
Il componente EsempioGen TFX Pipeline inserisce i dati nelle pipeline TFX. Consuma file/servizi esterni per generare esempi che verranno letti da altri componenti TFX. Fornisce inoltre una partizione coerente e configurabile e mescola il set di dati per le migliori pratiche di machine learning.
- Consuma: dati provenienti da origini dati esterne come CSV,
TFRecord, Avro, Parquet e BigQuery. - Genera: record
tf.Example, recordtf.SequenceExampleo formato proto, a seconda del formato del payload.
EsempioGen e altri componenti
EsempioGen fornisce dati ai componenti che utilizzano la libreria TensorFlow Data Validation , come SchemaGen , StatisticsGen e Esempio Validator . Fornisce inoltre dati a Transform , che utilizza la libreria TensorFlow Transform , e infine alle destinazioni di distribuzione durante l'inferenza.
Origini e formati dei dati
Attualmente un'installazione standard di TFX include componenti EsempiGen completi per queste origini dati e formati:
Sono disponibili anche esecutori personalizzati che consentono lo sviluppo di componenti EsempioGen per queste origini dati e formati:
Vedi gli esempi di utilizzo nel codice sorgente e questa discussione per ulteriori informazioni su come utilizzare e sviluppare esecutori personalizzati.
Inoltre, queste origini dati e formati sono disponibili come esempi di componenti personalizzati :
Acquisizione di formati di dati supportati da Apache Beam
Apache Beam supporta l'acquisizione di dati da un'ampia gamma di origini dati e formati ( vedere di seguito ). Queste funzionalità possono essere utilizzate per creare componenti EsempioGen personalizzati per TFX, come dimostrato da alcuni componenti EsempioGen esistenti ( vedi sotto ).
Come utilizzare un componente EsempioGen
Per le origini dati supportate (attualmente file CSV, file TFRecord con formato tf.Example , tf.SequenceExample e proto e risultati delle query BigQuery) il componente della pipeline EsempioGen può essere utilizzato direttamente nella distribuzione e richiede poca personalizzazione. Per esempio:
example_gen = CsvExampleGen(input_base='data_root')
o come di seguito per importare TFRecord esterno direttamente con tf.Example :
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Span, versione e suddivisione
Uno Span è un raggruppamento di esempi di formazione. Se i tuoi dati sono persistenti su un filesystem, ogni Span può essere archiviato in una directory separata. La semantica di uno Span non è codificata in TFX; un intervallo può corrispondere a un giorno di dati, a un'ora di dati o a qualsiasi altro raggruppamento significativo per l'attività.
Ciascun intervallo può contenere più versioni di dati. Per fare un esempio, se rimuovi alcuni esempi da uno span per ripulire dati di scarsa qualità, ciò potrebbe comportare una nuova versione di quello span. Per impostazione predefinita, i componenti TFX funzionano sulla versione più recente all'interno di un intervallo.
Ciascuna Versione all'interno di uno Span può essere ulteriormente suddivisa in più Split. Il caso d'uso più comune per suddividere uno Span è dividerlo in dati di training e di valutazione.
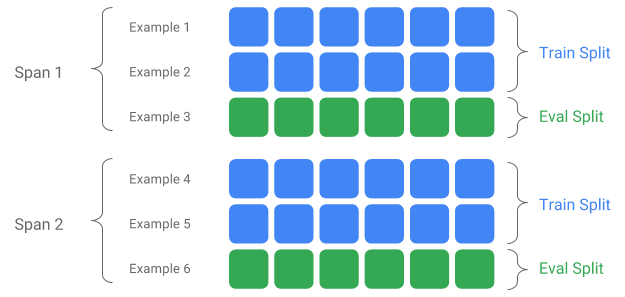
Suddivisione ingresso/uscita personalizzata
Per personalizzare il rapporto di suddivisione treno/valutazione che EsempioGen restituirà, imposta output_config per il componente EsempioGen. Per esempio:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Nota come sono stati impostati gli hash_buckets in questo esempio.
Per una sorgente di input che è già stata divisa, imposta input_config per il componente EsempioGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Per la generazione di esempi basata su file (ad esempio CsvExampleGen e ImportExampleGen), pattern è un modello di file relativo glob che si associa ai file di input con la directory root fornita dal percorso di base di input. Per la generazione di esempi basata su query (ad esempio BigQueryExampleGen, PrestoExampleGen), pattern è una query SQL.
