
Una volta che i tuoi dati sono in una pipeline TFX, puoi utilizzare i componenti TFX per analizzarli e trasformarli. Puoi utilizzare questi strumenti anche prima di addestrare un modello.
Ci sono molti motivi per analizzare e trasformare i tuoi dati:
- Per trovare problemi nei tuoi dati. I problemi comuni includono:
- Dati mancanti, come elementi con valori vuoti.
- Etichette trattate come funzionalità, in modo che il tuo modello possa sbirciare la risposta giusta durante l'addestramento.
- Funzionalità con valori esterni all'intervallo previsto.
- Anomalie dei dati.
- Il modello appreso di trasferimento presenta una preelaborazione che non corrisponde ai dati di training.
- Per progettare set di funzionalità più efficaci. Ad esempio, puoi identificare:
- Caratteristiche particolarmente informative.
- Funzionalità ridondanti.
- Caratteristiche che variano così ampiamente in scala da poter rallentare l’apprendimento.
- Funzionalità con poche o nessuna informazione predittiva univoca.
Gli strumenti TFX possono sia aiutare a trovare bug nei dati, sia aiutare con l'ingegneria delle funzionalità.
Convalida dei dati TensorFlow
- Panoramica
- Validazione di esempi basata su schemi
- Rilevamento di inclinazione al servizio dell'allenamento
- Rilevamento della deriva
Panoramica
TensorFlow Data Validation identifica anomalie nell'addestramento e nella fornitura dei dati e può creare automaticamente uno schema esaminando i dati. Il componente può essere configurato per rilevare diverse classi di anomalie nei dati. Può
- Esegui controlli di validità confrontando le statistiche dei dati con uno schema che codifica le aspettative dell'utente.
- Rileva la distorsione della distribuzione dell'addestramento confrontando gli esempi nei dati di addestramento e di distribuzione.
- Rileva la deriva dei dati osservando una serie di dati.
Documentiamo ciascuna di queste funzionalità in modo indipendente:
- Validazione di esempi basata su schemi
- Rilevamento di inclinazione al servizio dell'allenamento
- Rilevamento della deriva
Validazione di esempi basata su schemi
TensorFlow Data Validation identifica eventuali anomalie nei dati di input confrontando le statistiche dei dati con uno schema. Lo schema codifica le proprietà che i dati di input dovrebbero soddisfare, come tipi di dati o valori categoriali, e può essere modificato o sostituito dall'utente.
Tensorflow Data Validation viene in genere richiamato più volte nel contesto della pipeline TFX: (i) per ogni suddivisione ottenuta da EsempioGen, (ii) per tutti i dati pre-trasformati utilizzati da Transform e (iii) per tutti i dati post-trasformazione generati da Trasformare. Quando richiamati nel contesto di Transform (ii-iii), le opzioni statistiche e i vincoli basati su schema possono essere impostati definendo stats_options_updater_fn . Ciò è particolarmente utile quando si convalidano dati non strutturati (ad esempio caratteristiche di testo). Vedi il codice utente per un esempio.
Funzionalità avanzate dello schema
Questa sezione copre la configurazione dello schema più avanzata che può essere utile con configurazioni speciali.
Caratteristiche sparse
La codifica di funzionalità sparse negli esempi di solito introduce più funzionalità che dovrebbero avere la stessa valenza per tutti gli esempi. Ad esempio la funzionalità sparsa:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
La definizione di funzionalità sparse richiede uno o più indici e una funzionalità di valore che si riferiscono a funzionalità esistenti nello schema. La definizione esplicita di caratteristiche sparse consente a TFDV di verificare che le valenze di tutte le caratteristiche riferite corrispondano.
Alcuni casi d'uso introducono restrizioni di valenza simili tra le funzionalità, ma non codificano necessariamente una funzionalità sparsa. L'uso della funzionalità sparsa dovrebbe sbloccarti, ma non è l'ideale.
