
Fairness Indicators ได้รับการออกแบบมาเพื่อสนับสนุนทีมในการประเมินและปรับปรุงแบบจำลองสำหรับข้อกังวลเรื่องความเป็นธรรมโดยร่วมมือกับชุดเครื่องมือ Tensorflow ที่กว้างขึ้น ปัจจุบันเครื่องมือนี้ใช้งานภายในโดยผลิตภัณฑ์จำนวนมากของเรา และตอนนี้พร้อมใช้งานในรุ่นเบต้าเพื่อลองใช้กรณีการใช้งานของคุณเอง
ตัวชี้วัดความเป็นธรรมคืออะไร?
Fairness Indicators คือไลบรารีที่ช่วยให้คำนวณตัวชี้วัดความเป็นธรรมที่ระบุโดยทั่วไปสำหรับตัวแยกประเภทไบนารีและหลายคลาสได้อย่างง่ายดาย เครื่องมือที่มีอยู่มากมายสำหรับการประเมินข้อกังวลด้านความเป็นธรรมทำงานได้ไม่ดีกับชุดข้อมูลและแบบจำลองขนาดใหญ่ ที่ Google การมีเครื่องมือที่สามารถทำงานกับระบบที่มีผู้ใช้นับพันล้านเป็นสิ่งสำคัญสำหรับเรา ตัวบ่งชี้ความเป็นธรรมจะช่วยให้คุณสามารถประเมินกรณีการใช้งานทุกขนาดได้
โดยเฉพาะอย่างยิ่ง ตัวชี้วัดความเป็นธรรมรวมถึงความสามารถในการ:
- ประเมินการกระจายตัวของชุดข้อมูล
- ประเมินประสิทธิภาพของโมเดล โดยแบ่งเป็นกลุ่มผู้ใช้ที่กำหนด
- รู้สึกมั่นใจกับผลลัพธ์ของคุณด้วยช่วงความมั่นใจและการประเมินที่เกณฑ์ต่างๆ
- เจาะลึกในแต่ละส่วนเพื่อสำรวจสาเหตุที่แท้จริงและโอกาสในการปรับปรุง
การดาวน์โหลดแพ็คเกจ pip ประกอบด้วย:
- การตรวจสอบข้อมูล Tensorflow (TFDV)
- การวิเคราะห์แบบจำลองเทนเซอร์โฟลว์ (TFMA)
- ตัวชี้วัดความเป็นธรรม
- เครื่องมือ What-If (WIT)
การใช้ตัวบ่งชี้ความเป็นธรรมกับโมเดล Tensorflow
ข้อมูล
หากต้องการเรียกใช้ Fairness Indicators ด้วย TFMA ตรวจสอบให้แน่ใจว่าชุดข้อมูลการประเมินมีป้ายกำกับสำหรับคุณสมบัติที่คุณต้องการแบ่งส่วน หากคุณไม่มีคุณลักษณะการแบ่งส่วนที่แน่นอนสำหรับข้อกังวลด้านความเป็นธรรมของคุณ คุณอาจลองค้นหาชุดการประเมินที่มี หรือพิจารณาคุณลักษณะพร็อกซีภายในชุดคุณลักษณะของคุณที่อาจเน้นความแตกต่างของผลลัพธ์ สำหรับคำแนะนำเพิ่มเติม ดู ที่นี่
