
giriiş
TFX, TensorFlow'u temel alan, Google üretim ölçeğinde bir makine öğrenimi (ML) platformudur. Makine öğrenimi sisteminizi tanımlamak, başlatmak ve izlemek için gereken ortak bileşenleri entegre etmek için bir yapılandırma çerçevesi ve paylaşılan kitaplıklar sağlar.
TFX1.0
TFX 1.0.0'ın kullanıma sunulduğunu duyurmaktan mutluluk duyuyoruz. Bu, istikrarlı genel API'ler ve yapılar sağlayan TFX'in beta sonrası ilk sürümüdür. Gelecekteki TFX işlem hatlarınızın, bu RFC'de tanımlanan uyumluluk kapsamı dahilinde bir yükseltme sonrasında çalışmaya devam edeceğinden emin olabilirsiniz.
Kurulum

![]()
pip install tfx
Gecelik Paketler
TFX ayrıca Google Cloud'da https://pypi-nightly.tensorflow.org adresinde gecelik paketler de barındırır. En son gecelik paketi yüklemek için lütfen aşağıdaki komutu kullanın:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
Bu, TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD) gibi TFX'in ana bağımlılıklarına yönelik gecelik paketleri yükleyecektir.
TFX Hakkında
TFX, üretim ortamında makine öğrenimi iş akışlarını oluşturmaya ve yönetmeye yönelik bir platformdur. TFX aşağıdakileri sağlar:
Makine öğrenimi işlem hatları oluşturmaya yönelik bir araç seti. TFX işlem hatları, ML iş akışınızı Apache Airflow, Apache Beam ve Kubeflow Pipelines gibi çeşitli platformlarda düzenlemenize olanak tanır.
