
Fairness Indicators è progettato per supportare i team nella valutazione e nel miglioramento dei modelli per problemi di equità in collaborazione con il più ampio toolkit Tensorflow. Lo strumento è attualmente utilizzato attivamente internamente da molti dei nostri prodotti ed è ora disponibile in versione BETA per provarlo nei tuoi casi d'uso.
Che cosa sono gli indicatori di equità?
Fairness Indicators è una libreria che consente un facile calcolo delle metriche di equità comunemente identificate per i classificatori binari e multiclasse. Molti strumenti esistenti per valutare i problemi di equità non funzionano bene su set di dati e modelli su larga scala. Per Google è importante disporre di strumenti in grado di funzionare su sistemi con miliardi di utenti. Gli indicatori di equità ti consentiranno di valutare casi d'uso di qualsiasi dimensione.
In particolare, gli Indicatori di Equità includono la capacità di:
- Valutare la distribuzione dei set di dati
- Valuta le prestazioni del modello, suddiviso in gruppi definiti di utenti
- Sentiti sicuro dei tuoi risultati con intervalli di confidenza e valutazioni a più soglie
- Immergiti in profondità nelle singole sezioni per esplorare le cause profonde e le opportunità di miglioramento
Il download del pacchetto pip include:
- Convalida dei dati Tensorflow (TFDV)
- Analisi del modello Tensorflow (TFMA)
- Indicatori di equità
- Lo strumento What-If (WIT)
Utilizzo degli indicatori di equità con i modelli Tensorflow
Dati
Per eseguire gli indicatori di equità con TFMA, assicurati che il set di dati di valutazione sia etichettato per le funzionalità in base alle quali desideri suddividerle. Se non disponi delle funzionalità di fetta esatte per i tuoi dubbi sull'equità, puoi provare a trovare un set di valutazione che lo faccia o considerare le funzionalità proxy all'interno del tuo set di funzionalità che potrebbero evidenziare disparità di risultati. Per ulteriori indicazioni, vedere qui .
Modello
Puoi utilizzare la classe Tensorflow Estimator per creare il tuo modello. Il supporto per i modelli Keras sarà presto disponibile su TFMA. Se desideri eseguire TFMA su un modello Keras, consulta la sezione "TFMA indipendente dal modello" di seguito.
Dopo aver addestrato il tuo stimatore, dovrai esportare un modello salvato a scopo di valutazione. Per saperne di più consulta la guida TFMA .
Configurazione delle sezioni
Successivamente, definisci le sezioni su cui desideri valutare:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Se desideri valutare le sezioni intersezionali (ad esempio, sia il colore della pelliccia che l'altezza), puoi impostare quanto segue:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Calcolare le metriche di equità
