
ফেয়ারনেস ইন্ডিকেটরগুলি বৃহত্তর টেনসরফ্লো টুলকিটের সাথে অংশীদারিত্বে ন্যায্যতার উদ্বেগের জন্য মডেলগুলি মূল্যায়ন এবং উন্নত করতে দলগুলিকে সহায়তা করার জন্য ডিজাইন করা হয়েছে৷ টুলটি বর্তমানে আমাদের অনেক পণ্য দ্বারা অভ্যন্তরীণভাবে সক্রিয়ভাবে ব্যবহার করা হয়, এবং এখন আপনার নিজের ব্যবহারের ক্ষেত্রে চেষ্টা করার জন্য BETA-তে উপলব্ধ।
ন্যায্যতা সূচক কি?
ফেয়ারনেস ইন্ডিকেটর হল একটি লাইব্রেরি যা বাইনারি এবং মাল্টিক্লাস শ্রেণীবিভাগের জন্য সাধারণভাবে চিহ্নিত ন্যায্যতা মেট্রিক্সের সহজ গণনা সক্ষম করে। ন্যায্যতা উদ্বেগ মূল্যায়নের জন্য বিদ্যমান অনেক সরঞ্জাম বড় আকারের ডেটাসেট এবং মডেলগুলিতে ভাল কাজ করে না। Google-এ, বিলিয়ন-ব্যবহারকারী সিস্টেমে কাজ করতে পারে এমন সরঞ্জাম থাকা আমাদের জন্য গুরুত্বপূর্ণ। ন্যায্যতা সূচকগুলি আপনাকে যেকোনো আকারের ব্যবহারের ক্ষেত্রে মূল্যায়ন করার অনুমতি দেবে।
বিশেষ করে, ন্যায্যতা সূচকগুলির মধ্যে রয়েছে:
- ডেটাসেটের বিতরণ মূল্যায়ন করুন
- মডেল কর্মক্ষমতা মূল্যায়ন, ব্যবহারকারীদের সংজ্ঞায়িত গ্রুপ জুড়ে কাটা
- একাধিক থ্রেশহোল্ডে আত্মবিশ্বাসের ব্যবধান এবং ইভাল সহ আপনার ফলাফল সম্পর্কে আত্মবিশ্বাসী বোধ করুন
- মূল কারণ এবং উন্নতির সুযোগগুলি অন্বেষণ করতে পৃথক স্লাইসের গভীরে ডুব দিন
পাইপ প্যাকেজ ডাউনলোডের মধ্যে রয়েছে:
টেনসরফ্লো মডেলের সাথে ন্যায্যতা সূচক ব্যবহার করা
ডেটা
TFMA এর সাথে ন্যায্যতা সূচকগুলি চালানোর জন্য, নিশ্চিত করুন যে মূল্যায়ন ডেটাসেটটি বৈশিষ্ট্যগুলির জন্য লেবেল করা আছে যা আপনি কাটতে চান৷ যদি আপনার ন্যায্যতার উদ্বেগের জন্য সঠিক স্লাইস বৈশিষ্ট্যগুলি না থাকে, তাহলে আপনি এমন একটি মূল্যায়ন সেট খুঁজে বের করার চেষ্টা করতে পারেন বা আপনার বৈশিষ্ট্য সেটের মধ্যে প্রক্সি বৈশিষ্ট্যগুলি বিবেচনা করতে পারেন যা ফলাফলের বৈষম্যগুলিকে হাইলাইট করতে পারে। অতিরিক্ত নির্দেশিকা জন্য, এখানে দেখুন.
