
Gdy dane znajdą się w potoku TFX, możesz użyć komponentów TFX do ich analizy i transformacji. Z tych narzędzi można korzystać jeszcze przed wytrenowaniem modelu.
Istnieje wiele powodów, dla których warto analizować i przekształcać dane:
- Aby znaleźć problemy w danych. Typowe problemy obejmują:
- Brakujące dane, np. obiekty z pustymi wartościami.
- Etykiety traktowane jako funkcje, dzięki czemu Twój model może podejrzeć właściwą odpowiedź podczas szkolenia.
- Funkcje z wartościami spoza oczekiwanego zakresu.
- Anomalie danych.
- Model wyuczony transferu ma przetwarzanie wstępne, które nie jest zgodne z danymi szkoleniowymi.
- Aby zaprojektować bardziej efektywne zestawy funkcji. Można na przykład zidentyfikować:
- Szczególnie funkcje informacyjne.
- Nadmiarowe funkcje.
- Funkcje o tak dużej skali, że mogą spowolnić proces uczenia się.
- Funkcje z niewielką ilością unikalnych informacji predykcyjnych lub bez nich.
Narzędzia TFX mogą zarówno pomóc w znalezieniu błędów w danych, jak i pomóc w inżynierii funkcji.
Walidacja danych TensorFlow
- Przegląd
- Walidacja przykładu na podstawie schematu
- Wykrywanie pochylenia w zakresie szkolenia
- Wykrywanie dryfu
Przegląd
Walidacja danych TensorFlow identyfikuje anomalie w szkoleniu i udostępnianiu danych oraz może automatycznie utworzyć schemat na podstawie sprawdzenia danych. Komponent można skonfigurować tak, aby wykrywał różne klasy anomalii w danych. To może
- Przeprowadzaj kontrole ważności, porównując statystyki danych ze schematem, który kodyfikuje oczekiwania użytkownika.
- Wykrywaj odchylenia w zakresie szkolenia i udostępniania, porównując przykłady w danych szkoleniowych i udostępniających.
- Wykryj dryf danych, analizując serię danych.
Każdą z tych funkcjonalności dokumentujemy niezależnie:
- Walidacja przykładu na podstawie schematu
- Wykrywanie pochylenia w zakresie szkolenia
- Wykrywanie dryfu
Walidacja przykładu na podstawie schematu
Walidacja danych TensorFlow identyfikuje wszelkie anomalie w danych wejściowych poprzez porównanie statystyk danych ze schematem. Schemat koduje właściwości, które mają spełniać dane wejściowe, takie jak typy danych lub wartości kategoryczne, i może być modyfikowany lub zastępowany przez użytkownika.
Walidacja danych Tensorflow jest zwykle wywoływana wielokrotnie w kontekście potoku TFX: (i) dla każdego podziału uzyskanego z PrzykładGen, (ii) dla wszystkich wstępnie przekształconych danych używanych przez Transform oraz (iii) dla wszystkich danych po transformacji wygenerowanych przez Przekształcać. Po wywołaniu w kontekście Transform (ii-iii) opcje statystyczne i ograniczenia oparte na schemacie można ustawić, definiując stats_options_updater_fn . Jest to szczególnie przydatne podczas sprawdzania poprawności danych nieustrukturyzowanych (np. cech tekstowych). Zobacz przykładowy kod użytkownika .
Zaawansowane funkcje schematu
W tej sekcji opisano bardziej zaawansowaną konfigurację schematu, która może pomóc w przypadku konfiguracji specjalnych.
Rzadkie funkcje
Kodowanie rzadkich funkcji w przykładach zwykle wprowadza wiele funkcji, które mają mieć tę samą wartościowość we wszystkich przykładach. Na przykład rzadka funkcja:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
Definicja cechy rzadkiej wymaga jednego lub więcej cech indeksowych i wartościowych, które odnoszą się do cech istniejących w schemacie. Jawne zdefiniowanie rzadkich cech umożliwia TFDV sprawdzenie, czy wartościowości wszystkich odnośnych cech są zgodne.
Niektóre przypadki użycia wprowadzają podobne ograniczenia wartościowości między funkcjami, ale niekoniecznie kodują rzadką funkcję. Korzystanie z funkcji rzadkiej powinno cię odblokować, ale nie jest idealne.
Środowiska schematów
Domyślnie w walidacjach zakłada się, że wszystkie przykłady w potoku są zgodne z jednym schematem. W niektórych przypadkach konieczne jest wprowadzenie niewielkich zmian w schemacie, na przykład funkcje używane jako etykiety są wymagane podczas szkolenia (i powinny zostać sprawdzone), ale brakuje ich podczas udostępniania. Do wyrażenia takich wymagań można użyć środowisk, w szczególności default_environment() , in_environment() , not_in_environment() .
