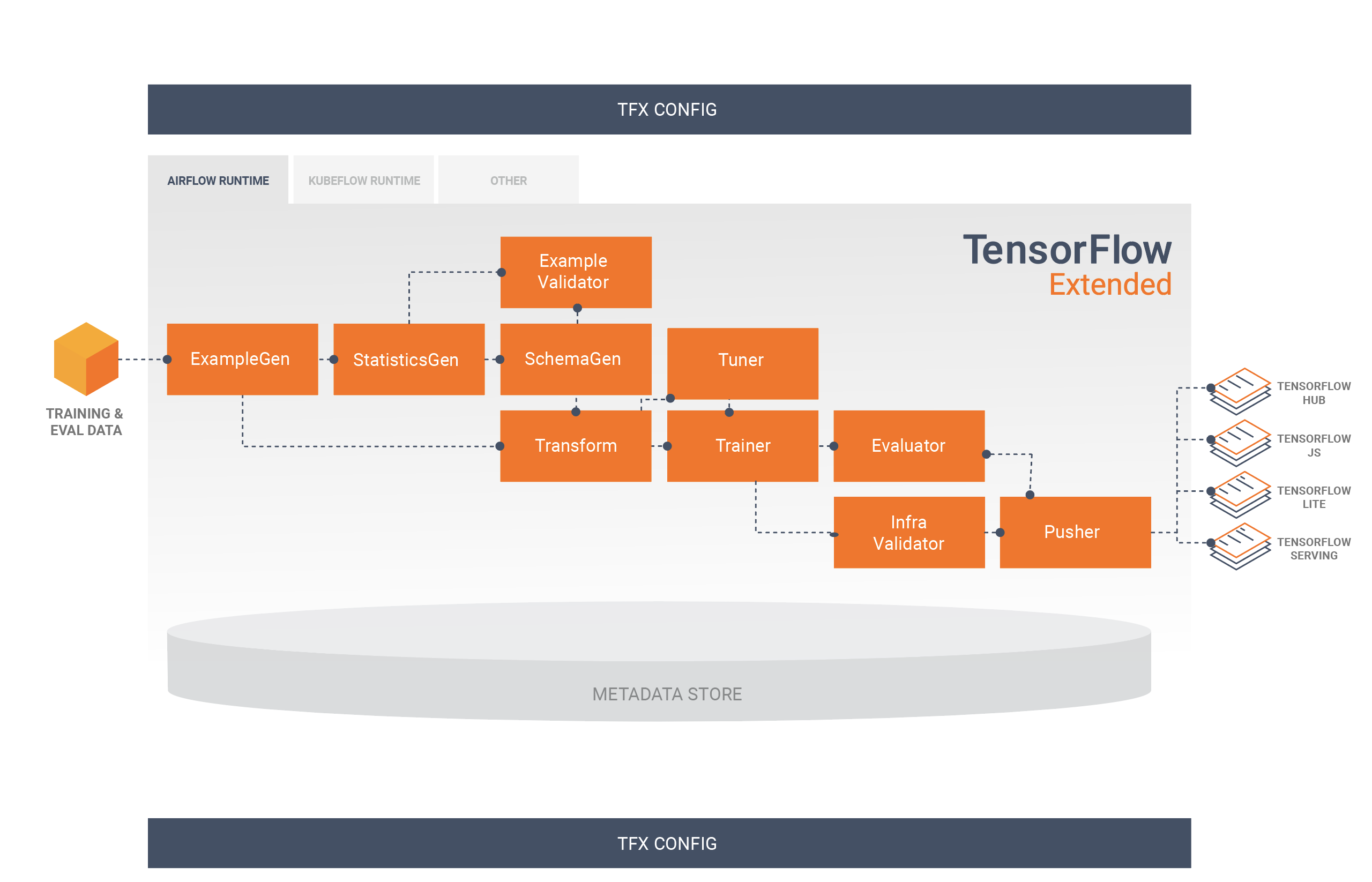
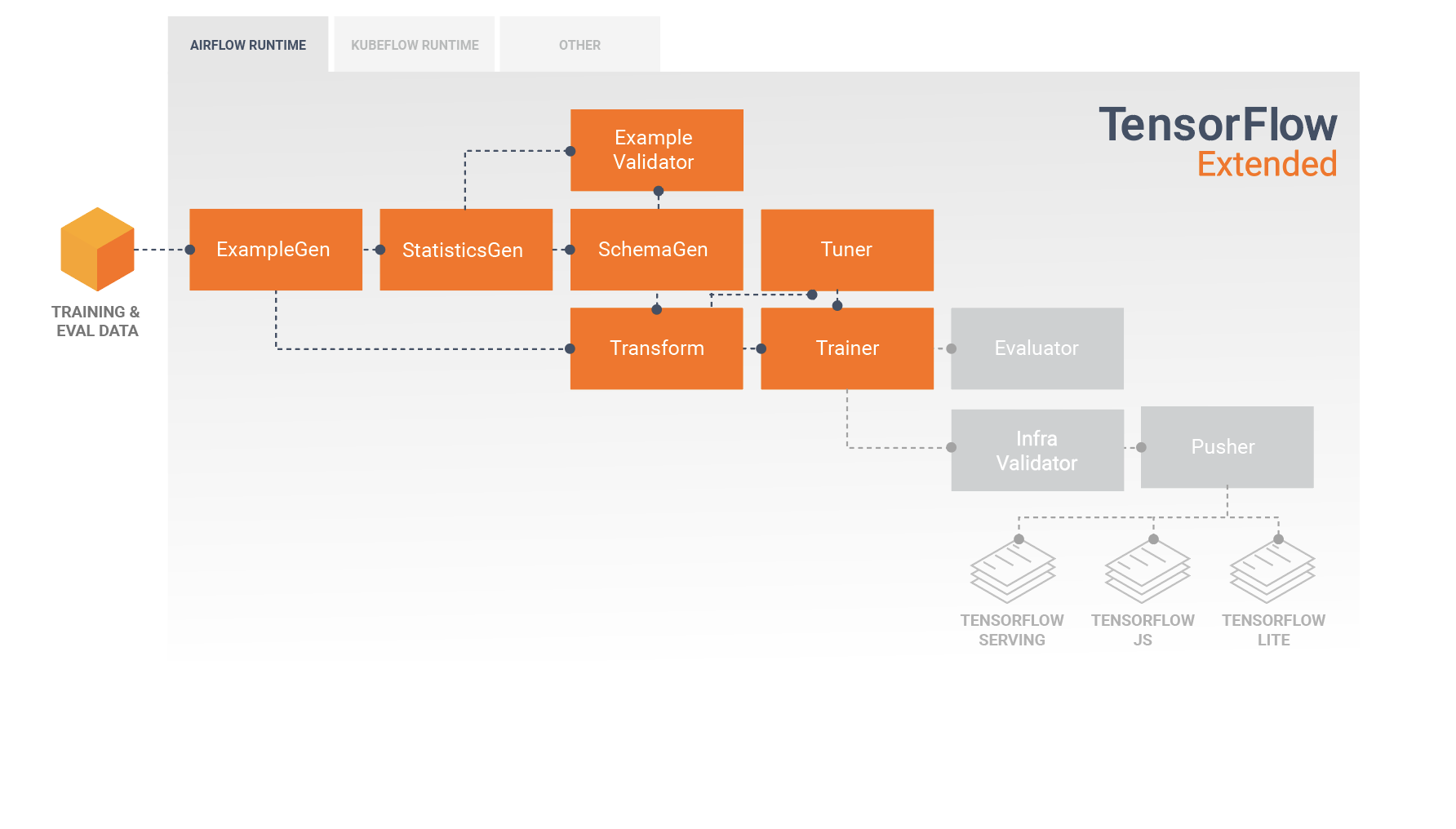
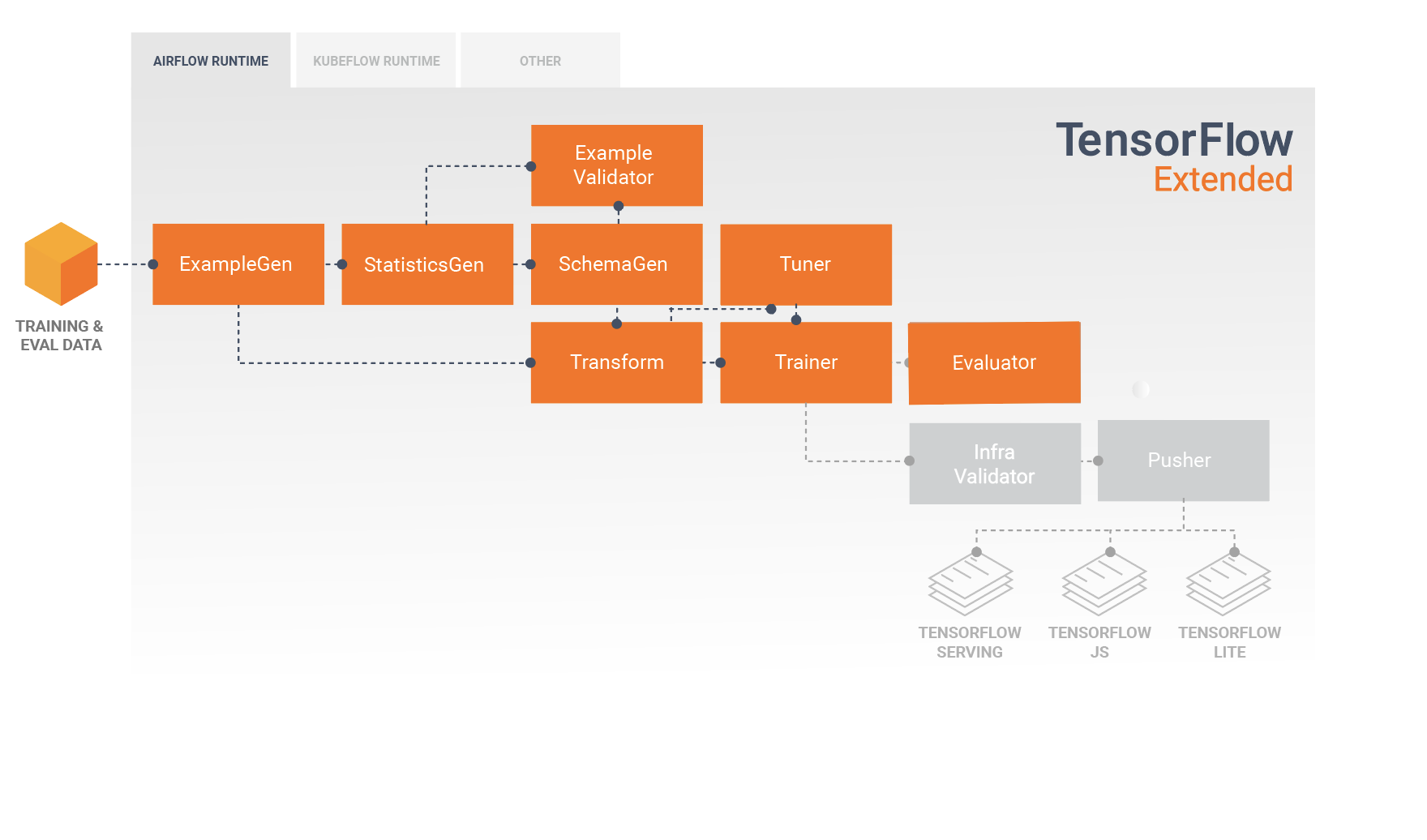
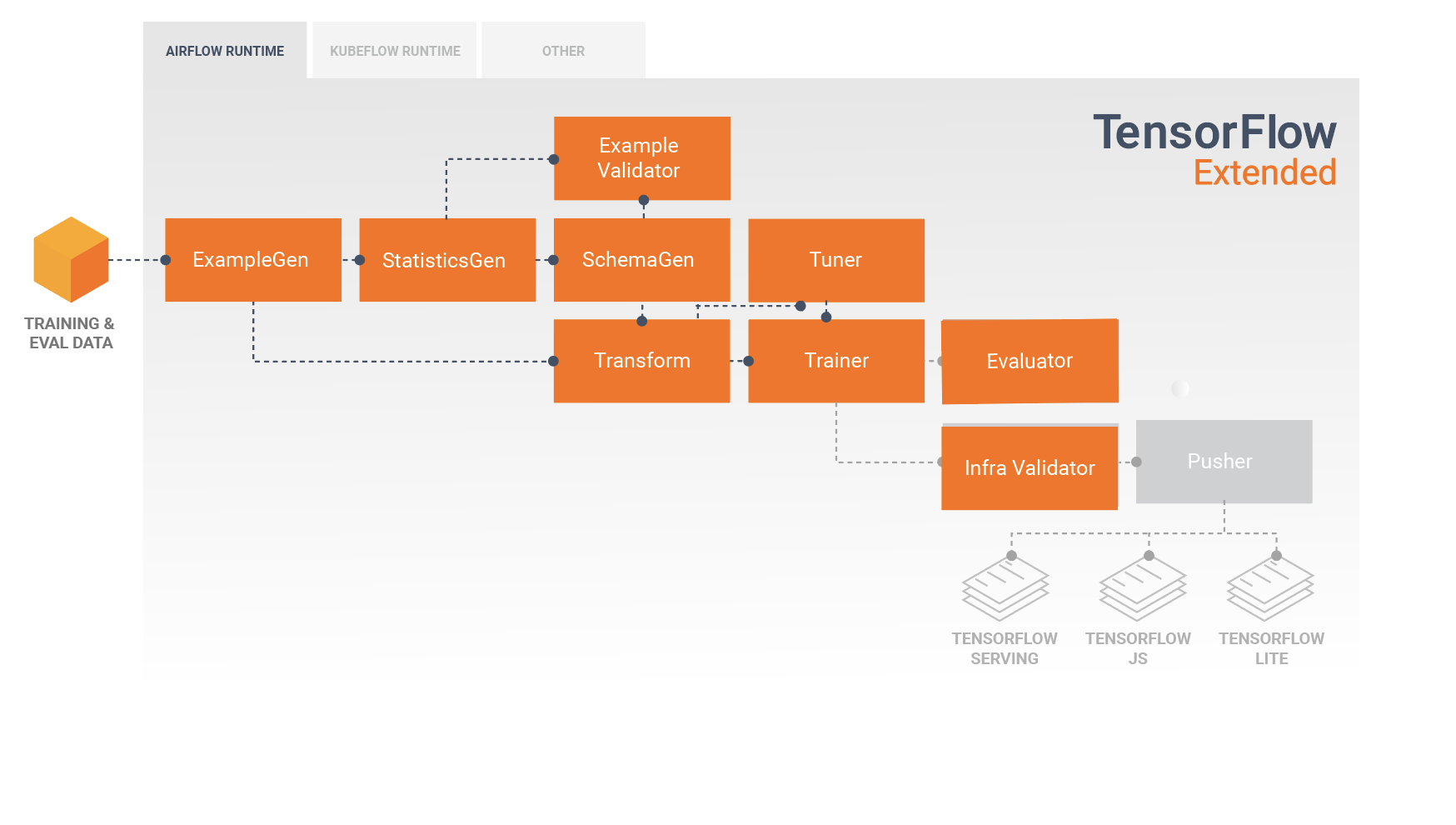
Конвейер TFX — это последовательность компонентов, реализующих конвейер машинного обучения , специально разработанный для масштабируемых и высокопроизводительных задач машинного обучения. Это включает в себя моделирование, обучение, предоставление логических выводов и управление развертыванием в Интернете, нативных мобильных устройствах и объектах JavaScript.
Конвейер TFX обычно включает в себя следующие компоненты:
SampleGen — это начальный входной компонент конвейера, который принимает и при необходимости разделяет входной набор данных.
СтатистикаГен вычисляет статистику для набора данных.
SchemaGen анализирует статистику и создает схему данных.
ПримерВалидатор ищет аномалии и пропущенные значения в наборе данных.
Transform выполняет разработку функций набора данных.
Тренер обучает модель.
Тюнер настраивает гиперпараметры модели.
Evaluator выполняет глубокий анализ результатов обучения и помогает вам проверить экспортированные модели, гарантируя, что они «достаточно хороши» для запуска в производство.
InfraValidator проверяет, действительно ли модель доступна для обслуживания из инфраструктуры, и предотвращает передачу плохой модели.
Pusher развертывает модель в обслуживающей инфраструктуре.
BulkInferrer выполняет пакетную обработку модели с немаркированными запросами вывода.
