
Thành phần Đường ống SampleGen TFX nhập dữ liệu vào đường ống TFX. Nó sử dụng các tệp/dịch vụ bên ngoài để tạo các Ví dụ sẽ được các thành phần TFX khác đọc. Nó cũng cung cấp phân vùng nhất quán và có thể định cấu hình, đồng thời xáo trộn tập dữ liệu để có phương pháp thực hành tốt nhất về ML.
- Tiêu thụ: Dữ liệu từ các nguồn dữ liệu bên ngoài như CSV,
TFRecord, Avro, Parquet và BigQuery. - Phát ra: bản ghi
tf.Example, bản ghitf.SequenceExamplehoặc định dạng proto, tùy thuộc vào định dạng tải trọng.
Ví dụGen và các thành phần khác
Ví dụGen cung cấp dữ liệu cho các thành phần sử dụng thư viện Xác thực dữ liệu TensorFlow , chẳng hạn như SchemaGen , StatsGen và Ví dụ Trình xác thực . Nó cũng cung cấp dữ liệu cho Transform , sử dụng thư viện TensorFlow Transform và cuối cùng là các mục tiêu triển khai trong quá trình suy luận.
Nguồn dữ liệu và định dạng
Hiện tại, bản cài đặt tiêu chuẩn của TFX bao gồm các thành phần hoàn chỉnh của exampleGen cho các nguồn và định dạng dữ liệu sau:
Các trình thực thi tùy chỉnh cũng có sẵn cho phép phát triển các thành phần exampleGen cho các nguồn và định dạng dữ liệu này:
Xem các ví dụ sử dụng trong mã nguồn và cuộc thảo luận này để biết thêm thông tin về cách sử dụng và phát triển các trình thực thi tùy chỉnh.
Ngoài ra, các nguồn dữ liệu và định dạng này có sẵn dưới dạng ví dụ về thành phần tùy chỉnh :
Nhập các định dạng dữ liệu được Apache Beam hỗ trợ
Apache Beam hỗ trợ nhập dữ liệu từ nhiều nguồn và định dạng dữ liệu khác nhau ( xem bên dưới ). Những khả năng này có thể được sử dụng để tạo các thành phần Ví dụ tùy chỉnh cho TFX, được thể hiện bằng một số thành phần Ví dụ hiện có ( xem bên dưới ).
Cách sử dụng Thành phần exampleGen
Đối với các nguồn dữ liệu được hỗ trợ (hiện tại là tệp CSV, tệp TFRecord có định dạng tf.Example , tf.SequenceExample và proto cũng như kết quả của các truy vấn BigQuery), thành phần quy trình SampleGen có thể được sử dụng trực tiếp trong quá trình triển khai và yêu cầu ít tùy chỉnh. Ví dụ:
example_gen = CsvExampleGen(input_base='data_root')
hoặc như bên dưới để nhập trực tiếp TFRecord bên ngoài bằng tf.Example :
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Khoảng cách, phiên bản và phân chia
Span là một nhóm các ví dụ huấn luyện. Nếu dữ liệu của bạn được lưu trên hệ thống tệp, mỗi Span có thể được lưu trữ trong một thư mục riêng. Ngữ nghĩa của Span không được mã hóa cứng thành TFX; một Khoảng thời gian có thể tương ứng với một ngày dữ liệu, một giờ dữ liệu hoặc bất kỳ nhóm nào khác có ý nghĩa đối với nhiệm vụ của bạn.
Mỗi Span có thể chứa nhiều Phiên bản dữ liệu. Để đưa ra một ví dụ, nếu bạn xóa một số ví dụ khỏi Span để xóa dữ liệu chất lượng kém, điều này có thể dẫn đến Phiên bản mới của Span đó. Theo mặc định, các thành phần TFX hoạt động trên Phiên bản mới nhất trong Span.