Bir işlem hattının parçası olarak veya makine öğrenimi eğitim betiğinizin bir parçası olarak kullanabileceğiniz bir dizi standart bileşen. TFX standart bileşenleri, bir makine öğrenimi sürecini kolayca oluşturmaya başlamanıza yardımcı olmak için kanıtlanmış işlevsellik sağlar.
Standart bileşenlerin çoğu için temel işlevleri sağlayan kitaplıklar. Bu işlevselliği kendi özel bileşenlerinize eklemek için TFX kitaplıklarını kullanabilir veya bunları ayrı ayrı kullanabilirsiniz.
TFX, TensorFlow'u temel alan, Google üretim ölçeğinde bir makine öğrenimi araç setidir. Makine öğrenimi sisteminizi tanımlamak, başlatmak ve izlemek için gereken ortak bileşenleri entegre etmek için bir yapılandırma çerçevesi ve paylaşılan kitaplıklar sağlar.
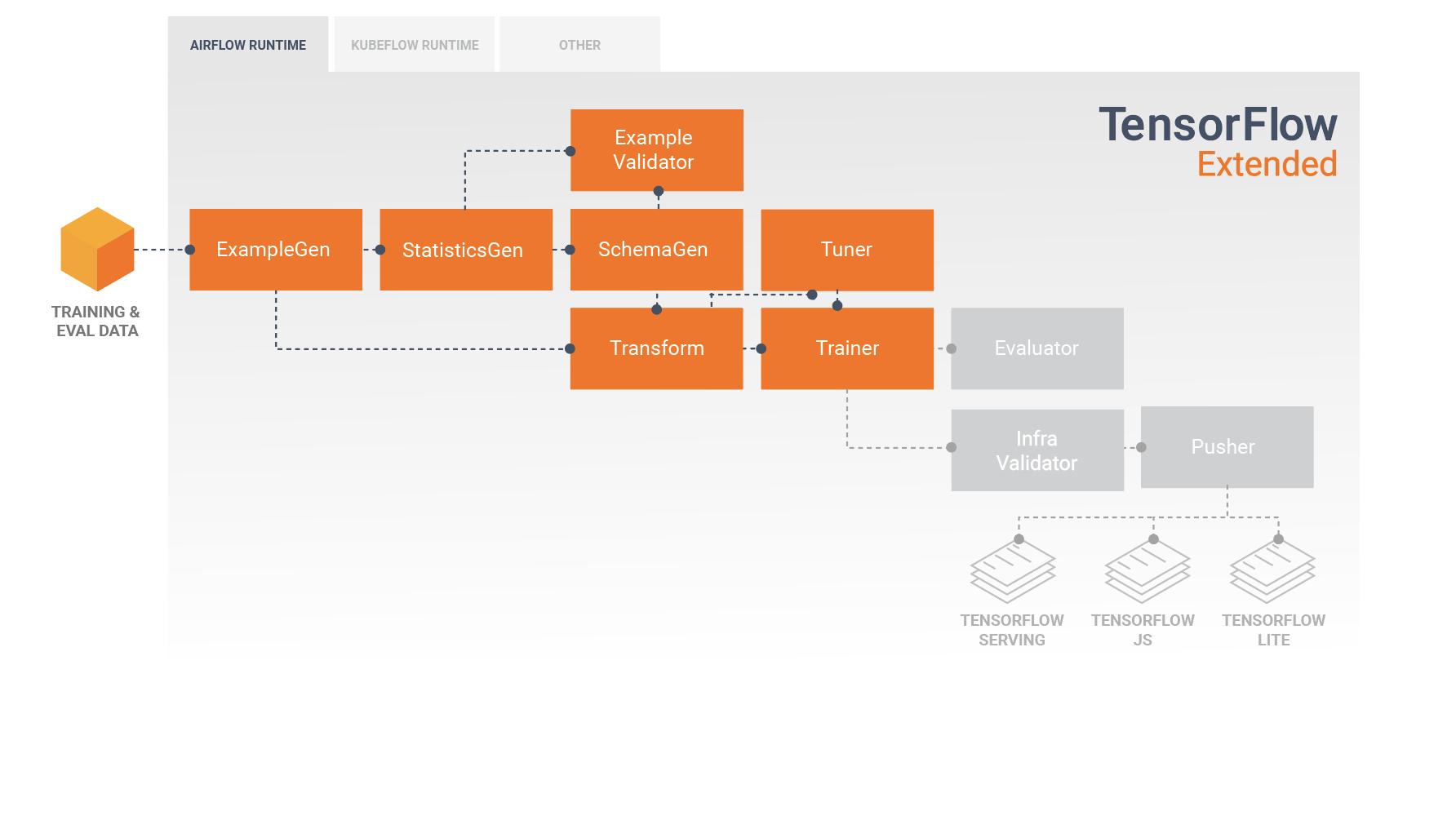
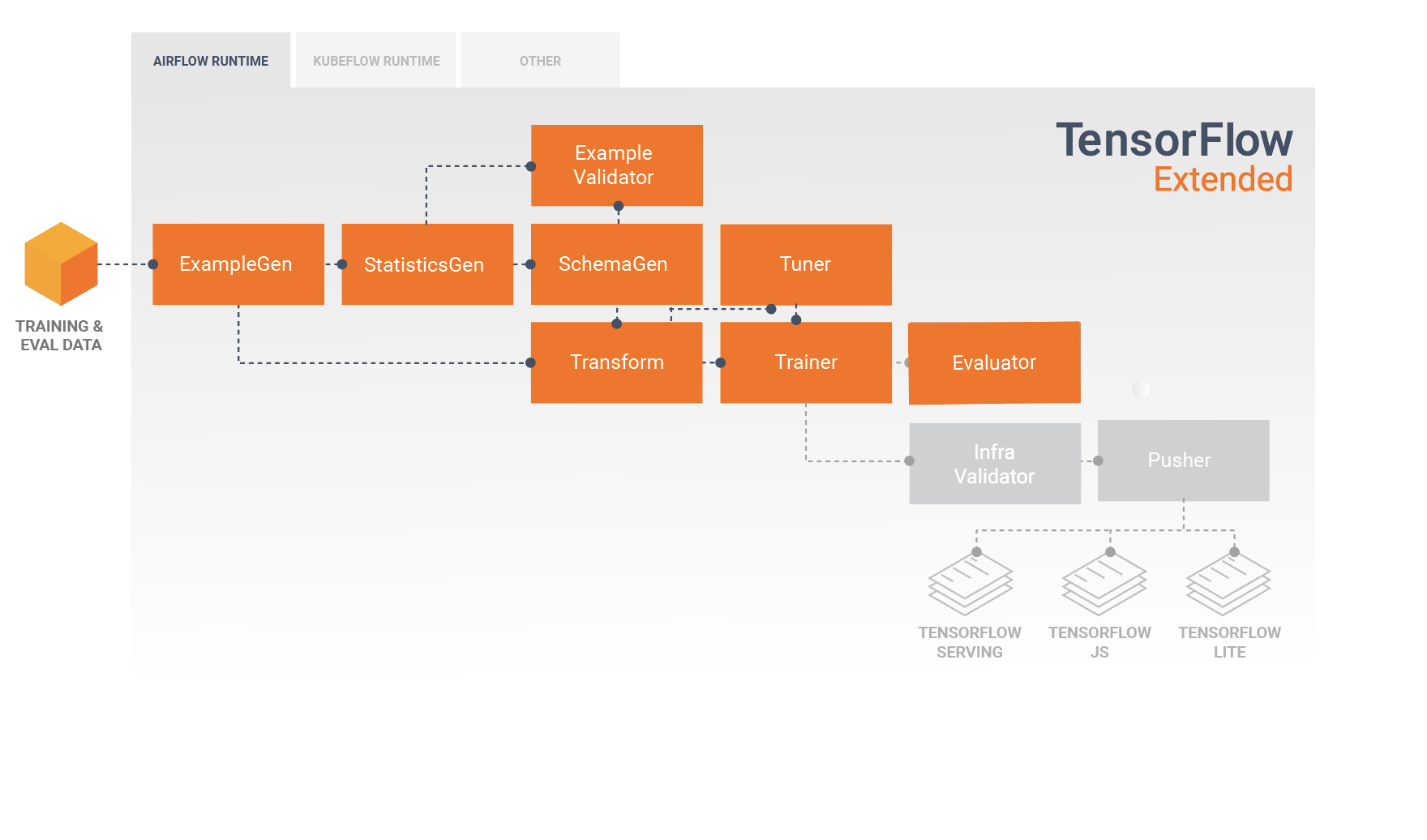
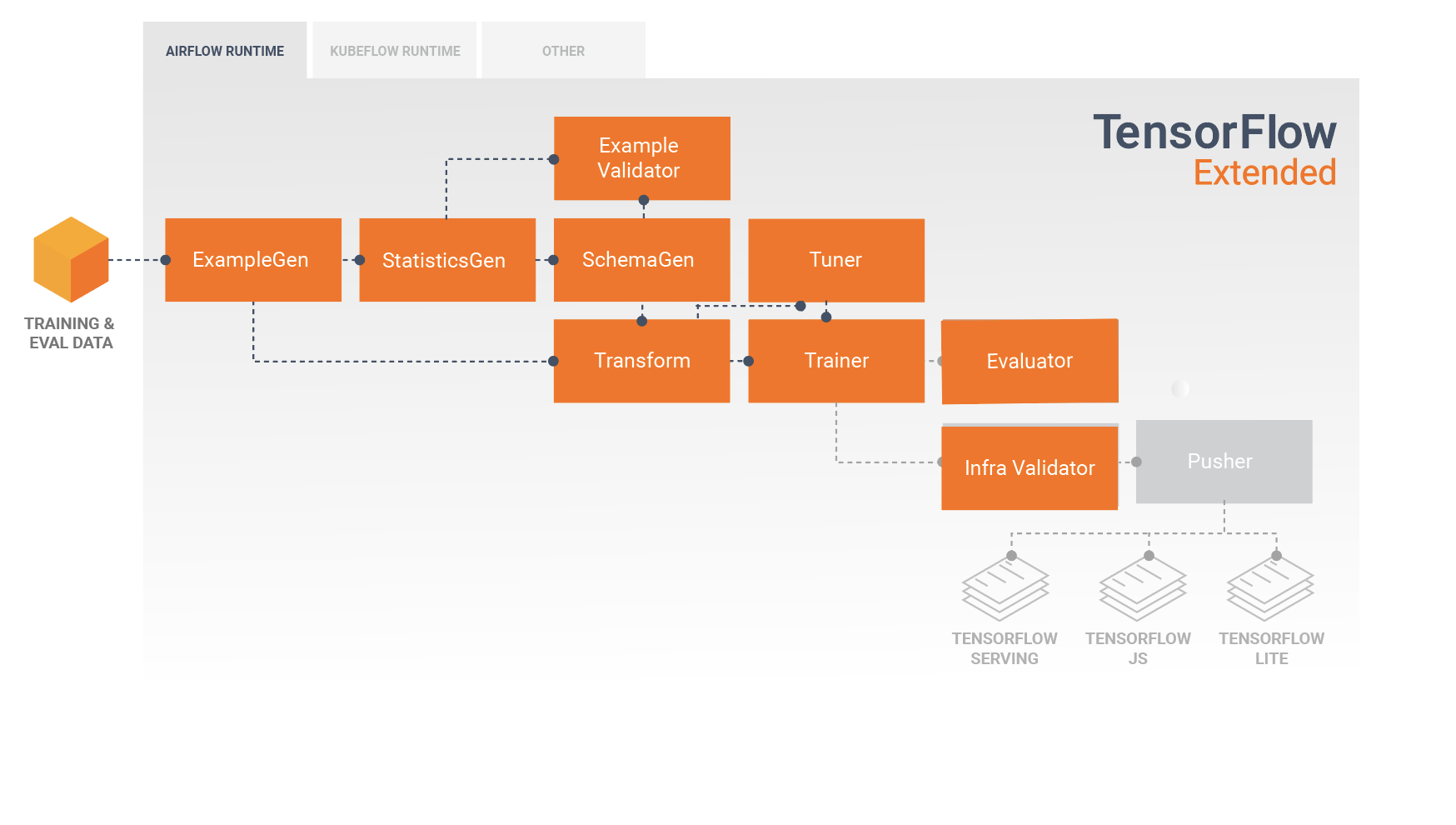
TFX Standart Bileşenleri
TFX işlem hattı, ölçeklenebilir, yüksek performanslı makine öğrenimi görevleri için özel olarak tasarlanmış bir ML işlem hattını uygulayan bir bileşenler dizisidir. Buna modelleme, eğitim, çıkarım sunma ve çevrimiçi, yerel mobil ve JavaScript hedeflerine yönelik dağıtımları yönetme dahildir.