แบบอย่าง
คุณสามารถใช้คลาส Tensorflow Estimator เพื่อสร้างโมเดลของคุณได้ TFMA จะรองรับโมเดล Keras เร็วๆ นี้ หากคุณต้องการเรียกใช้ TFMA บนโมเดล Keras โปรดดูส่วน “Model-Agnostic TFMA” ด้านล่าง
หลังจากฝึกฝนตัวประมาณค่าแล้ว คุณจะต้องส่งออกแบบจำลองที่บันทึกไว้เพื่อวัตถุประสงค์ในการประเมิน หากต้องการเรียนรู้เพิ่มเติม โปรดดู คู่มือ TFMA
การกำหนดค่าชิ้น
ถัดไป กำหนดส่วนที่คุณต้องการประเมิน:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
หากคุณต้องการประเมินการตัดขวาง (เช่น ทั้งสีขนและความสูง) คุณสามารถตั้งค่าดังต่อไปนี้:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
เมตริกความเป็นธรรมในการประมวลผล
เพิ่มการโทรกลับของตัวบ่งชี้ความเป็นธรรมไปยังรายการ metrics_callback ในการเรียกกลับ คุณสามารถกำหนดรายการเกณฑ์ที่แบบจำลองจะได้รับการประเมิน
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
ก่อนที่จะเรียกใช้การกำหนดค่า ให้พิจารณาว่าคุณต้องการเปิดใช้งานการคำนวณช่วงความเชื่อมั่นหรือไม่ ช่วงความเชื่อมั่นคำนวณโดยใช้การบูตสแตรปปิ้งปัวซอง และต้องมีการคำนวณใหม่มากกว่า 20 ตัวอย่าง
compute_confidence_intervals = True
รันไปป์ไลน์การประเมิน TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
แสดงผลตัวชี้วัดความเป็นธรรม
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
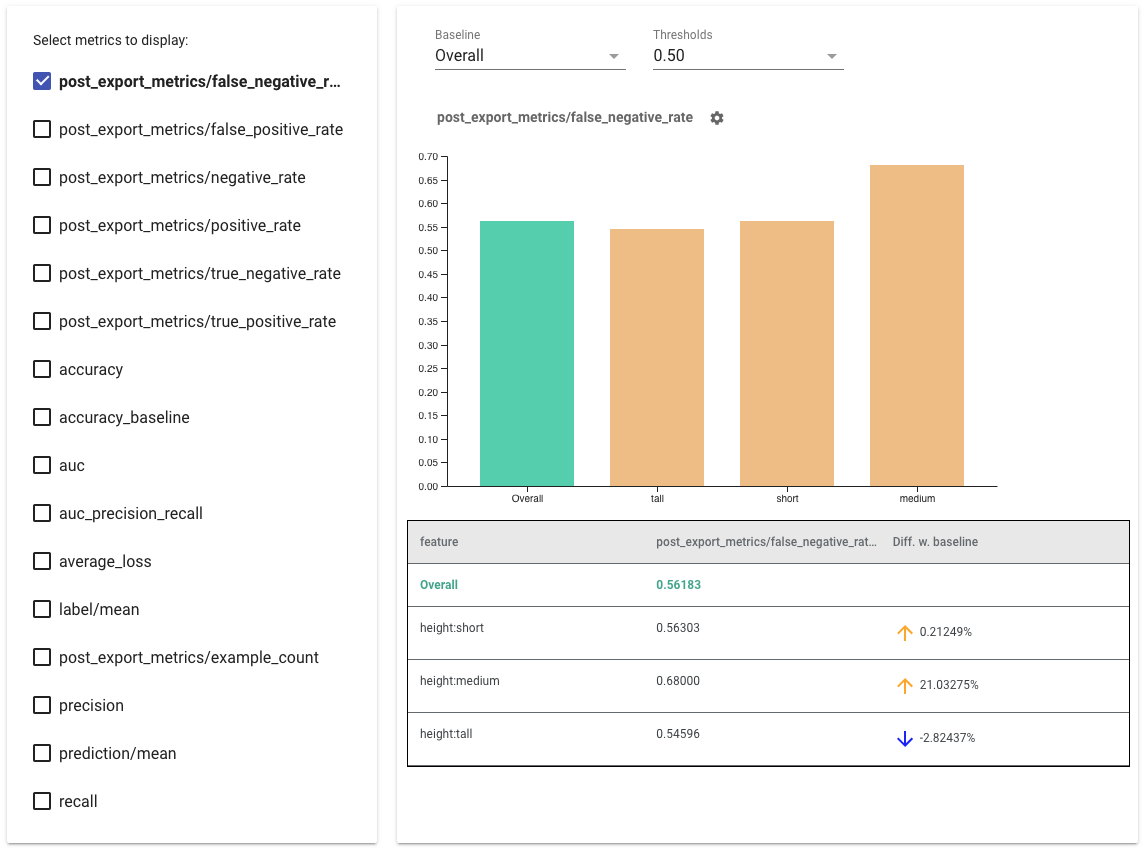
เคล็ดลับในการใช้ตัวชี้วัดความเป็นธรรม:
