
Le composant SampleGen TFX Pipeline ingère des données dans les pipelines TFX. Il consomme des fichiers/services externes pour générer des exemples qui seront lus par d'autres composants TFX. Il fournit également une partition cohérente et configurable et mélange l'ensemble de données selon les meilleures pratiques de ML.
- Consomme : données provenant de sources de données externes telles que CSV,
TFRecord, Avro, Parquet et BigQuery. - Émet : enregistrements
tf.Example, enregistrementstf.SequenceExampleou format proto, selon le format de la charge utile.
ExempleGen et autres composants
SampleGen fournit des données aux composants qui utilisent la bibliothèque TensorFlow Data Validation , tels que SchemaGen , StatisticsGen et Sample Validator . Il fournit également des données à Transform , qui utilise la bibliothèque TensorFlow Transform , et finalement aux cibles de déploiement lors de l'inférence.
Sources et formats de données
Actuellement, une installation standard de TFX comprend des composants complets SampleGen pour ces sources et formats de données :
Des exécuteurs personnalisés sont également disponibles qui permettent le développement de composants SampleGen pour ces sources et formats de données :
Consultez les exemples d'utilisation dans le code source et cette discussion pour plus d'informations sur la façon d'utiliser et de développer des exécuteurs personnalisés.
De plus, ces sources et formats de données sont disponibles sous forme d'exemples de composants personnalisés :
Ingestion de formats de données pris en charge par Apache Beam
Apache Beam prend en charge l'ingestion de données provenant d'un large éventail de sources et de formats de données ( voir ci-dessous ). Ces fonctionnalités peuvent être utilisées pour créer des composants SampleGen personnalisés pour TFX, ce qui est démontré par certains composants SampleGen existants ( voir ci-dessous ).
Comment utiliser un composant SampleGen
Pour les sources de données prises en charge (actuellement, les fichiers CSV, les fichiers TFRecord avec tf.Example , tf.SequenceExample et le format proto, ainsi que les résultats des requêtes BigQuery), le composant de pipeline SampleGen peut être utilisé directement dans le déploiement et nécessite peu de personnalisation. Par exemple:
example_gen = CsvExampleGen(input_base='data_root')
ou comme ci-dessous pour importer directement un TFRecord externe avec tf.Example :
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Portée, version et fractionnement
Un Span est un regroupement d’exemples de formation. Si vos données sont conservées sur un système de fichiers, chaque Span peut être stockée dans un répertoire distinct. La sémantique d'un Span n'est pas codée en dur dans TFX ; un Span peut correspondre à une journée de données, une heure de données ou tout autre regroupement significatif pour votre tâche.
Chaque Span peut contenir plusieurs versions de données. Pour donner un exemple, si vous supprimez certains exemples d'un Span pour nettoyer des données de mauvaise qualité, cela pourrait entraîner une nouvelle version de ce Span. Par défaut, les composants TFX fonctionnent sur la dernière version au sein d'un Span.
Chaque version au sein d'un Span peut en outre être subdivisée en plusieurs fractionnements. Le cas d'utilisation le plus courant pour diviser un Span consiste à le diviser en données d'entraînement et d'évaluation.
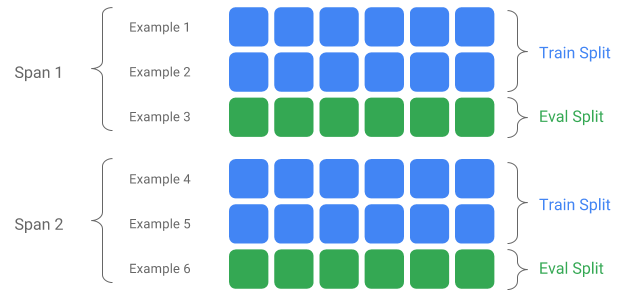
Répartition entrée/sortie personnalisée
Pour personnaliser le rapport de répartition train/évaluation que SampleGen affichera, définissez le output_config pour le composant SampleGen. Par exemple:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Remarquez comment les hash_buckets ont été définis dans cet exemple.
Pour une source d'entrée qui a déjà été divisée, définissez le input_config pour le composant SampleGen :
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Pour la génération d'exemples basés sur des fichiers (par exemple CsvExampleGen et ImportExampleGen), pattern est un modèle de fichier relatif global qui correspond aux fichiers d'entrée avec le répertoire racine donné par le chemin de base d'entrée. Pour la génération d'exemples basée sur des requêtes (par exemple BigQueryExampleGen, PrestoExampleGen), pattern est une requête SQL.
