
Fairness Indicators は、より広範な Tensorflow ツールキットと連携して、公平性の問題に対するモデルの評価と改善を行うチームをサポートするように設計されています。このツールは現在、多くの製品で社内で積極的に使用されており、独自のユースケースで試していただけるベータ版が提供されています。
公平性指標とは何ですか?
Fairness Indicators は、バイナリおよびマルチクラス分類子に対して一般的に識別される公平性メトリクスを簡単に計算できるようにするライブラリです。公平性の問題を評価するための既存のツールの多くは、大規模なデータセットやモデルではうまく機能しません。 Google では、10 億人のユーザー システムで動作するツールを用意することが重要です。公平性インジケーターを使用すると、あらゆる規模のユースケースを評価できます。
特に、公平性インジケーターには次の機能が含まれています。
- データセットの分布を評価する
- 定義されたユーザーのグループ全体でモデルのパフォーマンスを評価します
- 信頼区間と複数のしきい値での評価により、結果に自信を持ちます
- 個々のスライスを深く掘り下げて、根本原因と改善の機会を探ります
pip パッケージのダウンロードには次のものが含まれます。
Tensorflow モデルでの公平性インジケーターの使用
データ
TFMA を使用して公平性インジケーターを実行するには、スライスする特徴のラベルが評価データセットに付けられていることを確認してください。公平性の懸念に対応する正確なスライス機能がない場合は、機能セット内で結果の差異を強調する可能性のあるプロキシ機能を検討するか、機能セット内のプロキシ機能を検討することを検討してください。追加のガイダンスについては、ここを参照してください。
モデル
Tensorflow Estimator クラスを使用してモデルを構築できます。 Keras モデルのサポートが TFMA で間もなく開始されます。 Keras モデルで TFMA を実行したい場合は、以下の「モデルに依存しない TFMA」セクションを参照してください。
Estimator がトレーニングされた後、評価目的で保存されたモデルをエクスポートする必要があります。詳細については、 TFMA ガイドを参照してください。
スライスの構成
次に、評価するスライスを定義します。
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
交差するスライス (たとえば、ファーの色と高さの両方) を評価する場合は、次のように設定できます。
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
公平性メトリクスの計算
Fairness Indicators コールバックをmetrics_callbackリストに追加します。コールバックでは、モデルが評価されるしきい値のリストを定義できます。
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
設定を実行する前に、信頼区間の計算を有効にするかどうかを決定します。信頼区間はポアソン ブートストラップを使用して計算され、20 サンプルにわたる再計算が必要です。
compute_confidence_intervals = True