- เลือกเมตริกที่จะแสดง โดยทำเครื่องหมายในช่องด้านซ้ายมือ กราฟแต่ละรายการสำหรับแต่ละเมตริกจะปรากฏในวิดเจ็ตตามลำดับ
- เปลี่ยนส่วนพื้นฐาน ซึ่งเป็นแถบแรกบนกราฟโดยใช้ตัวเลือกแบบเลื่อนลง ส่วนต่างจะถูกคำนวณด้วยค่าพื้นฐานนี้
- เลือกเกณฑ์ โดยใช้ตัวเลือกแบบเลื่อนลง คุณสามารถดูเกณฑ์ได้หลายรายการบนกราฟเดียวกัน เกณฑ์ที่เลือกจะเป็นตัวหนา และคุณสามารถคลิกเกณฑ์ที่เป็นตัวหนาเพื่อยกเลิกการเลือกได้
- วางเมาส์เหนือแถบ เพื่อดูเมตริกสำหรับส่วนนั้น
- ระบุความแตกต่างด้วยเส้นฐาน โดยใช้คอลัมน์ "ส่วนต่างที่มีเส้นฐาน" ซึ่งระบุเปอร์เซ็นต์ความแตกต่างระหว่างชิ้นปัจจุบันและเส้นพื้นฐาน
- สำรวจจุดข้อมูลของชิ้นส่วนในเชิงลึก โดยใช้ เครื่องมือ What-If ดู ที่นี่ สำหรับตัวอย่าง
การแสดงตัวบ่งชี้ความเป็นธรรมสำหรับหลายรุ่น
ตัวบ่งชี้ความเป็นธรรมสามารถใช้เพื่อเปรียบเทียบแบบจำลองต่างๆ ได้ แทนที่จะส่งผ่านใน eval_result เดียว ให้ส่งผ่านในออบเจ็กต์ multi_eval_results ซึ่งเป็นพจนานุกรมที่จับคู่ชื่อโมเดลสองชื่อกับออบเจ็กต์ eval_result
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
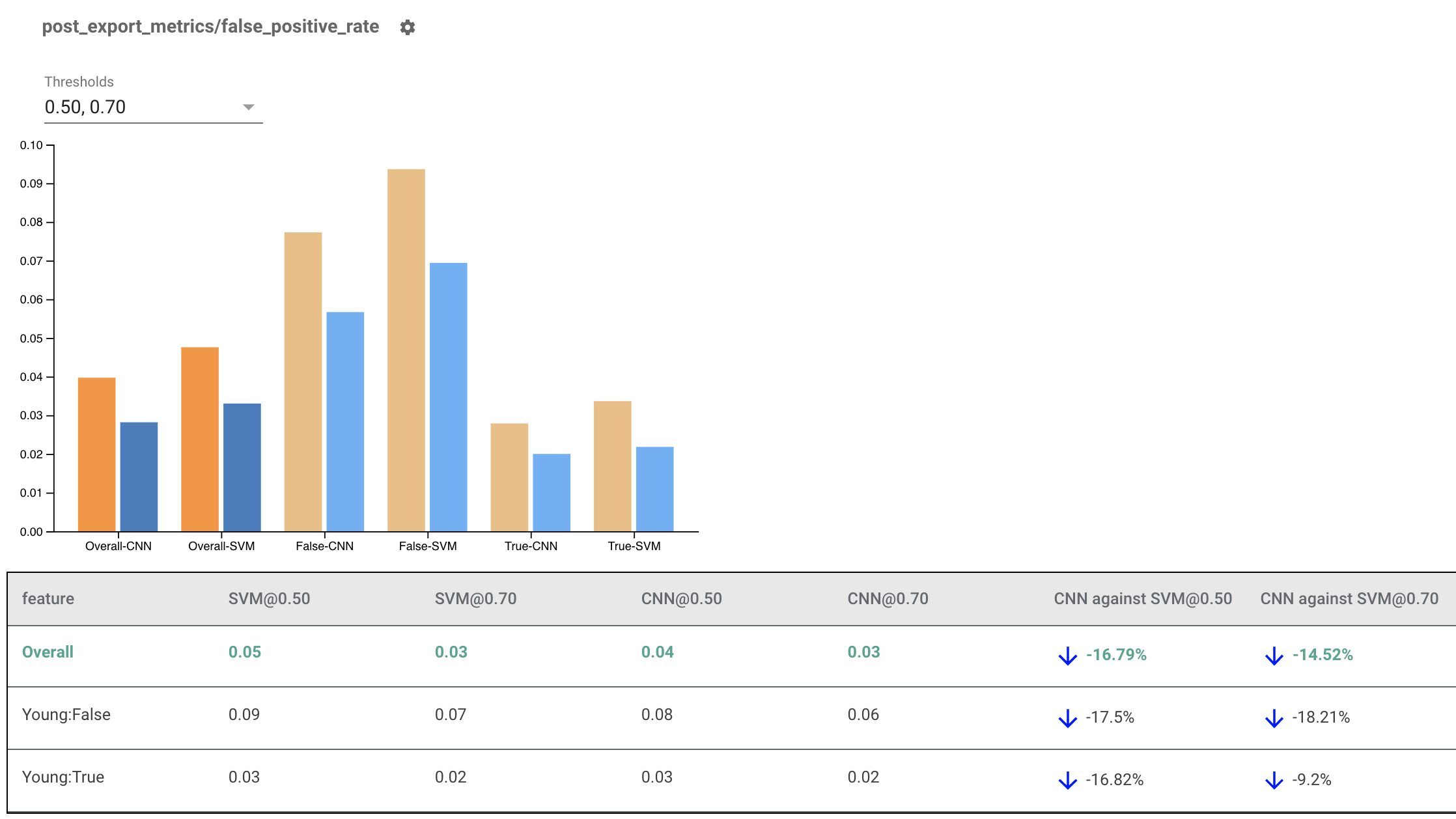
การเปรียบเทียบแบบจำลองสามารถใช้ควบคู่ไปกับการเปรียบเทียบเกณฑ์ได้ ตัวอย่างเช่น คุณสามารถเปรียบเทียบสองโมเดลโดยใช้เกณฑ์สองชุดเพื่อค้นหาชุดค่าผสมที่เหมาะสมที่สุดสำหรับเมตริกความเป็นธรรมของคุณ
การใช้ตัวบ่งชี้ความเป็นธรรมกับโมเดลที่ไม่ใช่ TensorFlow
เพื่อสนับสนุนลูกค้าที่มีโมเดลและเวิร์กโฟลว์ที่แตกต่างกันได้ดียิ่งขึ้น เราได้พัฒนาไลบรารีการประเมินผลซึ่งไม่เชื่อเรื่องโมเดลที่กำลังประเมิน