Par défaut, l'intégralité du répertoire de base d'entrée est traitée comme une seule répartition d'entrée, et la répartition de sortie d'entraînement et d'évaluation est générée avec un rapport de 2:1.
Veuillez vous référer à proto/example_gen.proto pour la configuration de répartition des entrées et sorties d'ExampleGen. Et reportez-vous au guide des composants en aval pour utiliser les répartitions personnalisées en aval.
Méthode de fractionnement
Lors de l'utilisation de la méthode de fractionnement hash_buckets , au lieu de l'enregistrement entier, on peut utiliser une fonctionnalité pour partitionner les exemples. Si une fonctionnalité est présente, SampleGen utilisera une empreinte digitale de cette fonctionnalité comme clé de partition.
Cette fonctionnalité peut être utilisée pour maintenir une répartition stable par rapport à certaines propriétés d'exemples : par exemple, un utilisateur sera toujours placé dans la même division si "user_id" a été sélectionné comme nom de fonctionnalité de partition.
L'interprétation de ce que signifie une « fonctionnalité » et de la manière de faire correspondre une « fonctionnalité » avec le nom spécifié dépend de l'implémentation de SampleGen et du type des exemples.
Pour les implémentations prêtes à l'emploi d'ExampleGen :
- S'il génère tf.Example, alors une "fonctionnalité" signifie une entrée dans tf.Example.features.feature.
- S'il génère tf.SequenceExample, alors une « fonctionnalité » signifie une entrée dans tf.SequenceExample.context.feature.
- Seules les fonctionnalités int64 et bytes sont prises en charge.
Dans les cas suivants, SampleGen génère des erreurs d'exécution :
- Le nom de fonctionnalité spécifié n'existe pas dans l'exemple.
- Fonctionnalité vide :
tf.train.Feature(). - Types de fonctionnalités non pris en charge, par exemple, fonctionnalités flottantes.
Pour générer la répartition train/évaluation en fonction d'une fonctionnalité dans les exemples, définissez le output_config pour le composant SampleGen. Par exemple:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Remarquez comment partition_feature_name a été défini dans cet exemple.
Portée
La durée peut être récupérée en utilisant la spécification '{SPAN}' dans le modèle global d'entrée :
- Cette spécification fait correspondre les chiffres et mappe les données dans les numéros SPAN pertinents. Par exemple, « data_{SPAN}-*.tfrecord » collectera des fichiers tels que « data_12-a.tfrecord », « data_12-b.tfrecord ».
- En option, cette spécification peut être spécifiée avec la largeur des entiers lors du mappage. Par exemple, « data_{SPAN:2}.file » correspond à des fichiers tels que « data_02.file » et « data_27.file » (en tant qu'entrées pour Span-2 et Span-27 respectivement), mais ne correspond pas à « data_1 ». fichier' ni 'data_123.file'.
- Lorsque la spécification SPAN est manquante, elle est supposée être toujours Span « 0 ».
- Si SPAN est spécifié, le pipeline traitera le dernier span et stockera le numéro de span dans les métadonnées.
Par exemple, supposons qu'il y ait des données d'entrée :
- '/tmp/span-1/train/données'
- '/tmp/span-1/eval/données'
- '/tmp/span-2/train/données'
- '/tmp/span-2/eval/données'
et la configuration d'entrée est affichée comme ci-dessous :
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
lors du déclenchement du pipeline, il traitera :
- '/tmp/span-2/train/data' en tant que fractionnement du train
- '/tmp/span-2/eval/data' comme fractionnement d'évaluation
avec le numéro de travée comme « 2 ». Si plus tard '/tmp/span-3/...' sont prêts, déclenchez simplement à nouveau le pipeline et il récupérera le span '3' pour le traitement. Ci-dessous montre l'exemple de code pour l'utilisation de la spécification span :
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
La récupération d'une certaine étendue peut être effectuée avec RangeConfig, qui est détaillé ci-dessous.
Date
Si votre source de données est organisée sur le système de fichiers par date, TFX prend en charge le mappage des dates directement sur les numéros d'étendue. Il existe trois spécifications pour représenter le mappage des dates aux périodes : {AAAA}, {MM} et {JJ} :
- Les trois spécifications doivent être totalement présentes dans le modèle global d'entrée, le cas échéant :
- Soit la spécification {SPAN}, soit cet ensemble de spécifications de date peuvent être spécifiés exclusivement.