Per impostazione predefinita, l'intera directory di base dell'input viene trattata come una singola suddivisione dell'input e la suddivisione dell'output train ed eval viene generata con un rapporto 2:1.
Fare riferimento a proto/example_gen.proto per la configurazione divisa di input e output di EsempioGen. E fare riferimento alla guida ai componenti downstream per utilizzare le suddivisioni personalizzate a valle.
Metodo di divisione
Quando si utilizza il metodo di suddivisione hash_buckets , invece dell'intero record, è possibile utilizzare una funzionalità per partizionare gli esempi. Se una funzionalità è presente, EsempioGen utilizzerà un'impronta digitale di tale funzionalità come chiave di partizione.
Questa funzionalità può essere utilizzata per mantenere una suddivisione stabile rispetto a determinate proprietà degli esempi: ad esempio, un utente verrà sempre inserito nella stessa suddivisione se "id_utente" è stato selezionato come nome della funzionalità della partizione.
L'interpretazione di cosa significhi una "funzionalità" e come abbinare una "funzionalità" al nome specificato dipende dall'implementazione di EsempioGen e dal tipo di esempi.
Per implementazioni di EsempioGen già pronte:
- Se genera tf.Example, una "funzionalità" indica una voce in tf.Example.features.feature.
- Se genera tf.SequenceExample, una "funzionalità" indica una voce in tf.SequenceExample.context.feature.
- Sono supportate solo le funzionalità int64 e byte.
Nei seguenti casi, EsempioGen genera errori di runtime:
- Il nome della funzione specificata non esiste nell'esempio.
- Funzionalità vuota:
tf.train.Feature(). - Tipi di funzionalità non supportate, ad esempio funzionalità float.
Per generare la suddivisione train/eval in base a una funzionalità negli esempi, imposta output_config per il componente EsempioGen. Per esempio:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Notare come è stato impostato partition_feature_name in questo esempio.
Durata
Lo span può essere recuperato utilizzando la specifica '{SPAN}' nel pattern glob di input :
- Questa specifica abbina le cifre e mappa i dati nei numeri SPAN pertinenti. Ad esempio, 'data_{SPAN}-*.tfrecord' raccoglierà file come 'data_12-a.tfrecord', 'data_12-b.tfrecord'.
- Facoltativamente, questa specifica può essere specificata con la larghezza degli interi quando mappata. Ad esempio, "data_{SPAN:2}.file" viene mappato a file come "data_02.file" e "data_27.file" (come input rispettivamente per Span-2 e Span-27), ma non viene mappato a "data_1. file' né 'data_123.file'.
- Quando manca la specifica SPAN, si presuppone che sia sempre Span '0'.
- Se viene specificato SPAN, la pipeline elaborerà l'intervallo più recente e memorizzerà il numero di intervallo nei metadati.
Ad esempio, supponiamo che ci siano dati di input:
- '/tmp/span-1/treno/dati'
- '/tmp/span-1/eval/dati'
- '/tmp/span-2/treno/dati'
- '/tmp/span-2/eval/dati'
e la configurazione dell'input è mostrata come di seguito:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
quando si attiva la pipeline, elaborerà:
- '/tmp/span-2/train/data' come suddivisione del treno
- '/tmp/span-2/eval/data' come suddivisione eval
con numero di span come "2". Se in seguito '/tmp/span-3/...' sono pronti, è sufficiente attivare nuovamente la pipeline e prenderà lo span '3' per l'elaborazione. Di seguito è riportato l'esempio di codice per l'utilizzo delle specifiche span:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Il recupero di un determinato intervallo può essere eseguito con RangeConfig, descritto in dettaglio di seguito.
Data
Se la tua origine dati è organizzata sul file system per data, TFX supporta la mappatura delle date direttamente sui numeri. Esistono tre specifiche per rappresentare la mappatura dalle date agli intervalli: {AAAA}, {MM} e {GG}:
- Le tre specifiche dovrebbero essere completamente presenti nel modello glob di input, se ne viene specificata una:
- È possibile specificare esclusivamente la specifica {SPAN} o questo insieme di specifiche della data.
- Viene calcolata una data di calendario con l'anno da AAAA, il mese da MM e il giorno del mese da GG, quindi il numero di intervallo viene calcolato come il numero di giorni dall'epoca unix (ovvero 1970-01-01). Ad esempio, 'log-{YYYY}{MM}{DD}.data' corrisponde a un file 'log-19700101.data' e lo utilizza come input per Span-0 e 'log-20170101.data' come input per Periodo-17167.