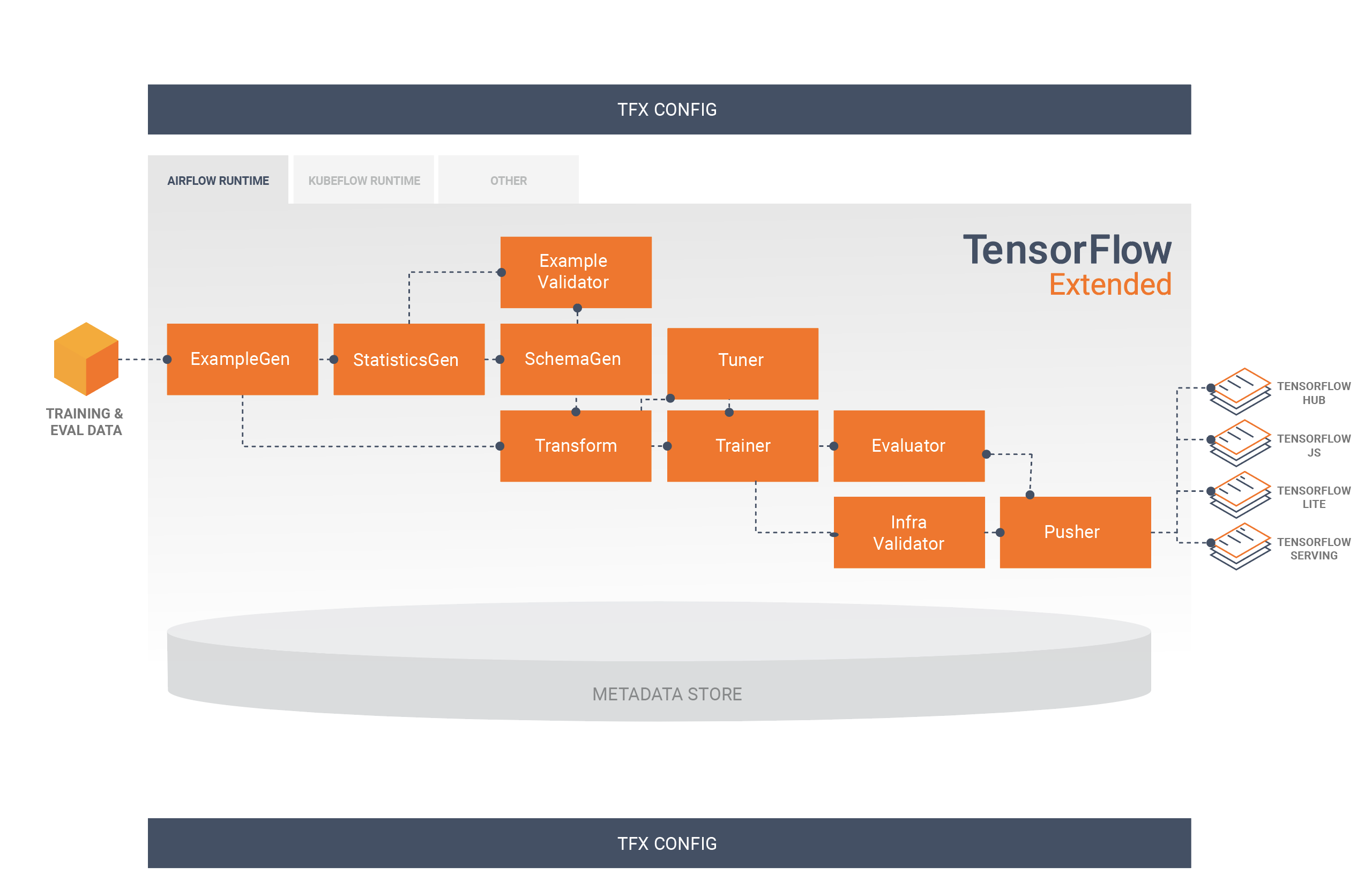
Bir TFX işlem hattı genellikle aşağıdaki bileşenleri içerir:
SampleGen, giriş veri kümesini alan ve isteğe bağlı olarak bölen bir işlem hattının ilk giriş bileşenidir.
İstatistikGen, veri kümesine ilişkin istatistikleri hesaplar.
SchemaGen istatistikleri inceler ve bir veri şeması oluşturur.
SampleValidator, veri kümesindeki anormallikleri ve eksik değerleri arar.
Transform, veri kümesi üzerinde özellik mühendisliği gerçekleştirir.
Eğitmen modeli eğitir.
Ayarlayıcı, modelin hiper parametrelerini ayarlar.
Değerlendirici, eğitim sonuçlarının derinlemesine analizini yapar ve dışa aktarılan modellerinizi doğrulamanıza yardımcı olarak bunların üretime aktarılacak kadar "yeterince iyi" olduğundan emin olmanızı sağlar.
InfraValidator, modelin gerçekten altyapıdan sunulabilir olup olmadığını kontrol eder ve hatalı modelin gönderilmesini engeller.
Pusher, modeli bir hizmet altyapısına dağıtır.
BulkInferrer, etiketlenmemiş çıkarım istekleri olan bir model üzerinde toplu işlem gerçekleştirir.
