
Setelah data Anda berada dalam pipeline TFX, Anda dapat menggunakan komponen TFX untuk menganalisis dan mengubahnya. Anda dapat menggunakan alat ini bahkan sebelum Anda melatih model.
Ada banyak alasan untuk menganalisis dan mengubah data Anda:
- Untuk menemukan masalah pada data Anda. Masalah umum meliputi:
- Data tidak ada, seperti fitur dengan nilai kosong.
- Label diperlakukan sebagai fitur, sehingga model Anda dapat melihat jawaban yang tepat selama pelatihan.
- Fitur dengan nilai di luar rentang yang Anda harapkan.
- Anomali data.
- Model transfer yang dipelajari memiliki prapemrosesan yang tidak cocok dengan data pelatihan.
- Untuk merekayasa kumpulan fitur yang lebih efektif. Misalnya, Anda dapat mengidentifikasi:
- Terutama fitur informatif.
- Fitur yang berlebihan.
- Fitur yang skalanya sangat bervariasi sehingga mungkin memperlambat pembelajaran.
- Fitur dengan sedikit atau tanpa informasi prediktif unik.
Alat TFX dapat membantu menemukan bug data dan membantu rekayasa fitur.
Validasi Data TensorFlow
Ringkasan
Validasi Data TensorFlow mengidentifikasi anomali dalam pelatihan dan penyajian data, dan dapat secara otomatis membuat skema dengan memeriksa data. Komponen ini dapat dikonfigurasi untuk mendeteksi berbagai kelas anomali dalam data. Itu bisa
- Lakukan pemeriksaan validitas dengan membandingkan statistik data dengan skema yang menyusun ekspektasi pengguna.
- Deteksi ketidakseimbangan penyajian pelatihan dengan membandingkan contoh dalam data pelatihan dan penyajian.
- Deteksi penyimpangan data dengan melihat serangkaian data.
Kami mendokumentasikan masing-masing fungsi ini secara independen:
Validasi Contoh Berbasis Skema
Validasi Data TensorFlow mengidentifikasi anomali apa pun pada data masukan dengan membandingkan statistik data dengan skema. Skema mengkodifikasi properti yang diharapkan dapat dipenuhi oleh data masukan, seperti tipe data atau nilai kategorikal, dan dapat dimodifikasi atau diganti oleh pengguna.
Validasi Data Tensorflow biasanya dipanggil beberapa kali dalam konteks pipeline TFX: (i) untuk setiap pemisahan yang diperoleh dari SampleGen, (ii) untuk semua data pra-transformasi yang digunakan oleh Transform dan (iii) untuk semua data pasca-transformasi yang dihasilkan oleh Mengubah. Ketika dipanggil dalam konteks Transformasi (ii-iii), opsi statistik dan batasan berbasis skema dapat diatur dengan mendefinisikan stats_options_updater_fn . Hal ini sangat berguna ketika memvalidasi data tidak terstruktur (misalnya fitur teks). Lihat kode pengguna sebagai contoh.
Fitur Skema Tingkat Lanjut
Bagian ini mencakup konfigurasi skema lebih lanjut yang dapat membantu pengaturan khusus.
Fitur Jarang
Pengkodean fitur-fitur renggang dalam Contoh biasanya memperkenalkan beberapa Fitur yang diharapkan memiliki valensi yang sama untuk semua Contoh. Misalnya fitur sparse:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
Definisi fitur sparse memerlukan satu atau lebih indeks dan satu fitur nilai yang mengacu pada fitur yang ada dalam skema. Mendefinisikan fitur renggang secara eksplisit memungkinkan TFDV memeriksa apakah valensi semua fitur yang dirujuk cocok.
Beberapa kasus penggunaan memperkenalkan pembatasan valensi yang serupa antar Fitur, namun tidak selalu mengkodekan fitur yang jarang. Menggunakan fitur sparse seharusnya membebaskan Anda, tetapi itu tidak ideal.