Эта диаграмма иллюстрирует поток данных между этими компонентами:
Библиотеки TFX
TFX включает в себя как библиотеки, так и компоненты конвейера. Эта диаграмма иллюстрирует взаимосвязь между библиотеками TFX и компонентами конвейера:
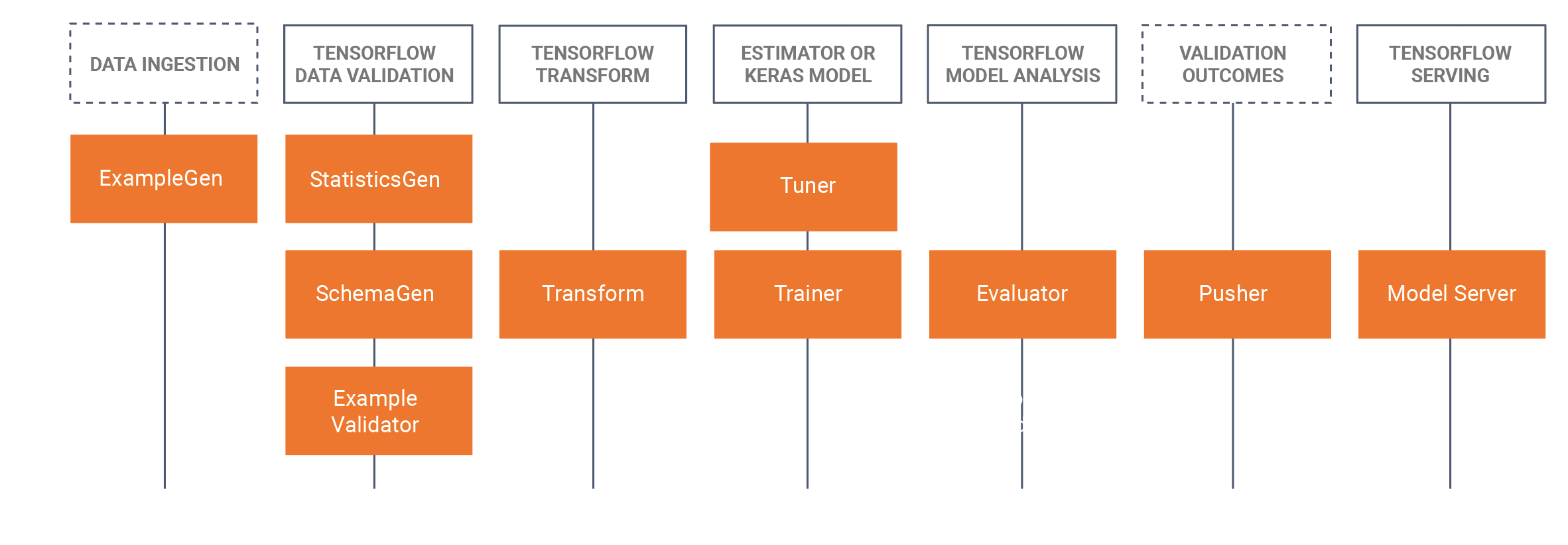
TFX предоставляет несколько пакетов Python, которые представляют собой библиотеки, используемые для создания компонентов конвейера. Вы будете использовать эти библиотеки для создания компонентов ваших конвейеров, чтобы ваш код мог сосредоточиться на уникальных аспектах вашего конвейера.
Библиотеки TFX включают:
TensorFlow Data Validation (TFDV) — это библиотека для анализа и проверки данных машинного обучения. Он разработан с учетом высокой масштабируемости и хорошей работы с TensorFlow и TFX. ТФДВ включает в себя:
- Масштабируемый расчет сводной статистики тренировок и тестовых данных.
- Интеграция со средством просмотра распределений данных и статистики, а также фасетное сравнение пар наборов данных (Facets).
- Автоматизированное создание схемы данных для описания ожиданий относительно данных, таких как требуемые значения, диапазоны и словари.
- Средство просмотра схемы, которое поможет вам проверить схему.
- Обнаружение аномалий для выявления аномалий, таких как отсутствующие объекты, значения, выходящие за пределы допустимого диапазона, или неправильные типы объектов и т. д.
- Средство просмотра аномалий, позволяющее увидеть, в каких функциях есть аномалии, и узнать больше, чтобы их исправить.
TensorFlow Transform (TFT) — это библиотека для предварительной обработки данных с помощью TensorFlow. TensorFlow Transform полезен для данных, требующих полного прохода, например:
- Нормализуйте входное значение по среднему и стандартному отклонению.
- Преобразуйте строки в целые числа, создав словарь для всех входных значений.
- Преобразуйте числа с плавающей запятой в целые числа, назначив их сегментам на основе наблюдаемого распределения данных.
TensorFlow используется для обучения моделей с помощью TFX. Он принимает данные обучения и код моделирования и создает результат SavedModel. Он также интегрирует конвейер разработки функций, созданный TensorFlow Transform для предварительной обработки входных данных.
KerasTuner используется для настройки гиперпараметров модели.
TensorFlow Model Analysis (TFMA) — это библиотека для оценки моделей TensorFlow. Он используется вместе с TensorFlow для создания EvalSavedModel, которая становится основой для ее анализа. Это позволяет пользователям оценивать свои модели на больших объемах данных распределенным образом, используя те же метрики, которые определены в их тренере. Эти метрики можно рассчитать на основе различных фрагментов данных и визуализировать в блокнотах Jupyter.
Метаданные TensorFlow (TFMD) предоставляют стандартные представления метаданных, которые полезны при обучении моделей машинного обучения с помощью TensorFlow. Метаданные могут создаваться вручную или автоматически во время анализа входных данных и могут использоваться для проверки, исследования и преобразования данных. Форматы сериализации метаданных включают в себя:
- Схема, описывающая табличные данные (например, tf.Examples).
- Сбор сводной статистики по таким наборам данных.
Метаданные ML (MLMD) — это библиотека для записи и извлечения метаданных, связанных с рабочими процессами разработчиков ML и специалистов по данным. Чаще всего в метаданных используются представления TFMD. MLMD управляет постоянством с помощью SQL-Lite , MySQL и других подобных хранилищ данных.
Поддержка технологий
Необходимый
- Apache Beam — это унифицированная модель с открытым исходным кодом для определения конвейеров пакетной и потоковой параллельной обработки данных. TFX использует Apache Beam для реализации конвейеров с параллельными данными. Затем конвейер выполняется одним из поддерживаемых Beam серверов распределенной обработки, включая Apache Flink, Apache Spark, Google Cloud Dataflow и другие.