Bu diyagram, bu bileşenler arasındaki veri akışını göstermektedir:
TFX Kütüphaneleri
TFX hem kitaplıkları hem de ardışık düzen bileşenlerini içerir. Bu diyagram, TFX kitaplıkları ve ardışık düzen bileşenleri arasındaki ilişkileri göstermektedir:
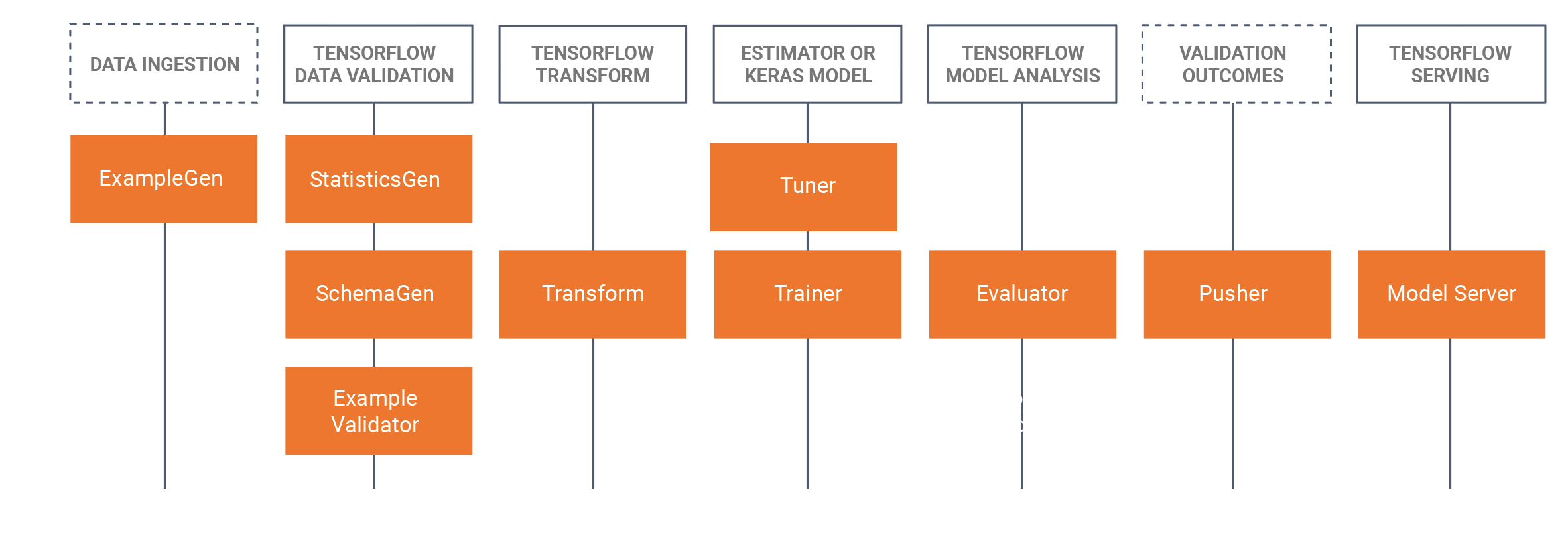
TFX, ardışık düzen bileşenleri oluşturmak için kullanılan kitaplıklar olan çeşitli Python paketleri sağlar. Kodunuzun işlem hattınızın benzersiz yönlerine odaklanabilmesi için işlem hatlarınızın bileşenlerini oluşturmak için bu kitaplıkları kullanacaksınız.
TFX kütüphaneleri şunları içerir:
TensorFlow Veri Doğrulaması (TFDV), makine öğrenimi verilerini analiz etmeye ve doğrulamaya yönelik bir kitaplıktır. Yüksek düzeyde ölçeklenebilir olacak ve TensorFlow ve TFX ile iyi çalışacak şekilde tasarlanmıştır. TFDV şunları içerir:
- Eğitim ve test verilerinin özet istatistiklerinin ölçeklenebilir hesaplanması.
- Veri dağıtımları ve istatistikler için bir görüntüleyiciyle entegrasyonun yanı sıra veri kümesi çiftlerinin (Facets) yönlü karşılaştırması.
- Gerekli değerler, aralıklar ve sözlükler gibi verilerle ilgili beklentileri tanımlamak için otomatik veri şeması oluşturma.
- Şemayı incelemenize yardımcı olacak bir şema görüntüleyici.
- Eksik özellikler, aralık dışı değerler veya yanlış özellik türleri gibi anormallikleri tanımlamak için anormallik tespiti bunlardan birkaçıdır.
- Hangi özelliklerde anormallik olduğunu görebilmenizi ve bunları düzeltmek için daha fazla bilgi edinebilmenizi sağlayan bir anormallik görüntüleyici.
TensorFlow Transform (TFT), TensorFlow ile verilerin ön işlenmesine yönelik bir kitaplıktır. TensorFlow Dönüşümü, aşağıdakiler gibi tam geçiş gerektiren veriler için kullanışlıdır:
- Bir giriş değerini ortalama ve standart sapmaya göre normalleştirin.
- Tüm giriş değerleri için bir sözlük oluşturarak dizeleri tam sayılara dönüştürün.
- Kayan noktaları gözlemlenen veri dağılımına göre paketlere atayarak tam sayılara dönüştürün.
TensorFlow, TFX ile modellerin eğitimi için kullanılır. Eğitim verilerini ve modelleme kodunu alır ve bir SavedModel sonucu oluşturur. Ayrıca, giriş verilerinin ön işlenmesi için TensorFlow Transform tarafından oluşturulan bir özellik mühendisliği hattını da entegre eder.
KerasTuner, model için hiperparametreleri ayarlamak için kullanılır.
TensorFlow Model Analizi (TFMA), TensorFlow modellerini değerlendirmeye yönelik bir kitaplıktır. Analizinin temelini oluşturan EvalSavedModel'i oluşturmak için TensorFlow ile birlikte kullanılır. Kullanıcıların, eğitmenlerinde tanımlanan aynı metrikleri kullanarak modellerini büyük miktarda veri üzerinde dağıtılmış bir şekilde değerlendirmelerine olanak tanır. Bu ölçümler farklı veri dilimleri üzerinden hesaplanabilir ve Jupyter not defterlerinde görselleştirilebilir.
TensorFlow Meta Verileri (TFMD), makine öğrenimi modellerini TensorFlow ile eğitirken faydalı olan meta veriler için standart gösterimler sağlar. Meta veriler, girdi verileri analizi sırasında elle veya otomatik olarak üretilebilir ve veri doğrulama, araştırma ve dönüştürme için kullanılabilir. Meta veri serileştirme formatları şunları içerir:
- Tablo verilerini açıklayan bir şema (örneğin, tf.Örnekler).
- Bu tür veri kümelerine ilişkin özet istatistik koleksiyonu.
ML Meta Verileri (MLMD), ML geliştiricisi ve veri bilimci iş akışlarıyla ilişkili meta verileri kaydetmeye ve almaya yönelik bir kitaplıktır. Çoğu zaman meta veriler TFMD gösterimlerini kullanır. MLMD, SQL-Lite , MySQL ve diğer benzer veri depolarını kullanarak kalıcılığı yönetir.
Destekleyici Teknolojiler
Gerekli
- Apache Beam, hem toplu hem de akışlı veri paralel işleme hatlarını tanımlamak için kullanılan açık kaynaklı, birleşik bir modeldir. TFX, veri paralel işlem hatlarını uygulamak için Apache Beam'i kullanır. İşlem hattı daha sonra Beam'in Apache Flink, Apache Spark, Google Cloud Dataflow ve diğerlerini içeren desteklenen dağıtılmış işleme arka uçlarından biri tarafından yürütülür.
İsteğe bağlı
Apache Airflow ve Kubeflow gibi orkestrasyon araçları, bir makine öğrenimi hattının yapılandırılmasını, çalıştırılmasını, izlenmesini ve bakımını kolaylaştırır.
