
Fairness Indicators está diseñado para ayudar a los equipos a evaluar y mejorar modelos para cuestiones de equidad en asociación con el conjunto de herramientas más amplio de Tensorflow. Actualmente, muchos de nuestros productos utilizan activamente la herramienta internamente y ahora está disponible en versión BETA para probarla en sus propios casos de uso.
¿Qué son los indicadores de equidad?
Fairness Indicators es una biblioteca que permite calcular fácilmente métricas de equidad comúnmente identificadas para clasificadores binarios y multiclase. Muchas herramientas existentes para evaluar cuestiones de equidad no funcionan bien en conjuntos de datos y modelos a gran escala. En Google, es importante para nosotros tener herramientas que puedan funcionar en sistemas de mil millones de usuarios. Los indicadores de equidad le permitirán evaluar casos de uso de cualquier tamaño.
En particular, los Indicadores de Equidad incluyen la capacidad de:
- Evaluar la distribución de conjuntos de datos.
- Evalúe el rendimiento del modelo, dividido en grupos definidos de usuarios
- Siéntase seguro de sus resultados con intervalos de confianza y evaluaciones en múltiples umbrales
- Profundice en sectores individuales para explorar las causas fundamentales y las oportunidades de mejora
La descarga del paquete pip incluye:
- Validación de datos de Tensorflow (TFDV)
- Análisis del modelo Tensorflow (TFMA)
- Indicadores de equidad
- La herramienta What-If (WIT)
Uso de indicadores de equidad con modelos de Tensorflow
Datos
Para ejecutar indicadores de equidad con TFMA, asegúrese de que el conjunto de datos de evaluación esté etiquetado para las características que desea dividir. Si no tiene las características de segmento exactas para sus preocupaciones de equidad, puede intentar encontrar un conjunto de evaluación que las tenga, o considerar características proxy dentro de su conjunto de características que puedan resaltar las disparidades en los resultados. Para obtener orientación adicional, consulte aquí .
Modelo
Puede utilizar la clase Tensorflow Estimator para construir su modelo. La compatibilidad con los modelos Keras llegará pronto a TFMA. Si desea ejecutar TFMA en un modelo de Keras, consulte la sección "TFMA independiente del modelo" a continuación.
Una vez que su Estimador esté entrenado, deberá exportar un modelo guardado para fines de evaluación. Para obtener más información, consulte la guía TFMA .
Configurar sectores
A continuación, defina los sectores que le gustaría evaluar:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Si desea evaluar cortes interseccionales (por ejemplo, tanto el color como la altura del pelaje), puede configurar lo siguiente:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Calcular métricas de equidad