মডেল
আপনি আপনার মডেল তৈরি করতে টেনসরফ্লো এস্টিমেটর ক্লাস ব্যবহার করতে পারেন। কেরাস মডেলের জন্য সমর্থন শীঘ্রই TFMA-তে আসছে। আপনি যদি কেরাস মডেলে TFMA চালাতে চান, অনুগ্রহ করে নীচের "মডেল-অ্যাগনস্টিক TFMA" বিভাগটি দেখুন।
আপনার অনুমানকারী প্রশিক্ষিত হওয়ার পরে, আপনাকে মূল্যায়নের উদ্দেশ্যে একটি সংরক্ষিত মডেল রপ্তানি করতে হবে। আরও জানতে, TFMA নির্দেশিকা দেখুন।
স্লাইস কনফিগার করা হচ্ছে
এর পরে, আপনি যে স্লাইসগুলি মূল্যায়ন করতে চান তা সংজ্ঞায়িত করুন:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
আপনি যদি ইন্টারসেকশনাল স্লাইস মূল্যায়ন করতে চান (উদাহরণস্বরূপ, পশমের রঙ এবং উচ্চতা উভয়), আপনি নিম্নলিখিত সেট করতে পারেন:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
ন্যায্যতা মেট্রিক্স গণনা
metrics_callback তালিকায় একটি ন্যায্যতা সূচক কলব্যাক যোগ করুন। কলব্যাকে, আপনি থ্রেশহোল্ডের একটি তালিকা নির্ধারণ করতে পারেন যেখানে মডেলটি মূল্যায়ন করা হবে।
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
কনফিগারেশন চালানোর আগে, আপনি আত্মবিশ্বাসের ব্যবধানের গণনা সক্ষম করতে চান কিনা তা নির্ধারণ করুন। আত্মবিশ্বাসের ব্যবধানগুলি Poisson বুটস্ট্র্যাপিং ব্যবহার করে গণনা করা হয় এবং 20 টিরও বেশি নমুনা পুনর্গণনার প্রয়োজন হয়।
compute_confidence_intervals = True
TFMA মূল্যায়ন পাইপলাইন চালান:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
ন্যায্যতা সূচক রেন্ডার
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
ন্যায্যতা সূচক ব্যবহার করার জন্য টিপস:
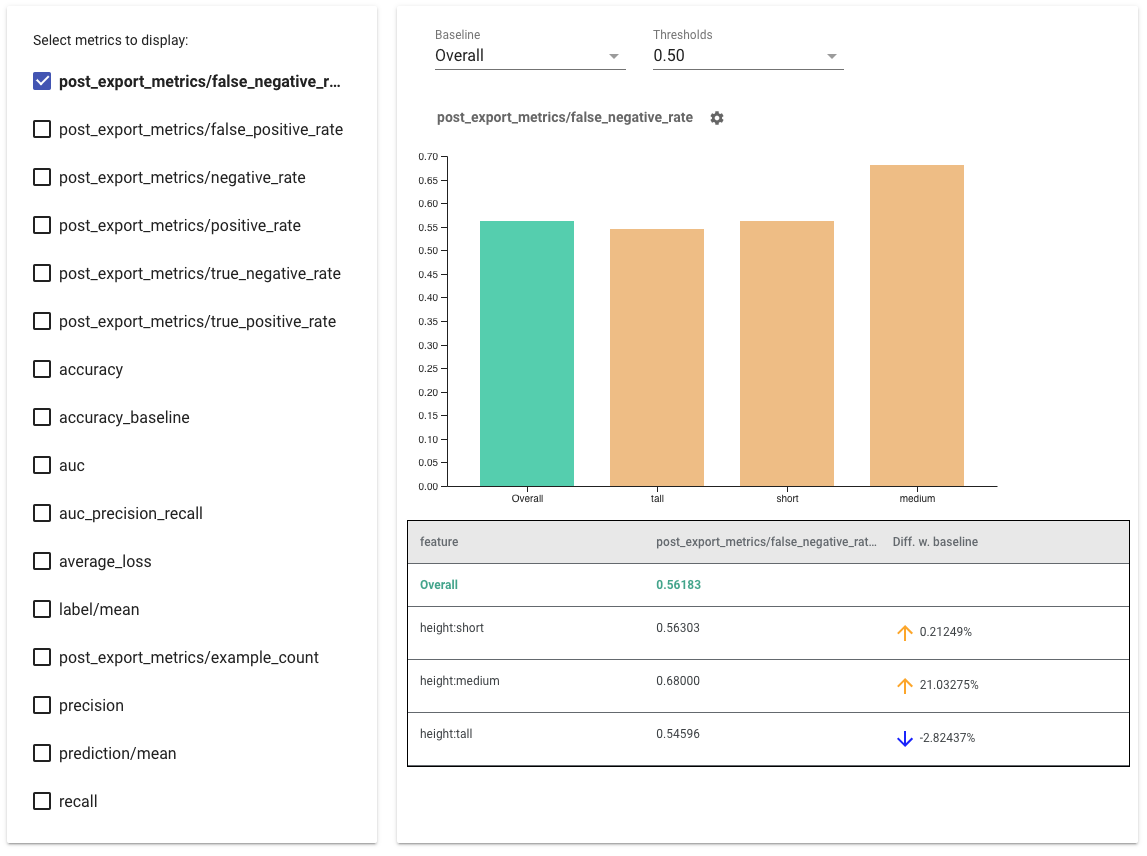
- বাম দিকের বাক্সগুলিতে টিক চিহ্ন দিয়ে প্রদর্শনের জন্য মেট্রিকগুলি নির্বাচন করুন ৷ প্রতিটি মেট্রিকের জন্য পৃথক গ্রাফগুলি উইজেটে, ক্রমানুসারে প্রদর্শিত হবে।