Mỗi Phiên bản trong một Khoảng có thể được chia nhỏ thành nhiều Phần tách. Trường hợp sử dụng phổ biến nhất để tách Span là chia nó thành dữ liệu huấn luyện và đánh giá.
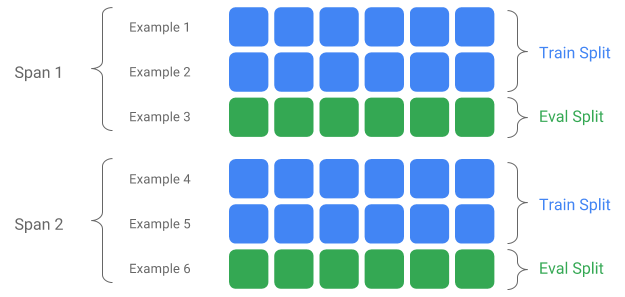
Phân chia đầu vào/đầu ra tùy chỉnh
Để tùy chỉnh tỷ lệ phân chia huấn luyện/eval mà exampleGen sẽ xuất ra, hãy đặt output_config cho thành phần exampleGen. Ví dụ:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Hãy chú ý cách đặt hash_buckets trong ví dụ này.
Đối với nguồn đầu vào đã được phân tách, hãy đặt input_config cho thành phần exampleGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Đối với gen ví dụ dựa trên tệp (ví dụ: CsvExampleGen và ImportExampleGen), pattern là mẫu tệp tương đối toàn cầu ánh xạ tới các tệp đầu vào có thư mục gốc được cung cấp bởi đường dẫn cơ sở đầu vào. Đối với gen ví dụ dựa trên truy vấn (ví dụ: BigQueryExampleGen, PrestoExampleGen), pattern là truy vấn SQL.
Theo mặc định, toàn bộ thư mục cơ sở đầu vào được coi là một phần tách đầu vào duy nhất và phần tách đầu ra của tàu và eval được tạo ra với tỷ lệ 2:1.
Vui lòng tham khảo proto/example_gen.proto để biết cấu hình phân chia đầu vào và đầu ra của exampleGen. Và tham khảo hướng dẫn về các thành phần xuôi dòng để sử dụng các phần phân chia tùy chỉnh ở xuôi dòng.
Phương pháp tách
Khi sử dụng phương pháp chia hash_buckets , thay vì toàn bộ bản ghi, người ta có thể sử dụng tính năng phân vùng các ví dụ. Nếu có một tính năng, exampleGen sẽ sử dụng dấu vân tay của tính năng đó làm khóa phân vùng.
Tính năng này có thể được sử dụng để duy trì sự phân chia ổn định với một số thuộc tính nhất định của ví dụ: ví dụ: một người dùng sẽ luôn được đặt trong cùng một phần phân chia nếu "user_id" được chọn làm tên tính năng phân vùng.
Việc giải thích ý nghĩa của "tính năng" và cách khớp "tính năng" với tên được chỉ định tùy thuộc vào cách triển khai exampleGen và loại ví dụ.
Đối với việc triển khai exampleGen được tạo sẵn:
- Nếu nó tạo ra tf.Example thì "tính năng" có nghĩa là một mục trong tf.Example.features.feature.
- Nếu nó tạo ra tf.SequenceExample thì "feature" nghĩa là một mục trong tf.SequenceExample.context.feature.
- Chỉ hỗ trợ các tính năng int64 và byte.
Trong các trường hợp sau, exampleGen đưa ra lỗi thời gian chạy:
- Tên tính năng được chỉ định không tồn tại trong ví dụ.
- Tính năng trống:
tf.train.Feature(). - Các loại tính năng không được hỗ trợ, ví dụ: tính năng float.
Để xuất ra sự phân tách đào tạo/eval dựa trên một tính năng trong các ví dụ, hãy đặt output_config cho thành phần exampleGen. Ví dụ:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Lưu ý cách partition_feature_name được đặt trong ví dụ này.
