
ברגע שהנתונים שלך נמצאים בצינור TFX, אתה יכול להשתמש ברכיבי TFX כדי לנתח ולשנות אותם. אתה יכול להשתמש בכלים האלה עוד לפני שאתה מכשיר מודל.
ישנן סיבות רבות לנתח ולשנות את הנתונים שלך:
- כדי למצוא בעיות בנתונים שלך. בעיות נפוצות כוללות:
- נתונים חסרים, כגון תכונות עם ערכים ריקים.
- תוויות מטופלות כאל תכונות, כך שהדוגמנית שלך תוכל להציץ בתשובה הנכונה במהלך האימון.
- תכונות עם ערכים מחוץ לטווח שאתה מצפה.
- חריגות נתונים.
- למודל העברה למד יש עיבוד מקדים שאינו תואם את נתוני האימון.
- להנדס מערכי תכונות יעילים יותר. לדוגמה, אתה יכול לזהות:
- תכונות אינפורמטיביות במיוחד.
- תכונות מיותרות.
- תכונות שונות כל כך בקנה מידה שהן עשויות להאט את הלמידה.
- תכונות עם מעט או ללא מידע חיזוי ייחודי.
כלי TFX יכולים גם לעזור למצוא באגים בנתונים וגם לעזור בהנדסת תכונות.
אימות נתונים של TensorFlow
סקירה כללית
TensorFlow Data Validation מזהה חריגות בנתוני ההדרכה וההגשה, ויכול ליצור סכימה באופן אוטומטי על ידי בחינת הנתונים. ניתן להגדיר את הרכיב כדי לזהות מחלקות שונות של חריגות בנתונים. זה יכול
- בצע בדיקות תקפות על ידי השוואת נתונים סטטיסטיים מול סכימה שמקודדת את הציפיות מהמשתמש.
- זיהוי הטיית אימון-הגשה על-ידי השוואה של דוגמאות בנתוני הדרכה והגשה.
- זיהוי סחיפת נתונים על ידי התבוננות בסדרת נתונים.
אנו מתעדים כל אחת מהפונקציות הללו באופן עצמאי:
אימות דוגמה מבוסס סכמה
TensorFlow Data Validation מזהה חריגות כלשהן בנתוני הקלט על ידי השוואת נתונים סטטיסטיים מול סכימה. הסכימה מקודדת מאפיינים שנתוני הקלט צפויים לעמוד בהם, כגון סוגי נתונים או ערכים קטגוריים, וניתן לשנות או להחליף על ידי המשתמש.
אימות נתונים של Tensorflow מופעל בדרך כלל מספר פעמים בהקשר של צינור ה-TFX: (i) עבור כל פיצול המתקבל מ-ExampleGen, (ii) עבור כל הנתונים שעברו טרנספורמציה המשמשים את Transform ו-(iii) עבור כל הנתונים שלאחר ההמרה שנוצרו על ידי לְשַׁנוֹת. כאשר מופעל בהקשר של Transform (ii-iii), ניתן להגדיר אפשרויות סטטיסטיקה ואילוצים מבוססי סכימה על ידי הגדרת ה- stats_options_updater_fn . זה שימושי במיוחד בעת אימות נתונים לא מובנים (למשל תכונות טקסט). עיין בקוד המשתמש לדוגמא.
תכונות סכימה מתקדמות
סעיף זה מכסה תצורת סכימה מתקדמת יותר שיכולה לעזור בהגדרות מיוחדות.
תכונות דלילות
קידוד תכונות דלילות בדוגמאות בדרך כלל מציג תכונות מרובות שצפויות להיות בעלות אותה ערכיות עבור כל הדוגמאות. למשל התכונה הדלילה:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
הגדרת התכונה הדלילה דורשת תכונה אחת או יותר של אינדקס וערך אחד המתייחסים לתכונות הקיימות בסכימה. הגדרה מפורשת של תכונות דלילות מאפשרת ל-TFDV לבדוק שהערכיות של כל התכונות המופנות תואמות.
מקרי שימוש מסוימים מציגים הגבלות ערך דומות בין תכונות, אך לא בהכרח מקודדות תכונה דלילה. שימוש בתכונה דלילה אמור לבטל את החסימה, אך אינו אידיאלי.