- ড্রপডাউন নির্বাচক ব্যবহার করে বেসলাইন স্লাইস, গ্রাফের প্রথম বার পরিবর্তন করুন । এই বেসলাইন মান দিয়ে ডেল্টা গণনা করা হবে।
- ড্রপডাউন নির্বাচক ব্যবহার করে থ্রেশহোল্ড নির্বাচন করুন । আপনি একই গ্রাফে একাধিক থ্রেশহোল্ড দেখতে পারেন। নির্বাচিত থ্রেশহোল্ডগুলিকে বোল্ড করা হবে এবং আপনি এটিকে আন-সিলেক্ট করতে একটি বোল্ড থ্রেশহোল্ডে ক্লিক করতে পারেন৷
- সেই স্লাইসের জন্য মেট্রিক্স দেখতে একটি বারের উপর হোভার করুন ।
- "ডিফ ডব্লিউ বেসলাইন" কলাম ব্যবহার করে বেসলাইনের সাথে অসমতা চিহ্নিত করুন , যা বর্তমান স্লাইস এবং বেসলাইনের মধ্যে শতাংশের পার্থক্য চিহ্নিত করে।
- What-If টুল ব্যবহার করে গভীরভাবে একটি স্লাইসের ডেটা পয়েন্টগুলি অন্বেষণ করুন । একটি উদাহরণের জন্য এখানে দেখুন.
একাধিক মডেলের জন্য ন্যায্যতা নির্দেশক রেন্ডারিং
ন্যায্যতা সূচক মডেল তুলনা করতে ব্যবহার করা যেতে পারে. একটি একক eval_result এ পাস করার পরিবর্তে, একটি multi_eval_results অবজেক্টে পাস করুন, যা একটি অভিধান যা eval_result অবজেক্টে দুটি মডেলের নাম ম্যাপ করছে।
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
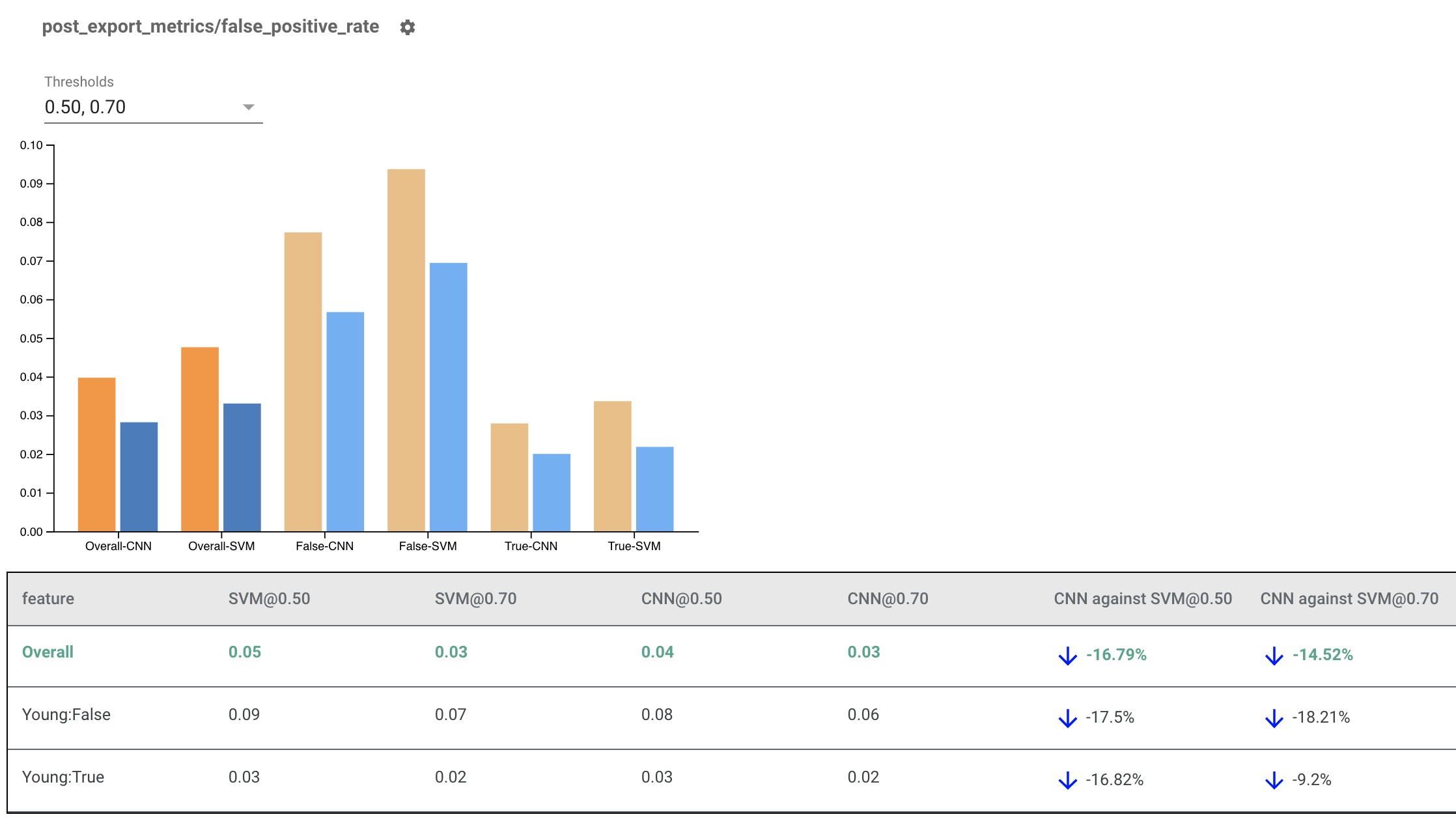
থ্রেশহোল্ড তুলনার পাশাপাশি মডেল তুলনা ব্যবহার করা যেতে পারে। উদাহরণস্বরূপ, আপনি আপনার ন্যায্যতা মেট্রিক্সের জন্য সর্বোত্তম সমন্বয় খুঁজে পেতে থ্রেশহোল্ডের দুটি সেটে দুটি মডেলের তুলনা করতে পারেন।
নন-টেনসরফ্লো মডেলের সাথে ফেয়ারনেস ইন্ডিকেটর ব্যবহার করা
বিভিন্ন মডেল এবং ওয়ার্কফ্লো আছে এমন ক্লায়েন্টদের আরও ভালভাবে সমর্থন করার জন্য, আমরা একটি মূল্যায়ন লাইব্রেরি তৈরি করেছি যা মূল্যায়ন করা মডেলের জন্য অজ্ঞেয়।
