
Verileriniz bir TFX kanalına alındıktan sonra, onu analiz etmek ve dönüştürmek için TFX bileşenlerini kullanabilirsiniz. Bir modeli eğitmeden önce bile bu araçları kullanabilirsiniz.
Verilerinizi analiz etmek ve dönüştürmek için birçok neden vardır:
- Verilerinizdeki sorunları bulmak için. Yaygın sorunlar şunları içerir:
- Boş değerlere sahip özellikler gibi eksik veriler.
- Etiketler özellik olarak değerlendirilir, böylece modeliniz eğitim sırasında doğru cevaba göz atabilir.
- Beklediğiniz aralığın dışında değerlere sahip özellikler.
- Veri anormallikleri.
- Öğrenileni aktar modelinde eğitim verileriyle eşleşmeyen ön işleme var.
- Daha etkili özellik setleri oluşturmak için. Örneğin şunları tanımlayabilirsiniz:
- Özellikle bilgilendirici özellikler.
- Yedek özellikler.
- Ölçeği o kadar geniş çeşitlilik gösteren özellikler ki öğrenmeyi yavaşlatabilir.
- Çok az veya hiç benzersiz tahmin bilgisi içermeyen özellikler.
TFX araçları hem veri hatalarının bulunmasına hem de özellik mühendisliğine yardımcı olabilir.
TensorFlow Veri Doğrulaması
Genel Bakış
TensorFlow Veri Doğrulaması, eğitim ve veri sunumundaki anormallikleri tespit eder ve verileri inceleyerek otomatik olarak bir şema oluşturabilir. Bileşen, verilerdeki farklı anormallik sınıflarını tespit edecek şekilde yapılandırılabilir. Bu olabilir
- Veri istatistiklerini kullanıcının beklentilerini kodlayan bir şemayla karşılaştırarak geçerlilik kontrolleri yapın.
- Eğitim ve sunum verilerindeki örnekleri karşılaştırarak eğitim-sunum çarpıklığını tespit edin.
- Bir dizi veriye bakarak veri kaymasını tespit edin.
Bu işlevlerin her birini bağımsız olarak belgeliyoruz:
Şema Tabanlı Örnek Doğrulama
TensorFlow Veri Doğrulaması, veri istatistiklerini bir şemayla karşılaştırarak giriş verilerindeki tüm anormallikleri tanımlar. Şema, veri türleri veya kategorik değerler gibi giriş verilerinin karşılaması beklenen özellikleri kodlar ve kullanıcı tarafından değiştirilebilir veya değiştirilebilir.
Tensorflow Veri Doğrulaması genellikle TFX işlem hattı bağlamında birden çok kez çağrılır: (i) exampleGen'den elde edilen her bölünme için, (ii) Transform tarafından kullanılan tüm önceden dönüştürülmüş veriler için ve (iii) tarafından oluşturulan tüm dönüşüm sonrası veriler için. Dönüştürün. Dönüşüm (ii-iii) bağlamında çağrıldığında istatistik seçenekleri ve şema tabanlı kısıtlamalar, stats_options_updater_fn tanımlanarak ayarlanabilir. Bu özellikle yapılandırılmamış verileri (örn. metin özellikleri) doğrularken faydalıdır. Örnek için kullanıcı koduna bakın.
Gelişmiş Şema Özellikleri
Bu bölüm, özel kurulumlara yardımcı olabilecek daha gelişmiş şema yapılandırmasını kapsar.
Seyrek Özellikler
Örneklerdeki seyrek özelliklerin kodlanması genellikle tüm Örnekler için aynı değerliliğe sahip olması beklenen birden fazla Özelliği ortaya çıkarır. Örneğin seyrek özellik:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
Seyrek özellik tanımı, şemada mevcut olan özelliklere atıfta bulunan bir veya daha fazla dizin ve bir değer özelliği gerektirir. Seyrek özelliklerin açık bir şekilde tanımlanması, TFDV'nin adı geçen tüm özelliklerin değerlerinin eşleşip eşleşmediğini kontrol etmesini sağlar.
Bazı kullanım durumları, Özellikler arasında benzer değerlik kısıtlamaları getirir, ancak seyrek bir özelliği mutlaka kodlamaz. Seyrek özelliğinin kullanılması engelinizi kaldıracaktır, ancak ideal değildir.
Şema Ortamları
Varsayılan olarak doğrulamalar, bir işlem hattındaki tüm Örneklerin tek bir şemaya bağlı olduğunu varsayar. Bazı durumlarda, küçük şema değişikliklerinin tanıtılması gereklidir; örneğin, etiket olarak kullanılan özellikler eğitim sırasında gereklidir (ve doğrulanması gerekir), ancak sunum sırasında eksiktir. Ortamlar, özellikle default_environment() , in_environment() , not_in_environment() gibi gereksinimleri ifade etmek için kullanılabilir.
