
Les pipelines TFX vous permettent d'orchestrer votre flux de travail de machine learning (ML) sur des orchestrateurs, tels que : Apache Airflow, Apache Beam et Kubeflow Pipelines. Les pipelines organisent votre flux de travail en une séquence de composants, où chaque composant effectue une étape de votre flux de travail ML. Les composants standard TFX offrent des fonctionnalités éprouvées pour vous aider à démarrer facilement la création d'un flux de travail ML. Vous pouvez également inclure des composants personnalisés dans votre flux de travail. Les composants personnalisés vous permettent d'étendre votre flux de travail ML en :
- Créer des composants adaptés à vos besoins, comme l'ingestion de données à partir d'un système propriétaire.
- Application d’une augmentation, d’un suréchantillonnage ou d’un sous-échantillonnage des données.
- Effectuez une détection d’anomalies basée sur des intervalles de confiance ou une erreur de reproduction de l’encodeur automatique.
- Interface avec des systèmes externes tels que les services d'assistance pour les alertes et la surveillance.
- Application d'étiquettes à des exemples non étiquetés.
- Intégrer des outils construits avec des langages autres que Python dans votre flux de travail ML, comme effectuer une analyse de données à l'aide de R.
En mélangeant des composants standards et des composants personnalisés, vous pouvez créer un workflow ML qui répond à vos besoins tout en profitant des meilleures pratiques intégrées aux composants standards TFX.
Ce guide décrit les concepts requis pour comprendre les composants personnalisés TFX et les différentes manières de créer des composants personnalisés.
Anatomie d'un composant TFX
Cette section fournit un aperçu général de la composition d'un composant TFX. Si vous débutez avec les pipelines TFX, découvrez les concepts de base en lisant le guide pour comprendre les pipelines TFX .
Les composants TFX sont composés d'une spécification de composant et d'une classe d'exécuteur qui sont regroupées dans une classe d'interface de composant.
Une spécification de composant définit le contrat d'entrée et de sortie du composant. Ce contrat spécifie les artefacts d'entrée et de sortie du composant, ainsi que les paramètres utilisés pour l'exécution du composant.
La classe exécuteur d'un composant fournit l'implémentation du travail effectué par le composant.
Une classe d'interface de composant combine la spécification du composant avec l'exécuteur pour une utilisation en tant que composant dans un pipeline TFX.
Composants TFX au moment de l'exécution
Lorsqu'un pipeline exécute un composant TFX, le composant est exécuté en trois phases :
- Tout d'abord, le pilote utilise la spécification du composant pour récupérer les artefacts requis du magasin de métadonnées et les transmettre au composant.
- Ensuite, l'exécuteur effectue le travail du composant.
- Ensuite, l'éditeur utilise la spécification du composant et les résultats de l'exécuteur pour stocker les sorties du composant dans le magasin de métadonnées.
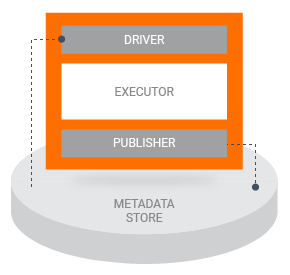
La plupart des implémentations de composants personnalisés ne nécessitent pas de personnaliser le pilote ou l'éditeur. En règle générale, des modifications du pilote et de l'éditeur ne devraient être nécessaires que si vous souhaitez modifier l'interaction entre les composants de votre pipeline et le magasin de métadonnées. Si vous souhaitez uniquement modifier les entrées, les sorties ou les paramètres de votre composant, il vous suffit de modifier la spécification du composant .
Types de composants personnalisés
Il existe trois types de composants personnalisés : les composants basés sur des fonctions Python, les composants basés sur des conteneurs et les composants entièrement personnalisés. Les sections suivantes décrivent les différents types de composants et les cas dans lesquels vous devez utiliser chaque approche.
Composants basés sur des fonctions Python
Les composants basés sur des fonctions Python sont plus faciles à créer que les composants basés sur des conteneurs ou les composants entièrement personnalisés. La spécification du composant est définie dans les arguments de la fonction Python à l'aide d'annotations de type qui décrivent si un argument est un artefact d'entrée, un artefact de sortie ou un paramètre. Le corps de la fonction définit l'exécuteur du composant. L'interface du composant est définie en ajoutant le décorateur @component à votre fonction.
En décorant votre fonction avec le décorateur @component et en définissant les arguments de la fonction avec des annotations de type, vous pouvez créer un composant sans la complexité liée à la création d'une spécification de composant, d'un exécuteur et d'une interface de composant.
Apprenez à créer des composants basés sur des fonctions Python .
Composants basés sur des conteneurs
Les composants basés sur des conteneurs offrent la flexibilité nécessaire pour intégrer du code écrit dans n'importe quel langage dans votre pipeline, à condition que vous puissiez exécuter ce code dans un conteneur Docker. Pour créer un composant basé sur un conteneur, vous devez créer une image de conteneur Docker contenant le code exécutable de votre composant. Ensuite vous devez appeler la fonction create_container_component pour définir :
- Les entrées, sorties et paramètres de la spécification de votre composant.
- L'image du conteneur et la commande que l'exécuteur du composant exécute.
Cette fonction renvoie une instance d'un composant que vous pouvez inclure dans votre définition de pipeline.
Cette approche est plus complexe que la création d'un composant basé sur des fonctions Python, car elle nécessite de conditionner votre code sous forme d'image de conteneur. Cette approche est la plus adaptée pour inclure du code non Python dans votre pipeline ou pour créer des composants Python avec des environnements d'exécution ou des dépendances complexes.
Découvrez comment créer des composants basés sur des conteneurs .
Composants entièrement personnalisés
Les composants entièrement personnalisés vous permettent de créer des composants en définissant la spécification du composant, l'exécuteur et les classes d'interface du composant. Cette approche vous permet de réutiliser et d'étendre un composant standard pour répondre à vos besoins.
Si un composant existant est défini avec les mêmes entrées et sorties que le composant personnalisé que vous développez, vous pouvez simplement remplacer la classe Executor du composant existant. Cela signifie que vous pouvez réutiliser une spécification de composant et implémenter un nouvel exécuteur dérivé d'un composant existant. De cette façon, vous réutilisez les fonctionnalités intégrées aux composants existants et implémentez uniquement les fonctionnalités requises.
Si toutefois les entrées et sorties de votre nouveau composant sont uniques, vous pouvez définir une toute nouvelle spécification de composant .
Cette approche est la meilleure pour réutiliser les spécifications et les exécuteurs de composants existants.
Apprenez à créer des composants entièrement personnalisés .