Agregue una devolución de llamada de indicadores de equidad a la lista metrics_callback . En la devolución de llamada, puede definir una lista de umbrales en los que se evaluará el modelo.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Antes de ejecutar la configuración, determine si desea habilitar o no el cálculo de intervalos de confianza. Los intervalos de confianza se calculan mediante arranque de Poisson y requieren un nuevo cálculo en 20 muestras.
compute_confidence_intervals = True
Ejecute el proceso de evaluación de TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Indicadores de equidad de renderizado
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
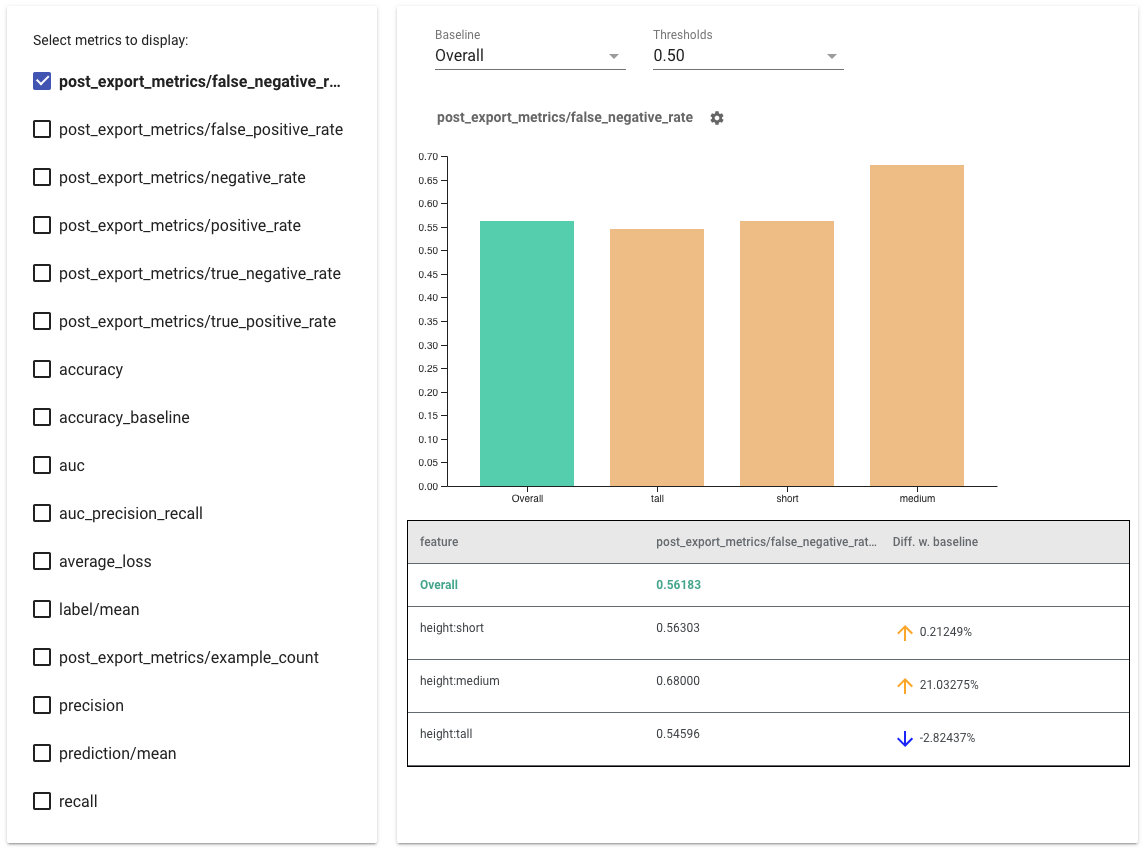
Consejos para utilizar indicadores de equidad:
- Seleccione las métricas para mostrar marcando las casillas en el lado izquierdo. Los gráficos individuales para cada una de las métricas aparecerán en el widget, en orden.
- Cambie el segmento de línea base , la primera barra del gráfico, usando el selector desplegable. Los deltas se calcularán con este valor de referencia.
- Seleccione umbrales usando el selector desplegable. Puede ver varios umbrales en el mismo gráfico. Los umbrales seleccionados aparecerán en negrita y podrá hacer clic en un umbral en negrita para anular su selección.
- Pase el cursor sobre una barra para ver las métricas de esa porción.
- Identifique las disparidades con la línea de base utilizando la columna "Diff w. baseline", que identifica la diferencia porcentual entre el segmento actual y la línea de base.
- Explore los puntos de datos de un segmento en profundidad utilizando la herramienta What-If . Vea aquí un ejemplo.
Representación de indicadores de equidad para múltiples modelos
Los indicadores de equidad también se pueden utilizar para comparar modelos. En lugar de pasar un único eval_result, pase un objeto multi_eval_results, que es un diccionario que asigna dos nombres de modelos a objetos eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
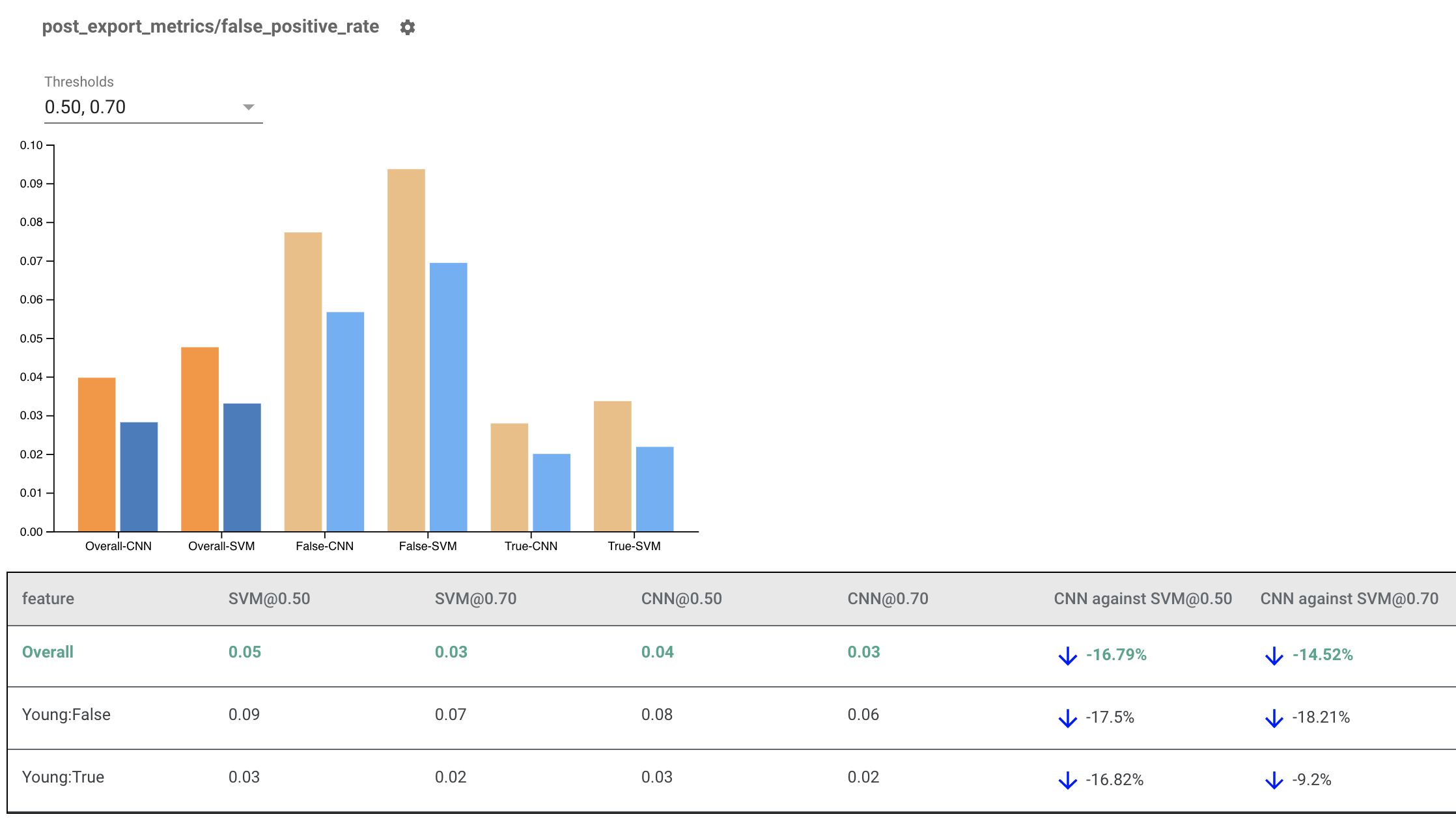
La comparación de modelos se puede utilizar junto con la comparación de umbrales. Por ejemplo, puede comparar dos modelos en dos conjuntos de umbrales para encontrar la combinación óptima para sus métricas de equidad.
Uso de indicadores de equidad con modelos que no son de TensorFlow
Para brindar un mejor soporte a los clientes que tienen diferentes modelos y flujos de trabajo, hemos desarrollado una biblioteca de evaluación que es independiente del modelo que se está evaluando.
Cualquiera que quiera evaluar su sistema de aprendizaje automático puede usarlo, especialmente si tiene modelos que no están basados en TensorFlow. Con el SDK de Apache Beam Python, puede crear un binario de evaluación TFMA independiente y luego ejecutarlo para analizar su modelo.
Datos
Este paso es para proporcionar el conjunto de datos en el que desea que se ejecuten las evaluaciones. Debe estar en formato tf.Proto de ejemplo que tenga etiquetas, predicciones y otras características que quizás desee dividir.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Modelo