ใครก็ตามที่ต้องการประเมินระบบแมชชีนเลิร์นนิงของตนก็สามารถใช้ได้ โดยเฉพาะอย่างยิ่งหากคุณมีโมเดลที่ไม่ใช่ TensorFlow เมื่อใช้ Apache Beam Python SDK คุณสามารถสร้างไบนารีการประเมินผล TFMA แบบสแตนด์อโลน จากนั้นเรียกใช้เพื่อวิเคราะห์โมเดลของคุณได้
ข้อมูล
ขั้นตอนนี้คือการจัดหาชุดข้อมูลที่คุณต้องการให้ดำเนินการประเมิน ควรอยู่ในรูปแบบ tf.Example proto ที่มีป้ายกำกับ การคาดคะเน และคุณลักษณะอื่นๆ ที่คุณอาจต้องการแบ่งส่วน
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
แบบอย่าง
แทนที่จะระบุโมเดล คุณจะสร้างการกำหนดค่าและแยกการกำหนดค่า eval ของผู้ไม่เชื่อเรื่องพระเจ้าของโมเดลเพื่อแยกวิเคราะห์และจัดเตรียมข้อมูลที่ TFMA จำเป็นต้องใช้ในการคำนวณเมทริก ข้อมูลจำเพาะ ModelAgnosticConfig กำหนดคุณสมบัติ การคาดการณ์ และป้ายกำกับที่จะใช้จากตัวอย่างอินพุต
สำหรับสิ่งนี้ ให้สร้างแผนผังคุณลักษณะที่มีคีย์ที่แสดงถึงคุณลักษณะทั้งหมด รวมถึงป้ายกำกับและคีย์การทำนาย และค่าที่แสดงถึงประเภทข้อมูลของคุณลักษณะ
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
สร้างการกำหนดค่าที่ไม่เชื่อเรื่องพระเจ้าของโมเดลโดยใช้คีย์ป้ายกำกับ คีย์การทำนาย และแมปคุณลักษณะ
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
ตั้งค่า Model Agnostic Extractor
Extractor ใช้เพื่อแยกฟีเจอร์ ป้ายกำกับ และการคาดคะเนจากอินพุตโดยใช้การกำหนดค่าที่ไม่เชื่อเรื่องโมเดล และหากคุณต้องการแบ่งส่วนข้อมูล คุณจะต้องกำหนด ข้อมูลจำเพาะของคีย์การแบ่งส่วน ซึ่งมีข้อมูลเกี่ยวกับคอลัมน์ที่คุณต้องการแบ่งส่วน
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
เมตริกความเป็นธรรมในการประมวลผล