- Se viene specificato questo insieme di specifiche di data, la pipeline elaborerà la data più recente e memorizzerà il numero di intervallo corrispondente nei metadati.
Ad esempio, supponiamo che ci siano dati di input organizzati per data di calendario:
- '/tmp/1970-01-02/treno/dati'
- '/tmp/1970-01-02/eval/dati'
- '/tmp/1970-01-03/treno/dati'
- '/tmp/1970-01-03/eval/dati'
e la configurazione dell'input è mostrata come di seguito:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
quando si attiva la pipeline, elaborerà:
- '/tmp/1970-01-03/train/data' come suddivisione del treno
- '/tmp/1970-01-03/eval/data' come divisione eval
con numero di span come "2". Se in seguito '/tmp/1970-01-04/...' sarà pronto, sarà sufficiente attivare nuovamente la pipeline e questa prenderà l'intervallo '3' per l'elaborazione. Di seguito viene mostrato l'esempio di codice per l'utilizzo delle specifiche della data:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Versione
La versione può essere recuperata utilizzando la specifica '{VERSION}' nel pattern glob di input :
- Questa specifica abbina le cifre e mappa i dati sui numeri di VERSIONE rilevanti sotto SPAN. Tieni presente che la specifica della versione può essere utilizzata in combinazione con la specifica dell'intervallo o della data.
- Questa specifica può anche essere facoltativamente specificata con la larghezza allo stesso modo della specifica SPAN. ad esempio 'span-{SPAN}/versione-{VERSION:4}/data-*'.
- Quando manca la specifica VERSION, la versione è impostata su None.
- Se SPAN e VERSION sono entrambi specificati, la pipeline elaborerà la versione più recente per l'intervallo più recente e memorizzerà il numero di versione nei metadati.
- Se viene specificata VERSIONE, ma non SPAN (o specifica della data), verrà generato un errore.
Ad esempio, supponiamo che ci siano dati di input:
- '/tmp/span-1/ver-1/treno/dati'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/treno/dati'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/treno/dati'
- '/tmp/span-2/ver-2/eval/data'
e la configurazione dell'input è mostrata come di seguito:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
quando si attiva la pipeline, elaborerà:
- '/tmp/span-2/ver-2/train/data' come suddivisione del treno
- '/tmp/span-2/ver-2/eval/data' come suddivisione eval
con numero di estensione come "2" e numero di versione come "2". Se in seguito '/tmp/span-2/ver-3/...' sono pronti, è sufficiente attivare nuovamente la pipeline e prenderà lo span '2' e la versione '3' per l'elaborazione. Di seguito è mostrato l'esempio di codice per l'utilizzo delle specifiche della versione:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Configurazione intervallo
TFX supporta il recupero e l'elaborazione di un intervallo specifico in EsempioGen basato su file utilizzando range config, una configurazione astratta utilizzata per descrivere intervalli per diverse entità TFX. Per recuperare un intervallo specifico, imposta range_config per un componente EsempioGen basato su file. Ad esempio, supponiamo che ci siano dati di input:
- '/tmp/span-01/treno/dati'
- '/tmp/span-01/eval/dati'
- '/tmp/span-02/treno/dati'
- '/tmp/span-02/eval/dati'
Per recuperare ed elaborare in modo specifico i dati con l'intervallo "1", specifichiamo una configurazione di intervallo oltre alla configurazione di input. Tieni presente che EsempioGen supporta solo intervalli statici a campata singola (per specificare l'elaborazione di campate individuali specifiche). Pertanto, per StaticRange, start_span_number deve essere uguale a end_span_number. Utilizzando l'intervallo fornito e le informazioni sulla larghezza dell'intervallo (se fornite) per il riempimento zero, EsempioGen sostituirà la specifica SPAN nei modelli di suddivisione forniti con il numero di intervallo desiderato. Di seguito è riportato un esempio di utilizzo:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
La configurazione dell'intervallo può essere utilizzata anche per elaborare date specifiche, se viene utilizzata la specifica della data anziché la specifica SPAN. Ad esempio, supponiamo che ci siano dati di input organizzati per data di calendario:
- '/tmp/1970-01-02/treno/dati'
- '/tmp/1970-01-02/eval/dati'
- '/tmp/1970-01-03/treno/dati'
- '/tmp/1970-01-03/eval/dati'
Per recuperare ed elaborare specificamente i dati relativi al 2 gennaio 1970, facciamo quanto segue:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Esempio personalizzatoGen
Se i componenti EsempioGen attualmente disponibili non soddisfano le tue esigenze, puoi creare un EsempioGen personalizzato, che ti consentirà di leggere da diverse origini dati o in diversi formati di dati.
