
Wstęp
TFX to platforma uczenia maszynowego (ML) na skalę produkcyjną Google, oparta na TensorFlow. Zapewnia platformę konfiguracyjną i współdzielone biblioteki do integracji typowych komponentów potrzebnych do definiowania, uruchamiania i monitorowania systemu uczenia maszynowego.
TFX 1.0
Z przyjemnością ogłaszamy dostępność TFX 1.0.0 . Jest to pierwsza wersja TFX po wersji beta, która zapewnia stabilne publiczne interfejsy API i artefakty. Możesz być pewien, że Twoje przyszłe potoki TFX będą nadal działać po aktualizacji w zakresie zgodności określonym w tym dokumencie RFC .
Instalacja

![]()
pip install tfx
Pakiety nocne
TFX obsługuje również pakiety nocne pod adresem https://pypi-nightly.tensorflow.org w Google Cloud. Aby zainstalować najnowszy pakiet nightly, użyj następującego polecenia:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Spowoduje to zainstalowanie pakietów nocnych dla głównych zależności TFX, takich jak analiza modelu TensorFlow (TFMA), sprawdzanie poprawności danych TensorFlow (TFDV), transformacja TensorFlow (TFT), podstawowe biblioteki współdzielone TFX (TFX-BSL), metadane ML (MLMD).
O TFX-ie
TFX to platforma do budowania i zarządzania przepływami pracy ML w środowisku produkcyjnym. TFX zapewnia co następuje:
Zestaw narzędzi do tworzenia potoków uczenia maszynowego. Potoki TFX umożliwiają orkiestrację przepływu pracy ML na kilku platformach, takich jak: Apache Airflow, Apache Beam i Kubeflow Pipelines.
Zestaw standardowych komponentów, których można używać jako części potoku lub jako części skryptu szkoleniowego ML. Standardowe komponenty TFX zapewniają sprawdzoną funkcjonalność, która pomaga łatwo rozpocząć budowanie procesu ML.
Biblioteki zapewniające podstawową funkcjonalność wielu standardowych komponentów. Możesz użyć bibliotek TFX, aby dodać tę funkcjonalność do własnych komponentów niestandardowych lub użyć ich osobno.
TFX to zestaw narzędzi Google do uczenia maszynowego na skalę produkcyjną oparty na TensorFlow. Zapewnia platformę konfiguracyjną i współdzielone biblioteki do integracji typowych komponentów potrzebnych do definiowania, uruchamiania i monitorowania systemu uczenia maszynowego.
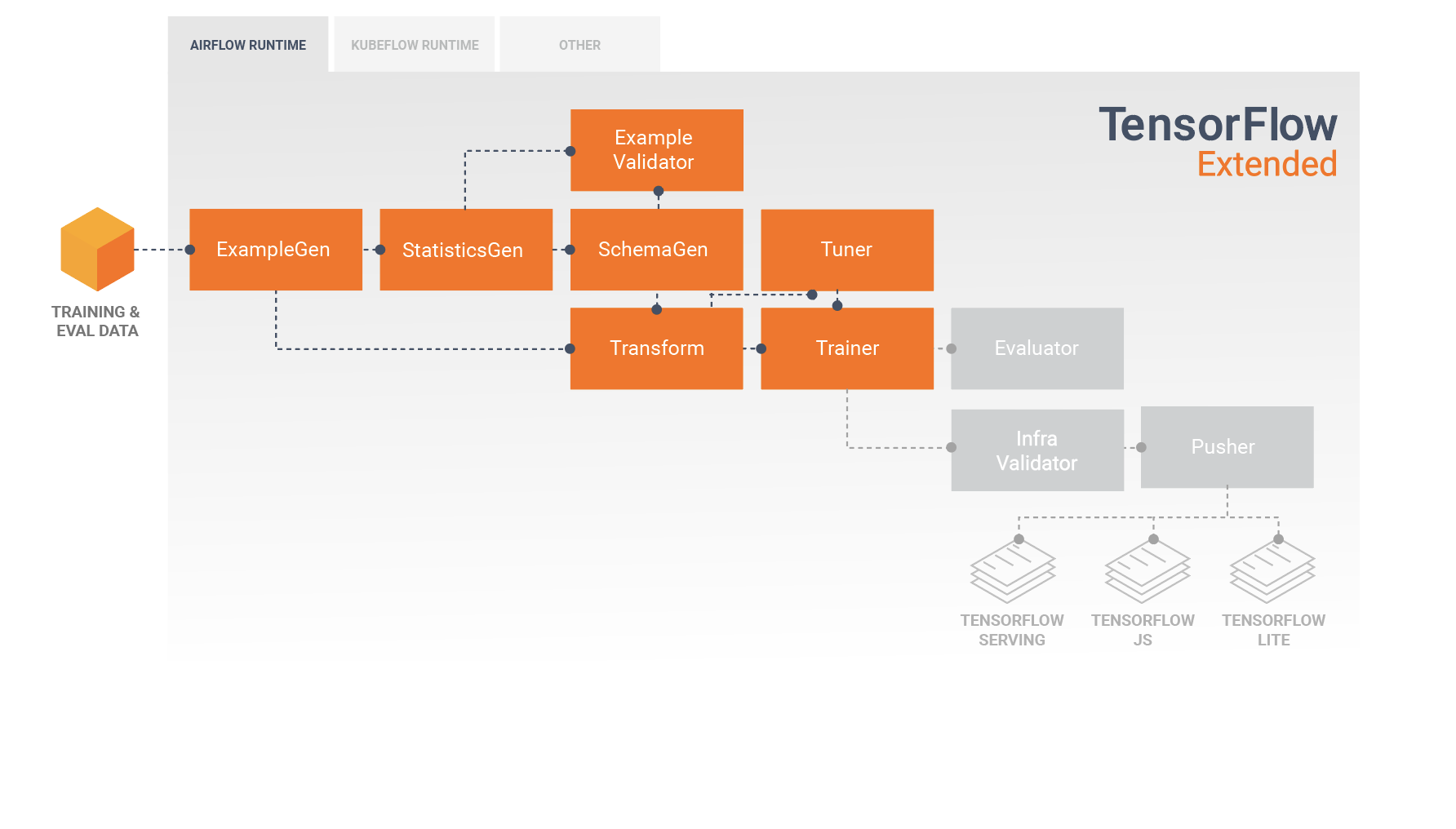
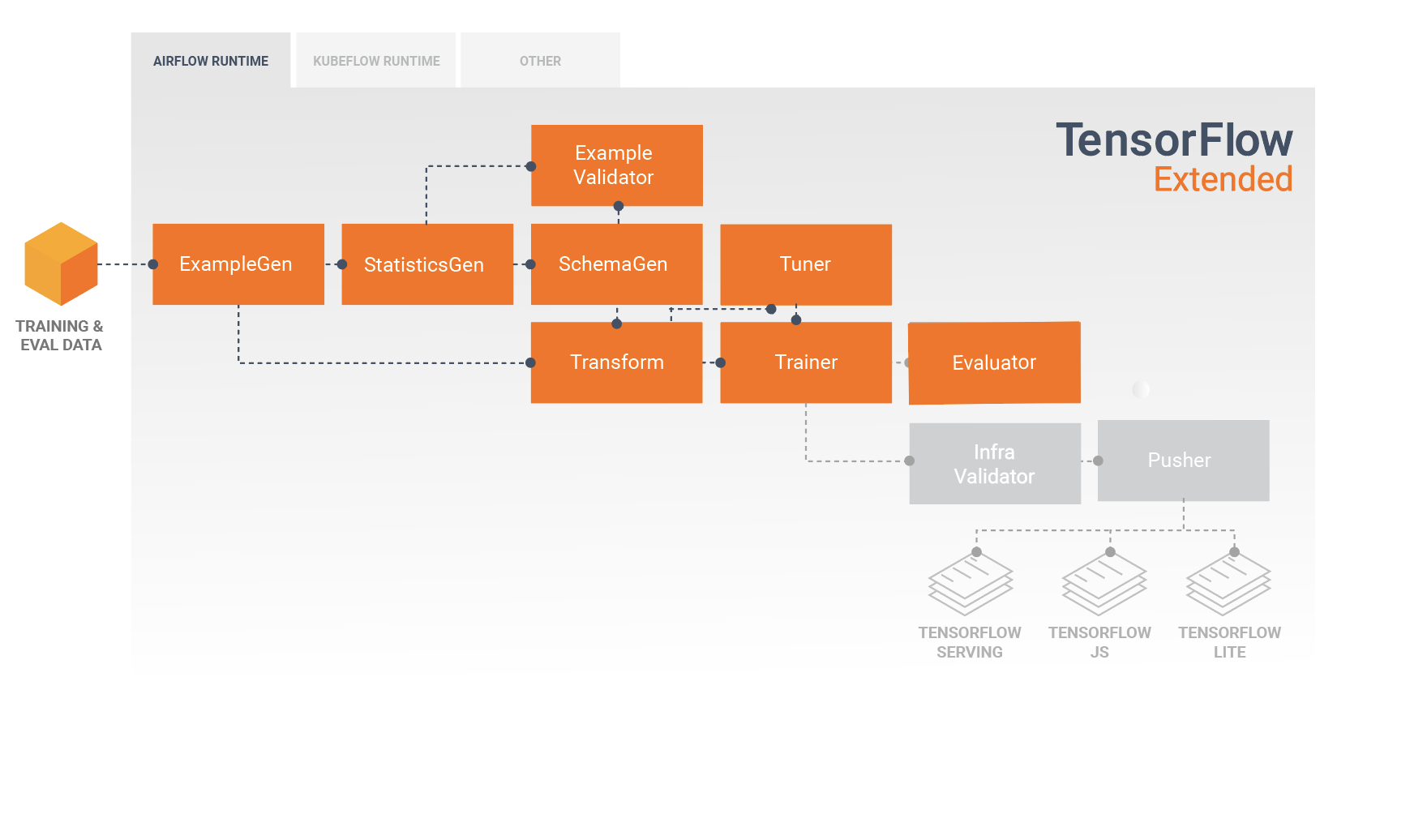
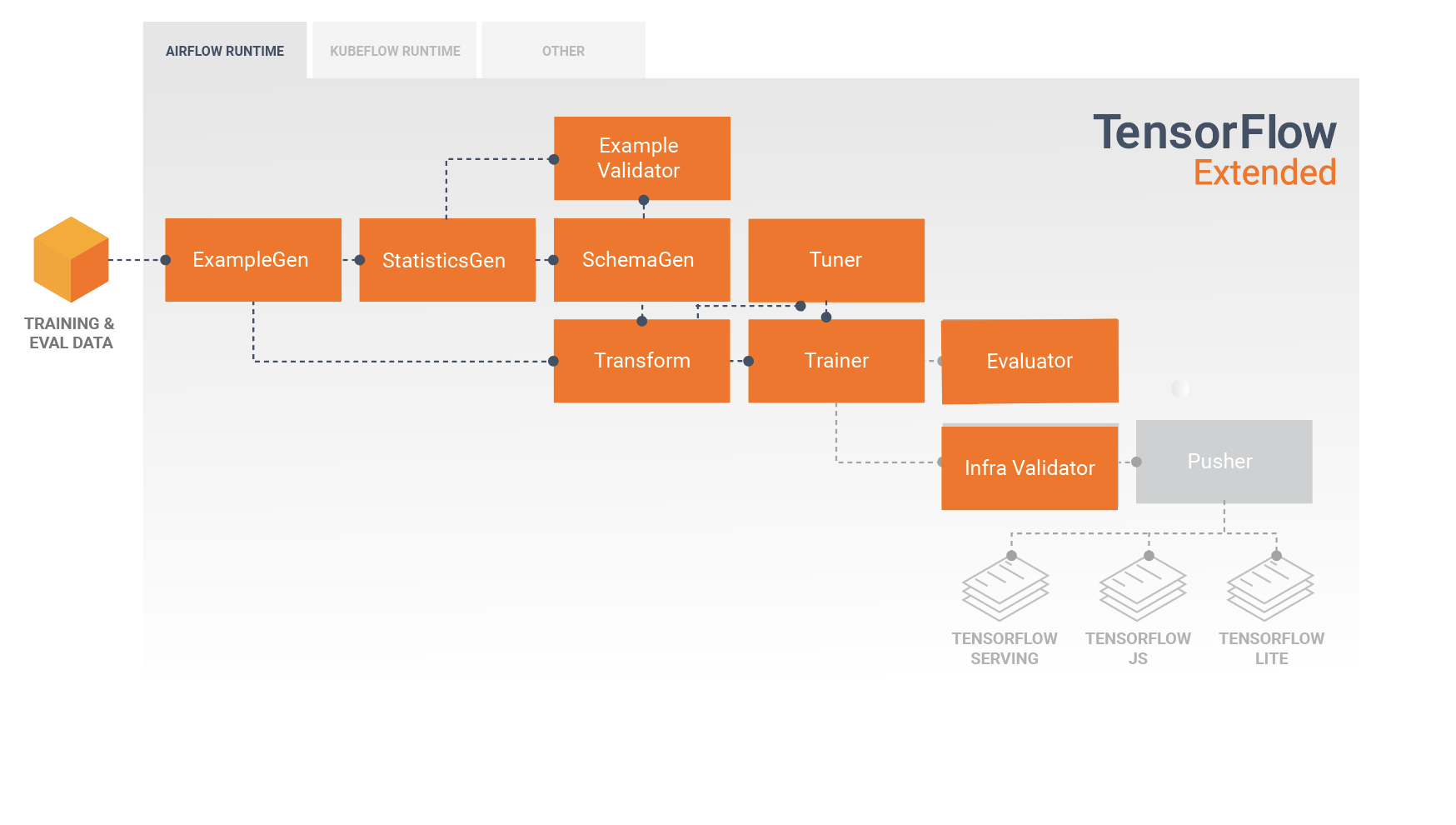
Standardowe komponenty TFX
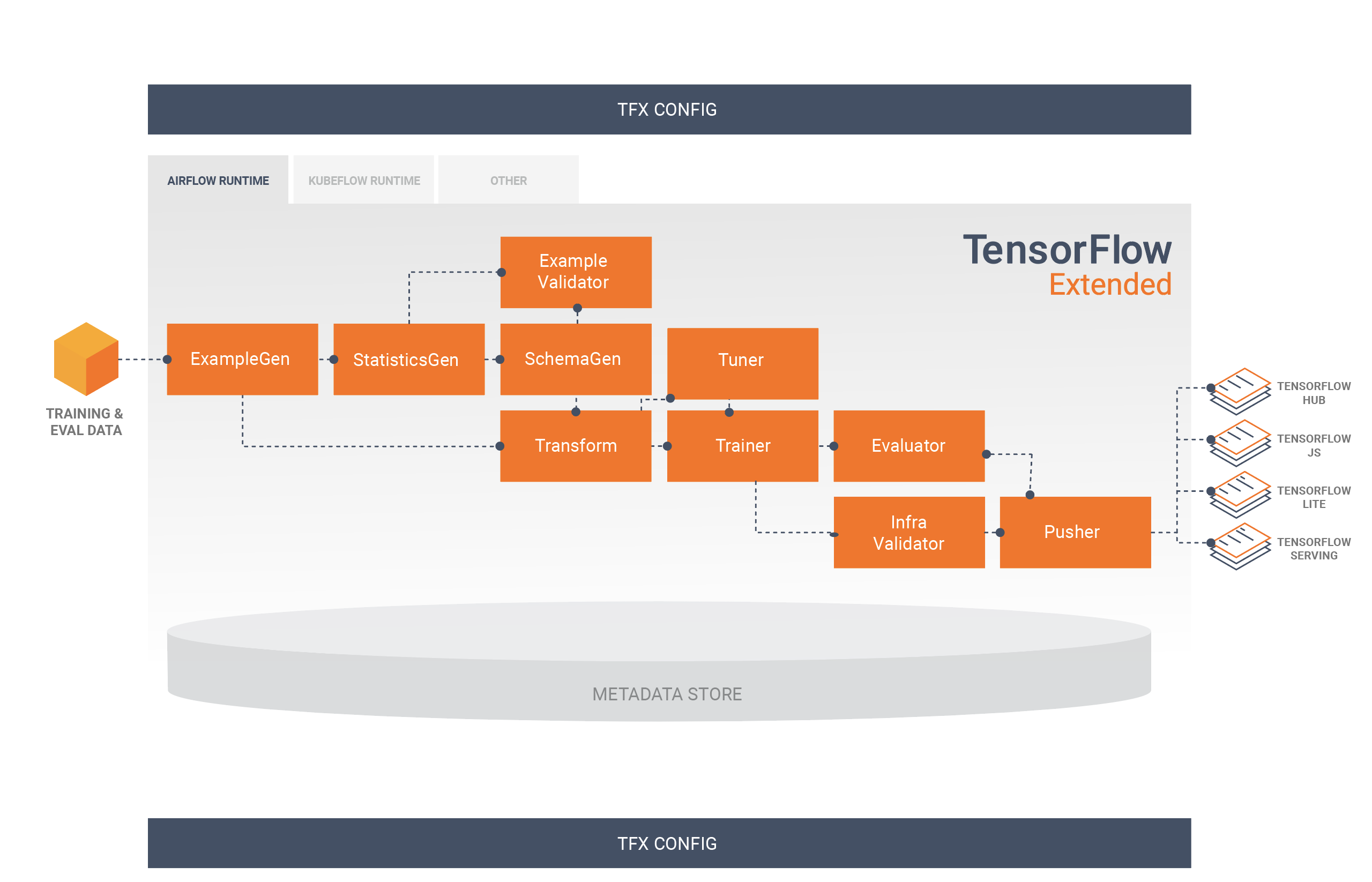