Необязательный
Оркестраторы, такие как Apache Airflow и Kubeflow, упрощают настройку, эксплуатацию, мониторинг и обслуживание конвейера машинного обучения.
Apache Airflow — это платформа для программного создания, планирования и мониторинга рабочих процессов. TFX использует Airflow для создания рабочих процессов в виде направленных ациклических графов (DAG) задач. Планировщик Airflow выполняет задачи над массивом воркеров, следуя указанным зависимостям. Богатые утилиты командной строки позволяют с легкостью выполнять сложные операции с группами DAG. Богатый пользовательский интерфейс позволяет легко визуализировать рабочие конвейеры, отслеживать ход выполнения и устранять проблемы, когда это необходимо. Когда рабочие процессы определяются как код, они становятся более удобными для сопровождения, версионирования, тестирования и совместной работы.
Kubeflow стремится сделать развертывание рабочих процессов машинного обучения (ML) в Kubernetes простым, портативным и масштабируемым. Цель Kubeflow — не воссоздать другие сервисы, а предоставить простой способ развертывания лучших в своем классе систем с открытым исходным кодом для машинного обучения в различных инфраструктурах. Kubeflow Pipelines позволяет создавать и выполнять воспроизводимые рабочие процессы в Kubeflow, интегрированные с экспериментами и опытом на основе блокнотов. Службы Kubeflow Pipelines в Kubernetes включают размещенное хранилище метаданных, механизм оркестрации на основе контейнеров, сервер ноутбуков и пользовательский интерфейс, которые помогают пользователям разрабатывать, запускать и управлять сложными конвейерами машинного обучения в любом масштабе. SDK Kubeflow Pipelines позволяет программно создавать и совместно использовать компоненты и состав конвейеров.
Портативность и совместимость
TFX предназначен для переносимости в различные среды и платформы оркестрации, включая Apache Airflow , Apache Beam и Kubeflow . Его также можно переносить на различные вычислительные платформы, в том числе локальные, и облачные платформы, такие как Google Cloud Platform (GCP) . В частности, TFX взаимодействует с серверными управляемыми сервисами GCP, такими как Cloud AI Platform для обучения и прогнозирования и Cloud Dataflow для распределенной обработки данных для некоторых других аспектов жизненного цикла машинного обучения.
Модель против сохраненной модели
Модель
Модель — это результат процесса обучения. Это сериализованная запись весов, полученных в ходе тренировочного процесса. Эти веса впоследствии можно использовать для вычисления прогнозов для новых входных примеров. Для TFX и TensorFlow «модель» относится к контрольным точкам, содержащим веса, полученные до этой точки.
Обратите внимание, что «модель» может также относиться к определению графа вычислений TensorFlow (т. е. файла Python), который выражает, как будет вычисляться прогноз. Эти два чувства могут использоваться взаимозаменяемо в зависимости от контекста.
Сохраненнаямодель
- Что такое SavedModel : универсальная, нейтральная к языку, герметичная, восстанавливаемая сериализация модели TensorFlow.
- Почему это важно : это позволяет системам более высокого уровня создавать, преобразовывать и использовать модели TensorFlow, используя единую абстракцию.
SavedModel — это рекомендуемый формат сериализации для обслуживания модели TensorFlow в рабочей среде или экспорта обученной модели в собственное мобильное приложение или приложение JavaScript. Например, чтобы превратить модель в службу REST для прогнозирования, вы можете сериализовать модель как SavedModel и обслуживать ее с помощью TensorFlow Serving. Дополнительную информацию см. в разделе Обслуживание модели TensorFlow .
Схема
Некоторые компоненты TFX используют описание входных данных, называемое схемой . Схема является экземпляром Schema.proto . Схемы — это тип буфера протокола , более известный как «protobuf». В схеме можно указать типы данных для значений признаков, должен ли признак присутствовать во всех примерах, допустимые диапазоны значений и другие свойства. Одним из преимуществ использования проверки данных TensorFlow (TFDV) является то, что она автоматически генерирует схему, выявляя типы, категории и диапазоны на основе обучающих данных.
Вот выдержка из схемы protobuf:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Следующие компоненты используют схему:
- Проверка данных TensorFlow
- Преобразование TensorFlow
В типичном конвейере TFX проверка данных TensorFlow генерирует схему, которая используется другими компонентами.
Разработка с TFX
TFX предоставляет мощную платформу для каждого этапа проекта машинного обучения: от исследований, экспериментов и разработок на локальном компьютере до развертывания. Чтобы избежать дублирования кода и исключить возможность неравномерности обучения/обслуживания, настоятельно рекомендуется реализовать конвейер TFX как для обучения моделей, так и для развертывания обученных моделей, а также использовать компоненты Transform , которые используют библиотеку TensorFlow Transform как для обучения, так и для вывода. Поступая таким образом, вы будете последовательно использовать один и тот же код предварительной обработки и анализа и избегать различий между данными, используемыми для обучения, и данными, передаваемыми в ваши обученные модели в рабочей среде, а также получите выгоду от написания этого кода один раз.