Apache Airflow, iş akışlarını programlı olarak yazmak, planlamak ve izlemek için kullanılan bir platformdur. TFX, iş akışlarını görevlerin yönlendirilmiş döngüsel grafikleri (DAG'ler) olarak yazmak için Airflow'u kullanır. Airflow zamanlayıcı, belirtilen bağımlılıkları takip ederken bir dizi çalışan üzerinde görevleri yürütür. Zengin komut satırı yardımcı programları, DAG'lerde karmaşık ameliyatların kolaylıkla gerçekleştirilmesini sağlar. Zengin kullanıcı arayüzü, üretimde çalışan işlem hatlarını görselleştirmeyi, ilerlemeyi izlemeyi ve gerektiğinde sorunları gidermeyi kolaylaştırır. İş akışları kod olarak tanımlandığında daha sürdürülebilir, sürümlendirilebilir, test edilebilir ve işbirliğine dayalı hale gelirler.
Kubeflow, Kubernetes'te makine öğrenimi (ML) iş akışlarının dağıtımlarını basit, taşınabilir ve ölçeklenebilir hale getirmeye kendini adamıştır. Kubeflow'un hedefi diğer hizmetleri yeniden oluşturmak değil, makine öğrenimi için türünün en iyisi açık kaynak sistemlerini çeşitli altyapılara dağıtmanın basit bir yolunu sağlamaktır. Kubeflow İşlem Hatları , deney ve dizüstü bilgisayar tabanlı deneyimlerle entegre olarak Kubeflow'ta tekrarlanabilir iş akışlarının oluşturulmasına ve yürütülmesine olanak tanır. Kubernetes'teki Kubeflow Pipelines hizmetleri, kullanıcıların karmaşık ML işlem hatlarını uygun ölçekte geliştirmesine, çalıştırmasına ve yönetmesine yardımcı olmak için barındırılan Meta Veri deposunu, konteyner tabanlı düzenleme motorunu, dizüstü bilgisayar sunucusunu ve kullanıcı arayüzünü içerir. Kubeflow Pipelines SDK, bileşenlerin ve ardışık düzen kompozisyonlarının program aracılığıyla oluşturulmasına ve paylaşılmasına olanak tanır.
Taşınabilirlik ve Birlikte Çalışabilirlik
TFX, Apache Airflow , Apache Beam ve Kubeflow dahil olmak üzere birçok ortama ve düzenleme çerçevesine taşınabilir olacak şekilde tasarlanmıştır. Ayrıca şirket içi ve Google Cloud Platform (GCP) gibi bulut platformları da dahil olmak üzere farklı bilgi işlem platformlarına taşınabilir. TFX, özellikle Eğitim ve Tahmin için Cloud AI Platformu ve makine öğrenimi yaşam döngüsünün diğer bazı yönleri için dağıtılmış veri işlemeye yönelik Cloud Dataflow gibi sunucu tarafından yönetilen GCP hizmetleriyle birlikte çalışır.
Model ve SavedModel Karşılaştırması
Modeli
Model eğitim sürecinin çıktısıdır. Eğitim sürecinde öğrenilen ağırlıkların serileştirilmiş kaydıdır. Bu ağırlıklar daha sonra yeni girdi örneklerine yönelik tahminleri hesaplamak için kullanılabilir. TFX ve TensorFlow için 'model', o ana kadar öğrenilen ağırlıkları içeren kontrol noktalarını ifade eder.
'Model'in aynı zamanda bir tahminin nasıl hesaplanacağını ifade eden TensorFlow hesaplama grafiğinin (yani bir Python dosyası) tanımına da atıfta bulunabileceğini unutmayın. Bağlama bağlı olarak iki anlam birbirinin yerine kullanılabilir.
KaydedilenModel
- SavedModel nedir : TensorFlow modelinin evrensel, dilden bağımsız, hermetik, kurtarılabilir serileştirmesi.
- Neden önemlidir : Üst düzey sistemlerin TensorFlow modellerini tek bir soyutlama kullanarak üretmesini, dönüştürmesini ve tüketmesini sağlar.
SavedModel, bir TensorFlow modelini üretimde sunmak veya eğitilmiş bir modeli yerel bir mobil veya JavaScript uygulamasına aktarmak için önerilen serileştirme formatıdır. Örneğin, bir modeli tahmin yapmak amacıyla bir REST hizmetine dönüştürmek için modeli SavedModel olarak serileştirebilir ve TensorFlow Serving'i kullanarak sunabilirsiniz. Daha fazla bilgi için bkz. TensorFlow Modelini Sunma .
Şema
Bazı TFX bileşenleri giriş verilerinizin şema adı verilen bir tanımını kullanır. Şema, schema.proto'nun bir örneğidir. Şemalar, daha genel olarak "protobuf" olarak bilinen bir tür protokol arabelleğidir . Şema, özellik değerleri için veri türlerini, bir özelliğin tüm örneklerde mevcut olup olmayacağını, izin verilen değer aralıklarını ve diğer özellikleri belirtebilir. TensorFlow Veri Doğrulamasını (TFDV) kullanmanın faydalarından biri, eğitim verilerinden türleri, kategorileri ve aralıkları çıkararak otomatik olarak bir şema oluşturmasıdır.
İşte şema protobuf'tan bir alıntı:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
Aşağıdaki bileşenler şemayı kullanır:
- TensorFlow Veri Doğrulaması
- TensorFlow Dönüşümü
Tipik bir TFX işlem hattında TensorFlow Veri Doğrulaması, diğer bileşenler tarafından tüketilen bir şema oluşturur.
TFX ile Geliştirme
TFX, yerel makinenizdeki araştırma, deney ve geliştirmeden dağıtıma kadar bir makine öğrenimi projesinin her aşaması için güçlü bir platform sağlar. Kod tekrarını önlemek ve eğitim/sunum çarpıklığı potansiyelini ortadan kaldırmak için, hem model eğitimi hem de eğitimli modellerin dağıtımı için TFX işlem hattınızı uygulamanız ve hem eğitim hem de çıkarım için TensorFlow Transform kitaplığından yararlanan Transform bileşenlerini kullanmanız önemle tavsiye edilir. Bunu yaparak aynı ön işleme ve analiz kodunu tutarlı bir şekilde kullanacak ve eğitim için kullanılan veriler ile üretimde eğitilmiş modellerinize beslenen veriler arasındaki farkları önleyecek ve bu kodu bir kez yazmanın avantajından yararlanacaksınız.