Załóżmy na przykład, że funkcja o nazwie „LABEL” jest wymagana do trenowania, ale prawdopodobnie nie będzie wyświetlana. Można to wyrazić poprzez:
- Zdefiniuj w schemacie dwa różne środowiska: ["SERWING", "SZKOLENIE"] i skojarz "LABEL" tylko ze środowiskiem "SZKOLENIE".
- Powiąż dane szkoleniowe ze środowiskiem „TRAINING”, a dane udostępniające ze środowiskiem „SERVING”.
Generacja schematu
Schemat danych wejściowych jest określony jako instancja schematu TensorFlow.
Zamiast ręcznie konstruować schemat od podstaw, programista może polegać na automatycznej konstrukcji schematu TensorFlow Data Validation. W szczególności funkcja sprawdzania poprawności danych TensorFlow automatycznie konstruuje początkowy schemat na podstawie statystyk obliczonych na podstawie danych szkoleniowych dostępnych w potoku. Użytkownicy mogą po prostu przejrzeć ten automatycznie wygenerowany schemat, zmodyfikować go w razie potrzeby, sprawdzić w systemie kontroli wersji i przekazać go bezpośrednio do potoku w celu dalszej weryfikacji.
TFDV zawiera infer_schema() do automatycznego generowania schematu. Na przykład:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Spowoduje to automatyczne wygenerowanie schematu w oparciu o następujące reguły:
Jeśli schemat został już wygenerowany automatycznie, zostanie użyty w niezmienionej postaci.
W przeciwnym razie funkcja sprawdzania poprawności danych TensorFlow sprawdza dostępne statystyki danych i oblicza odpowiedni schemat dla danych.
Uwaga: schemat wygenerowany automatycznie jest najlepszym rozwiązaniem i stara się jedynie wywnioskować podstawowe właściwości danych. Oczekuje się, że użytkownicy będą go przeglądać i modyfikować w razie potrzeby.
Wykrywanie pochylenia w zakresie szkolenia
Przegląd
Walidacja danych TensorFlow może wykryć zniekształcenie dystrybucji między danymi szkoleniowymi i udostępnianymi. Skośność rozkładu występuje, gdy rozkład wartości funkcji dla danych szkoleniowych znacznie różni się od danych udostępnianych. Jedną z kluczowych przyczyn odchylenia rozkładu jest użycie zupełnie innego korpusu do generowania danych szkoleniowych w celu przezwyciężenia braku danych początkowych w pożądanym korpusie. Innym powodem jest wadliwy mechanizm próbkowania, który wybiera tylko podpróbkę udostępnianych danych do trenowania.
Przykładowy scenariusz
Zobacz Przewodnik wprowadzający dotyczący sprawdzania poprawności danych TensorFlow, aby uzyskać informacje na temat konfigurowania wykrywania skosu obsługującego szkolenie.
Wykrywanie dryfu
Obsługiwane jest wykrywanie dryftu pomiędzy kolejnymi zakresami danych (tj. pomiędzy zakresem N i zakresem N+1), na przykład pomiędzy różnymi dniami danych szkoleniowych. Dryf wyrażamy w kategoriach odległości L-nieskończoności dla cech kategorycznych i przybliżonej rozbieżności Jensena-Shannona dla cech numerycznych. Możesz ustawić odległość progową, aby otrzymywać ostrzeżenia, gdy dryft jest wyższy niż akceptowalny. Ustawianie prawidłowej odległości jest zazwyczaj procesem iteracyjnym wymagającym wiedzy dziedzinowej i eksperymentowania.
Aby uzyskać informacje na temat konfigurowania wykrywania dryftu, zobacz Przewodnik wprowadzający dotyczący sprawdzania poprawności danych TensorFlow .
Używanie wizualizacji do sprawdzania danych
Walidacja danych TensorFlow zapewnia narzędzia do wizualizacji rozkładu wartości funkcji. Badając te rozkłady w notatniku Jupyter za pomocą Facets, możesz wychwycić typowe problemy z danymi.