Potok TFX to sekwencja komponentów implementujących potok ML , który został specjalnie zaprojektowany do skalowalnych i wydajnych zadań uczenia maszynowego. Obejmuje to modelowanie, trenowanie, udostępnianie wnioskowania i zarządzanie wdrożeniami w celach online, natywnych urządzeniach mobilnych i JavaScript.
Potok TFX zazwyczaj zawiera następujące komponenty:
PrzykładGen jest początkowym komponentem wejściowym potoku, który pobiera i opcjonalnie dzieli wejściowy zestaw danych.
StatisticsGen oblicza statystyki dla zbioru danych.
SchemaGen sprawdza statystyki i tworzy schemat danych.
PrzykładValidator wyszukuje anomalie i brakujące wartości w zbiorze danych.
Transform wykonuje inżynierię funkcji na zestawie danych.
Trener trenuje model.
Tuner dostraja hiperparametry modelu.
Narzędzie oceniające przeprowadza głęboką analizę wyników uczenia i pomaga zweryfikować wyeksportowane modele, upewniając się, że są one „wystarczająco dobre”, aby można je było przenieść do produkcji.
InfraValidator sprawdza, czy model rzeczywiście można udostępnić z infrastruktury i zapobiega wypchnięciu złego modelu.
Pusher wdraża model w infrastrukturze obsługującej.
BulkInferrer wykonuje przetwarzanie wsadowe na modelu z żądaniami wnioskowania bez etykiet.