Lingkungan Skema
Secara default, validasi mengasumsikan bahwa semua Contoh dalam pipeline mematuhi satu skema. Dalam beberapa kasus, diperlukan sedikit variasi skema, misalnya fitur yang digunakan sebagai label diperlukan selama pelatihan (dan harus divalidasi), namun hilang selama penayangan. Lingkungan dapat digunakan untuk menyatakan persyaratan tersebut, khususnya default_environment() , in_environment() , not_in_environment() .
Misalnya, asumsikan fitur bernama 'LABEL' diperlukan untuk pelatihan, namun diperkirakan tidak ada saat ditayangkan. Hal ini dapat diungkapkan dengan:
- Tentukan dua lingkungan berbeda dalam skema: ["SERVING", "TRAINING"] dan kaitkan 'LABEL' hanya dengan lingkungan "TRAINING".
- Kaitkan data pelatihan dengan lingkungan "TRAINING" dan data penyajian dengan lingkungan "SERVING".
Pembuatan Skema
Skema data masukan ditentukan sebagai turunan dari Skema TensorFlow.
Daripada membuat skema secara manual dari awal, developer dapat mengandalkan konstruksi skema otomatis Validasi Data TensorFlow. Secara khusus, Validasi Data TensorFlow secara otomatis membuat skema awal berdasarkan statistik yang dihitung melalui data pelatihan yang tersedia di pipeline. Pengguna cukup meninjau skema yang dibuat secara otomatis ini, memodifikasinya sesuai kebutuhan, memeriksanya ke dalam sistem kontrol versi, dan memasukkannya secara eksplisit ke dalam pipeline untuk validasi lebih lanjut.
TFDV menyertakan infer_schema() untuk menghasilkan skema secara otomatis. Misalnya:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Hal ini memicu pembuatan skema otomatis berdasarkan aturan berikut:
Jika suatu skema telah dibuat secara otomatis maka skema tersebut akan digunakan apa adanya.
Jika tidak, Validasi Data TensorFlow akan memeriksa statistik data yang tersedia dan menghitung skema yang sesuai untuk data tersebut.
Catatan: Skema yang dibuat secara otomatis merupakan upaya terbaik dan hanya mencoba menyimpulkan properti dasar data. Pengguna diharapkan meninjau dan memodifikasinya sesuai kebutuhan.
Deteksi Kemiringan Penyajian Pelatihan
Ringkasan
Validasi Data TensorFlow dapat mendeteksi ketidakseimbangan distribusi antara data pelatihan dan penyajian. Kemiringan distribusi terjadi ketika distribusi nilai fitur untuk data pelatihan berbeda secara signifikan dengan data penyajian. Salah satu penyebab utama ketidakseimbangan distribusi adalah penggunaan korpus yang benar-benar berbeda untuk pembuatan data pelatihan guna mengatasi kekurangan data awal pada korpus yang diinginkan. Alasan lainnya adalah mekanisme pengambilan sampel yang salah sehingga hanya memilih subsampel dari data penyajian untuk dilatih.
Contoh Skenario
Lihat Panduan Memulai Validasi Data TensorFlow untuk informasi tentang mengonfigurasi deteksi kemiringan penyajian pelatihan.
Deteksi Melayang
Deteksi penyimpangan didukung antara rentang data yang berurutan (yaitu, antara rentang N dan rentang N+1), seperti antara hari data pelatihan yang berbeda. Kami menyatakan penyimpangan dalam bentuk jarak L-tak terhingga untuk fitur kategorikal dan perkiraan divergensi Jensen-Shannon untuk fitur numerik. Anda dapat mengatur jarak ambang batas sehingga Anda menerima peringatan ketika penyimpangan lebih tinggi dari yang dapat diterima. Menetapkan jarak yang tepat biasanya merupakan proses berulang yang memerlukan pengetahuan domain dan eksperimen.
Lihat Panduan Memulai Validasi Data TensorFlow untuk informasi tentang mengonfigurasi deteksi penyimpangan.
Menggunakan Visualisasi untuk Memeriksa Data Anda
Validasi Data TensorFlow menyediakan alat untuk memvisualisasikan distribusi nilai fitur. Dengan memeriksa distribusi ini di notebook Jupyter menggunakan Facets, Anda dapat mengetahui masalah umum pada data.