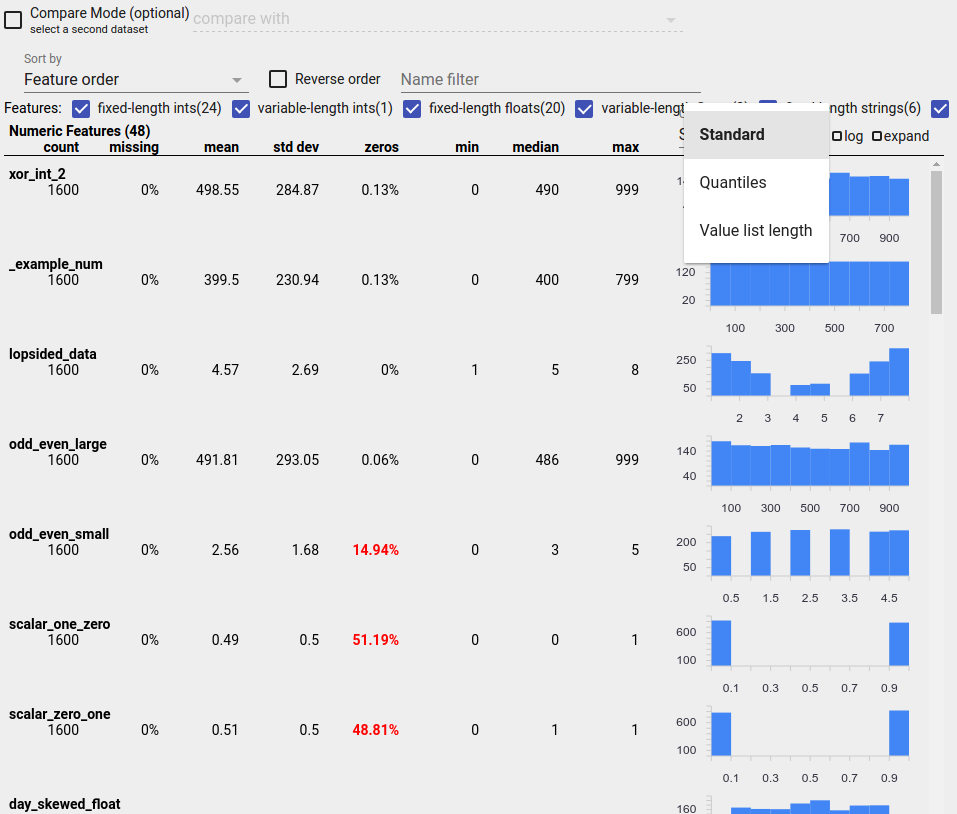
Identyfikowanie podejrzanych dystrybucji
Możesz zidentyfikować typowe błędy w danych, korzystając z ekranu Przegląd aspektów, aby wyszukać podejrzane rozkłady wartości funkcji.
Niezrównoważone dane
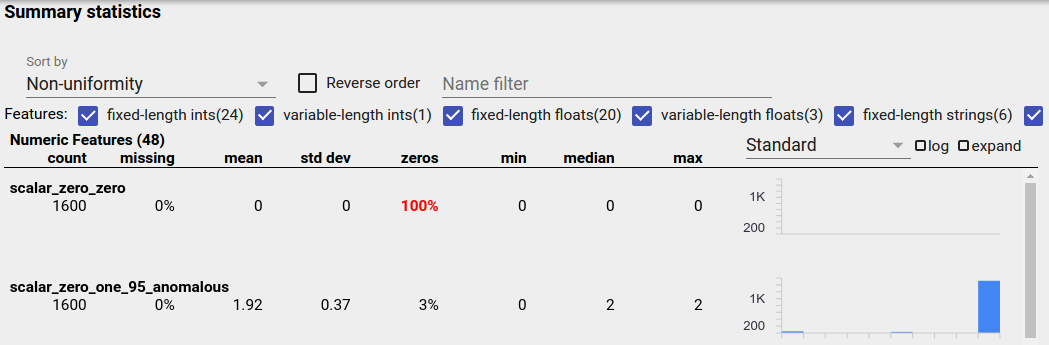
Cecha niezrównoważona to cecha, dla której dominuje jedna wartość. Niezrównoważone funkcje mogą występować naturalnie, ale jeśli funkcja ma zawsze tę samą wartość, może wystąpić błąd w danych. Aby wykryć niezrównoważone cechy w przeglądzie aspektów, wybierz opcję „Niejednorodność” z listy rozwijanej „Sortuj według”.