Poniższy diagram ilustruje przepływ danych pomiędzy tymi komponentami:
Biblioteki TFX
TFX zawiera zarówno biblioteki, jak i komponenty potoków. Ten diagram ilustruje relacje między bibliotekami TFX i komponentami potoku:
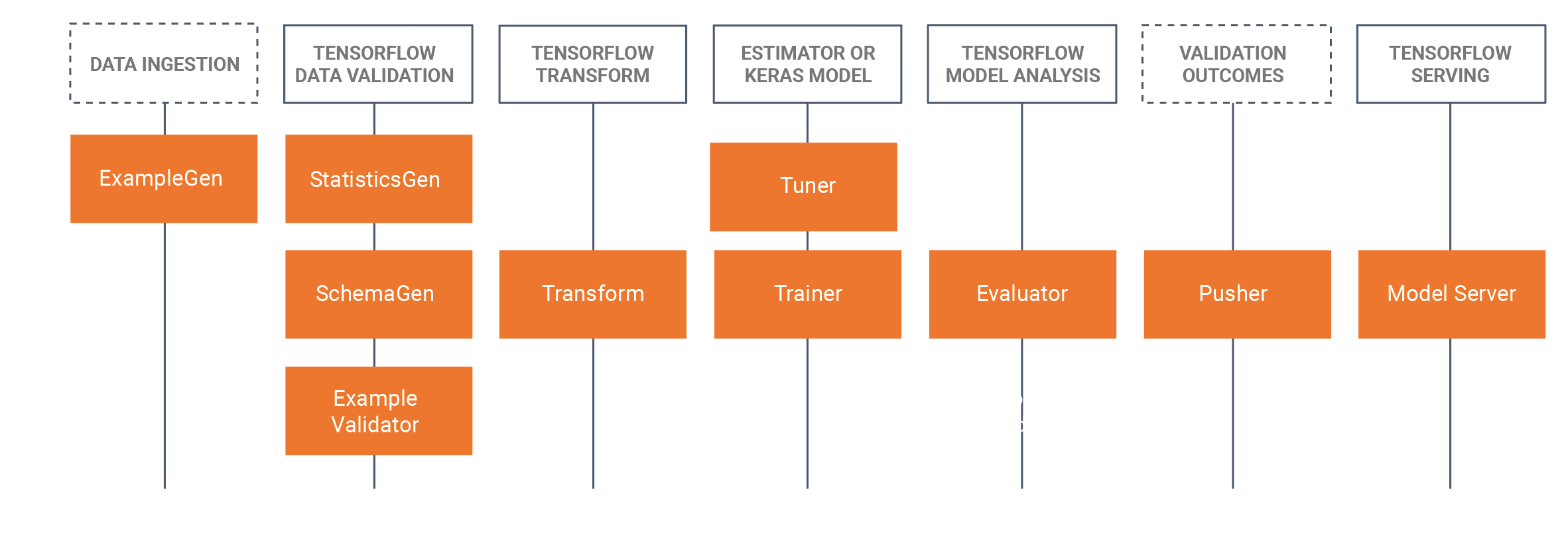
TFX udostępnia kilka pakietów Pythona, które są bibliotekami używanymi do tworzenia komponentów potoku. Będziesz używać tych bibliotek do tworzenia komponentów potoków, dzięki czemu kod będzie mógł skupić się na unikalnych aspektach potoku.
Biblioteki TFX obejmują:
TensorFlow Data Validation (TFDV) to biblioteka do analizowania i sprawdzania poprawności danych uczenia maszynowego. Został zaprojektowany tak, aby był wysoce skalowalny i dobrze współpracował z TensorFlow i TFX. TFDV obejmuje:
- Skalowalne obliczanie statystyk podsumowujących dane treningowe i testowe.
- Integracja z przeglądarką w celu dystrybucji danych i statystyk, a także wieloaspektowego porównywania par zbiorów danych (Facetów).
- Zautomatyzowane generowanie schematów danych w celu opisania oczekiwań dotyczących danych, takich jak wymagane wartości, zakresy i słowniki.
- Przeglądarka schematów, która pomoże Ci sprawdzić schemat.
- Wykrywanie anomalii w celu identyfikacji anomalii, takich jak brakujące funkcje, wartości spoza zakresu lub nieprawidłowe typy funkcji, żeby wymienić tylko kilka.
- Przeglądarka anomalii, dzięki której możesz zobaczyć, które funkcje mają anomalie i dowiedzieć się więcej, aby je poprawić.
TensorFlow Transform (TFT) to biblioteka do wstępnego przetwarzania danych za pomocą TensorFlow. TensorFlow Transform jest przydatny w przypadku danych wymagających pełnego przebiegu, takich jak:
- Normalizuj wartość wejściową za pomocą średniej i odchylenia standardowego.
- Konwertuj ciągi na liczby całkowite, generując słownik dla wszystkich wartości wejściowych.
- Konwertuj liczby zmiennoprzecinkowe na liczby całkowite, przypisując je do segmentów na podstawie zaobserwowanego rozkładu danych.
TensorFlow służy do uczenia modeli za pomocą TFX. Pozyskuje dane szkoleniowe i kod modelowania i tworzy wynik SavedModel. Integruje także potok inżynierii funkcji stworzony przez TensorFlow Transform do wstępnego przetwarzania danych wejściowych.
KerasTuner służy do dostrajania hiperparametrów modelu.
Analiza modelu TensorFlow (TFMA) to biblioteka do oceny modeli TensorFlow. Służy wraz z TensorFlow do tworzenia EvalSavedModel, który staje się podstawą jego analizy. Umożliwia użytkownikom ocenę swoich modeli na dużych ilościach danych w sposób rozproszony, przy użyciu tych samych metryk zdefiniowanych w ich trainerze. Metryki te można obliczać na różnych fragmentach danych i wizualizować w notatnikach Jupyter.
Metadane TensorFlow (TFMD) zapewniają standardowe reprezentacje metadanych, które są przydatne podczas uczenia modeli uczenia maszynowego za pomocą TensorFlow. Metadane mogą być tworzone ręcznie lub automatycznie podczas analizy danych wejściowych i mogą być wykorzystywane do walidacji, eksploracji i transformacji danych. Formaty serializacji metadanych obejmują:
- Schemat opisujący dane tabelaryczne (np. tf.Examples).
- Zbiór statystyk podsumowujących dotyczących takich zbiorów danych.
ML Metadata (MLMD) to biblioteka do rejestrowania i pobierania metadanych powiązanych z przepływami pracy programistów ML i analityków danych. Najczęściej metadane wykorzystują reprezentacje TFMD. MLMD zarządza trwałością przy użyciu SQL-Lite , MySQL i innych podobnych magazynów danych.
Technologie wspierające
Wymagany
- Apache Beam to ujednolicony model typu open source służący do definiowania potoków przetwarzania danych wsadowych i strumieniowych z równoległym przetwarzaniem. TFX używa Apache Beam do implementowania potoków równoległych danych. Potok jest następnie wykonywany przez jeden z obsługiwanych przez Beam zapleczy przetwarzania rozproszonego, do których należą Apache Flink, Apache Spark, Google Cloud Dataflow i inne.