Örneğin, 'LABEL' adlı bir özelliğin eğitim için gerekli olduğunu, ancak sunumda eksik olmasının beklendiğini varsayalım. Bu şu şekilde ifade edilebilir:
- Şemada iki farklı ortam tanımlayın: ["SERVING", "TRAINING"] ve 'LABEL'i yalnızca "TRAINING" ortamıyla ilişkilendirin.
- Eğitim verilerini "TRAINING" ortamıyla ve hizmet verilerini "SERVING" ortamıyla ilişkilendirin.
Şema Oluşturma
Giriş veri şeması TensorFlow Schema'nın bir örneği olarak belirtilir.
Bir geliştirici, sıfırdan manuel olarak bir şema oluşturmak yerine TensorFlow Veri Doğrulamanın otomatik şema yapısına güvenebilir. Özellikle TensorFlow Veri Doğrulaması, üretim hattındaki mevcut eğitim verileri üzerinden hesaplanan istatistiklere dayalı olarak otomatik olarak bir başlangıç şeması oluşturur. Kullanıcılar bu otomatik olarak oluşturulan şemayı kolayca inceleyebilir, gerektiği gibi değiştirebilir, bir sürüm kontrol sistemine kontrol edebilir ve daha fazla doğrulama için açık bir şekilde işlem hattına aktarabilir.
TFDV, otomatik olarak bir şema oluşturmak için infer_schema() işlevini içerir. Örneğin:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Bu, aşağıdaki kurallara göre otomatik bir şema oluşturulmasını tetikler:
Bir şema zaten otomatik olarak oluşturulmuşsa olduğu gibi kullanılır.
Aksi takdirde TensorFlow Veri Doğrulaması mevcut veri istatistiklerini inceler ve veriler için uygun bir şema hesaplar.
Not: Otomatik olarak oluşturulan şema en iyi çabadır ve yalnızca verilerin temel özelliklerini çıkarmaya çalışır. Kullanıcıların gerektiğinde incelemesi ve değiştirmesi beklenmektedir.
Eğitim Hizmetinde Eğrilik Tespiti
Genel Bakış
TensorFlow Veri Doğrulaması, eğitim ve veri sunumu arasındaki dağılım çarpıklığını tespit edebilir. Eğitim verilerinin özellik değerlerinin dağılımı, sunulan verilerden önemli ölçüde farklı olduğunda dağıtım çarpıklığı oluşur. Dağıtım çarpıklığının temel nedenlerinden biri, istenen derlemdeki başlangıç verisi eksikliğinin üstesinden gelmek amacıyla veri oluşturma eğitimi için tamamen farklı bir derlem kullanmaktır. Diğer bir neden ise eğitim için yalnızca sunulan verilerin bir alt örneğini seçen hatalı bir örnekleme mekanizmasıdır.
Örnek Senaryo
Eğitim sunumunda çarpıklık algılamayı yapılandırma hakkında bilgi için TensorFlow Veri Doğrulama Başlangıç Kılavuzu'na bakın.
Sürüklenme Algılama
Farklı eğitim verileri günleri arasında olduğu gibi ardışık veri aralıkları arasında (yani, N aralığı ile N+1 aralığı arasında) sapma tespiti desteklenir. Kategorik özellikler için sürüklenmeyi L-sonsuzluk mesafesi cinsinden, sayısal özellikler için ise yaklaşık Jensen-Shannon sapması cinsinden ifade ediyoruz. Eşik mesafesini, sürüklenme kabul edilebilir değerden yüksek olduğunda uyarı alacağınız şekilde ayarlayabilirsiniz. Doğru mesafeyi ayarlamak genellikle alan bilgisi ve deney gerektiren yinelenen bir süreçtir.
Sapma algılamayı yapılandırma hakkında bilgi için TensorFlow Veri Doğrulama Başlangıç Kılavuzu'na bakın.
Verilerinizi Kontrol Etmek İçin Görselleştirmeleri Kullanma
TensorFlow Veri Doğrulaması, özellik değerlerinin dağılımını görselleştirmek için araçlar sağlar. Bu dağılımları Facets kullanarak bir Jupyter not defterinde inceleyerek verilerle ilgili yaygın sorunları yakalayabilirsiniz.
Şüpheli Dağıtımların Belirlenmesi
Özellik değerlerinin şüpheli dağılımlarını aramak için Özelliklere Genel Bakış ekranını kullanarak verilerinizdeki yaygın hataları tanımlayabilirsiniz.