Khoảng cách
Có thể truy xuất khoảng cách bằng cách sử dụng thông số '{SPAN}' trong mẫu hình cầu đầu vào :
- Thông số kỹ thuật này khớp với các chữ số và ánh xạ dữ liệu vào các số SPAN có liên quan. Ví dụ: 'data_{SPAN}-*.tfrecord' sẽ thu thập các tệp như 'data_12-a.tfrecord', 'data_12-b.tfrecord'.
- Tùy chọn, thông số kỹ thuật này có thể được chỉ định bằng chiều rộng của số nguyên khi được ánh xạ. Ví dụ: 'data_{SPAN:2}.file' ánh xạ tới các tệp như 'data_02.file' và 'data_27.file' (dưới dạng đầu vào cho Span-2 và Span-27 tương ứng), nhưng không ánh xạ tới 'data_1. tập tin' hay 'data_123.file'.
- Khi thiếu thông số SPAN, nó luôn được coi là Span '0'.
- Nếu SPAN được chỉ định, đường dẫn sẽ xử lý khoảng thời gian mới nhất và lưu trữ số khoảng thời gian trong siêu dữ liệu.
Ví dụ: giả sử có dữ liệu đầu vào:
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
và cấu hình đầu vào được hiển thị như dưới đây:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
khi kích hoạt đường ống, nó sẽ xử lý:
- '/tmp/span-2/train/data' khi phân chia đoàn tàu
- '/tmp/span-2/eval/data' dưới dạng phân chia eval
với số nhịp là '2'. Nếu sau này '/tmp/span-3/...' đã sẵn sàng, bạn chỉ cần kích hoạt lại đường dẫn và nó sẽ chọn span '3' để xử lý. Dưới đây hiển thị ví dụ mã để sử dụng thông số span:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Việc truy xuất một khoảng nhất định có thể được thực hiện bằng RangeConfig, được trình bày chi tiết bên dưới.
Ngày
Nếu nguồn dữ liệu của bạn được sắp xếp trên hệ thống tệp theo ngày, TFX hỗ trợ ánh xạ ngày trực tiếp theo số khoảng. Có ba thông số kỹ thuật để thể hiện ánh xạ từ ngày đến các khoảng: {YYYY}, {MM} và {DD}:
- Ba thông số kỹ thuật phải có mặt hoàn toàn trong mẫu hình cầu đầu vào nếu có bất kỳ thông số nào được chỉ định:
- Thông số {SPAN} hoặc bộ thông số ngày này có thể được chỉ định riêng.
- Ngày theo lịch có năm từ YYYY, tháng từ MM và ngày trong tháng từ DD được tính, sau đó số khoảng được tính bằng số ngày kể từ kỷ nguyên unix (tức là 1970-01-01). Ví dụ: 'log-{YYYY}{MM}{DD}.data' khớp với tệp 'log-19700101.data' và sử dụng nó làm đầu vào cho Span-0 và 'log-20170101.data' làm đầu vào cho Span-17167.
- Nếu tập hợp thông số ngày này được chỉ định, quy trình sẽ xử lý ngày mới nhất mới nhất và lưu trữ số khoảng tương ứng trong siêu dữ liệu.
Ví dụ: giả sử có dữ liệu đầu vào được sắp xếp theo ngày dương lịch:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
và cấu hình đầu vào được hiển thị như dưới đây:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
khi kích hoạt đường ống, nó sẽ xử lý:
- '/tmp/1970-01-03/train/data' khi phân chia đoàn tàu
- '/tmp/1970-01-03/eval/data' dưới dạng phân chia eval
với số nhịp là '2'. Nếu sau này '/tmp/1970-01-04/...' đã sẵn sàng, bạn chỉ cần kích hoạt lại đường dẫn và nó sẽ chọn khoảng '3' để xử lý. Dưới đây hiển thị ví dụ mã để sử dụng thông số ngày:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Phiên bản
Có thể truy xuất phiên bản bằng cách sử dụng thông số '{VERSION}' trong mẫu toàn cầu đầu vào :
- Thông số kỹ thuật này khớp với các chữ số và ánh xạ dữ liệu tới các số PHIÊN BẢN có liên quan trong SPAN. Lưu ý rằng thông số Phiên bản có thể được sử dụng kết hợp với thông số Span hoặc Date.