Fakultatywny
Koordynatorzy, tacy jak Apache Airflow i Kubeflow, ułatwiają konfigurowanie, obsługę, monitorowanie i konserwację potoku uczenia maszynowego.
Apache Airflow to platforma do programowego tworzenia, planowania i monitorowania przepływów pracy. TFX używa Airflow do tworzenia przepływów pracy w postaci ukierunkowanych grafów acyklicznych (DAG) zadań. Harmonogram przepływu powietrza wykonuje zadania na tablicy procesów roboczych, przestrzegając określonych zależności. Bogate narzędzia wiersza poleceń sprawiają, że wykonywanie skomplikowanych operacji na DAG-ach jest dziecinnie proste. Bogaty interfejs użytkownika ułatwia wizualizację potoków działających w produkcji, monitorowanie postępu i rozwiązywanie problemów w razie potrzeby. Gdy przepływy pracy są zdefiniowane jako kod, stają się łatwiejsze w utrzymaniu, wersjonowaniu, testowaniu i współpracy.
Kubeflow ma na celu uczynienie wdrożeń przepływów pracy uczenia maszynowego (ML) w Kubernetes prostych, przenośnych i skalowalnych. Celem Kubeflow nie jest odtworzenie innych usług, ale zapewnienie prostego sposobu wdrażania najlepszych w swojej klasie systemów open source dla ML w różnorodnych infrastrukturach. Kubeflow Pipelines umożliwiają komponowanie i wykonywanie powtarzalnych przepływów pracy w Kubeflow, zintegrowanych z doświadczeniami opartymi na eksperymentach i notatnikach. Usługi Kubeflow Pipelines w Kubernetes obejmują hostowany magazyn metadanych, silnik orkiestracji oparty na kontenerach, serwer notatników i interfejs użytkownika, które pomagają użytkownikom tworzyć, uruchamiać i zarządzać złożonymi potokami uczenia maszynowego na dużą skalę. Kubeflow Pipelines SDK umożliwia programowe tworzenie i udostępnianie komponentów i składu potoków.
Przenośność i interoperacyjność
TFX zaprojektowano tak, aby można go było przenosić do wielu środowisk i struktur orkiestracyjnych, w tym Apache Airflow , Apache Beam i Kubeflow . Można go także przenosić na różne platformy komputerowe, w tym lokalne, i platformy chmurowe, takie jak Google Cloud Platform (GCP) . W szczególności TFX współpracuje z zarządzanymi serwerowo usługami GCP, takimi jak Cloud AI Platform for Training and Prediction oraz Cloud Dataflow do rozproszonego przetwarzania danych dla kilku innych aspektów cyklu życia ML.
Model kontra zapisany model
Model
Model jest wynikiem procesu szkoleniowego. Jest to serializowany zapis ciężarów, których nauczyłeś się podczas procesu treningowego. Wagi te można później wykorzystać do obliczenia prognoz dla nowych przykładów wejściowych. W przypadku TFX i TensorFlow „model” odnosi się do punktów kontrolnych zawierających wagi poznane do tego momentu.
Należy zauważyć, że „model” może również odnosić się do definicji wykresu obliczeniowego TensorFlow (tj. pliku Pythona), który wyraża sposób obliczania przewidywania. Te dwa znaczenia mogą być używane zamiennie w zależności od kontekstu.
ZapisanyModel
- Co to jest SavedModel : uniwersalna, neutralna językowo, hermetyczna, możliwa do odzyskania serializacja modelu TensorFlow.
- Dlaczego to jest ważne : Umożliwia systemom wyższego poziomu tworzenie, przekształcanie i wykorzystywanie modeli TensorFlow przy użyciu pojedynczej abstrakcji.
SavedModel to zalecany format serializacji do obsługi modelu TensorFlow w środowisku produkcyjnym lub eksportowania przeszkolonego modelu do natywnej aplikacji mobilnej lub aplikacji JavaScript. Na przykład, aby przekształcić model w usługę REST do tworzenia prognoz, możesz serializować model jako SavedModel i udostępniać go za pomocą TensorFlow Serving. Aby uzyskać więcej informacji, zobacz Udostępnianie modelu TensorFlow .
Schemat
Niektóre komponenty TFX używają opisu danych wejściowych zwanego schematem . Schemat jest instancją schema.proto . Schematy są rodzajem bufora protokołu , bardziej ogólnie znanego jako „protobuf”. Schemat może określać typy danych dla wartości funkcji, czy funkcja musi być obecna we wszystkich przykładach, dozwolone zakresy wartości i inne właściwości. Jedną z zalet korzystania z walidacji danych TensorFlow (TFDV) jest to, że automatycznie generuje schemat na podstawie typów, kategorii i zakresów na podstawie danych szkoleniowych.
Oto fragment schematu protobuf:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Następujące komponenty korzystają ze schematu:
- Walidacja danych TensorFlow
- Transformacja TensorFlow
W typowym potoku TFX TensorFlow Data Validation generuje schemat, który jest używany przez inne komponenty.
Programowanie z TFX
TFX zapewnia potężną platformę dla każdej fazy projektu uczenia maszynowego, od badań, eksperymentów i rozwoju na maszynie lokalnej, aż po wdrożenie. Aby uniknąć powielania kodu i wyeliminować ryzyko zniekształcenia uczenia/obsługi, zdecydowanie zaleca się wdrożenie potoku TFX zarówno do szkolenia modeli, jak i wdrażania wyszkolonych modeli, a także używanie komponentów Transform , które wykorzystują bibliotekę TensorFlow Transform zarówno do szkolenia, jak i wnioskowania. W ten sposób będziesz konsekwentnie używać tego samego kodu przetwarzania wstępnego i analizy i unikniesz różnic między danymi używanymi do szkolenia a danymi wprowadzanymi do wytrenowanych modeli w środowisku produkcyjnym, a także skorzystasz z jednorazowego napisania tego kodu.