TFMA 評価パイプラインを実行します。
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
レンダリング公平性インジケーター
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
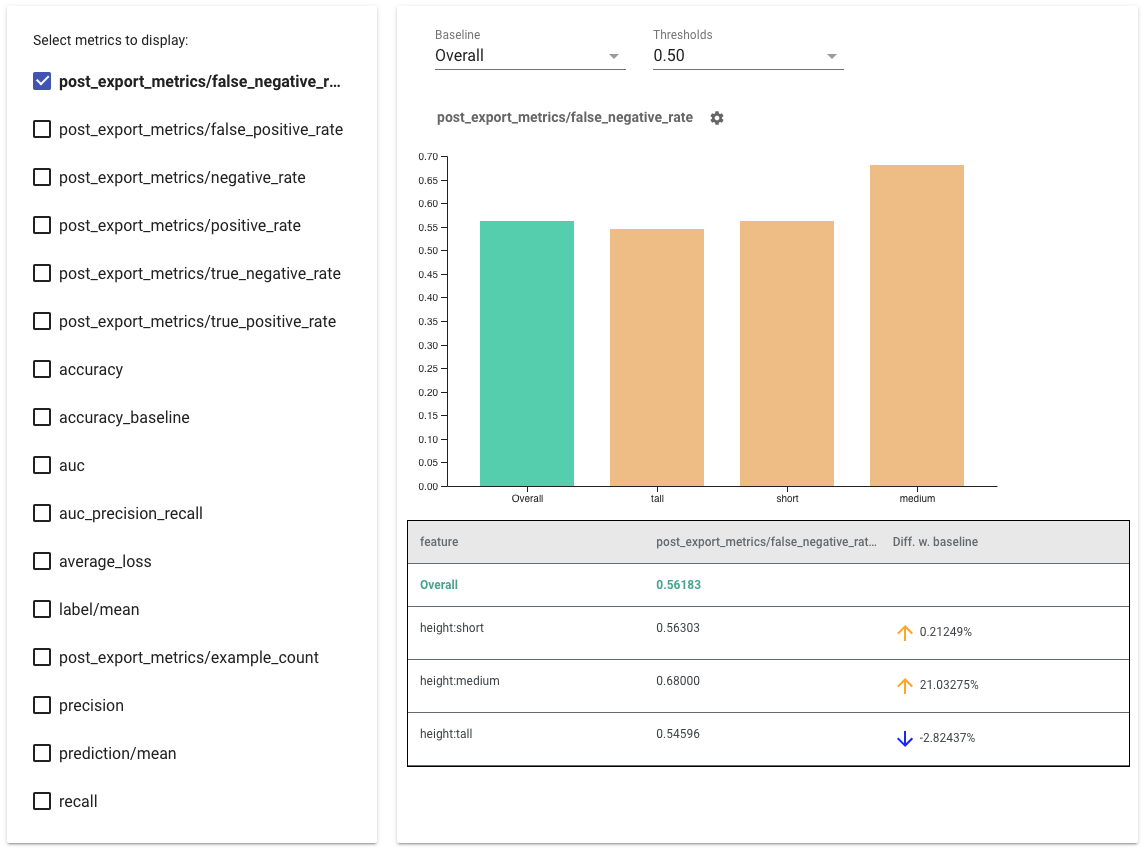
公平性インジケーターを使用するためのヒント:
- 左側のボックスをチェックして、表示するメトリクスを選択します。各メトリクスの個別のグラフがウィジェットに順番に表示されます。
- ドロップダウン セレクターを使用して、グラフの最初のバーであるベースライン スライスを変更します。デルタはこのベースライン値を使用して計算されます。
- ドロップダウン セレクターを使用してしきい値を選択します。同じグラフ上に複数のしきい値を表示できます。選択したしきい値は太字で表示され、太字のしきい値をクリックすると選択を解除できます。
- バーの上にマウスを置くと、そのスライスのメトリクスが表示されます。
- 「ベースラインとの差」列を使用して、ベースラインとの差異を特定します。これは、現在のスライスとベースラインの間の差異のパーセンテージを特定します。
- What-If ツールを使用して、スライスのデータ ポイントを詳しく調べます。例については、ここを参照してください。
複数のモデルのレンダリング公平性インジケーター
公平性インジケーターは、モデルの比較にも使用できます。単一の eval_result を渡す代わりに、multi_eval_results オブジェクトを渡します。これは、2 つのモデル名を eval_result オブジェクトにマッピングする辞書です。
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
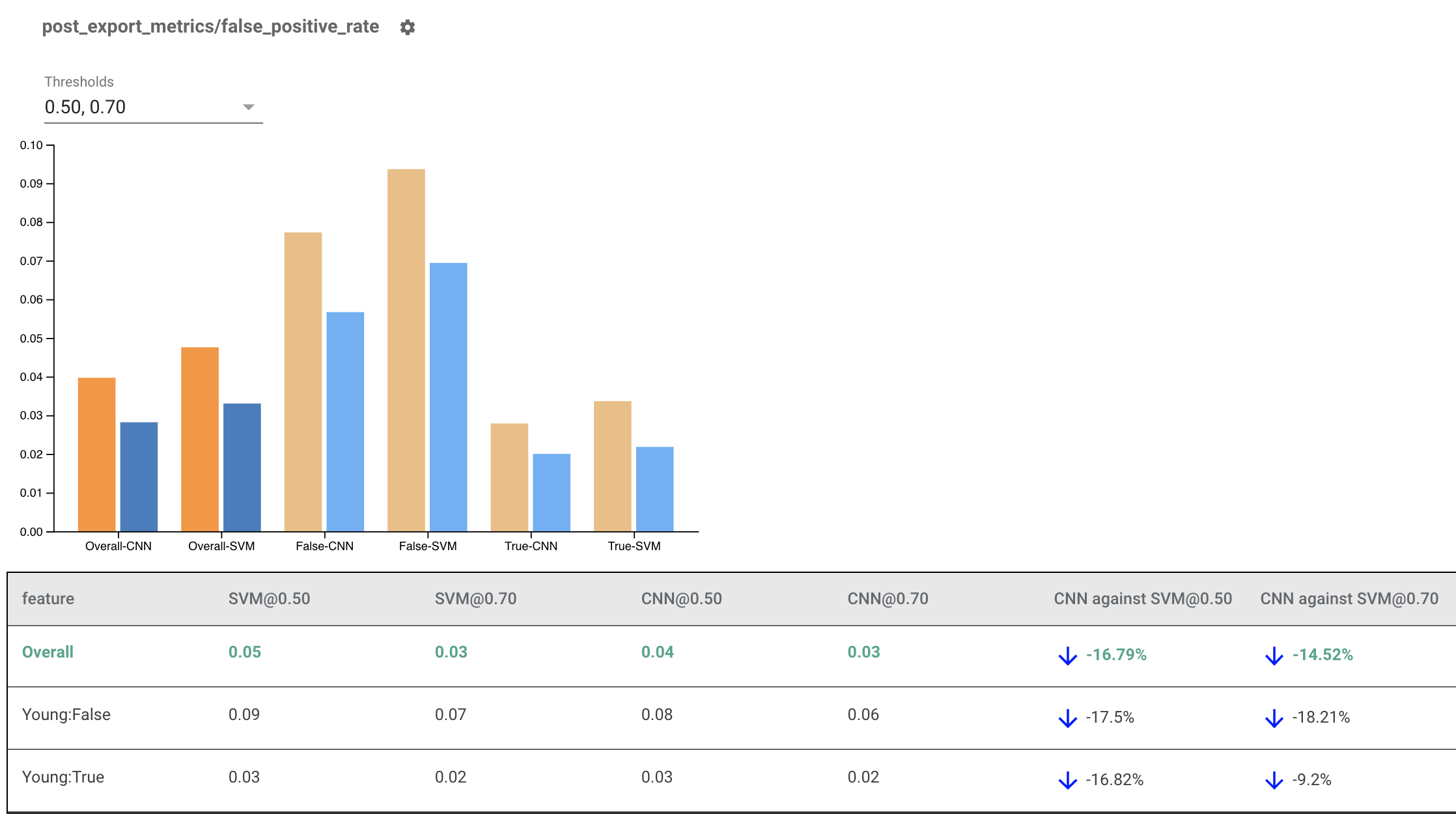
モデル比較は、しきい値比較と並行して使用できます。たとえば、2 つのしきい値セットで 2 つのモデルを比較して、公平性メトリクスに最適な組み合わせを見つけることができます。
非 TensorFlow モデルでの公平性インジケーターの使用
さまざまなモデルやワークフローを持つクライアントをより適切にサポートするために、評価対象のモデルに依存しない評価ライブラリを開発しました。
機械学習システムを評価したい人は誰でも、特に非 TensorFlow ベースのモデルを使用している場合にこれを使用できます。 Apache Beam Python SDK を使用すると、スタンドアロン TFMA 評価バイナリを作成し、それを実行してモデルを分析できます。
データ
このステップでは、評価を実行するデータセットを提供します。これは、ラベル、予測、スライスしたいその他の機能を含むtf.Example proto 形式である必要があります。
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
モデル
モデルを指定する代わりに、モデルに依存しない eval 構成とエクストラクターを作成して、TFMA がメトリクスを計算するために必要なデータを解析して提供します。 ModelAgnosticConfig仕様は、入力例から使用される特徴、予測、ラベルを定義します。
