
ML Metadata (MLMD) to biblioteka do rejestrowania i pobierania metadanych powiązanych z przepływami pracy programistów ML i analityków danych. MLMD jest integralną częścią TensorFlow Extended (TFX) , ale został zaprojektowany tak, aby można go było używać niezależnie.
Każde uruchomienie produkcyjnego potoku ML generuje metadane zawierające informacje o różnych komponentach potoku, ich wykonaniach (np. przebiegach szkoleniowych) i powstałych artefaktach (np. przeszkolonych modelach). W przypadku nieoczekiwanego zachowania lub błędów potoku te metadane można wykorzystać do analizy pochodzenia komponentów potoku i rozwiązywania problemów. Pomyśl o tych metadanych jak o logowaniu się do tworzenia oprogramowania.
MLMD pomaga zrozumieć i analizować wszystkie połączone ze sobą części potoku ML zamiast analizować je w izolacji i może pomóc odpowiedzieć na pytania dotyczące potoku ML, takie jak:
- Na jakim zbiorze danych trenowano model?
- Jakie hiperparametry wykorzystano do uczenia modelu?
- Które uruchomienie potoku utworzyło model?
- Który przebieg treningowy doprowadził do powstania tego modelu?
- Która wersja TensorFlow utworzyła ten model?
- Kiedy wypchnięto nieudany model?
Magazyn metadanych
MLMD rejestruje następujące typy metadanych w bazie danych zwanej Magazynem Metadanych .
- Metadane dotyczące artefaktów generowanych przez komponenty/kroki potoków uczenia maszynowego
- Metadane dotyczące wykonania tych komponentów/kroków
- Metadane dotyczące potoków i powiązanych informacji o pochodzeniu
Magazyn metadanych udostępnia interfejsy API służące do rejestrowania i pobierania metadanych do i z zaplecza pamięci masowej. Zaplecze pamięci masowej jest podłączane i można je rozszerzać. MLMD zapewnia referencyjne implementacje SQLite (obsługujące pamięć i dysk) oraz MySQL od razu po wyjęciu z pudełka.
Ta grafika przedstawia ogólny przegląd różnych komponentów wchodzących w skład MLMD.
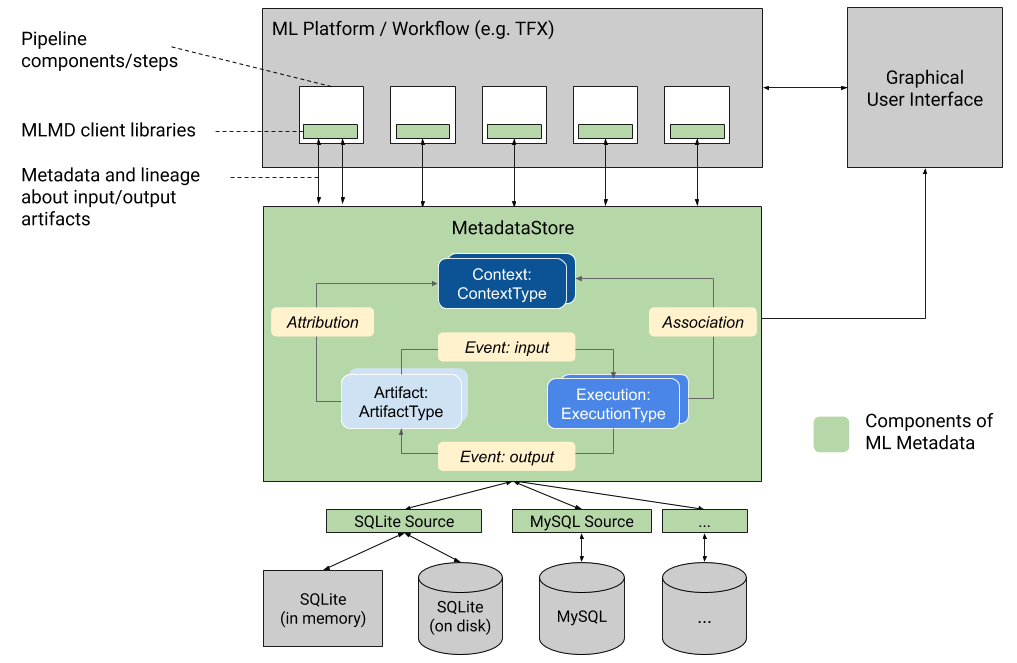
Backendy do przechowywania metadanych i konfiguracja połączenia ze sklepem
Obiekt MetadataStore otrzymuje konfigurację połączenia odpowiadającą używanemu zapleczu pamięci masowej.