Исследование, визуализация и очистка данных
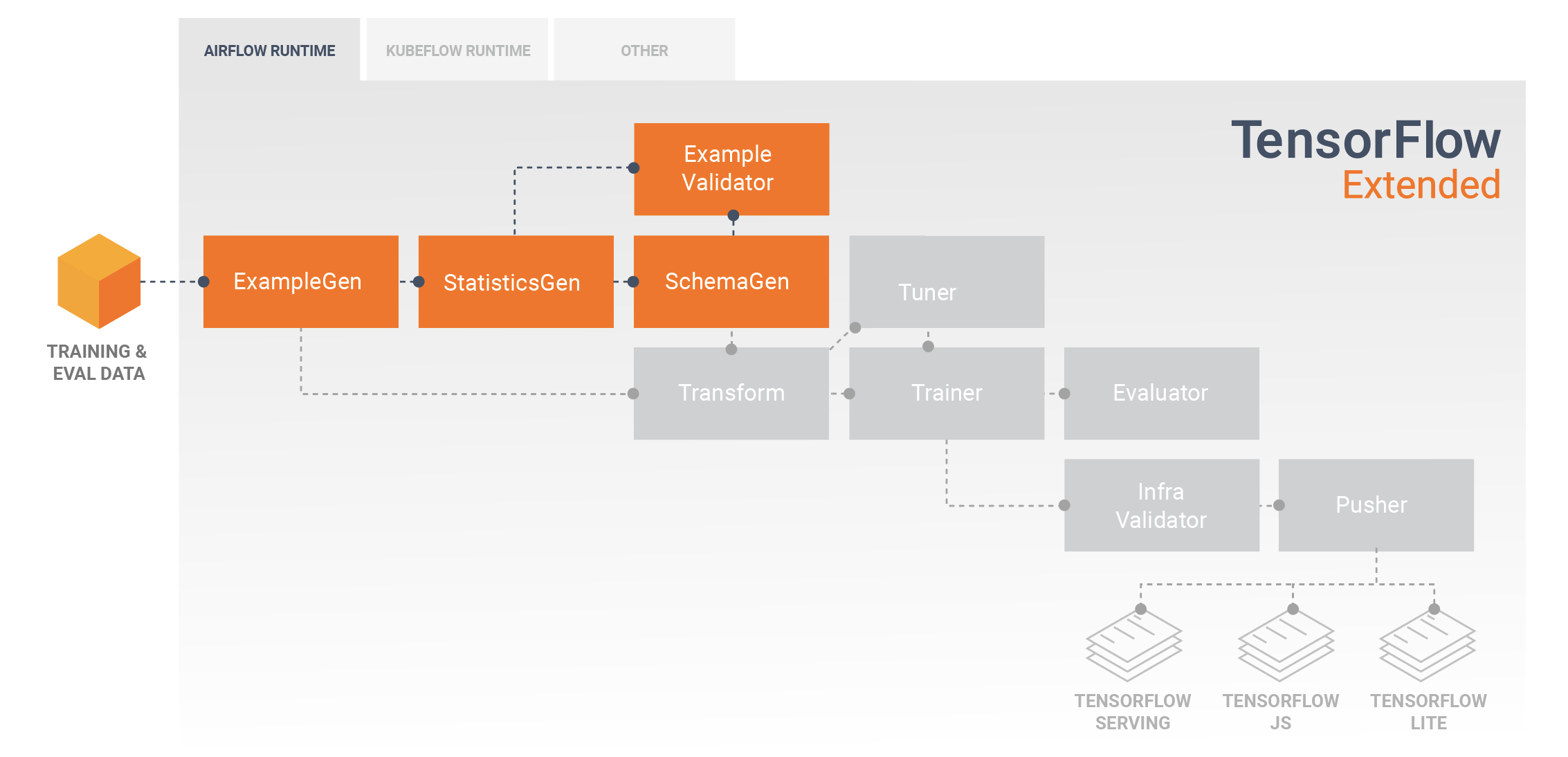
Конвейеры TFX обычно начинаются с компонента SampleGen , который принимает входные данные и форматирует их как tf.Examples. Часто это делается после того, как данные были разделены на наборы обучающих и оценочных данных, так что фактически существует две копии компонентов SampleGen, по одной для обучения и оценки. Обычно за этим следуют компонент СтатистикаGen и компонент SchemaGen , которые проверят ваши данные и выведут схему данных и статистику. Схема и статистика будут использоваться компонентом SampleValidator , который будет искать аномалии, пропущенные значения и неверные типы данных в ваших данных. Все эти компоненты используют возможности библиотеки проверки данных TensorFlow .
Проверка данных TensorFlow (TFDV) — ценный инструмент при первоначальном исследовании, визуализации и очистке набора данных. TFDV проверяет ваши данные и определяет типы, категории и диапазоны данных, а затем автоматически помогает выявить аномалии и пропущенные значения. Он также предоставляет инструменты визуализации, которые помогут вам изучить и понять ваш набор данных. После завершения конвейера вы можете прочитать метаданные из MLMD и использовать инструменты визуализации TFDV в блокноте Jupyter для анализа данных.
После первоначального обучения и развертывания модели TFDV можно использовать для мониторинга новых данных из запросов на вывод к развернутым моделям и поиска аномалий и/или отклонений. Это особенно полезно для данных временных рядов, которые меняются со временем в результате тренда или сезонности, и может помочь сообщить, когда возникают проблемы с данными или когда модели необходимо переобучить на новых данных.
Визуализация данных
После того как вы завершили первый прогон данных через раздел конвейера, использующий TFDV (обычноStatisticGen, SchemaGen и exampleValidator), вы можете визуализировать результаты в блокноте в стиле Jupyter. При дополнительных запусках вы можете сравнивать эти результаты по мере внесения корректировок, пока ваши данные не станут оптимальными для вашей модели и приложения.
Сначала вы запросите метаданные ML (MLMD) , чтобы найти результаты выполнения этих компонентов, а затем используете API поддержки визуализации в TFDV для создания визуализаций в своем блокноте. Сюда входят tfdv.load_statistics() и tfdv.visualize_statistics(). Используя эту визуализацию, вы сможете лучше понять характеристики вашего набора данных и при необходимости изменить их по мере необходимости.