סביבות סכימה
כברירת מחדל, אימותים מניחים שכל הדוגמאות בצנרת תואמות לסכימה אחת. במקרים מסוימים יש צורך להציג שינויים קלים בסכימה, למשל תכונות המשמשות כתוויות נדרשות במהלך ההדרכה (וצריך לאמתן), אך הן חסרות במהלך ההגשה. ניתן להשתמש בסביבות כדי לבטא דרישות כאלה, במיוחד default_environment() , in_environment() , not_in_environment() .
לדוגמה, נניח שתכונה בשם 'LABEL' נדרשת להדרכה, אך צפויה להיעדר בהגשה. זה יכול להתבטא ב:
- הגדר שתי סביבות נפרדות בסכמה: ["SERVING", "TRAINING"] ושייך את 'LABEL' רק לסביבה "TRAINING".
- שייך את נתוני ההדרכה לסביבה "TRAINING" ואת נתוני ההגשה לסביבה "SERVING".
יצירת סכימה
סכימת נתוני הקלט מצוינת כמופע של TensorFlow Schema .
במקום לבנות סכימה ידנית מאפס, מפתח יכול להסתמך על בניית הסכימה האוטומטית של TensorFlow Data Validation. באופן ספציפי, TensorFlow Data Validation בונה אוטומטית סכימה ראשונית המבוססת על נתונים סטטיסטיים המחושבים על פי נתוני אימון הזמינים בצנרת. משתמשים יכולים פשוט לעיין בסכימה שנוצרה אוטומטית זו, לשנות אותה לפי הצורך, לבדוק אותה למערכת בקרת גרסאות, ולדחוף אותה במפורש לצינור לצורך אימות נוסף.
TFDV כולל infer_schema() ליצירת סכימה באופן אוטומטי. לְדוּגמָה:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
זה מפעיל יצירת סכימה אוטומטית המבוססת על הכללים הבאים:
אם סכימה כבר נוצרה אוטומטית, היא משמשת כפי שהיא.
אחרת, TensorFlow Data Validation בוחן את הנתונים הסטטיסטיים הזמינים ומחשב סכימה מתאימה עבור הנתונים.
הערה: הסכימה שנוצרה אוטומטית היא במאמץ הטוב ביותר ומנסה רק להסיק מאפיינים בסיסיים של הנתונים. צפוי שמשתמשים יבדקו וישנו אותו לפי הצורך.
איתור הטיות של אימון-הגשה
סקירה כללית
אימות נתונים של TensorFlow יכול לזהות הטיית התפלגות בין נתוני אימון להגשה. הטיית התפלגות מתרחשת כאשר התפלגות ערכי תכונה עבור נתוני אימון שונה באופן משמעותי מנתוני הגשה. אחת הסיבות העיקריות להטיית הפצה היא שימוש בקורפוס שונה לחלוטין ליצירת נתונים כדי להתגבר על חוסר בנתונים ראשוניים בקורפוס הרצוי. סיבה נוספת היא מנגנון דגימה פגום שבוחר רק תת-דגימה של נתוני ההגשה להתאמן עליו.
תרחיש לדוגמה
עיין במדריך תחילת העבודה לאימות נתונים של TensorFlow למידע על קביעת תצורה של זיהוי הטיה בשרת אימונים.
זיהוי סחיפה
זיהוי סחיפה נתמך בין טווחי נתונים עוקבים (כלומר, בין טווח N לטווח N+1), כגון בין ימי אימון שונים. אנו מבטאים סחף במונחים של מרחק L-אינסוף עבור מאפיינים קטגוריים והסתייגות משוערת של Jensen-Shannon עבור תכונות מספריות. אתה יכול להגדיר את מרחק הסף כך שתקבל אזהרות כאשר הסחף גבוה מהמקובל. הגדרת המרחק הנכון היא בדרך כלל תהליך איטרטיבי הדורש ידע וניסוי בתחום.
עיין במדריך לתחילת העבודה של TensorFlow Data Validation לקבלת מידע על הגדרת זיהוי סחיפה.