- Fałszywa baza danych zapewnia bazę danych w pamięci (przy użyciu SQLite) do szybkich eksperymentów i uruchomień lokalnych. Baza danych jest usuwana w przypadku zniszczenia obiektu sklepu.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite odczytuje i zapisuje pliki z dysku.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL łączy się z serwerem MySQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
Podobnie, jeśli używasz instancji MySQL z Google CloudSQL ( szybki start , przegląd połączenia ), można również użyć opcji SSL, jeśli ma to zastosowanie.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL łączy się z serwerem PostgreSQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
Podobnie, jeśli używasz instancji PostgreSQL z Google CloudSQL ( szybki start , przegląd połączenia ), można również użyć opcji SSL, jeśli ma to zastosowanie.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
Model danych
Magazyn metadanych korzysta z następującego modelu danych do rejestrowania i pobierania metadanych z zaplecza magazynu.
-
ArtifactTypeopisuje typ artefaktu i jego właściwości przechowywane w magazynie metadanych. Możesz zarejestrować te typy na bieżąco w magazynie metadanych w kodzie lub możesz załadować je do sklepu z formatu serializowanego. Po zarejestrowaniu typu, jego definicja będzie dostępna przez cały okres istnienia sklepu. -
Artifactopisuje konkretną instancjęArtifactTypei jej właściwości zapisane w magazynie metadanych. -
ExecutionTypeopisuje typ komponentu lub kroku w przepływie pracy oraz jego parametry wykonawcze. -
Executionto zapis przebiegu komponentu lub kroku w przepływie pracy ML oraz parametry środowiska wykonawczego. Wykonanie można traktować jako instancjęExecutionType. Wykonania są rejestrowane po uruchomieniu potoku lub kroku ML. -
Eventjest zapisem związku pomiędzy artefaktami i egzekucjami. Kiedy ma miejsce egzekucja, zdarzenia rejestrują każdy artefakt użyty podczas egzekucji i każdy artefakt, który został wyprodukowany. Zapisy te umożliwiają śledzenie pochodzenia w trakcie przepływu pracy. Analizując wszystkie zdarzenia, MLMD wie, jakie egzekucje miały miejsce i jakie artefakty powstały w ich wyniku. MLMD może następnie powrócić z dowolnego artefaktu do wszystkich swoich wejściowych danych wejściowych. -
ContextTypeopisuje typ koncepcyjnej grupy artefaktów i wykonań w przepływie pracy oraz jej właściwości strukturalne. Na przykład: projekty, przebiegi rurociągów, eksperymenty, właściciele itp. -
Contextjest instancjąContextType. Przechwytuje informacje udostępniane w grupie. Na przykład: nazwa projektu, identyfikator zatwierdzenia listy zmian, adnotacje eksperymentów itp. Ma zdefiniowaną przez użytkownika unikalną nazwę w ramachContextType. -
Attributionto zapis relacji między artefaktami i kontekstami. -
Associationjest zapisem relacji pomiędzy wykonaniami i kontekstami.
Funkcjonalność MLMD
Śledzenie wejść i wyjść wszystkich komponentów/etapów przepływu pracy ML oraz ich pochodzenia umożliwia platformom ML udostępnienie kilku ważnych funkcji. Poniższa lista zawiera niewyczerpujący przegląd niektórych głównych korzyści.
- Wypisz wszystkie artefakty określonego typu. Przykład: wszystkie Modele, które zostały przeszkolone.
- Załaduj dwa artefakty tego samego typu dla porównania. Przykład: porównaj wyniki dwóch eksperymentów.
- Pokaż DAG wszystkich powiązanych wykonań oraz artefaktów wejściowych i wyjściowych kontekstu. Przykład: wizualizacja przebiegu eksperymentu dotyczącego debugowania i wykrywania.
- Wróć do wszystkich wydarzeń, aby zobaczyć, jak powstał artefakt. Przykłady: zobacz, jakie dane zostały wprowadzone do modelu; egzekwować plany przechowywania danych.
- Zidentyfikuj wszystkie artefakty, które zostały utworzone przy użyciu danego artefaktu. Przykłady: zobacz wszystkie modele wyszkolone z określonego zbioru danych; oznaczaj modele na podstawie złych danych.
- Sprawdź, czy wykonanie zostało wcześniej uruchomione na tych samych danych wejściowych. Przykład: ustal, czy komponent/etap wykonał już tę samą pracę, a poprzednie wyniki można po prostu ponownie wykorzystać.
- Kontekst rekordów i zapytań o przebiegi przepływu pracy. Przykłady: śledzenie właściciela i listy zmian używanych w przebiegu przepływu pracy; grupować linię według eksperymentów; zarządzaj artefaktami według projektów.
- Możliwości filtrowania węzłów deklaratywnych według właściwości i węzłów sąsiedzkich z 1 przeskokiem. Przykłady: szukaj artefaktów danego typu i w kontekście potoku; zwraca wpisane artefakty, gdy wartość danej właściwości mieści się w określonym zakresie; znajdź poprzednie wykonania w kontekście z tymi samymi danymi wejściowymi.