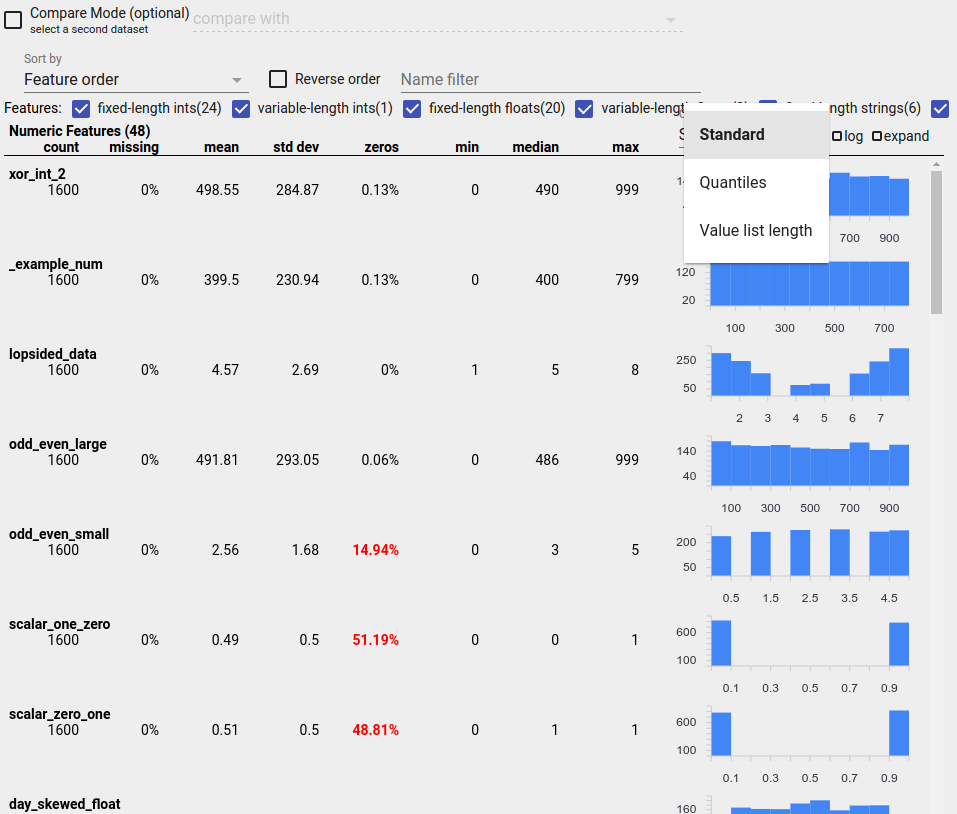
Mengidentifikasi Distribusi yang Mencurigakan
Anda dapat mengidentifikasi bug umum dalam data Anda dengan menggunakan tampilan Ikhtisar Faset untuk mencari distribusi nilai fitur yang mencurigakan.
Data Tidak Seimbang
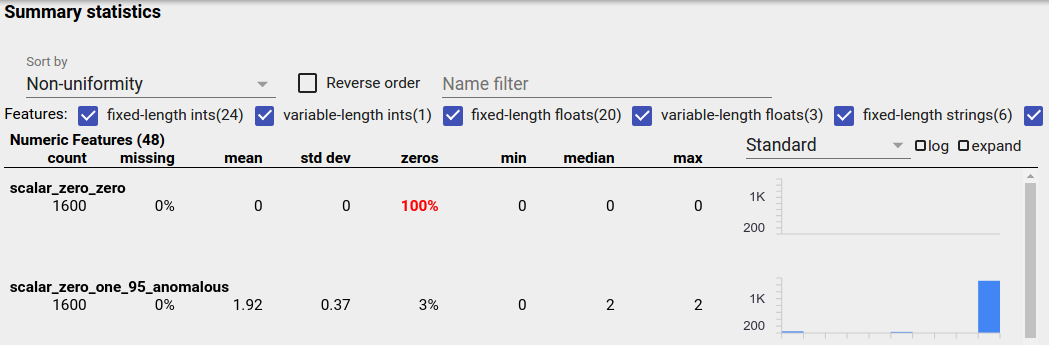
Fitur yang tidak seimbang adalah fitur yang mempunyai satu nilai yang mendominasi. Fitur yang tidak seimbang dapat terjadi secara alami, tetapi jika suatu fitur selalu memiliki nilai yang sama, Anda mungkin mengalami bug data. Untuk mendeteksi fitur yang tidak seimbang dalam Ikhtisar Faset, pilih "Ketidakseragaman" dari tarik-turun "Urutkan berdasarkan".