Veri Araştırma, Görselleştirme ve Temizleme
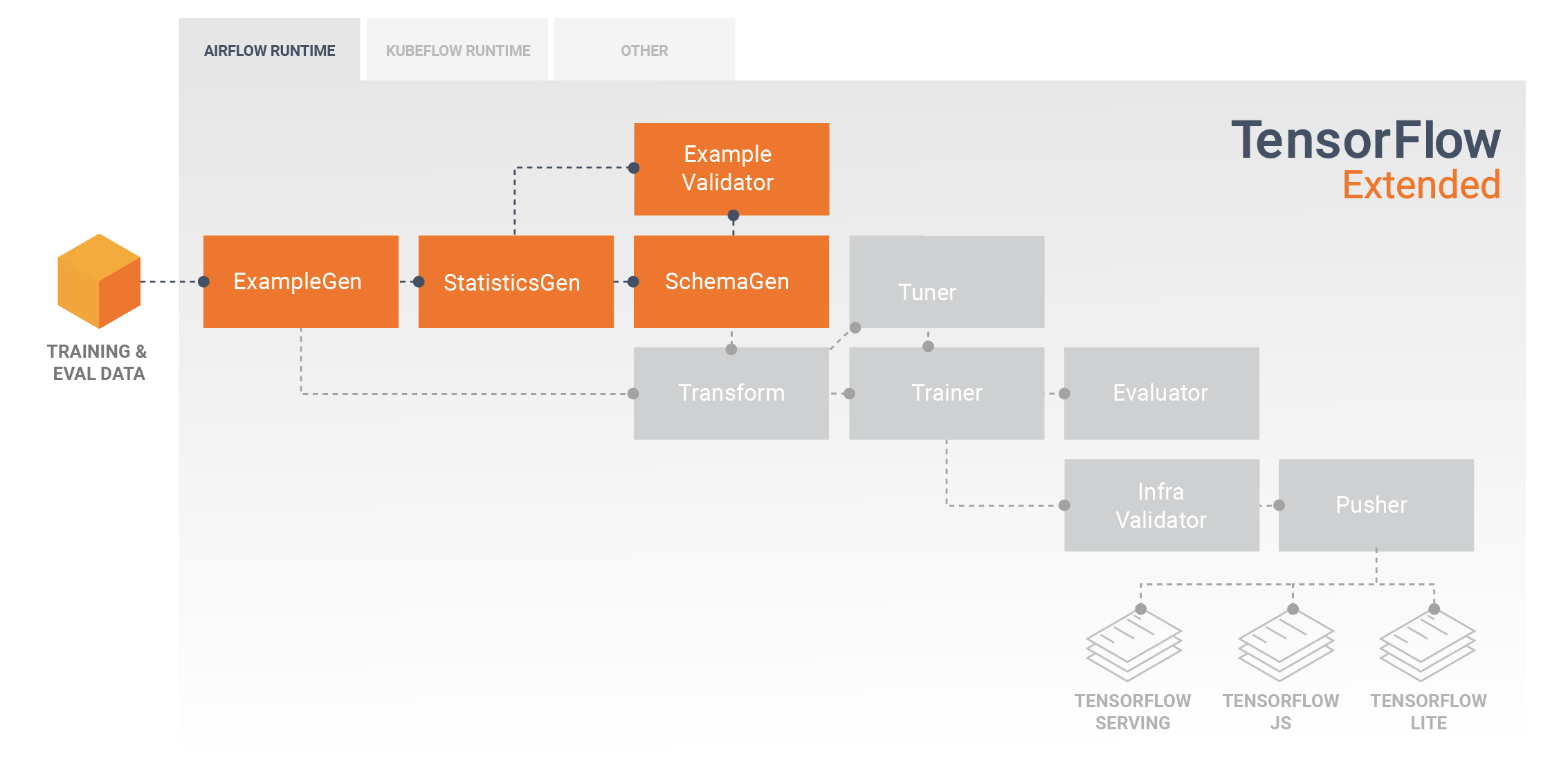
TFX işlem hatları genellikle giriş verilerini kabul eden ve bunu tf.Examples olarak biçimlendiren bir SampleGen bileşeniyle başlar. Genellikle bu, veriler eğitim ve değerlendirme veri kümelerine bölündükten sonra yapılır, böylece her biri eğitim ve değerlendirme için olmak üzere aslında SampleGen bileşenlerinin iki kopyası olur. Bunu genellikle verilerinizi inceleyip bir veri şeması ve istatistik çıkarımı yapacak olan bir İstatistikGen bileşeni ve bir SchemaGen bileşeni takip eder. Şema ve istatistikler, verilerinizdeki anormallikleri, eksik değerleri ve yanlış veri türlerini arayan bir SampleValidator bileşeni tarafından kullanılacaktır. Bu bileşenlerin tümü TensorFlow Veri Doğrulama kütüphanesinin yeteneklerinden yararlanır.
TensorFlow Veri Doğrulaması (TFDV), veri kümenizin ilk keşfini, görselleştirilmesini ve temizlenmesini gerçekleştirirken değerli bir araçtır. TFDV, verilerinizi inceleyerek veri türleri, kategorileri ve aralıkları hakkında çıkarım yapar ve ardından anormalliklerin ve eksik değerlerin belirlenmesine otomatik olarak yardımcı olur. Ayrıca veri kümenizi incelemenize ve anlamanıza yardımcı olabilecek görselleştirme araçları da sağlar. İşlem hattınız tamamlandıktan sonra, verilerinizi analiz etmek için MLMD'den meta verileri okuyabilir ve bir Jupyter not defterindeki TFDV'nin görselleştirme araçlarını kullanabilirsiniz.
İlk model eğitiminizin ve dağıtımınızın ardından TFDV, çıkarım isteklerinden dağıtılan modellerinize kadar olan yeni verileri izlemek ve anormallikleri ve/veya sapmaları aramak için kullanılabilir. Bu, özellikle trend veya mevsimselliğin bir sonucu olarak zaman içinde değişen zaman serisi verileri için kullanışlıdır ve veri sorunları olduğunda veya modellerin yeni veriler üzerinde yeniden eğitilmesi gerektiğinde bilgi verilmesine yardımcı olabilir.
Veri Görselleştirme
İşlem hattınızın TFDV (genellikle İstatistikGen, SchemaGen ve ÖrnekValidator) kullanan bölümü aracılığıyla verilerinizin ilk çalışmasını tamamladıktan sonra, sonuçları Jupyter tarzı bir not defterinde görselleştirebilirsiniz. Ek çalıştırmalar için, verileriniz modeliniz ve uygulamanız için ideal olana kadar ayarlamalar yaparken bu sonuçları karşılaştırabilirsiniz.
Bu bileşenlerin bu uygulamalarının sonuçlarını bulmak için önce ML Meta Verilerini (MLMD) sorgulayacak ve ardından not defterinizde görselleştirmeler oluşturmak için TFDV'deki görselleştirme destek API'sini kullanacaksınız. Buna tfdv.load_statistics() ve tfdv.visualize_statistics() dahildir. Bu görselleştirmeyi kullanarak veri kümenizin özelliklerini daha iyi anlayabilir ve gerekirse gerektiği gibi değiştirebilirsiniz.