Najbardziej niezrównoważone funkcje zostaną wyświetlone na górze każdej listy typów funkcji. Na przykład poniższy zrzut ekranu przedstawia jedną funkcję składającą się wyłącznie z zer i drugą, która jest wysoce niezrównoważona, na górze listy „Funkcje numeryczne”:
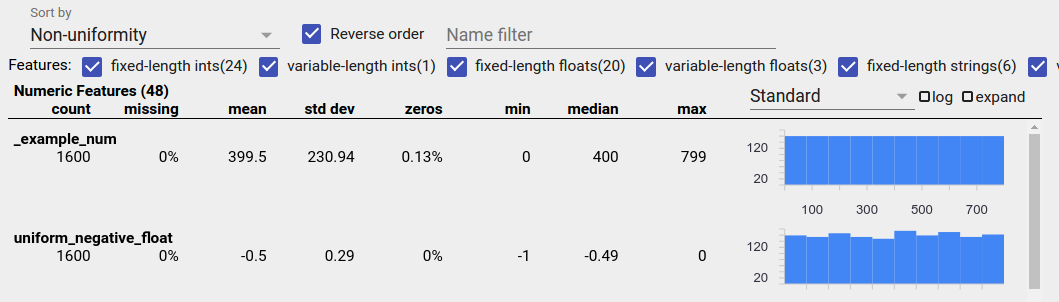
Jednolicie rozproszone dane
Cecha o rozkładzie równomiernie to taka, dla której wszystkie możliwe wartości pojawiają się z niemal tą samą częstotliwością. Podobnie jak w przypadku danych niezrównoważonych, dystrybucja ta może wystąpić naturalnie, ale może być również spowodowana błędami w danych.
Aby wykryć równomiernie rozłożone cechy w Przeglądzie aspektów, wybierz opcję „Niejednorodność” z listy rozwijanej „Sortuj według” i zaznacz pole wyboru „Odwróć kolejność”:
Dane łańcuchowe są reprezentowane za pomocą wykresów słupkowych, jeśli istnieje 20 lub mniej unikalnych wartości, oraz jako wykres rozkładu skumulowanego, jeśli istnieje więcej niż 20 unikalnych wartości. Zatem w przypadku danych łańcuchowych rozkłady równomierne mogą być wyświetlane w postaci płaskich wykresów słupkowych, jak ten powyżej, lub linii prostych, jak poniżej:

Błędy, które mogą generować równomiernie rozproszone dane
Oto kilka typowych błędów, które mogą powodować równomierne rozłożenie danych:
Używanie ciągów do reprezentowania typów danych innych niż ciągi, takich jak daty. Na przykład będziesz mieć wiele unikalnych wartości dla funkcji datetime z reprezentacjami takimi jak „2017-03-01-11-45-03”. Unikalne wartości będą dystrybuowane równomiernie.
Uwzględnij indeksy takie jak „numer wiersza” jako funkcje. Tutaj znowu masz wiele unikalnych wartości.
Brakujące dane
Aby sprawdzić, czy w obiekcie całkowicie brakuje wartości:
- Z listy rozwijanej „Sortuj według” wybierz opcję „Brakująca kwota/zero”.
- Zaznacz pole wyboru „Odwróć kolejność”.
- Spójrz na kolumnę „brakujące”, aby zobaczyć procent wystąpień z brakującymi wartościami dla danej funkcji.
Błąd danych może również powodować niekompletne wartości funkcji. Na przykład możesz spodziewać się, że lista wartości funkcji będzie zawsze zawierać trzy elementy, a czasami okaże się, że zawiera tylko jeden. Aby sprawdzić niekompletne wartości lub inne przypadki, w których listy wartości funkcji nie zawierają oczekiwanej liczby elementów:
Z menu rozwijanego „Wykres do pokazania” po prawej stronie wybierz opcję „Długość listy wartości”.
Spójrz na wykres po prawej stronie każdego wiersza funkcji. Wykres pokazuje zakres długości list wartości dla tej funkcji. Na przykład podświetlony wiersz na zrzucie ekranu poniżej przedstawia funkcję zawierającą listy wartości o zerowej długości:

Duże różnice w skali pomiędzy obiektami
Jeśli Twoje funkcje różnią się znacznie pod względem skali, model może mieć trudności z nauką. Na przykład, jeśli niektóre cechy różnią się od 0 do 1, a inne od 0 do 1 000 000 000, różnica w skali jest duża. Porównaj kolumny „maks.” i „min.” w różnych funkcjach, aby znaleźć bardzo zróżnicowane skale.
Rozważ normalizację wartości cech, aby zmniejszyć te duże różnice.
Etykiety z nieprawidłowymi etykietami
Estymatory TensorFlow mają ograniczenia dotyczące rodzaju danych, które akceptują jako etykiety. Na przykład klasyfikatory binarne zazwyczaj działają tylko z etykietami {0, 1}.
Przejrzyj wartości etykiet w Przeglądzie aspektów i upewnij się, że są zgodne z wymaganiami Estymatorów .