שימוש בהדמיות לבדיקת הנתונים שלך
TensorFlow Data Validation מספק כלים להמחשת התפלגות ערכי תכונות. על ידי בחינת ההפצות הללו במחברת Jupyter באמצעות Facets תוכל לתפוס בעיות נפוצות עם נתונים.
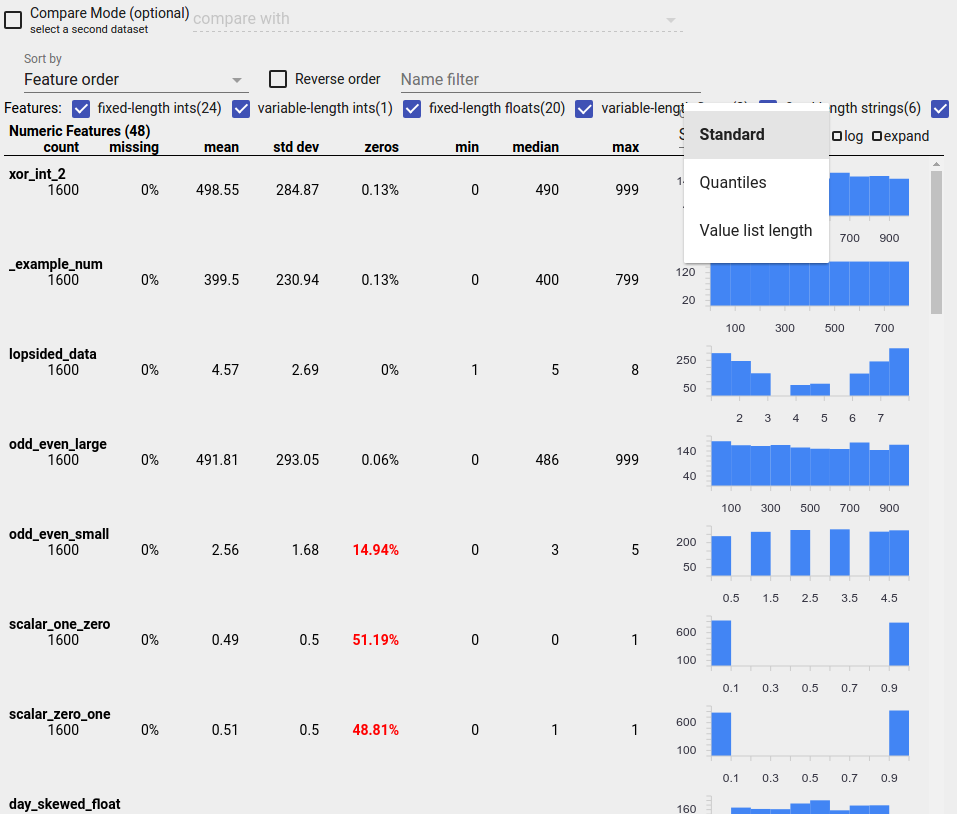
זיהוי הפצות חשודות
אתה יכול לזהות באגים נפוצים בנתונים שלך על ידי שימוש בתצוגת סקירת פנים כדי לחפש הפצות חשודות של ערכי תכונה.
נתונים לא מאוזנים
תכונה לא מאוזנת היא תכונה שערך אחד שולט בה. תכונות לא מאוזנות יכולות להתרחש באופן טבעי, אבל אם לתכונה יש תמיד אותו ערך ייתכן שיש לך באג נתונים. כדי לזהות תכונות לא מאוזנות בסקירת היבטים, בחר "אי אחידות" מהתפריט הנפתח "מיין לפי".