Model Geliştirme ve Eğitim
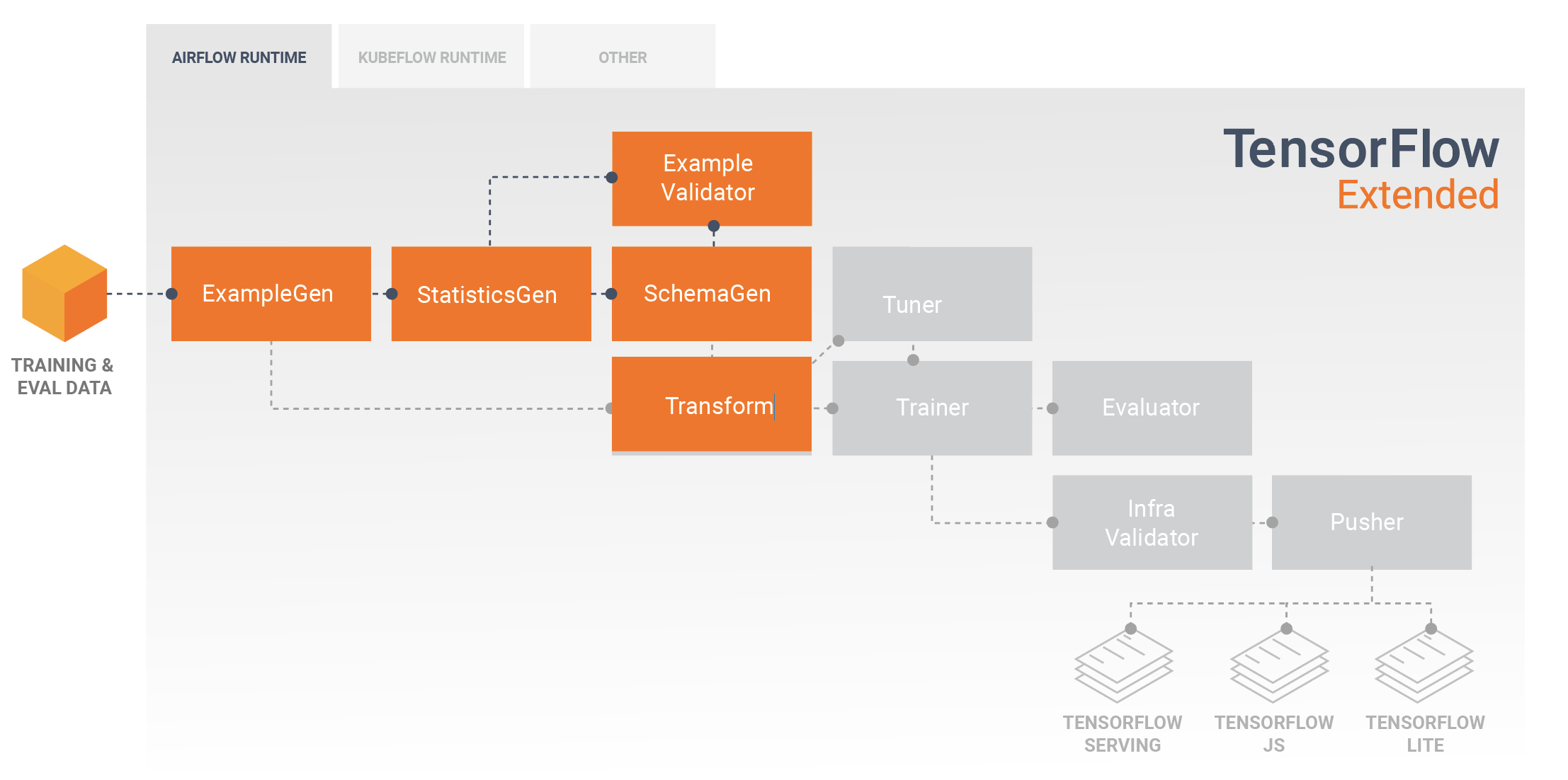
Tipik bir TFX işlem hattı, TensorFlow Transform (TFT) kütüphanesinin yeteneklerinden yararlanarak özellik mühendisliği gerçekleştirecek bir Transform bileşeni içerecektir. Transform bileşeni, SchemaGen bileşeni tarafından oluşturulan şemayı kullanır ve modelinizi eğitmek için kullanılacak özellikleri oluşturmak, birleştirmek ve dönüştürmek için veri dönüştürmelerini uygular. Çıkarım istekleri için gönderilen verilerde de mevcut olma ihtimali varsa, eksik değerlerin temizlenmesi ve türlerin dönüştürülmesi de Transform bileşeninde yapılmalıdır. TFX'te eğitim için TensorFlow kodunu tasarlarken bazı önemli hususlar vardır .
Transform bileşeninin sonucu, Trainer bileşeni sırasında TensorFlow'daki modelleme kodunuzda içe aktarılacak ve kullanılacak olan bir SavedModel'dir. Bu SavedModel, Transform bileşeninde oluşturulan tüm veri mühendisliği dönüşümlerini içerir, böylece aynı dönüşümler hem eğitim hem de çıkarım sırasında tam olarak aynı kod kullanılarak gerçekleştirilir. Transform bileşenindeki SavedModel dahil olmak üzere modelleme kodunu kullanarak eğitim ve değerlendirme verilerinizi kullanabilir ve modelinizi eğitebilirsiniz.
Tahminci tabanlı modellerle çalışırken modelleme kodunuzun son bölümü modelinizi hem SavedModel hem de EvalSavedModel olarak kaydetmelidir. EvalSavedModel olarak kaydetmek, eğitim sırasında kullanılan ölçümlerin değerlendirme sırasında da kullanılabilir olmasını sağlar (bunun keras tabanlı modeller için gerekli olmadığını unutmayın). Bir EvalSavedModel'i kaydetmek, Trainer bileşeninize TensorFlow Model Analizi (TFMA) kitaplığını içe aktarmanızı gerektirir.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
Modelin hiperparametrelerini (örn. katman sayısı) ayarlamak için Trainer'dan önce isteğe bağlı bir Tuner bileşeni eklenebilir. Verilen model ve hiperparametrelerin arama alanıyla, ayarlama algoritması hedefe dayalı en iyi hiperparametreleri bulacaktır.
Model Performansını Analiz Etme ve Anlama
İlk model geliştirme ve eğitimin ardından modelinizin performansını analiz etmek ve gerçekten anlamak önemlidir. Tipik bir TFX işlem hattı, geliştirmenin bu aşaması için güçlü bir araç seti sağlayan TensorFlow Model Analizi (TFMA) kütüphanesinin yeteneklerinden yararlanan bir Değerlendirici bileşeni içerecektir. Bir Evaluator bileşeni, yukarıda dışa aktardığınız modeli kullanır ve modelinizin performansını görselleştirirken ve analiz ederken kullanabileceğiniz bir tfma.SlicingSpec listesi belirtmenize olanak tanır. Her SlicingSpec kategorik özellikler için belirli kategoriler veya sayısal özellikler için belirli aralıklar gibi, eğitim verilerinizin incelemek istediğiniz bir dilimini tanımlar.