Fitur yang paling tidak seimbang akan dicantumkan di bagian atas setiap daftar jenis fitur. Misalnya, tangkapan layar berikut memperlihatkan satu fitur yang semuanya nol, dan fitur kedua yang sangat tidak seimbang, di bagian atas daftar "Fitur Numerik":
Data Terdistribusi Secara Seragam
Fitur yang terdistribusi secara seragam adalah fitur yang semua nilai yang mungkin muncul dengan frekuensi yang mendekati sama. Seperti halnya data yang tidak seimbang, distribusi ini dapat terjadi secara alami, namun dapat juga disebabkan oleh bug data.
Untuk mendeteksi fitur-fitur yang terdistribusi secara seragam dalam Ikhtisar Faset, pilih "Ketidakseragaman" dari tarik-turun "Urutkan berdasarkan" dan centang kotak "Urutan terbalik":
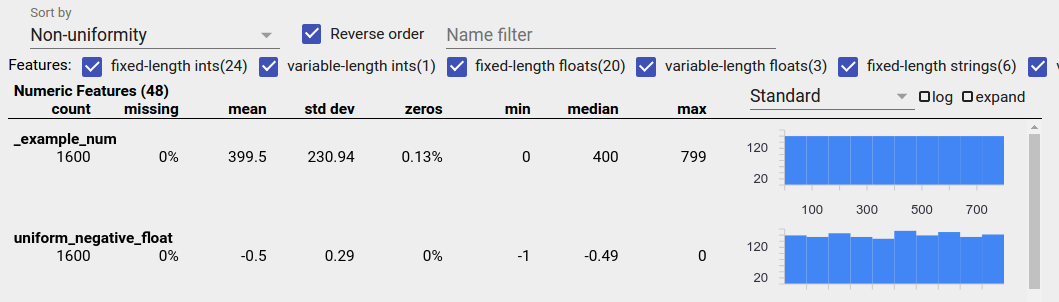
Data string direpresentasikan menggunakan diagram batang jika terdapat 20 nilai unik atau kurang, dan sebagai grafik distribusi kumulatif jika terdapat lebih dari 20 nilai unik. Jadi untuk data string, distribusi seragam dapat muncul sebagai grafik batang datar seperti di atas atau garis lurus seperti di bawah ini:

Bug Yang Dapat Menghasilkan Data Terdistribusi Secara Seragam
Berikut beberapa bug umum yang dapat menghasilkan data terdistribusi secara merata:
Menggunakan string untuk mewakili tipe data non-string seperti tanggal. Misalnya, Anda akan memiliki banyak nilai unik untuk fitur tanggal-waktu dengan representasi seperti "03-03-2017-03-11-45-2017". Nilai-nilai unik akan didistribusikan secara seragam.
Menyertakan indeks seperti "nomor baris" sebagai fitur. Di sini sekali lagi Anda memiliki banyak nilai unik.
Data Hilang
Untuk memeriksa apakah suatu fitur tidak memiliki nilai sama sekali:
- Pilih "Jumlah yang hilang/nol" dari tarik-turun "Urutkan berdasarkan".
- Centang kotak "Urutan terbalik".
- Lihat kolom "hilang" untuk melihat persentase instance yang nilai fiturnya hilang.