Zobacz samouczek MLMD , aby zapoznać się z przykładem pokazującym, jak używać interfejsu API MLMD i magazynu metadanych do pobierania informacji o pochodzeniu.
Zintegruj metadane ML ze swoimi przepływami pracy ML
Jeśli jesteś programistą platformy zainteresowanym integracją MLMD ze swoim systemem, skorzystaj z poniższego przykładowego przepływu pracy, aby użyć niskopoziomowych interfejsów API MLMD do śledzenia wykonania zadania szkoleniowego. W środowiskach notatników można także używać interfejsów API języka Python wyższego poziomu do rejestrowania metadanych eksperymentów.
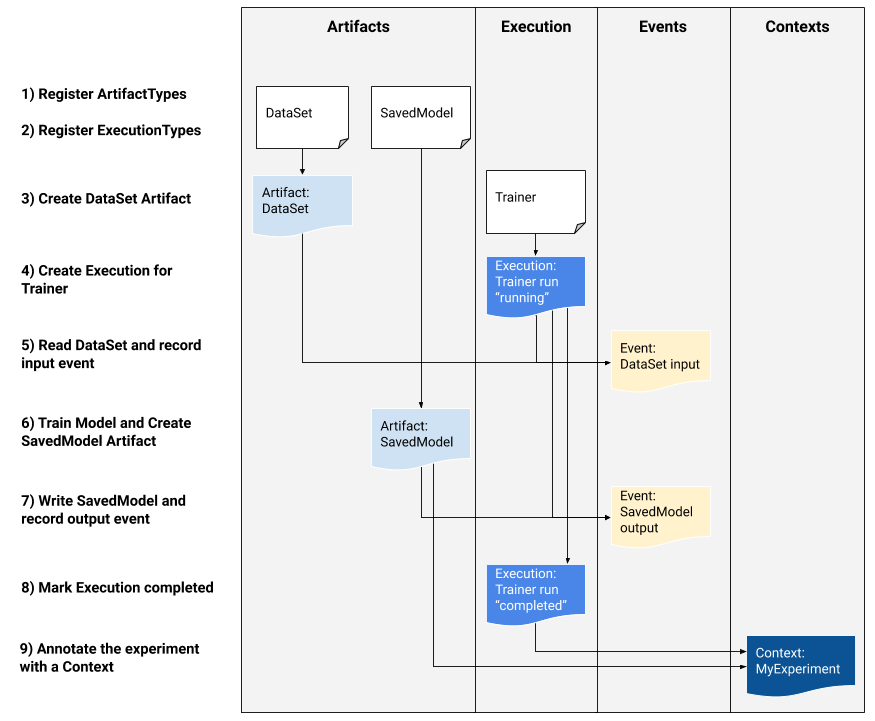
1) Zarejestruj typy artefaktów
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) Zarejestruj typy wykonania dla wszystkich kroków przepływu pracy ML
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) Utwórz artefakt typu ArtifactType zestawu danych
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) Utwórz wykonanie przebiegu Trainer
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) Zdefiniuj zdarzenie wejściowe i odczytaj dane
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) Zadeklaruj artefakt wyjściowy
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) Zapisz zdarzenie wyjściowe
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) Oznacz wykonanie jako ukończone
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) Grupuj artefakty i wykonania w kontekście przy użyciu artefaktów atrybucji i asercji
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
Użyj MLMD ze zdalnym serwerem gRPC
Możesz używać MLMD ze zdalnymi serwerami gRPC, jak pokazano poniżej:
- Uruchom serwer
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
Domyślnie serwer używa fałszywej bazy danych w pamięci na każde żądanie i nie utrwala metadanych podczas połączeń. Można go również skonfigurować za pomocą MLMD MetadataStoreServerConfig do korzystania z plików SQLite lub instancji MySQL. Konfigurację można zapisać w tekstowym pliku protobuf i przekazać do pliku binarnego za pomocą --metadata_store_server_config_file=path_to_the_config_file .
Przykładowy plik MetadataStoreServerConfig w formacie tekstowym protobuf:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- Utwórz kod pośredniczący klienta i użyj go w Pythonie
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- Użyj MLMD z wywołaniami RPC
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
Zasoby
Biblioteka MLMD zawiera interfejs API wysokiego poziomu, którego można łatwo używać w potokach ML. Więcej szczegółów znajdziesz w dokumentacji MLMD API .
Zapoznaj się z tematem Filtrowanie węzłów deklaratywnych MLMD , aby dowiedzieć się, jak korzystać z możliwości filtrowania węzłów deklaratywnych MLMD dla właściwości i węzłów sąsiedzkich z 1 przeskokiem.
Zapoznaj się także z samouczkiem MLMD , aby dowiedzieć się, jak używać MLMD do śledzenia pochodzenia komponentów potoku.
MLMD udostępnia narzędzia do obsługi migracji schematów i danych pomiędzy wersjami. Więcej szczegółów można znaleźć w Przewodniku MLMD.