Örneğin bu, modelinizin müşterilerinizin farklı segmentleri için (yıllık satın alımlara, coğrafi verilere, yaş grubuna veya cinsiyete göre segmentlere ayrılabilecek) performansını anlamaya çalışmak açısından önemli olabilir. Bu, baskın bir grubun performansının önemli ancak daha küçük gruplar için kabul edilemez performansı maskeleyebileceği uzun kuyruklu veri kümeleri için özellikle önemli olabilir. Örneğin, modeliniz ortalama çalışanlar için iyi performans gösterebilir ancak yönetici personel için çok başarısız olabilir ve bunu bilmeniz sizin için önemli olabilir.
Model Analizi ve Görselleştirme
Modelinizi eğiterek ve Eğitim sonuçları üzerinde Değerlendirici bileşenini ( TFMA'dan yararlanan) çalıştırarak verilerinizin ilk çalıştırmasını tamamladıktan sonra, sonuçları Jupyter tarzı bir not defterinde görselleştirebilirsiniz. Ek çalıştırmalar için, sonuçlarınız modeliniz ve uygulamanız için en uygun olana kadar ayarlamalar yaptıkça bu sonuçları karşılaştırabilirsiniz.
Bu bileşenlerin bu uygulamalarının sonuçlarını bulmak için önce ML Meta Verilerini (MLMD) sorgulayacak ve ardından not defterinizde görselleştirmeler oluşturmak için TFMA'daki görselleştirme destek API'sini kullanacaksınız. Buna tfma.load_eval_results ve tfma.view.render_slicing_metrics dahildir. Bu görselleştirmeyi kullanarak modelinizin özelliklerini daha iyi anlayabilir ve gerekirse gerektiği gibi değiştirebilirsiniz.
Model Performansının Doğrulanması
Bir modelin performansını analiz etmenin bir parçası olarak, performansı bir temele (şu anda hizmet veren model gibi) göre doğrulamak isteyebilirsiniz. Model doğrulama, hem aday hem de temel modelin Değerlendirici bileşenine geçirilmesiyle gerçekleştirilir. Değerlendirici, karşılık gelen bir diferansiyel ölçüm seti ile birlikte hem aday hem de temel için ölçümleri (örn. AUC, kayıp) hesaplar. Daha sonra eşikler uygulanabilir ve modellerinizi üretime itmek için kullanılabilir.
Bir Modelin Sunulabileceğinin Doğrulanması
Eğitilen modeli dağıtmadan önce modelin hizmet veren altyapıda gerçekten hizmet verebilir olup olmadığını doğrulamak isteyebilirsiniz. Yeni yayınlanan modelin sistemin tahmin sunmasını engellememesini sağlamak için bu özellikle üretim ortamlarında önemlidir. InfraValidator bileşeni, modelinizin korumalı alana alınmış bir ortamda canary dağıtımını yapacak ve isteğe bağlı olarak modelinizin doğru çalıştığını kontrol etmek için gerçek istekler gönderecektir.
Dağıtım Hedefleri
Memnun kaldığınız bir modeli geliştirip eğittiğinizde, artık onu çıkarım isteklerini alacağı bir veya daha fazla dağıtım hedefine dağıtmanın zamanı geldi. TFX, üç sınıf dağıtım hedefine dağıtımı destekler. SavedModels olarak dışa aktarılan eğitimli modeller, bu dağıtım hedeflerinden herhangi birine veya tümüne dağıtılabilir.
Çıkarım: TensorFlow Sunumu
TensorFlow Serving (TFS) , üretim ortamları için tasarlanmış, makine öğrenimi modellerine yönelik esnek, yüksek performanslı bir hizmet sistemidir. Bir SavedModel tüketir ve REST veya gRPC arayüzleri üzerinden çıkarım isteklerini kabul eder. Senkronizasyon ve dağıtılmış hesaplamayı yönetmek için çeşitli gelişmiş mimarilerden birini kullanarak bir veya daha fazla ağ sunucusunda bir dizi işlem olarak çalışır. TFS çözümlerini geliştirme ve dağıtma hakkında daha fazla bilgi için TFS belgelerine bakın.
Tipik bir işlem hattında, bir Trainer bileşeninde eğitilmiş bir SavedModel, ilk olarak bir InfraValidator bileşeninde alt-doğrulama işlemine tabi tutulur. InfraValidator, SavedModel'e gerçekten hizmet verecek bir kanarya TFS model sunucusunu başlatır. Doğrulama başarılı olursa, bir Pusher bileşeni sonunda SavedModel'i TFS altyapınıza dağıtır. Bu, birden fazla sürümün ve model güncellemelerinin ele alınmasını içerir.
Yerel Mobil ve IoT Uygulamalarında Çıkarım: TensorFlow Lite
TensorFlow Lite, geliştiricilerin eğitimli TensorFlow Modellerini yerel mobil ve IoT uygulamalarında kullanmalarına yardımcı olmaya adanmış bir araç paketidir. TensorFlow Serving ile aynı SavedModels'ı kullanır ve mobil ve IoT cihazlarda çalıştırma zorluklarına karşı ortaya çıkan modellerin boyutunu ve performansını optimize etmek için niceleme ve budama gibi optimizasyonlar uygular. TensorFlow Lite kullanımı hakkında daha fazla bilgi için TensorFlow Lite belgelerine bakın.
JavaScript'te Çıkarım: TensorFlow JS
TensorFlow JS, ML modellerini tarayıcıda ve Node.js'de eğitmeye ve dağıtmaya yönelik bir JavaScript kitaplığıdır. TensorFlow Serving ve TensorFlow Lite ile aynı SavedModels'ı kullanır ve bunları TensorFlow.js Web biçimine dönüştürür. TensorFlow JS'nin kullanımına ilişkin daha fazla ayrıntı için TensorFlow JS belgelerine bakın.
Hava Akışlı TFX Boru Hattı Oluşturma
Ayrıntılar için hava akışı atölyesini kontrol edin
Kubeflow ile TFX Ardışık Düzeni Oluşturma
Kurmak
Kubeflow, işlem hatlarını uygun ölçekte çalıştırmak için bir Kubernetes kümesi gerektirir. Kubeflow kümesini dağıtma seçeneklerine rehberlik eden Kubeflow dağıtım kılavuzuna bakın.
TFX işlem hattını yapılandırma ve çalıştırma
Kubeflow'ta TFX örnek işlem hattını çalıştırmak için lütfen Bulut Yapay Zeka Platformu İşlem Hattı üzerinde TFX eğitimini izleyin. TFX bileşenleri, Kubeflow işlem hattını oluşturmak için kapsayıcıya alınmıştır ve örnek, işlem hattının büyük genel veri kümesini okuyacak ve bulutta uygun ölçekte eğitim ve veri işleme adımlarını yürütecek şekilde yapılandırılma yeteneğini göstermektedir.
Boru hattı eylemleri için komut satırı arayüzü
TFX, Apache Airflow, Apache Beam ve Kubeflow dahil olmak üzere çeşitli orkestratörlerde işlem hatları oluşturma, güncelleme, çalıştırma, listeleme ve silme gibi tüm işlem hattı eylemlerini gerçekleştirmeye yardımcı olan birleşik bir CLI sağlar. Ayrıntılar için lütfen bu talimatları izleyin.