Eksploracja danych, wizualizacja i czyszczenie
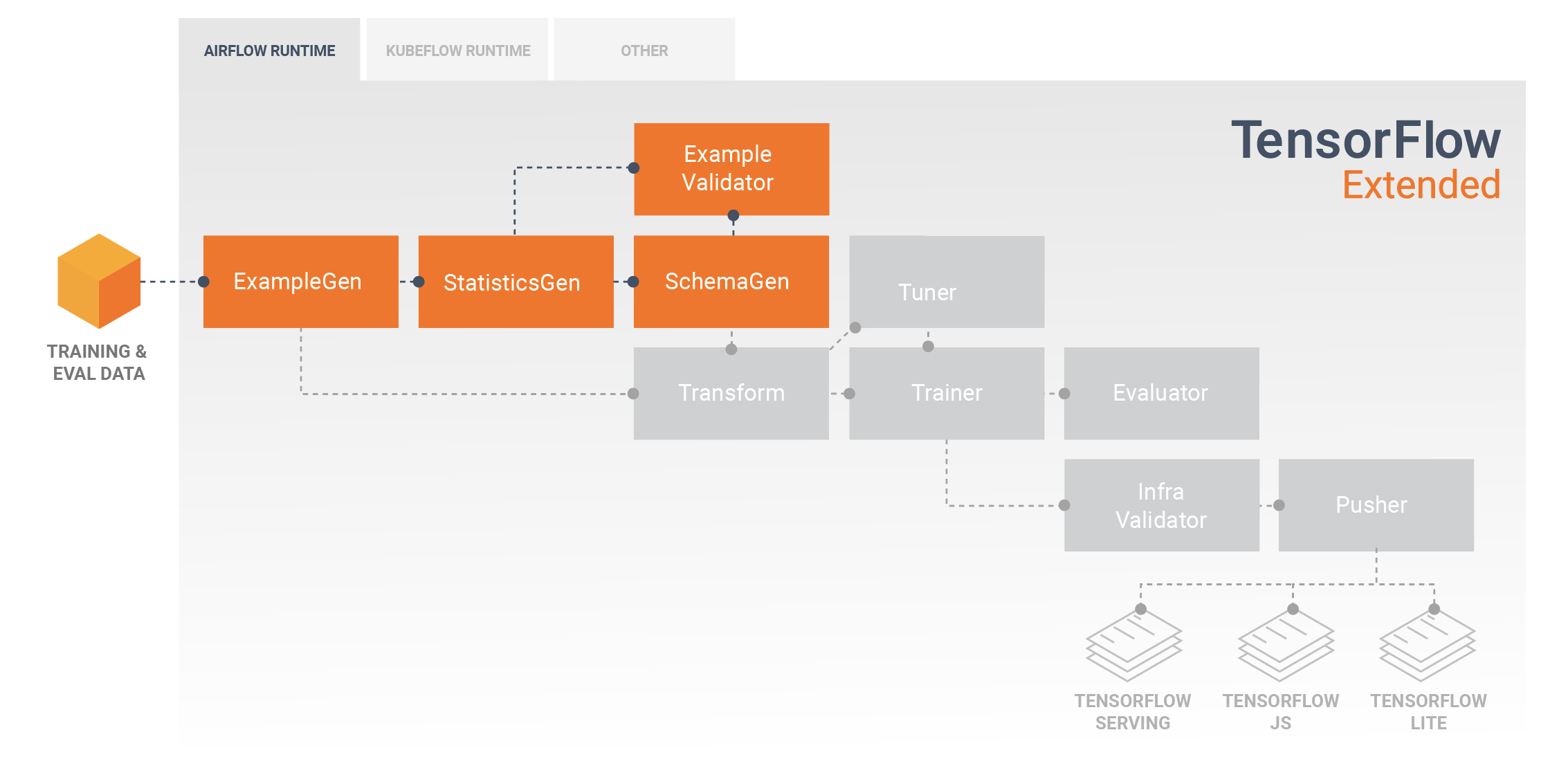
Potoki TFX zazwyczaj zaczynają się od komponentu PrzykładGen , który akceptuje dane wejściowe i formatuje je jako tf.Examples. Często robi się to po podzieleniu danych na zestawy danych szkoleniowe i ewaluacyjne, tak że w rzeczywistości istnieją dwie kopie komponentów PrzykładGen, po jednej na potrzeby szkolenia i ewaluacji. Zwykle po nim następuje komponent StatisticsGen i SchemaGen , które sprawdzają dane i wyciągają wnioski dotyczące schematu danych i statystyk. Schemat i statystyki zostaną wykorzystane przez komponent PrzykładValidator , który będzie wyszukiwał anomalie, brakujące wartości i nieprawidłowe typy danych w Twoich danych. Wszystkie te komponenty wykorzystują możliwości biblioteki TensorFlow Data Validation .
Walidacja danych TensorFlow (TFDV) to cenne narzędzie podczas wstępnej eksploracji, wizualizacji i czyszczenia zestawu danych. TFDV sprawdza Twoje dane i wnioskuje o ich typach, kategoriach i zakresach, a następnie automatycznie pomaga zidentyfikować anomalie i brakujące wartości. Udostępnia także narzędzia do wizualizacji, które mogą pomóc w badaniu i zrozumieniu zbioru danych. Po zakończeniu potoku możesz odczytać metadane z MLMD i użyć narzędzi do wizualizacji TFDV w notatniku Jupyter w celu przeanalizowania danych.
Po wstępnym szkoleniu i wdrożeniu modelu TFDV może służyć do monitorowania nowych danych z żądań wnioskowania do wdrożonych modeli oraz do wyszukiwania anomalii i/lub dryftu. Jest to szczególnie przydatne w przypadku danych szeregów czasowych, które zmieniają się w czasie w wyniku trendu lub sezonowości, i może pomóc w informowaniu o problemach z danymi lub konieczności ponownego uczenia modeli na nowych danych.
Wizualizacja danych
Po zakończeniu pierwszego przebiegu danych w sekcji potoku korzystającej z TFDV (zwykle StatisticsGen, SchemaGen i SampleValidator) możesz wizualizować wyniki w notatniku w stylu Jupytera. W przypadku dodatkowych przebiegów możesz porównywać te wyniki w trakcie dokonywania korekt, aż dane będą optymalne dla Twojego modelu i aplikacji.
Najpierw wykonasz zapytanie do metadanych ML (MLMD) , aby zlokalizować wyniki tych wykonań tych komponentów, a następnie użyjesz interfejsu API obsługi wizualizacji w TFDV, aby utworzyć wizualizacje w notatniku. Obejmuje to tfdv.load_statistics() i tfdv.visualize_statistics(). Dzięki tej wizualizacji możesz lepiej zrozumieć charakterystykę swojego zbioru danych i, jeśli to konieczne, zmodyfikować go zgodnie z wymaganiami.