Ambienti dello schema
Per impostazione predefinita, le convalide presuppongono che tutti gli esempi in una pipeline aderiscano a un singolo schema. In alcuni casi è necessario introdurre leggere variazioni dello schema, ad esempio le funzionalità utilizzate come etichette sono richieste durante la formazione (e dovrebbero essere convalidate), ma mancano durante la pubblicazione. Gli ambienti possono essere utilizzati per esprimere tali requisiti, in particolare default_environment() , in_environment() , not_in_environment() .
Ad esempio, supponiamo che una funzionalità denominata "LABEL" sia necessaria per l'addestramento, ma che dovrebbe mancare nella pubblicazione. Ciò può essere espresso da:
- Definire due ambienti distinti nello schema: ["SERVING", "TRAINING"] e associare 'LABEL' solo all'ambiente "TRAINING".
- Associare i dati di addestramento all'ambiente "TRAINING" e i dati di servizio all'ambiente "SERVING".
Generazione di schemi
Lo schema dei dati di input è specificato come un'istanza dello schema TensorFlow.
Invece di costruire manualmente uno schema da zero, uno sviluppatore può fare affidamento sulla costruzione automatica dello schema di TensorFlow Data Validation. Nello specifico, TensorFlow Data Validation costruisce automaticamente uno schema iniziale basato sulle statistiche calcolate sui dati di training disponibili nella pipeline. Gli utenti possono semplicemente rivedere questo schema generato automaticamente, modificarlo secondo necessità, inserirlo in un sistema di controllo della versione e inserirlo esplicitamente nella pipeline per un'ulteriore convalida.
TFDV include infer_schema() per generare automaticamente uno schema. Per esempio:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Ciò attiva una generazione automatica dello schema in base alle seguenti regole:
Se uno schema è già stato generato automaticamente, viene utilizzato così com'è.
Altrimenti, TensorFlow Data Validation esamina le statistiche dei dati disponibili e calcola uno schema adatto per i dati.
Nota: lo schema generato automaticamente è il massimo sforzo e tenta solo di dedurre le proprietà di base dei dati. Si prevede che gli utenti lo rivedano e lo modifichino secondo necessità.
Rilevamento di inclinazione al servizio dell'allenamento
Panoramica
TensorFlow Data Validation è in grado di rilevare l'asimmetria della distribuzione tra i dati di addestramento e quelli di fornitura. La distorsione della distribuzione si verifica quando la distribuzione dei valori delle funzionalità per i dati di training è significativamente diversa dai dati di fornitura. Una delle cause principali dell'asimmetria della distribuzione è l'utilizzo di un corpus completamente diverso per l'addestramento della generazione dei dati per superare la mancanza di dati iniziali nel corpus desiderato. Un altro motivo è un meccanismo di campionamento difettoso che sceglie solo un sottocampione dei dati di servizio su cui eseguire l'addestramento.
Scenario di esempio
Consulta la Guida introduttiva alla convalida dei dati di TensorFlow per informazioni sulla configurazione del rilevamento disallineamento per la formazione.
Rilevamento della deriva
Il rilevamento della deriva è supportato tra intervalli di dati consecutivi (ad esempio, tra l'intervallo N e l'intervallo N+1), ad esempio tra diversi giorni di dati di addestramento. Esprimiamo la deriva in termini di distanza L-infinito per caratteristiche categoriali e divergenza approssimata di Jensen-Shannon per caratteristiche numeriche. È possibile impostare la distanza soglia in modo da ricevere avvisi quando la deriva è superiore a quella accettabile. L'impostazione della distanza corretta è in genere un processo iterativo che richiede conoscenza e sperimentazione del dominio.
Consulta la Guida introduttiva alla convalida dei dati di TensorFlow per informazioni sulla configurazione del rilevamento della deriva.