Aggiungi un callback Fairness Indicators all'elenco metrics_callback . Nel callback è possibile definire un elenco di soglie alle quali verrà valutato il modello.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Prima di eseguire la configurazione, determinare se si desidera abilitare o meno il calcolo degli intervalli di confidenza. Gli intervalli di confidenza vengono calcolati utilizzando il bootstrap di Poisson e richiedono il ricalcolo su 20 campioni.
compute_confidence_intervals = True
Esegui la pipeline di valutazione TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Indicatori di equità di rendering
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
Suggerimenti per l’utilizzo degli indicatori di equità:
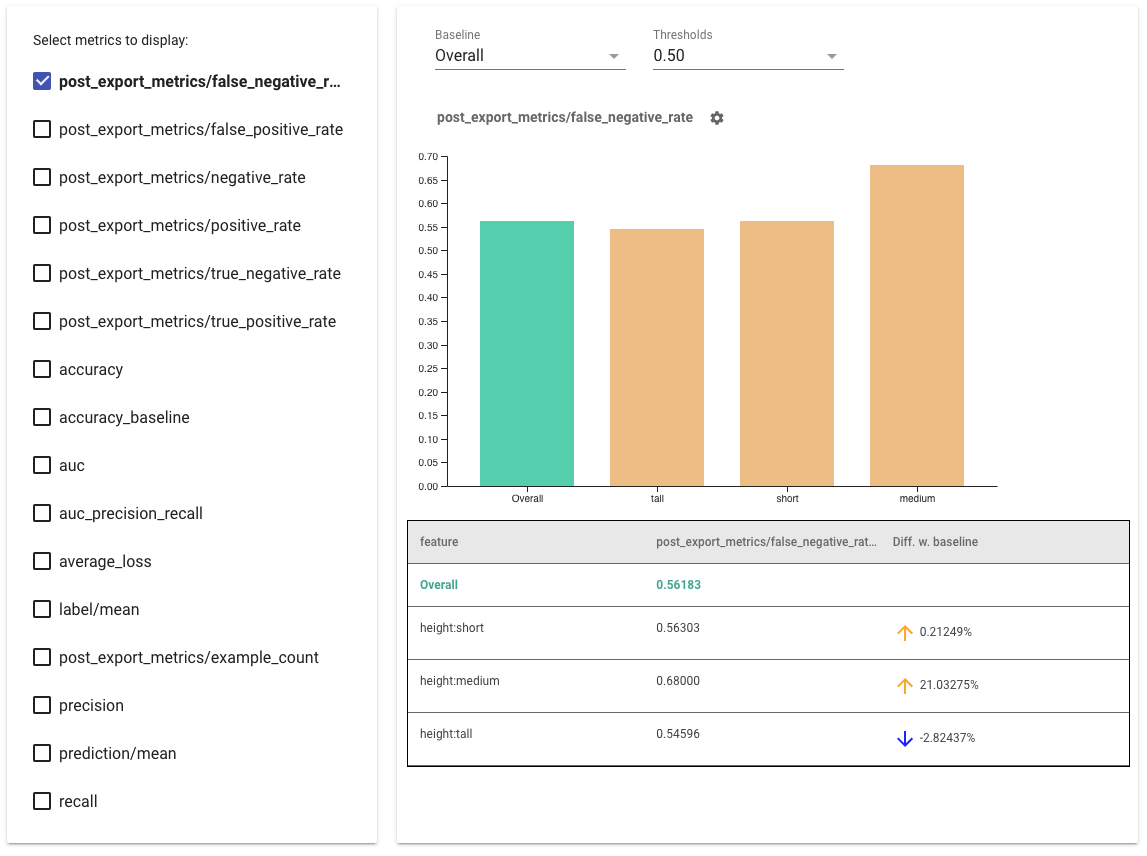
- Seleziona le metriche da visualizzare selezionando le caselle sul lato sinistro. I singoli grafici per ciascuna metrica verranno visualizzati nel widget, in ordine.
- Modifica la sezione della linea di base , la prima barra del grafico, utilizzando il selettore a discesa. I delta verranno calcolati con questo valore di base.
- Seleziona le soglie utilizzando il selettore a discesa. È possibile visualizzare più soglie sullo stesso grafico. Le soglie selezionate verranno visualizzate in grassetto ed è possibile fare clic su una soglia in grassetto per deselezionarla.
- Passa il mouse sopra una barra per visualizzare le metriche per quella sezione.
- Identificare le disparità con la linea di base utilizzando la colonna "Diff w. baseline", che identifica la differenza percentuale tra la sezione corrente e la linea di base.
- Esplora in modo approfondito i punti dati di una sezione utilizzando lo strumento What-If . Vedi qui per un esempio.
Indicatori di equità del rendering per più modelli
Gli indicatori di equità possono essere utilizzati anche per confrontare i modelli. Invece di passare un singolo eval_result, passa un oggetto multi_eval_results, che è un dizionario che mappa due nomi di modello su oggetti eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
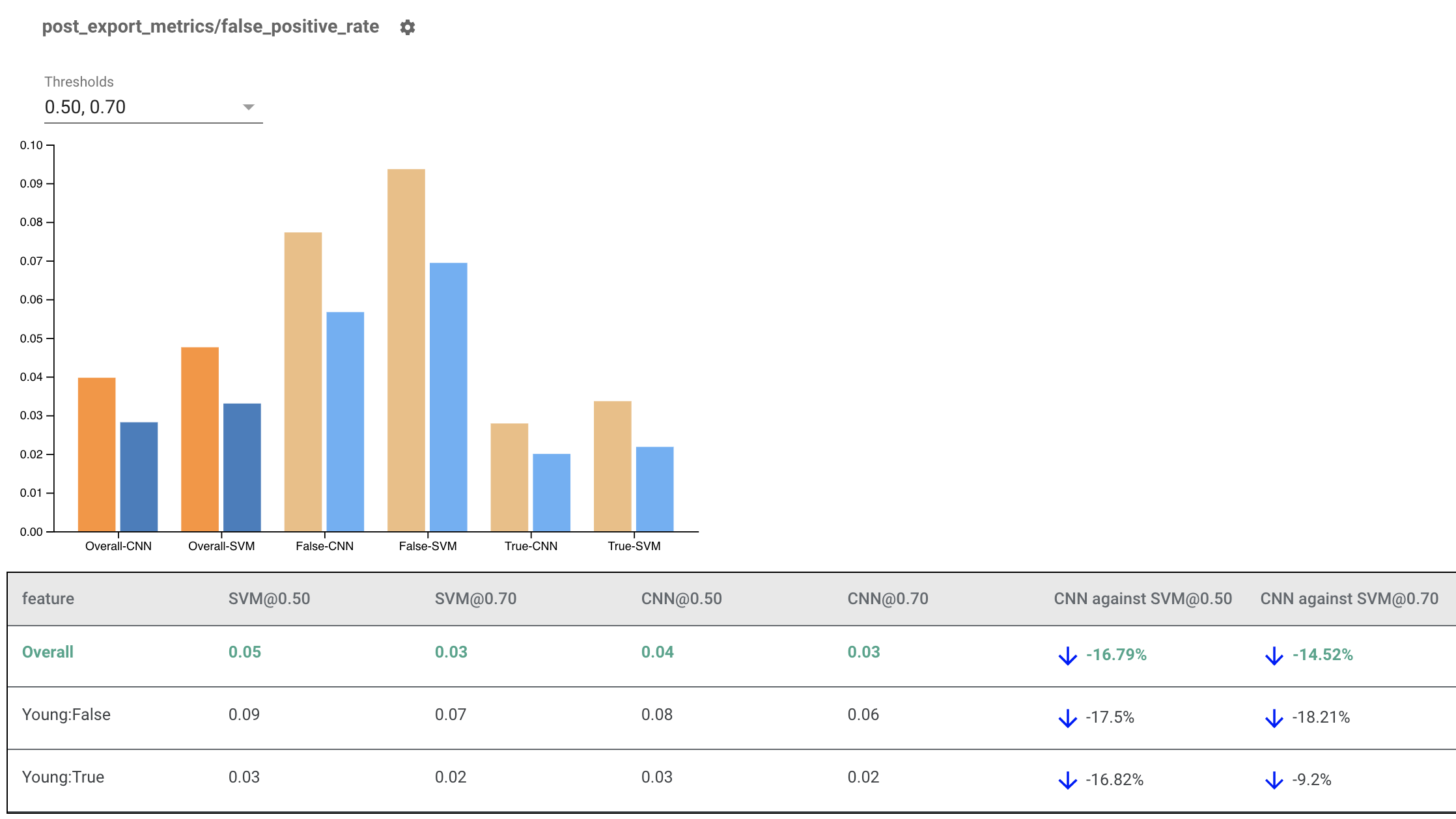
Il confronto dei modelli può essere utilizzato insieme al confronto delle soglie. Ad esempio, puoi confrontare due modelli a due serie di soglie per trovare la combinazione ottimale per le tue metriche di equità.
Utilizzo di indicatori di equità con modelli non TensorFlow
Per supportare meglio i clienti che hanno modelli e flussi di lavoro diversi, abbiamo sviluppato una libreria di valutazione indipendente dal modello da valutare.
Chiunque voglia valutare il proprio sistema di machine learning può utilizzarlo, soprattutto se si dispone di modelli non basati su TensorFlow. Utilizzando Apache Beam Python SDK, puoi creare un file binario di valutazione TFMA autonomo e quindi eseguirlo per analizzare il tuo modello.
Dati
Questo passaggio consiste nel fornire il set di dati su cui si desidera eseguire le valutazioni. Dovrebbe essere in formato proto tf.Example con etichette, previsioni e altre funzionalità che potresti voler suddividere.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Modello