Разработка и обучение моделей
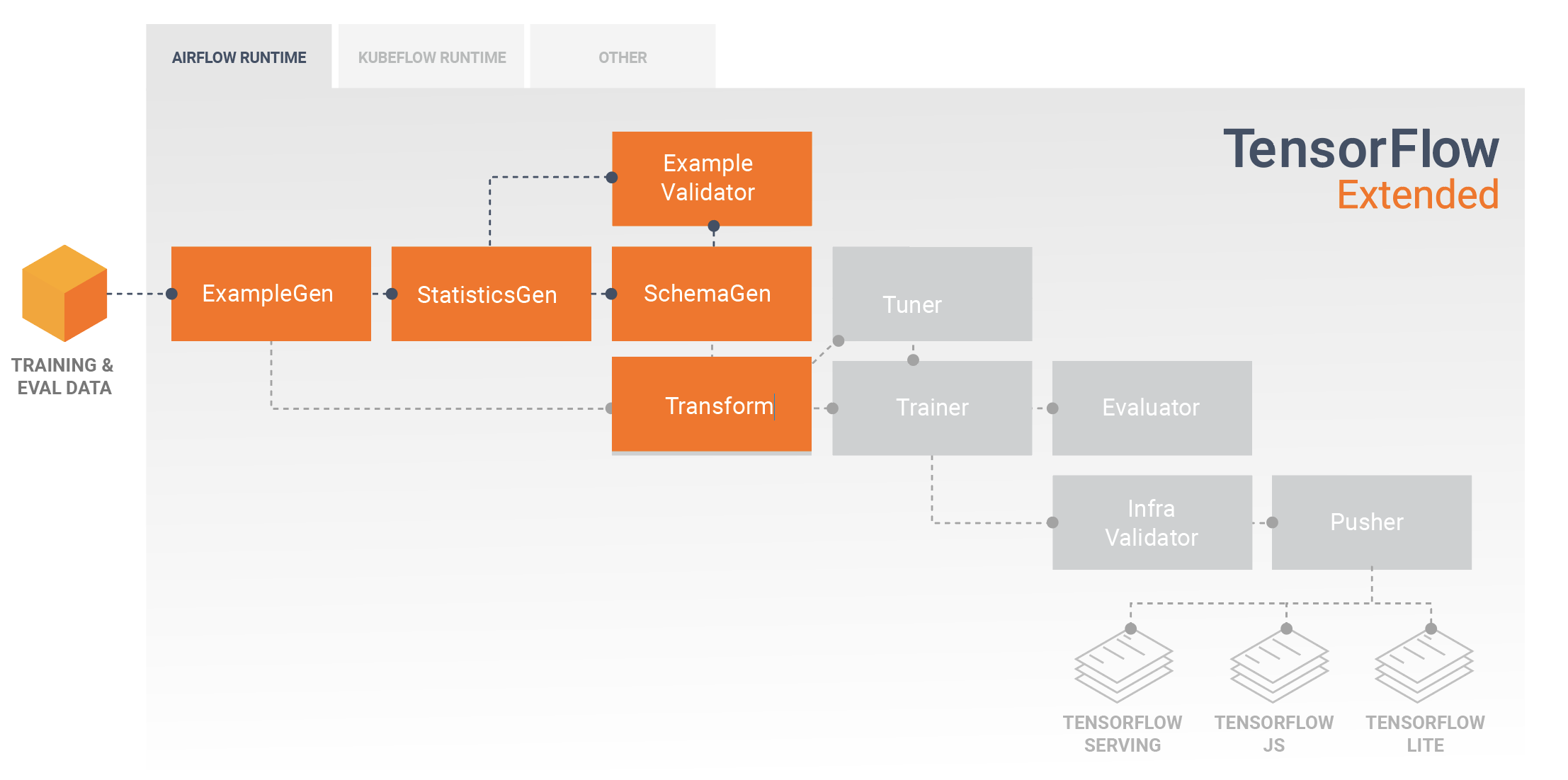
Типичный конвейер TFX будет включать компонент Transform , который будет выполнять разработку функций, используя возможности библиотеки TensorFlow Transform (TFT) . Компонент Transform использует схему, созданную компонентом SchemaGen, и применяет преобразования данных для создания, объединения и преобразования функций, которые будут использоваться для обучения вашей модели. Очистку отсутствующих значений и преобразование типов также следует выполнять в компоненте Transform, если существует вероятность того, что они также будут присутствовать в данных, отправленных для запросов на вывод. При разработке кода TensorFlow для обучения TFX необходимо учитывать некоторые важные соображения .
Результатом работы компонента Transform является SavedModel, который будет импортирован и использован в вашем коде моделирования в TensorFlow во время компонента Trainer . Эта SavedModel включает в себя все преобразования обработки данных, созданные в компоненте Transform, поэтому идентичные преобразования выполняются с использованием одного и того же кода как во время обучения, так и в процессе вывода. Используя код моделирования, включая SavedModel из компонента Transform, вы можете использовать данные обучения и оценки и обучать свою модель.
При работе с моделями на основе Estimator последний раздел вашего кода моделирования должен сохранить вашу модель как SavedModel, так и EvalSavedModel. Сохранение в виде EvalSavedModel гарантирует, что метрики, используемые во время обучения, также будут доступны во время оценки (обратите внимание, что это не требуется для моделей на основе keras). Для сохранения EvalSavedModel необходимо импортировать библиотеку анализа модели TensorFlow (TFMA) в ваш компонент Trainer.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Перед Trainer можно добавить дополнительный компонент Tuner для настройки гиперпараметров (например, количества слоев) модели. Используя данную модель и пространство поиска гиперпараметров, алгоритм настройки найдет лучшие гиперпараметры в зависимости от цели.
Анализ и понимание производительности модели
После первоначальной разработки и обучения модели важно проанализировать и по-настоящему понять ее эффективность. Типичный конвейер TFX будет включать компонент Evaluator , который использует возможности библиотеки анализа модели TensorFlow (TFMA) , которая предоставляет мощный набор инструментов для этого этапа разработки. Компонент Evaluator использует экспортированную выше модель и позволяет указать список tfma.SlicingSpec , который можно использовать при визуализации и анализе производительности вашей модели. Каждая SlicingSpec определяет фрагмент ваших обучающих данных, который вы хотите изучить, например определенные категории для категориальных признаков или определенные диапазоны для числовых признаков.