Dengesiz Veriler
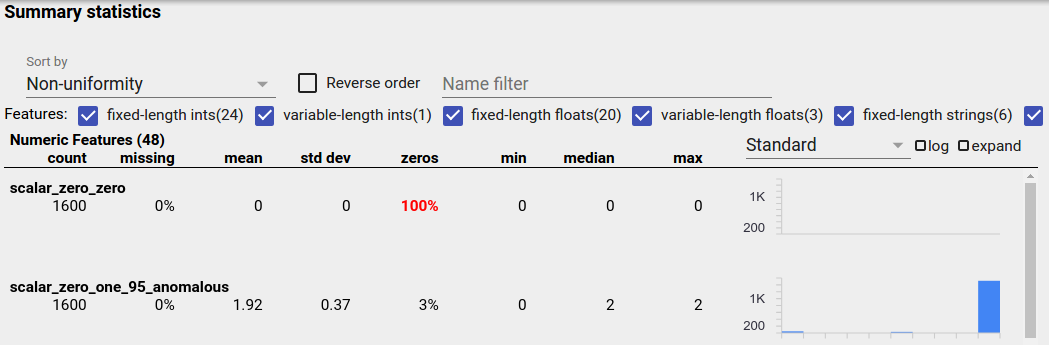
Dengesiz bir özellik, bir değerin baskın olduğu bir özelliktir. Dengesiz özellikler doğal olarak ortaya çıkabilir, ancak bir özellik her zaman aynı değere sahipse veri hatası yaşayabilirsiniz. Özelliklere Genel Bakışta dengesiz özellikleri tespit etmek için "Sıralama ölçütü" açılır menüsünden "Tekdüzeliksizlik" seçeneğini seçin.
En dengesiz özellikler, her özellik türü listesinin en üstünde listelenecektir. Örneğin, aşağıdaki ekran görüntüsünde "Sayısal Özellikler" listesinin en üstünde tamamı sıfır olan bir özellik ve son derece dengesiz olan bir ikinci özellik gösterilmektedir:
Düzgün Dağıtılmış Veriler
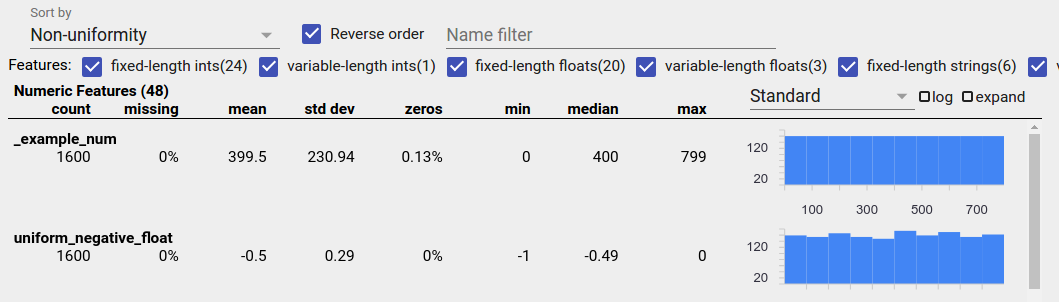
Düzgün dağıtılmış bir özellik, tüm olası değerlerin aynı frekansa yakın göründüğü bir özelliktir. Dengesiz verilerde olduğu gibi bu dağılım doğal olarak oluşabileceği gibi veri hatalarından da kaynaklanabilir.
Özelliklere Genel Bakışta eşit şekilde dağıtılmış özellikleri tespit etmek için, "Sıralama ölçütü" açılır menüsünden "Tekdüzeliksizlik" seçeneğini seçin ve "Sırayı tersine çevir" onay kutusunu işaretleyin:
Dize verileri, 20 veya daha az benzersiz değer varsa çubuk grafikler kullanılarak ve 20'den fazla benzersiz değer varsa kümülatif dağılım grafiği kullanılarak temsil edilir. Dolayısıyla dize verileri için tekdüze dağılımlar, yukarıdaki gibi düz çubuk grafikler veya aşağıdaki gibi düz çizgiler olarak görünebilir:

Düzgün Dağıtılmış Veri Üretebilen Hatalar
Eşit şekilde dağıtılmış veriler üretebilen bazı yaygın hatalar şunlardır:
Tarihler gibi dize olmayan veri türlerini temsil etmek için dizeleri kullanma. Örneğin, bir tarihsaat özelliği için "2017-03-01-11-45-03" gibi gösterimlere sahip birçok benzersiz değeriniz olacaktır. Benzersiz değerler eşit şekilde dağıtılacaktır.
Özellik olarak "satır numarası" gibi endekslerin dahil edilmesi. Burada yine birçok eşsiz değere sahipsiniz.