このために、ラベルおよび予測キーを含むすべての特徴を表すキーと、特徴のデータ型を表す値を含む特徴マップを作成します。
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
ラベル キー、予測キー、および特徴マップを使用して、モデルに依存しない構成を作成します。
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
モデルに依存しないエクストラクターのセットアップ
Extractorは、モデルに依存しない構成を使用して入力から特徴、ラベル、予測を抽出するために使用されます。データをスライスする場合は、スライスする列に関する情報を含むスライス キー仕様も定義する必要があります。
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
公平性メトリクスの計算
EvalSharedModelの一部として、モデルを評価するすべてのメトリクスを提供できます。メトリクスは、 post_export_metricsまたはFairness_indicatorsで定義されているようなメトリクス コールバックの形式で提供されます。
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
また、評価を実行するためのテンソルフロー グラフを作成するために使用されるconstruct_fnも取り込みます。
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
すべての設定が完了したら、 model_eval_libによって提供されるExtractEvaluateまたはExtractEvaluateAndWriteResults関数のいずれかを使用してモデルを評価します。
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
最後に、上記の「公平性インジケーターのレンダリング」セクションの手順に従って、公平性インジケーターをレンダリングします。
他の例
Fairness Indicators のサンプル ディレクトリには、いくつかの例が含まれています。
- Fairness_Indicators_Example_Colab.ipynbでは、TensorFlow モデル分析における公平性インジケーターの概要と、それを実際のデータセットで使用する方法を説明します。このノートブックでは、公平性インジケーターにパッケージ化されている TensorFlow モデルを分析するための 2 つのツールであるTensorFlow Data ValidationとWhat-If Toolについても説明します。
- Fairness_Indicators_on_TF_Hub.ipynbは、公平性インジケーターを使用して、さまざまなテキスト埋め込みでトレーニングされたモデルを比較する方法を示しています。このノートブックは、TensorFlow のライブラリであるTensorFlow Hubのテキスト埋め込みを使用して、モデル コンポーネントを公開、検出、再利用します。
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynbは、TensorBoard でフェアネス インジケーターを視覚化する方法を示します。