Например, это может быть важно для того, чтобы попытаться понять эффективность вашей модели для различных сегментов ваших клиентов, которые могут быть сегментированы по годовым покупкам, географическим данным, возрастной группе или полу. Это может быть особенно важно для наборов данных с длинными хвостами, где показатели доминирующей группы могут маскировать неприемлемые результаты для важных, но более мелких групп. Например, ваша модель может хорошо работать для рядовых сотрудников, но совершенно неэффективна для руководителей, и вам может быть важно это знать.
Модельный анализ и визуализация
После того как вы завершили первый прогон данных путем обучения модели и запуска компонента Evaluator (который использует TFMA ) на результатах обучения, вы можете визуализировать результаты в блокноте в стиле Jupyter. При дополнительных запусках вы можете сравнивать эти результаты по мере внесения корректировок, пока результаты не станут оптимальными для вашей модели и приложения.
Сначала вы запросите метаданные ML (MLMD) , чтобы найти результаты выполнения этих компонентов, а затем используете API поддержки визуализации в TFMA для создания визуализаций в своем блокноте. Сюда входят tfma.load_eval_results и tfma.view.render_slicing_metrics. Используя эту визуализацию, вы можете лучше понять характеристики вашей модели и при необходимости изменить ее по мере необходимости.
Проверка производительности модели
В рамках анализа производительности модели вы можете проверить производительность по сравнению с базовым уровнем (например, с текущей обслуживаемой моделью). Проверка модели выполняется путем передачи как кандидатской, так и базовой модели компоненту Evaluator . Оценщик вычисляет показатели (например, AUC, потери) как для кандидата, так и для базового уровня вместе с соответствующим набором показателей различий. Затем можно применить пороговые значения и использовать их для запуска ваших моделей в производство.
Проверка возможности обслуживания модели
Перед развертыванием обученной модели вы можете проверить, действительно ли модель пригодна для обслуживания в обслуживающей инфраструктуре. Это особенно важно в производственных средах, чтобы гарантировать, что недавно опубликованная модель не помешает системе предоставлять прогнозы. Компонент InfraValidator выполнит канареечное развертывание вашей модели в изолированной среде и, при необходимости, отправит реальные запросы для проверки правильности работы вашей модели.
Цели развертывания
После того как вы разработали и обучили модель, которая вас устраивает, пришло время развернуть ее в одной или нескольких целях развертывания, где она будет получать запросы на логический вывод. TFX поддерживает развертывание в трех классах целей развертывания. Обученные модели, экспортированные как SavedModels, можно развернуть в любой или во всех этих целях развертывания.
Вывод: обслуживание TensorFlow
TensorFlow Serving (TFS) — это гибкая и высокопроизводительная система обслуживания моделей машинного обучения, предназначенная для производственных сред. Он использует SavedModel и будет принимать запросы на вывод через интерфейсы REST или gRPC. Он выполняется как набор процессов на одном или нескольких сетевых серверах, используя одну из нескольких передовых архитектур для синхронизации и распределенных вычислений. Дополнительную информацию о разработке и развертывании решений TFS см. в документации TFS .
В типичном конвейере SavedModel, обученная в компоненте Trainer , сначала должна пройти инфраструктурную проверку в компоненте InfraValidator . InfraValidator запускает канареечный сервер модели TFS для фактического обслуживания SavedModel. Если проверка прошла успешно, компонент Pusher наконец развернет SavedModel в вашей инфраструктуре TFS. Это включает в себя обработку нескольких версий и обновлений модели.
Вывод в собственных мобильных приложениях и приложениях Интернета вещей: TensorFlow Lite
TensorFlow Lite — это набор инструментов, который помогает разработчикам использовать обученные модели TensorFlow в собственных мобильных приложениях и приложениях IoT. Он использует те же модели SavedModels, что и TensorFlow Serving, и применяет такие оптимизации, как квантование и сокращение, чтобы оптимизировать размер и производительность полученных моделей для решения задач работы на мобильных устройствах и устройствах IoT. Дополнительную информацию об использовании TensorFlow Lite см. в документации TensorFlow Lite.
Вывод в JavaScript: TensorFlow JS
TensorFlow JS — это библиотека JavaScript для обучения и развертывания моделей машинного обучения в браузере и на Node.js. Он использует те же модели SavedModels, что и TensorFlow Serving и TensorFlow Lite, и преобразует их в веб-формат TensorFlow.js. Дополнительную информацию об использовании TensorFlow JS см. в документации TensorFlow JS.
Создание конвейера TFX с помощью Airflow
Подробности можно узнать в мастерской воздушного потока.
Создание конвейера TFX с помощью Kubeflow
Настраивать
Kubeflow требует кластера Kubernetes для запуска конвейеров в нужном масштабе. См. руководство по развертыванию Kubeflow, в котором описаны варианты развертывания кластера Kubeflow.
Настройте и запустите конвейер TFX
Пожалуйста, следуйте руководству TFX on Cloud AI Platform Pipeline, чтобы запустить пример конвейера TFX в Kubeflow. Компоненты TFX были помещены в контейнеры для создания конвейера Kubeflow, и пример иллюстрирует возможность настройки конвейера для чтения большого общедоступного набора данных и выполнения этапов обучения и обработки данных в облаке в любом масштабе.
Интерфейс командной строки для действий конвейера
TFX предоставляет унифицированный интерфейс командной строки, который помогает выполнять полный спектр действий с конвейерами, таких как создание, обновление, запуск, составление списка и удаление конвейеров в различных оркестраторах, включая Apache Airflow, Apache Beam и Kubeflow. Для получения подробной информации, пожалуйста, следуйте этим инструкциям .