যে কেউ তাদের মেশিন লার্নিং সিস্টেমের মূল্যায়ন করতে চান তারা এটি ব্যবহার করতে পারেন, বিশেষ করে যদি আপনার নন-টেনসরফ্লো ভিত্তিক মডেল থাকে। Apache Beam Python SDK ব্যবহার করে, আপনি একটি স্বতন্ত্র TFMA মূল্যায়ন বাইনারি তৈরি করতে পারেন এবং তারপর আপনার মডেল বিশ্লেষণ করতে এটি চালাতে পারেন।
ডেটা
এই পদক্ষেপটি হল ডেটাসেট প্রদান করা যা আপনি মূল্যায়নগুলি চালাতে চান৷ এটি tf. উদাহরণ প্রোটো বিন্যাসে হওয়া উচিত যাতে লেবেল, ভবিষ্যদ্বাণী এবং অন্যান্য বৈশিষ্ট্য রয়েছে যা আপনি স্লাইস করতে চান৷
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
মডেল
একটি মডেল নির্দিষ্ট করার পরিবর্তে, আপনি একটি মডেল অজ্ঞেয়বাদী ইভাল কনফিগারেশন এবং এক্সট্রাক্টর তৈরি করুন এবং মেট্রিক্স গণনা করার জন্য TFMA-এর প্রয়োজনীয় ডেটা পার্স এবং প্রদান করুন। ModelAgnosticConfig স্পেক ইনপুট উদাহরণ থেকে ব্যবহার করা বৈশিষ্ট্য, ভবিষ্যদ্বাণী এবং লেবেল সংজ্ঞায়িত করে।
এর জন্য, লেবেল এবং ভবিষ্যদ্বাণী কী এবং বৈশিষ্ট্যের ডেটা টাইপ প্রতিনিধিত্বকারী মান সহ সমস্ত বৈশিষ্ট্য উপস্থাপন করে কীগুলির সাথে একটি বৈশিষ্ট্য মানচিত্র তৈরি করুন।
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
লেবেল কী, পূর্বাভাস কী এবং বৈশিষ্ট্য মানচিত্র ব্যবহার করে একটি মডেল অজ্ঞেয়বাদী কনফিগার তৈরি করুন।
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
মডেল অ্যাগনস্টিক এক্সট্র্যাক্টর সেট আপ করুন
মডেল অ্যাগনস্টিক কনফিগারেশন ব্যবহার করে ইনপুট থেকে বৈশিষ্ট্য, লেবেল এবং পূর্বাভাস বের করতে এক্সট্র্যাক্টর ব্যবহার করা হয়। এবং আপনি যদি আপনার ডেটা স্লাইস করতে চান তবে আপনাকে স্লাইস কী স্পেকটিও সংজ্ঞায়িত করতে হবে, যেখানে আপনি যে কলামগুলি স্লাইস করতে চান সে সম্পর্কে তথ্য রয়েছে।
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
ন্যায্যতা মেট্রিক্স গণনা