Personalizzazione di exampleGen basata su file (sperimentale)
Innanzitutto, estendi BaseExampleGenExecutor con un Beam PTransform personalizzato, che fornisce la conversione dalla suddivisione dell'input train/eval in esempi TF. Ad esempio, l' esecutore CsvExampleGen fornisce la conversione da una suddivisione CSV di input in esempi TF.
Quindi, crea un componente con l'esecutore sopra, come fatto in CsvExampleGen componente . In alternativa, passa un esecutore personalizzato nel componente EsempioGen standard come mostrato di seguito.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Ora supportiamo anche la lettura di file Avro e Parquet utilizzando questo metodo .
Formati dati aggiuntivi
Apache Beam supporta la lettura di numerosi formati di dati aggiuntivi . attraverso le trasformazioni I/O del fascio. Puoi creare componenti EsempioGen personalizzati sfruttando le trasformazioni Beam I/O utilizzando un modello simile all'esempio Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
Al momento della stesura di questo documento i formati e le origini dati attualmente supportati per Beam Python SDK includono:
- Amazon S3
- Apache Avro
- Apache Hadoop
- Apache Kafka
- Parquet Apache
- Google Cloud BigQuery
- Google Cloud BigTable
- Archivio dati Google Cloud
- Google Cloud Pub/Sub
- Archiviazione Google Cloud (GCS)
- MongoDB
Controlla i documenti di Beam per l'elenco più recente.
Personalizzazione di exampleGen basata su query (sperimentale)
Innanzitutto, estendi BaseExampleGenExecutor con un Beam PTransform personalizzato, che legge dall'origine dati esterna. Quindi, crea un componente semplice estendendo QueryBasedExampleGen.
Ciò potrebbe richiedere o meno configurazioni di connessione aggiuntive. Ad esempio, l' esecutore BigQuery legge utilizzando un connettore beam.io predefinito, che estrae i dettagli di configurazione della connessione. L' esecutore Presto richiede un Beam PTransform personalizzato e un protobuf di configurazione della connessione personalizzato come input.
Se è richiesta una configurazione di connessione per un componente EsempioGen personalizzato, crea un nuovo protobuf e passalo tramite custom_config, che ora è un parametro di esecuzione facoltativo. Di seguito è riportato un esempio di come utilizzare un componente configurato.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Componenti downstream di exampleGen
La configurazione di suddivisione personalizzata è supportata per i componenti downstream.
StatisticaGen
Il comportamento predefinito consiste nell'eseguire la generazione delle statistiche per tutti i gruppi.
Per escludere eventuali suddivisioni, impostare exclude_splits per il componente StatisticsGen. Per esempio:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
Il comportamento predefinito consiste nel generare uno schema basato su tutte le suddivisioni.
Per escludere eventuali divisioni, impostare exclude_splits per il componente SchemaGen. Per esempio:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
EsempioValidator
Il comportamento predefinito consiste nel convalidare le statistiche di tutte le suddivisioni sugli esempi di input rispetto a uno schema.
Per escludere eventuali suddivisioni, impostare il exclude_splits per il componente EsempioValidator. Per esempio:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Trasformare
Il comportamento predefinito è analizzare e produrre i metadati dalla suddivisione "train" e trasformare tutte le suddivisioni.
Per specificare le suddivisioni di analisi e trasformazione, impostare splits_config per il componente Trasforma. Per esempio:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Formatore e sintonizzatore
Il comportamento predefinito è addestrare sulla suddivisione "train" e valutare sulla suddivisione "eval".
Per specificare le suddivisioni del treno e valutare le suddivisioni, impostare train_args e eval_args per il componente Trainer. Per esempio:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Valutatore
Il comportamento predefinito è fornire metriche calcolate sulla suddivisione "eval".
Per calcolare le statistiche di valutazione sulle suddivisioni personalizzate, impostare example_splits per il componente Evaluator. Per esempio:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Maggiori dettagli sono disponibili nel riferimento API CsvExampleGen , nell'implementazione API FileBasedExampleGen e nel riferimento API ImportExampleGen .