- Une date du calendrier avec l'année à partir de AAAA, le mois à partir de MM et le jour du mois à partir de DD est calculée, puis le numéro d'intervalle est calculé comme le nombre de jours depuis l'époque Unix (c'est-à-dire 1970-01-01). Par exemple, 'log-{YYYY}{MM}{DD}.data' correspond à un fichier 'log-19700101.data' et le consomme comme entrée pour Span-0, et 'log-20170101.data' comme entrée pour Portée-17167.
- Si cet ensemble de spécifications de date est spécifié, le pipeline traitera la dernière date la plus récente et stockera le numéro de période correspondant dans les métadonnées.
Par exemple, supposons qu'il existe des données d'entrée organisées par date du calendrier :
- '/tmp/1970-01-02/train/données'
- '/tmp/1970-01-02/eval/données'
- '/tmp/1970-01-03/train/données'
- '/tmp/1970-01-03/eval/données'
et la configuration d'entrée est affichée comme ci-dessous :
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
lors du déclenchement du pipeline, il traitera :
- '/tmp/1970-01-03/train/data' lors de la division du train
- '/tmp/1970-01-03/eval/data' comme division d'évaluation
avec le numéro de travée comme « 2 ». Si plus tard '/tmp/1970-01-04/...' sont prêts, déclenchez simplement à nouveau le pipeline et il récupérera le span '3' pour le traitement. Ci-dessous montre l'exemple de code pour utiliser la spécification de date :
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Version
La version peut être récupérée en utilisant la spécification '{VERSION}' dans le modèle global d'entrée :
- Cette spécification fait correspondre les chiffres et mappe les données aux numéros de VERSION pertinents sous le SPAN. Notez que la spécification Version peut être utilisée en combinaison avec la spécification Span ou Date.
- Cette spécification peut également être éventuellement spécifiée avec la largeur de la même manière que la spécification SPAN. par exemple 'span-{SPAN}/version-{VERSION:4}/data-*'.
- Lorsque la spécification VERSION est manquante, la version est définie sur Aucune.
- Si SPAN et VERSION sont tous deux spécifiés, le pipeline traitera la dernière version pour la dernière étendue et stockera le numéro de version dans les métadonnées.
- Si VERSION est spécifié, mais pas SPAN (ou spécification de date), une erreur sera générée.
Par exemple, supposons qu'il y ait des données d'entrée :
- '/tmp/span-1/ver-1/train/données'
- '/tmp/span-1/ver-1/eval/données'
- '/tmp/span-2/ver-1/train/données'
- '/tmp/span-2/ver-1/eval/données'
- '/tmp/span-2/ver-2/train/données'
- '/tmp/span-2/ver-2/eval/données'
et la configuration d'entrée est affichée comme ci-dessous :
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
lors du déclenchement du pipeline, il traitera :
- '/tmp/span-2/ver-2/train/data' en tant que fractionnement du train
- '/tmp/span-2/ver-2/eval/data' comme fractionnement d'évaluation
avec le numéro de span comme « 2 » et le numéro de version comme « 2 ». Si plus tard '/tmp/span-2/ver-3/...' sont prêts, déclenchez simplement à nouveau le pipeline et il récupérera le span '2' et la version '3' pour le traitement. Ci-dessous montre l'exemple de code pour utiliser la spécification de version :
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Configuration de la plage
TFX prend en charge la récupération et le traitement d'une étendue spécifique dans SampleGen basé sur des fichiers à l'aide de la configuration de plage, une configuration abstraite utilisée pour décrire les plages de différentes entités TFX. Pour récupérer une étendue spécifique, définissez range_config pour un composant SampleGen basé sur un fichier. Par exemple, supposons qu'il y ait des données d'entrée :
- '/tmp/span-01/train/données'
- '/tmp/span-01/eval/données'
- '/tmp/span-02/train/données'
- '/tmp/span-02/eval/données'
Pour récupérer et traiter spécifiquement les données avec l'étendue « 1 », nous spécifions une configuration de plage en plus de la configuration d'entrée. Notez que SampleGen ne prend en charge que les plages statiques à une seule travée (pour spécifier le traitement de travées individuelles spécifiques). Ainsi, pour StaticRange, start_span_number doit être égal à end_span_number. En utilisant l'étendue fournie et les informations de largeur d'étendue (si fournies) pour le remplissage de zéros, SampleGen remplacera la spécification SPAN dans les modèles de division fournis par le numéro d'étendue souhaité. Un exemple d'utilisation est présenté ci-dessous :
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
La configuration de plage peut également être utilisée pour traiter des dates spécifiques, si la spécification de date est utilisée à la place de la spécification SPAN. Par exemple, supposons qu'il existe des données d'entrée organisées par date du calendrier :
- '/tmp/1970-01-02/train/données'
- '/tmp/1970-01-02/eval/données'
- '/tmp/1970-01-03/train/données'
- '/tmp/1970-01-03/eval/données'
Pour récupérer et traiter spécifiquement les données du 2 janvier 1970, nous procédons comme suit :
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Exemple personnaliséGen
Si les composants ExempleGen actuellement disponibles ne répondent pas à vos besoins, vous pouvez créer un ExempleGen personnalisé, qui vous permettra de lire à partir de différentes sources de données ou dans différents formats de données.