התכונות הכי לא מאוזנות יופיעו בראש כל רשימה מסוג תכונה. לדוגמה, צילום המסך הבא מציג תכונה אחת שכולה אפסים, ושנייה שהיא מאוד לא מאוזנת, בראש הרשימה "תכונות מספריות":
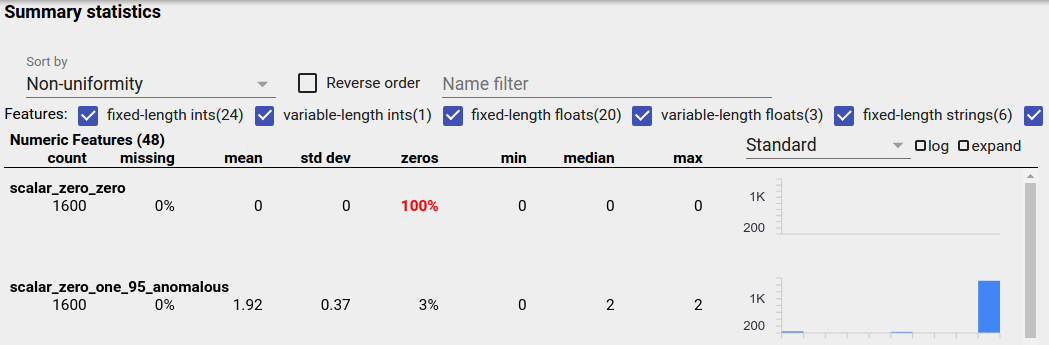
נתונים בחלוקה אחידה
תכונה בחלוקה אחידה היא תכונה שעבורה כל הערכים האפשריים מופיעים קרוב לאותה תדירות. כמו בנתונים לא מאוזנים, התפלגות זו יכולה להתרחש באופן טבעי, אך יכולה להיווצר גם על ידי באגי נתונים.
כדי לזהות תכונות בחלוקה אחידה בסקירת היבטים, בחר "אי אחידות" מהתפריט הנפתח "מיין לפי" וסמן את תיבת הסימון "סדר הפוך":
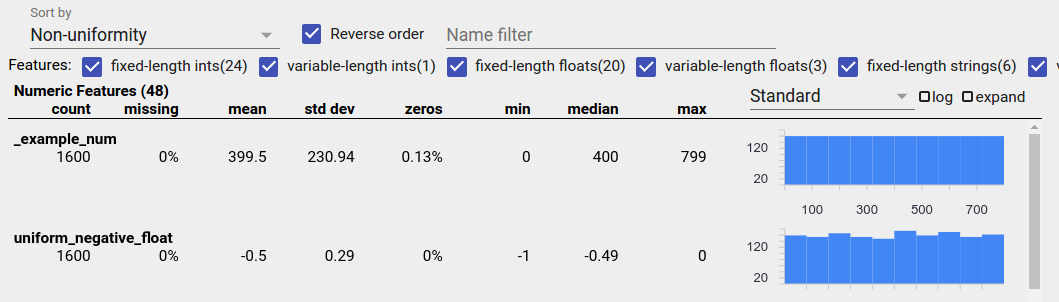
נתוני מחרוזת מיוצגים באמצעות תרשימי עמודות אם יש 20 ערכים ייחודיים או פחות, וכגרף התפלגות מצטבר אם יש יותר מ-20 ערכים ייחודיים. אז עבור נתוני מחרוזת, התפלגויות אחידות יכולות להופיע כגרפים שטוחים כמו זה שלמעלה או קווים ישרים כמו זה למטה:

באגים שיכולים לייצר נתונים בחלוקה אחידה
הנה כמה באגים נפוצים שיכולים לייצר נתונים בחלוקה אחידה:
שימוש במחרוזות לייצוג סוגי נתונים שאינם מחרוזים כגון תאריכים. לדוגמה, יהיו לך ערכים ייחודיים רבים עבור תכונת תאריך ושעה עם ייצוגים כמו "2017-03-01-11-45-03". ערכים ייחודיים יחולקו באופן אחיד.
כולל מדדים כמו "מספר שורה" כמאפיינים. כאן שוב יש לך ערכים ייחודיים רבים.
נתונים חסרים
כדי לבדוק אם בתכונה חסרים ערכים לחלוטין:
- בחר "כמות חסר/אפס" מהתפריט הנפתח "מיין לפי".
- סמן את תיבת הסימון "סדר הפוך".
- עיין בעמודה "חסר" כדי לראות את אחוז המופעים עם ערכים חסרים עבור תכונה.