ในฐานะส่วนหนึ่งของ EvalSharedModel คุณสามารถระบุตัววัดทั้งหมดที่คุณต้องการให้โมเดลของคุณได้รับการประเมิน เมตริกมีให้ในรูปแบบของการเรียกกลับเมตริก เช่นเดียวกับที่กำหนดไว้ใน post_export_metrics หรือ fairness_indicators
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
นอกจากนี้ยังใช้ construct_fn ซึ่งใช้ในการสร้างกราฟเทนเซอร์โฟลว์เพื่อทำการประเมิน
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
เมื่อตั้งค่าทุกอย่างแล้ว ให้ใช้ฟังก์ชัน ExtractEvaluate หรือ ExtractEvaluateAndWriteResults ที่ได้รับจาก model_eval_lib เพื่อประเมินโมเดล
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
สุดท้าย เรนเดอร์ตัวบ่งชี้ความเป็นธรรมโดยใช้คำแนะนำจากส่วน "เรนเดอร์ตัวบ่งชี้ความเป็นธรรม" ด้านบน
ตัวอย่างเพิ่มเติม
ไดเร็กทอรีตัวอย่าง Fairness Indicators มีตัวอย่างหลายตัวอย่าง:
- Fairness_Indicators_Example_Colab.ipynb ให้ภาพรวมของตัวบ่งชี้ความเป็นธรรมใน การวิเคราะห์โมเดล TensorFlow และวิธีการใช้กับชุดข้อมูลจริง สมุดบันทึกนี้ยังครอบคลุมถึง การตรวจสอบความถูกต้องของข้อมูล TensorFlow และ เครื่องมือ What-If ซึ่งเป็น เครื่องมือสองรายการสำหรับการวิเคราะห์แบบจำลอง TensorFlow ที่มาพร้อมกับ Fairness Indicators
- Fairness_Indicators_on_TF_Hub.ipynb สาธิตวิธีใช้ตัวบ่งชี้ความเป็นธรรมเพื่อเปรียบเทียบแบบจำลองที่ได้รับการฝึกเกี่ยวกับ การฝังข้อความ ต่างๆ สมุดบันทึกนี้ใช้การฝังข้อความจาก TensorFlow Hub ซึ่งเป็นไลบรารีของ TensorFlow เพื่อเผยแพร่ ค้นหา และนำส่วนประกอบของโมเดลกลับมาใช้ใหม่
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb สาธิตวิธีแสดงภาพตัวบ่งชี้ความเป็นธรรมใน TensorBoard