Eksik Veri
Bir özelliğin değerlerinin tamamen eksik olup olmadığını kontrol etmek için:
- "Sıralama ölçütü" açılır menüsünden "Eksik/sıfır tutarı"nı seçin.
- "Sırayı tersine çevir" onay kutusunu işaretleyin.
- Bir özelliğe ilişkin eksik değerlerin bulunduğu örneklerin yüzdesini görmek için "eksik" sütununa bakın.
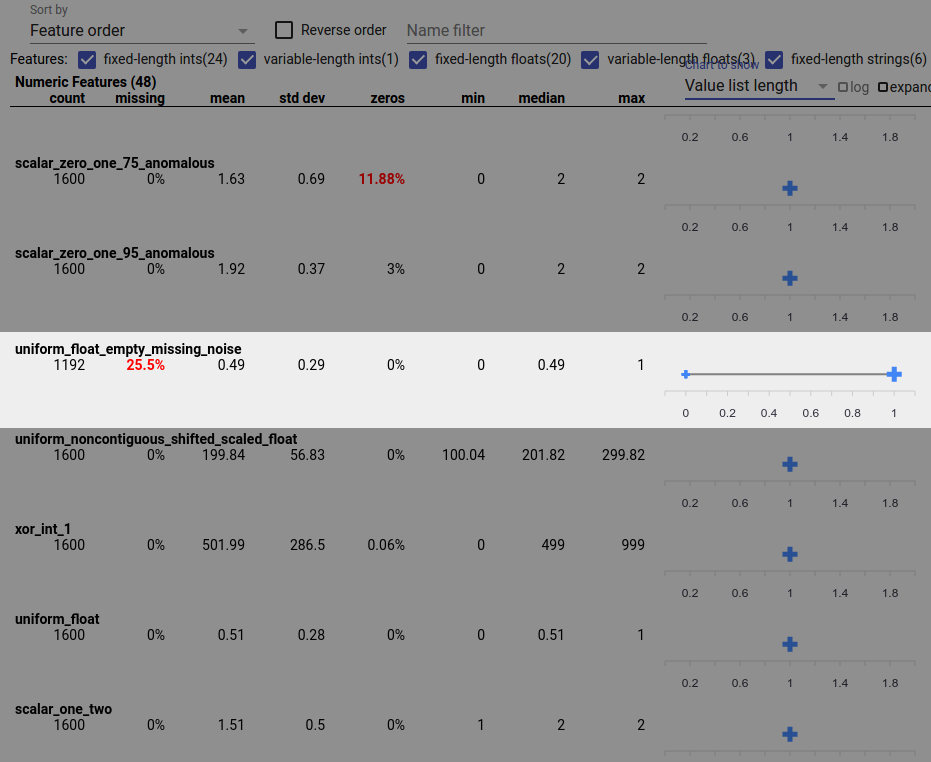
Bir veri hatası aynı zamanda eksik özellik değerlerine de neden olabilir. Örneğin, bir özelliğin değer listesinin her zaman üç öğeye sahip olmasını bekleyebilir ve bazen yalnızca bir öğeye sahip olduğunu keşfedebilirsiniz. Eksik değerleri veya özellik değeri listelerinin beklenen sayıda öğeye sahip olmadığı diğer durumları kontrol etmek için:
Sağdaki "Gösterilecek grafik" açılır menüsünden "Değer listesi uzunluğu"nu seçin.
Her özellik satırının sağındaki grafiğe bakın. Grafik, özelliğe ilişkin değer listesi uzunluklarının aralığını gösterir. Örneğin, aşağıdaki ekran görüntüsünde vurgulanan satırda bazı sıfır uzunluklu değer listelerine sahip bir özellik gösterilmektedir:
Özellikler Arasındaki Büyük Ölçek Farklılıkları
Özelliklerinizin ölçeği büyük ölçüde farklılık gösteriyorsa model öğrenmede zorluk yaşayabilir. Örneğin, bazı özellikler 0'dan 1'e, diğerleri ise 0'dan 1.000.000.000'e kadar değişiyorsa, ölçek açısından büyük bir farkınız olur. Çok çeşitli ölçekleri bulmak için özelliklerdeki "max" ve "min" sütunlarını karşılaştırın.
Bu geniş farklılıkları azaltmak için özellik değerlerini normalleştirmeyi düşünün.
Geçersiz Etiketli Etiketler
TensorFlow'un Tahmincilerinin etiket olarak kabul ettikleri veri türü konusunda kısıtlamaları vardır. Örneğin ikili sınıflandırıcılar genellikle yalnızca {0, 1} etiketleriyle çalışır.
Özelliklere Genel Bakış bölümündeki etiket değerlerini gözden geçirin ve Tahmincilerin gereksinimlerine uyduklarından emin olun.