Utilizzo delle visualizzazioni per verificare i dati
TensorFlow Data Validation fornisce strumenti per visualizzare la distribuzione dei valori delle funzionalità. Esaminando queste distribuzioni in un notebook Jupyter utilizzando Facets è possibile individuare problemi comuni con i dati.
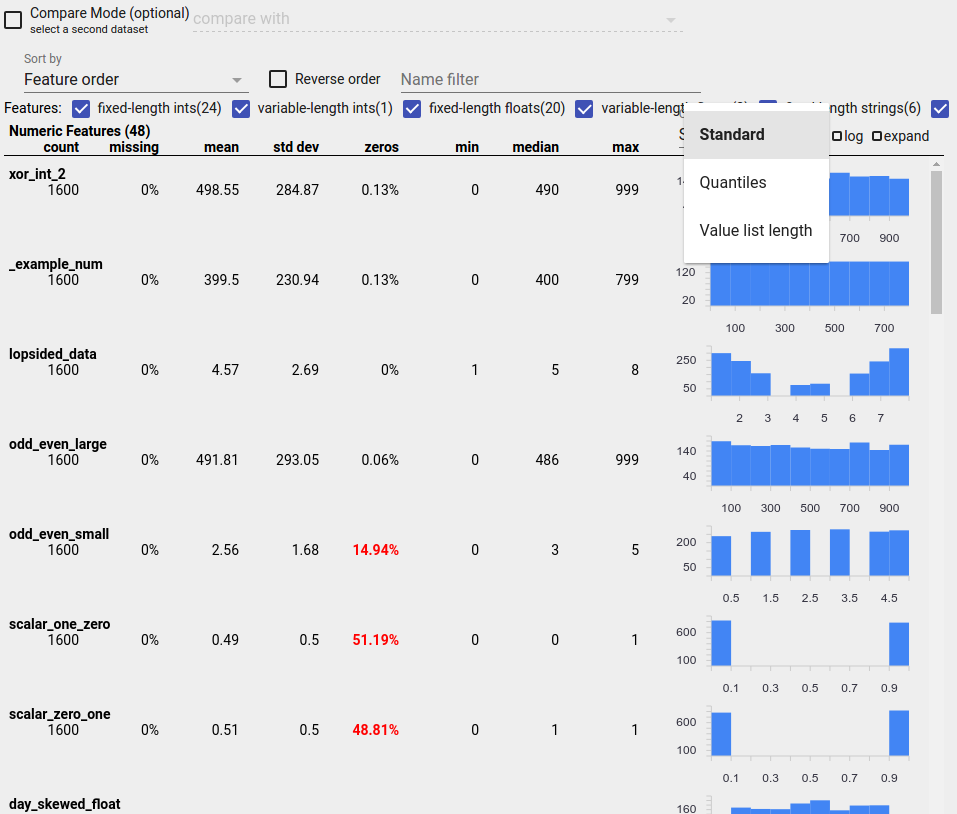
Identificazione delle distribuzioni sospette
Puoi identificare i bug comuni nei tuoi dati utilizzando la visualizzazione Panoramica sfaccettature per cercare distribuzioni sospette dei valori delle funzionalità.
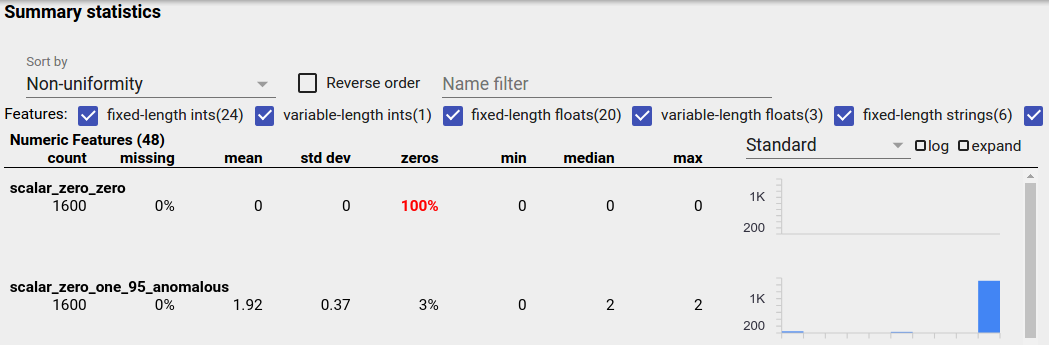
Dati sbilanciati
Una caratteristica sbilanciata è una caratteristica per la quale predomina un valore. Funzionalità sbilanciate possono verificarsi naturalmente, ma se una funzionalità ha sempre lo stesso valore potresti avere un bug di dati. Per rilevare funzionalità sbilanciate in una panoramica delle sfaccettature, scegli "Non uniformità" dal menu a discesa "Ordina per".