EvalSharedModel- এর অংশ হিসাবে, আপনি আপনার মডেলের মূল্যায়ন করতে চান এমন সমস্ত মেট্রিক্স প্রদান করতে পারেন। মেট্রিক্স মেট্রিক্স কলব্যাক আকারে প্রদান করা হয় যেমন post_export_metrics বা fairness_indicators এ সংজ্ঞায়িত করা হয়েছে।
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
এটি একটি construct_fn ও নেয় যা মূল্যায়ন করার জন্য একটি টেনসরফ্লো গ্রাফ তৈরি করতে ব্যবহৃত হয়।
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
সবকিছু সেট আপ হয়ে গেলে, মডেলটি মূল্যায়ন করতে model_eval_lib দ্বারা প্রদত্ত ExtractEvaluate বা ExtractEvaluateAndWriteResults ফাংশনগুলির একটি ব্যবহার করুন।
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
অবশেষে, উপরের "রেন্ডার ফেয়ারনেস ইন্ডিকেটর" বিভাগের নির্দেশাবলী ব্যবহার করে ন্যায্যতা সূচক রেন্ডার করুন।
আরো উদাহরণ
ন্যায্যতা নির্দেশক উদাহরণ ডিরেক্টরিতে বেশ কয়েকটি উদাহরণ রয়েছে:
- Fairness_Indicators_Example_Colab.ipynb টেনসরফ্লো মডেল বিশ্লেষণে ন্যায্যতা সূচকগুলির একটি ওভারভিউ দেয় এবং কীভাবে এটি একটি বাস্তব ডেটাসেটের সাথে ব্যবহার করতে হয়। এই নোটবুকটি টেনসরফ্লো ডেটা ভ্যালিডেশন এবং হোয়াট-ইফ টুলের উপরেও যায়, টেনসরফ্লো মডেল বিশ্লেষণ করার জন্য দুটি টুল যা ফেয়ারনেস ইন্ডিকেটর দিয়ে প্যাকেজ করা হয়।
- Fairness_Indicators_on_TF_Hub.ipynb প্রদর্শন করে কিভাবে বিভিন্ন টেক্সট এম্বেডিং -এ প্রশিক্ষিত মডেলের তুলনা করতে ফেয়ারনেস ইন্ডিকেটর ব্যবহার করতে হয়। এই নোটবুকটি মডেলের উপাদান প্রকাশ, আবিষ্কার এবং পুনরায় ব্যবহার করতে TensorFlow Hub , TensorFlow-এর লাইব্রেরি থেকে পাঠ্য এম্বেডিং ব্যবহার করে।
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb প্রদর্শন করে কিভাবে টেনসরবোর্ডে ন্যায্যতা সূচকগুলিকে কল্পনা করা যায়।