Modele rozwijania i uczenia się
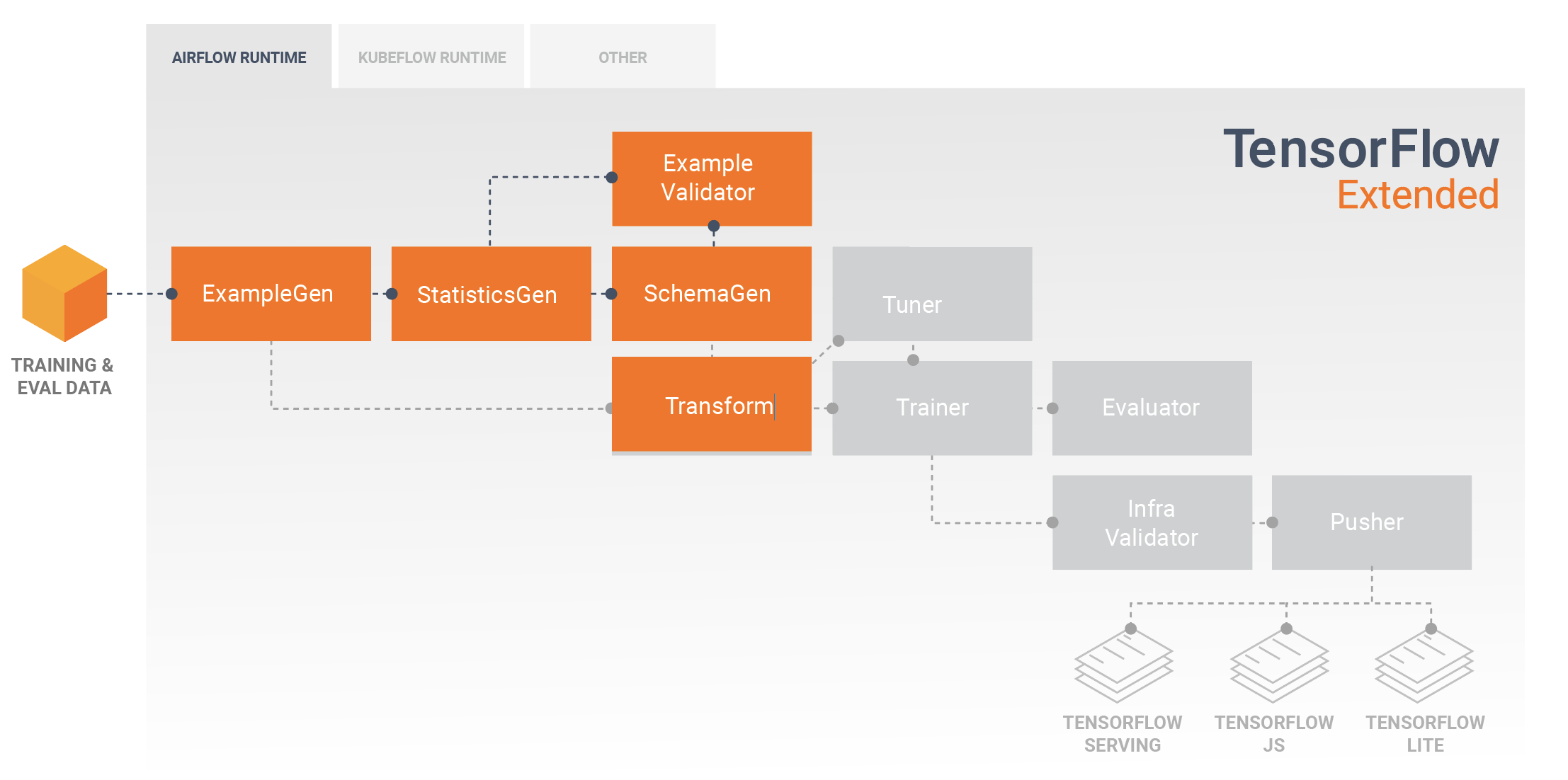
Typowy potok TFX będzie zawierał komponent Transform , który będzie przeprowadzał inżynierię funkcji, wykorzystując możliwości biblioteki TensorFlow Transform (TFT) . Składnik Transform wykorzystuje schemat utworzony przez składnik SchemaGen i stosuje transformacje danych w celu tworzenia, łączenia i przekształcania funkcji, które będą używane do uczenia modelu. Oczyszczanie brakujących wartości i konwersję typów należy również przeprowadzić w komponencie Transform, jeśli kiedykolwiek istnieje możliwość, że będą one również obecne w danych wysyłanych w celu żądania wnioskowania. Projektując kod TensorFlow do szkolenia w TFX , należy wziąć pod uwagę kilka ważnych kwestii .
Wynikiem komponentu Transform jest SavedModel, który zostanie zaimportowany i użyty w kodzie modelowania w TensorFlow podczas komponentu Trainer . Ten SavedModel zawiera wszystkie transformacje inżynierii danych utworzone w komponencie Transform, dzięki czemu identyczne transformacje są wykonywane przy użyciu dokładnie tego samego kodu zarówno podczas uczenia, jak i wnioskowania. Korzystając z kodu modelowania, w tym SavedModel ze składnika Transform, możesz korzystać z danych szkoleniowych i ewaluacyjnych oraz trenować swój model.
Podczas pracy z modelami opartymi na estymatorze ostatnia sekcja kodu modelowania powinna zapisać model zarówno jako SavedModel, jak i EvalSavedModel. Zapisanie jako EvalSavedModel gwarantuje, że metryki używane w czasie szkolenia będą również dostępne podczas oceny (należy pamiętać, że nie jest to wymagane w przypadku modeli opartych na keras). Zapisanie EvalSavedModel wymaga zaimportowania biblioteki TensorFlow Model Analysis (TFMA) do komponentu Trainer.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Przed Trainerem można dodać opcjonalny komponent Tuner , aby dostroić hiperparametry (np. liczbę warstw) modelu. Mając dany model i przestrzeń poszukiwań hiperparametrów, algorytm dostrajający znajdzie najlepsze hiperparametry w oparciu o cel.
Analizowanie i zrozumienie wydajności modelu
Po wstępnym opracowaniu modelu i szkoleniu ważne jest, aby przeanalizować i naprawdę zrozumieć działanie modelu. Typowy potok TFX będzie zawierał komponent Evaluator , który wykorzystuje możliwości biblioteki TensorFlow Model Analysis (TFMA) , która zapewnia zestaw zaawansowanych narzędzi na tym etapie programowania. Komponent Evaluator wykorzystuje wyeksportowany powyżej model i umożliwia określenie listy tfma.SlicingSpec , której można używać podczas wizualizacji i analizowania wydajności modelu. Każda SlicingSpec definiuje wycinek danych szkoleniowych, który chcesz sprawdzić, na przykład określone kategorie cech kategorycznych lub określone zakresy cech liczbowych.
Może to być na przykład ważne przy próbie zrozumienia skuteczności Twojego modelu w przypadku różnych segmentów klientów, których można podzielić na segmenty według rocznych zakupów, danych geograficznych, grupy wiekowej lub płci. Może to być szczególnie ważne w przypadku zbiorów danych z długimi ogonami, gdzie wyniki dominującej grupy mogą maskować niedopuszczalne wyniki w przypadku ważnych, ale mniejszych grup. Na przykład Twój model może działać dobrze w przypadku przeciętnych pracowników, ale kiepsko zawodzić w przypadku kadry kierowniczej, i może być dla Ciebie ważne, aby o tym wiedzieć.