Personnalisation d'exemples basés sur des fichiers (expérimental)
Tout d’abord, étendez BaseExampleGenExecutor avec un Beam PTransform personnalisé, qui fournit la conversion de votre répartition d’entrée train/eval en exemples TF. Par exemple, l' exécuteur CsvExampleGen fournit la conversion d'un fractionnement CSV d'entrée en exemples TF.
Ensuite, créez un composant avec l'exécuteur ci-dessus, comme cela est fait dans le composant CsvExampleGen . Vous pouvez également transmettre un exécuteur personnalisé dans le composant standard SampleGen comme indiqué ci-dessous.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Désormais, nous prenons également en charge la lecture des fichiers Avro et Parquet en utilisant cette méthode .
Formats de données supplémentaires
Apache Beam prend en charge la lecture d'un certain nombre de formats de données supplémentaires . via les transformations d'E/S de faisceau. Vous pouvez créer des composants SampleGen personnalisés en tirant parti des transformations Beam I/O en utilisant un modèle similaire à l' exemple Avro.
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
Au moment d'écrire ces lignes, les formats et sources de données actuellement pris en charge pour le SDK Beam Python incluent :
- Amazone S3
- Apache Avro
- Apache Hadoop
- Apache Kafka
- Parquet Apache
- Google Cloud BigQuery
- Google Cloud BigTable
- Banque de données Google Cloud
- Google Cloud Pub/Sub
- Stockage Google Cloud (GCS)
- MongoDB
Consultez la documentation Beam pour la dernière liste.
Personnalisation d'ExampleGen basée sur des requêtes (expérimentale)
Tout d’abord, étendez BaseExampleGenExecutor avec un Beam PTransform personnalisé, qui lit à partir de la source de données externe. Créez ensuite un composant simple en étendant QueryBasedExampleGen.
Cela peut nécessiter ou non des configurations de connexion supplémentaires. Par exemple, l' exécuteur BigQuery lit à l'aide d'un connecteur Beam.io par défaut, qui résume les détails de configuration de la connexion. L' exécuteur Presto nécessite un Beam PTransform personnalisé et un protobuf de configuration de connexion personnalisé en entrée.
Si une configuration de connexion est requise pour un composant SampleGen personnalisé, créez un nouveau protobuf et transmettez-le via custom_config, qui est désormais un paramètre d'exécution facultatif. Vous trouverez ci-dessous un exemple d'utilisation d'un composant configuré.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Composants en aval d'ExampleGen
La configuration fractionnée personnalisée est prise en charge pour les composants en aval.
StatistiquesGen
Le comportement par défaut consiste à générer des statistiques pour toutes les divisions.
Pour exclure des fractionnements, définissez le composant exclude_splits pour StatisticsGen. Par exemple:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchémaGen
Le comportement par défaut consiste à générer un schéma basé sur toutes les divisions.
Pour exclure des fractionnements, définissez le composant exclude_splits pour SchemaGen. Par exemple:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ExempleValidator
Le comportement par défaut consiste à valider les statistiques de toutes les divisions sur les exemples d'entrée par rapport à un schéma.
Pour exclure des fractionnements, définissez le composant exclude_splits pour SampleValidator. Par exemple:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Transformer
Le comportement par défaut est d'analyser et de produire les métadonnées de la division « entraîner » et de transformer toutes les divisions.
Pour spécifier les fractionnements d'analyse et de transformation, définissez splits_config pour le composant Transform. Par exemple:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Entraîneur et accordeur
Le comportement par défaut est de former sur la division « train » et d'évaluer sur la division « eval ».
Pour spécifier les fractionnements de train et évaluer les fractionnements, définissez les train_args et eval_args pour le composant Trainer. Par exemple:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Évaluateur
Le comportement par défaut consiste à fournir des métriques calculées sur la répartition « eval ».
Pour calculer les statistiques d'évaluation sur des répartitions personnalisées, définissez le composant example_splits pour Evaluator. Par exemple:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Plus de détails sont disponibles dans la référence de l'API CsvExampleGen , l'implémentation de l'API FileBasedExampleGen et la référence de l'API ImportExampleGen .