Invece di specificare un modello, puoi creare una configurazione di valutazione ed un estrattore indipendenti dal modello per analizzare e fornire i dati necessari a TFMA per calcolare le metriche. La specifica ModelAgnosticConfig definisce le funzionalità, le previsioni e le etichette da utilizzare dagli esempi di input.
A questo scopo, crea una mappa delle funzionalità con chiavi che rappresentano tutte le funzionalità, comprese le chiavi di etichetta e previsione e i valori che rappresentano il tipo di dati della funzionalità.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Crea una configurazione indipendente dal modello utilizzando le chiavi di etichetta, le chiavi di previsione e la mappa delle funzionalità.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Configurare l'estrattore indipendente dal modello
L'estrattore viene utilizzato per estrarre le funzionalità, le etichette e le previsioni dall'input utilizzando la configurazione indipendente dal modello. E se vuoi suddividere i tuoi dati, devi anche definire la slice key spec , contenente informazioni sulle colonne su cui vuoi suddividere.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Calcolare le metriche di equità
Come parte di EvalSharedModel , puoi fornire tutti i parametri in base ai quali desideri che venga valutato il tuo modello. Le metriche vengono fornite sotto forma di callback di metriche come quelle definite in post_export_metrics o fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
Richiede anche un construct_fn che viene utilizzato per creare un grafico tensorflow per eseguire la valutazione.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
Una volta impostato tutto, utilizza una delle funzioni ExtractEvaluate o ExtractEvaluateAndWriteResults fornite da model_eval_lib per valutare il modello.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Infine, esegui il rendering degli indicatori di equità utilizzando le istruzioni della sezione "Render Fairness Indicators" sopra.
Altri esempi
La directory degli esempi di Fairness Indicators contiene diversi esempi:
- Fairness_Indicators_Example_Colab.ipynb fornisce una panoramica degli indicatori di equità nell'analisi del modello TensorFlow e come utilizzarlo con un set di dati reale. Questo notebook esamina anche TensorFlow Data Validation e What-If Tool , due strumenti per l'analisi dei modelli TensorFlow forniti con indicatori di equità.
- Fairness_Indicators_on_TF_Hub.ipynb dimostra come utilizzare gli indicatori di equità per confrontare modelli addestrati su diversi incorporamenti di testo . Questo notebook utilizza incorporamenti di testo da TensorFlow Hub , la libreria di TensorFlow per pubblicare, scoprire e riutilizzare i componenti del modello.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb mostra come visualizzare gli indicatori di equità in TensorBoard.