En lugar de especificar un modelo, puede crear una configuración de evaluación y un extractor independientes del modelo para analizar y proporcionar los datos que TFMA necesita para calcular las métricas. La especificación ModelAgnosticConfig define las características, predicciones y etiquetas que se utilizarán a partir de los ejemplos de entrada.
Para ello, cree un mapa de características con claves que representen todas las características, incluidas etiquetas y claves de predicción y valores que representen el tipo de datos de la característica.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Cree una configuración independiente del modelo utilizando claves de etiqueta, claves de predicción y el mapa de características.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Configurar el extractor independiente del modelo
Extractor se utiliza para extraer las características, etiquetas y predicciones de la entrada utilizando una configuración independiente del modelo. Y si desea dividir sus datos, también debe definir la especificación de clave de segmento , que contiene información sobre las columnas que desea dividir.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Calcular métricas de equidad
Como parte de EvalSharedModel , puede proporcionar todas las métricas según las cuales desea que se evalúe su modelo. Las métricas se proporcionan en forma de devoluciones de llamadas de métricas como las definidas en post_export_metrics o fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
También incorpora un construct_fn que se utiliza para crear un gráfico de tensorflow para realizar la evaluación.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
Una vez que todo esté configurado, use una de las funciones ExtractEvaluate o ExtractEvaluateAndWriteResults proporcionadas por model_eval_lib para evaluar el modelo.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Finalmente, renderice indicadores de equidad siguiendo las instrucciones de la sección "Renderizar indicadores de equidad" anterior.
Más ejemplos
El directorio de ejemplos de Indicadores de equidad contiene varios ejemplos:
- Fairness_Indicators_Example_Colab.ipynb ofrece una descripción general de los indicadores de equidad en el análisis del modelo TensorFlow y cómo usarlos con un conjunto de datos real. Este cuaderno también analiza la validación de datos de TensorFlow y la herramienta What-If , dos herramientas para analizar modelos de TensorFlow que vienen con indicadores de equidad.
- Fairness_Indicators_on_TF_Hub.ipynb demuestra cómo utilizar indicadores de equidad para comparar modelos entrenados en diferentes incrustaciones de texto . Este cuaderno utiliza incrustaciones de texto de TensorFlow Hub , la biblioteca de TensorFlow para publicar, descubrir y reutilizar componentes del modelo.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb demuestra cómo visualizar indicadores de equidad en TensorBoard.