Le funzionalità più sbilanciate verranno elencate nella parte superiore di ciascun elenco di tipi di funzionalità. Ad esempio, lo screenshot seguente mostra una caratteristica che è tutta zero e una seconda che è molto sbilanciata, nella parte superiore dell'elenco "Caratteristiche numeriche":
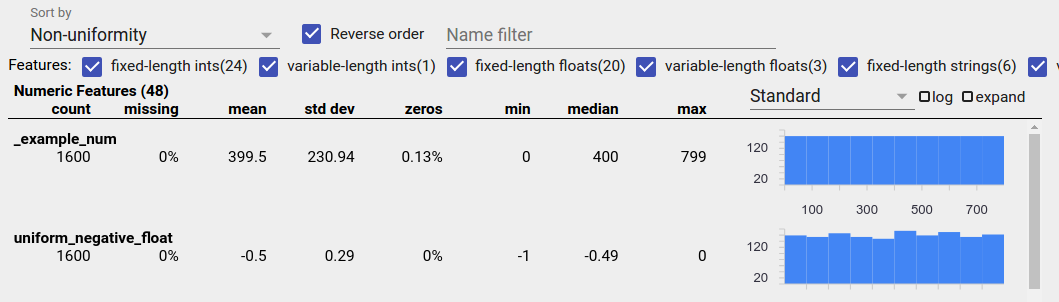
Dati uniformemente distribuiti
Una caratteristica distribuita uniformemente è quella per cui tutti i valori possibili appaiono quasi con la stessa frequenza. Come nel caso dei dati sbilanciati, questa distribuzione può avvenire in modo naturale, ma può anche essere prodotta da bug nei dati.
Per rilevare funzionalità distribuite in modo uniforme in una panoramica delle sfaccettature, scegli "Non uniformità" dal menu a discesa "Ordina per" e seleziona la casella di controllo "Ordine inverso":
I dati stringa vengono rappresentati utilizzando grafici a barre se sono presenti 20 o meno valori univoci e come grafico di distribuzione cumulativa se sono presenti più di 20 valori univoci. Quindi, per i dati di tipo stringa, le distribuzioni uniformi possono apparire come grafici a barre piatte come quello sopra o come linee rette come quello sotto:

Bug che possono produrre dati distribuiti uniformemente
Ecco alcuni bug comuni che possono produrre dati distribuiti uniformemente:
Utilizzo di stringhe per rappresentare tipi di dati non stringa come le date. Ad esempio, avrai molti valori univoci per una funzionalità datetime con rappresentazioni come "2017-03-01-11-45-03". I valori univoci verranno distribuiti uniformemente.
Inclusi indici come "numero di riga" come caratteristiche. Anche in questo caso hai molti valori unici.
Dati mancanti
Per verificare se a una funzione mancano completamente dei valori:
- Scegli "Importo mancante/zero" dal menu a discesa "Ordina per".
- Seleziona la casella di controllo "Ordine inverso".
- Osserva la colonna "mancante" per vedere la percentuale di istanze con valori mancanti per una funzionalità.