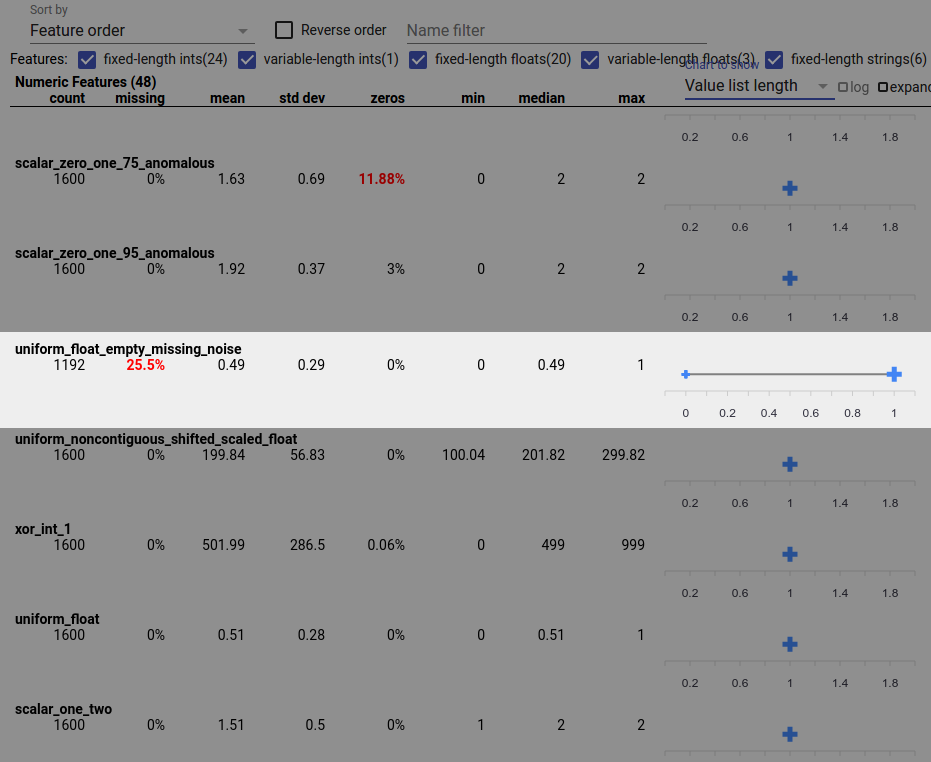
באג נתונים יכול גם לגרום לערכי תכונה לא שלמים. לדוגמה, ייתכן שתצפה שרשימת הערכים של תכונה תכלול תמיד שלושה אלמנטים ותגלה שלפעמים יש לה רק אחד. כדי לבדוק אם קיימים ערכים לא שלמים או מקרים אחרים שבהם רשימות ערכי תכונות אינן כוללות את המספר הצפוי של רכיבים:
בחר "אורך רשימת ערכים" מהתפריט הנפתח "תרשים להצגה" בצד ימין.
התבונן בתרשים מימין לכל שורת תכונה. התרשים מציג את טווח אורכי רשימת הערכים עבור התכונה. לדוגמה, השורה המודגשת בצילום המסך שלהלן מציגה תכונה שיש לה כמה רשימות ערכים באורך אפס:
הבדלים גדולים בקנה מידה בין תכונות
אם המאפיינים שלך משתנים מאוד בקנה מידה, אז המודל עשוי להתקשות בלמידה. לדוגמה, אם תכונות מסוימות משתנות מ-0 ל-1 ואחרות משתנות מ-0 ל-1,000,000,000, יש לך הבדל גדול בקנה המידה. השווה את העמודות "מקסימום" ו"דקות" בין תכונות שונות כדי למצוא קנה מידה משתנים מאוד.
שקול לנרמל ערכי תכונה כדי להפחית את הווריאציות הרחבות הללו.
תוויות עם תוויות לא חוקיות
לאומדני TensorFlow יש הגבלות על סוג הנתונים שהם מקבלים כתוויות. לדוגמה, מסווגים בינאריים פועלים בדרך כלל רק עם תוויות {0, 1}.
סקור את ערכי התווית בסקירת ההיבטים הכללית וודא שהם תואמים את הדרישות של מעריכים .