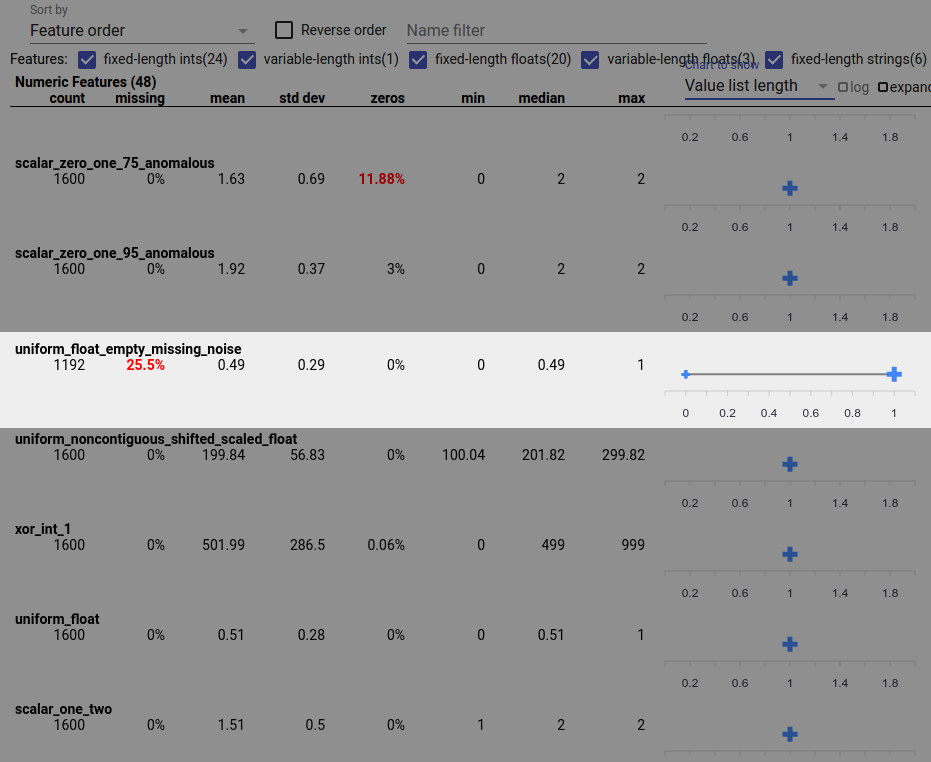
Bug data juga dapat menyebabkan nilai fitur tidak lengkap. Misalnya, Anda mungkin mengharapkan daftar nilai suatu fitur selalu memiliki tiga elemen dan menemukan bahwa terkadang hanya memiliki satu elemen. Untuk memeriksa nilai yang tidak lengkap atau kasus lain ketika daftar nilai fitur tidak memiliki jumlah elemen yang diharapkan:
Pilih "Panjang daftar nilai" dari menu tarik-turun "Bagan untuk ditampilkan" di sebelah kanan.
Lihatlah bagan di sebelah kanan setiap baris fitur. Bagan menunjukkan rentang panjang daftar nilai untuk fitur tersebut. Misalnya, baris yang disorot pada tangkapan layar di bawah menunjukkan fitur yang memiliki beberapa daftar nilai dengan panjang nol:
Perbedaan Besar dalam Skala Antar Fitur
Jika skala fitur Anda sangat bervariasi, model mungkin mengalami kesulitan dalam belajar. Misalnya, jika beberapa fitur bervariasi dari 0 hingga 1 dan fitur lainnya bervariasi dari 0 hingga 1.000.000.000, Anda memiliki perbedaan skala yang besar. Bandingkan kolom "maks" dan "min" di seluruh fitur untuk menemukan skala yang sangat bervariasi.
Pertimbangkan untuk menormalkan nilai fitur untuk mengurangi variasi yang luas ini.
Label dengan Label Tidak Valid
Estimator TensorFlow memiliki batasan pada jenis data yang diterima sebagai label. Misalnya, pengklasifikasi biner biasanya hanya berfungsi dengan label {0, 1}.
Tinjau nilai label di Ikhtisar Faset dan pastikan nilai tersebut sesuai dengan persyaratan Estimator .