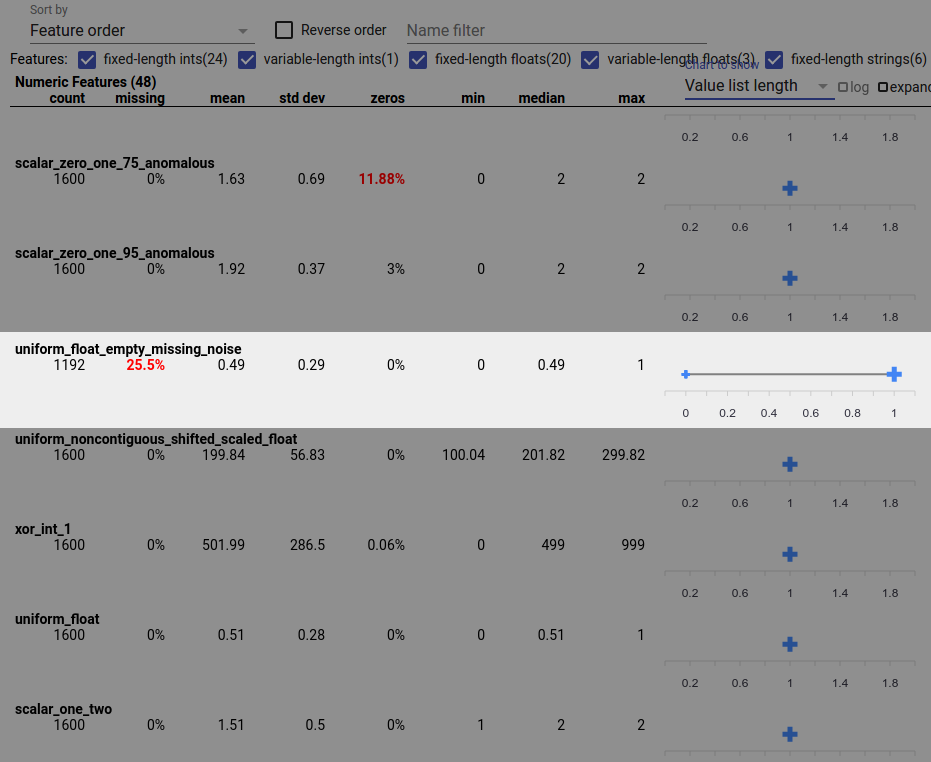
Un bug nei dati può anche causare valori di funzionalità incompleti. Ad esempio, potresti aspettarti che la lista dei valori di una caratteristica abbia sempre tre elementi e scoprire che a volte ne ha solo uno. Per verificare la presenza di valori incompleti o altri casi in cui gli elenchi di valori delle caratteristiche non hanno il numero previsto di elementi:
Scegli "Lunghezza elenco valori" dal menu a discesa "Grafico da mostrare" a destra.
Osserva il grafico a destra di ciascuna riga di funzionalità. Il grafico mostra l'intervallo di lunghezze della lista valori per la funzionalità. Ad esempio, la riga evidenziata nello screenshot seguente mostra una funzionalità che presenta alcuni elenchi di valori di lunghezza zero:
Grandi differenze di scala tra le caratteristiche
Se le caratteristiche variano notevolmente in scala, il modello potrebbe avere difficoltà di apprendimento. Ad esempio, se alcune funzionalità variano da 0 a 1 e altre da 0 a 1.000.000.000, si ha una grande differenza di scala. Confronta le colonne "max" e "min" tra le funzionalità per trovare scale molto diverse.
Prendi in considerazione la normalizzazione dei valori delle funzionalità per ridurre queste ampie variazioni.
Etichette con etichette non valide
Gli stimatori di TensorFlow hanno restrizioni sul tipo di dati che accettano come etichette. Ad esempio, i classificatori binari in genere funzionano solo con le etichette {0, 1}.
Esamina i valori delle etichette nella Panoramica dei facet e assicurati che siano conformi ai requisiti degli Estimatori .