Analiza modelu i wizualizacja
Po ukończeniu pierwszego przebiegu danych poprzez przeszkolenie modelu i uruchomienie komponentu Evaluator (który wykorzystuje TFMA ) na wynikach uczenia, możesz wizualizować wyniki w notatniku w stylu Jupytera. W przypadku dodatkowych serii możesz porównywać te wyniki w trakcie dokonywania regulacji, aż wyniki będą optymalne dla Twojego modelu i zastosowania.
Najpierw wykonasz zapytanie do metadanych ML (MLMD) , aby zlokalizować wyniki tych wykonań tych komponentów, a następnie użyjesz interfejsu API obsługi wizualizacji w TFMA, aby utworzyć wizualizacje w swoim notatniku. Obejmuje to tfma.load_eval_results i tfma.view.render_slicing_metrics Dzięki tej wizualizacji możesz lepiej zrozumieć charakterystykę swojego modelu i, jeśli to konieczne, zmodyfikować go zgodnie z wymaganiami.
Sprawdzanie wydajności modelu
W ramach analizowania wydajności modelu możesz chcieć zweryfikować wydajność względem wartości bazowej (takiej jak aktualnie wyświetlany model). Walidacja modelu odbywa się poprzez przekazanie zarówno modelu kandydującego, jak i modelu bazowego do komponentu oceniającego . Osoba oceniająca oblicza metryki (np. AUC, strata) zarówno dla kandydata, jak i linii bazowej, wraz z odpowiednim zestawem metryk różnicowych. Następnie można zastosować progi i wykorzystać je do wypuszczenia modeli do produkcji.
Sprawdzanie, czy model może zostać wyświetlony
Przed wdrożeniem przeszkolonego modelu warto sprawdzić, czy model jest rzeczywiście możliwy do obsługi w infrastrukturze obsługującej. Jest to szczególnie ważne w środowiskach produkcyjnych, aby mieć pewność, że nowo opublikowany model nie uniemożliwi systemowi obsługi predykcji. Komponent InfraValidator przeprowadzi wdrożenie Twojego modelu w środowisku piaskownicy i opcjonalnie wyśle rzeczywiste żądania w celu sprawdzenia, czy Twój model działa poprawnie.
Cele wdrożenia
Po opracowaniu i wytrenowaniu modelu, z którego jesteś zadowolony, nadszedł czas na wdrożenie go w co najmniej jednym miejscu docelowym wdrożenia, gdzie będzie on otrzymywać żądania wnioskowania. TFX obsługuje wdrażanie w trzech klasach celów wdrożenia. Wytrenowane modele, które zostały wyeksportowane jako SavedModels, można wdrożyć w dowolnym lub wszystkich tych miejscach docelowych wdrożenia.
Wniosek: obsługa TensorFlow
TensorFlow Serving (TFS) to elastyczny, wysokowydajny system obsługi modeli uczenia maszynowego, zaprojektowany z myślą o środowiskach produkcyjnych. Zużywa SavedModel i akceptuje żądania wnioskowania za pośrednictwem interfejsów REST lub gRPC. Działa jako zestaw procesów na jednym lub większej liczbie serwerów sieciowych, wykorzystując jedną z kilku zaawansowanych architektur do obsługi synchronizacji i obliczeń rozproszonych. Więcej informacji na temat opracowywania i wdrażania rozwiązań TFS można znaleźć w dokumentacji TFS .
W typowym potoku SavedModel, który został przeszkolony w komponencie Trainer , zostałby najpierw poddany infra-walidacji w komponencie InfraValidator . InfraValidator uruchamia serwer modelu Canary TFS, który faktycznie obsługuje SavedModel. Jeśli weryfikacja przebiegła pomyślnie, komponent Pusher w końcu wdroży SavedModel w infrastrukturze TFS. Obejmuje to obsługę wielu wersji i aktualizacji modeli.
Wnioskowanie w natywnych aplikacjach mobilnych i IoT: TensorFlow Lite
TensorFlow Lite to zestaw narzędzi, który ma pomóc programistom w korzystaniu z wyszkolonych modeli TensorFlow w natywnych aplikacjach mobilnych i IoT. Wykorzystuje te same SavedModels co TensorFlow Serving i stosuje optymalizacje, takie jak kwantyzacja i przycinanie, aby zoptymalizować rozmiar i wydajność wynikowych modeli pod kątem wyzwań związanych z działaniem na urządzeniach mobilnych i IoT. Więcej informacji na temat korzystania z TensorFlow Lite można znaleźć w dokumentacji TensorFlow Lite.
Wnioskowanie w JavaScript: TensorFlow JS
TensorFlow JS to biblioteka JavaScript do uczenia i wdrażania modeli ML w przeglądarce i na Node.js. Wykorzystuje te same SavedModels co TensorFlow Serving i TensorFlow Lite i konwertuje je do formatu internetowego TensorFlow.js. Więcej szczegółów na temat korzystania z TensorFlow JS można znaleźć w dokumentacji TensorFlow JS.
Tworzenie rurociągu TFX z przepływem powietrza
Aby uzyskać szczegółowe informacje, sprawdź warsztat zajmujący się przepływem powietrza
Tworzenie potoku TFX za pomocą Kubeflow
Organizować coś
Kubeflow wymaga klastra Kubernetes do uruchamiania potoków na dużą skalę. Zobacz wytyczne dotyczące wdrażania Kubeflow, które przedstawiają opcje wdrażania klastra Kubeflow.
Skonfiguruj i uruchom potok TFX
Aby uruchomić przykładowy potok TFX w Kubeflow, postępuj zgodnie z samouczkiem dotyczącym TFX na platformie Cloud AI Platform Pipeline . Komponenty TFX zostały skonteneryzowane w celu utworzenia potoku Kubeflow, a przykład ilustruje możliwość skonfigurowania potoku do odczytu dużego publicznego zestawu danych oraz wykonywania etapów szkolenia i przetwarzania danych na dużą skalę w chmurze.
Interfejs wiersza poleceń dla działań potokowych
TFX zapewnia ujednolicony interfejs CLI, który pomaga wykonywać pełny zakres działań potokowych, takich jak tworzenie, aktualizacja, uruchamianie, wyświetlanie listy i usuwanie potoków w różnych orkiestratorach, w tym Apache Airflow, Apache Beam i Kubeflow. Aby uzyskać szczegółowe informacje, postępuj zgodnie z poniższymi instrukcjami .