- Thông số kỹ thuật này cũng có thể được chỉ định tùy ý với chiều rộng giống như thông số SPAN. ví dụ: 'span-{SPAN}/version-{VERSION:4}/data-*'.
- Khi thiếu thông số VERSION, phiên bản được đặt thành Không có.
- Nếu cả SPAN và VERSION đều được chỉ định, quy trình sẽ xử lý phiên bản mới nhất cho khoảng thời gian mới nhất và lưu trữ số phiên bản trong siêu dữ liệu.
- Nếu VERSION được chỉ định, nhưng không phải SPAN (hoặc thông số ngày), sẽ xảy ra lỗi.
Ví dụ: giả sử có dữ liệu đầu vào:
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
và cấu hình đầu vào được hiển thị như dưới đây:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
khi kích hoạt đường ống, nó sẽ xử lý:
- '/tmp/span-2/ver-2/train/data' khi phân chia đoàn tàu
- '/tmp/span-2/ver-2/eval/data' dưới dạng phân chia eval
với số nhịp là '2' và số phiên bản là '2'. Nếu sau này '/tmp/span-2/ver-3/...' đã sẵn sàng, bạn chỉ cần kích hoạt lại đường dẫn và nó sẽ chọn span '2' và phiên bản '3' để xử lý. Dưới đây hiển thị ví dụ mã để sử dụng thông số phiên bản:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Cấu hình phạm vi
TFX hỗ trợ truy xuất và xử lý một khoảng cụ thể trong exampleGen dựa trên tệp bằng cách sử dụng cấu hình phạm vi, một cấu hình trừu tượng được sử dụng để mô tả các phạm vi cho các thực thể TFX khác nhau. Để truy xuất một khoảng cụ thể, hãy đặt range_config cho thành phần exampleGen dựa trên tệp. Ví dụ: giả sử có dữ liệu đầu vào:
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
Để truy xuất và xử lý dữ liệu cụ thể có khoảng '1', chúng tôi chỉ định cấu hình phạm vi ngoài cấu hình đầu vào. Lưu ý rằng exampleGen chỉ hỗ trợ các phạm vi tĩnh một nhịp (để chỉ định việc xử lý các phạm vi riêng lẻ cụ thể). Do đó, đối với StaticRange, start_span_number phải bằng end_span_number. Sử dụng khoảng được cung cấp và thông tin về độ rộng khoảng (nếu được cung cấp) cho khoảng đệm bằng 0, exampleGen sẽ thay thế thông số SPAN trong các mẫu phân tách được cung cấp bằng số khoảng mong muốn. Một ví dụ về cách sử dụng được hiển thị dưới đây:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Cấu hình phạm vi cũng có thể được sử dụng để xử lý các ngày cụ thể, nếu thông số ngày được sử dụng thay vì thông số SPAN. Ví dụ: giả sử có dữ liệu đầu vào được sắp xếp theo ngày dương lịch:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
Để truy xuất và xử lý cụ thể dữ liệu ngày 2/1/1970, chúng ta thực hiện như sau:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Ví dụ tùy chỉnhGen
Nếu các thành phần SampleGen hiện có không phù hợp với nhu cầu của bạn, bạn có thể tạo một exampleGen tùy chỉnh, cho phép bạn đọc từ các nguồn dữ liệu khác nhau hoặc ở các định dạng dữ liệu khác nhau.
Tùy chỉnh Ví dụ dựa trên tệp (Thử nghiệm)
Trước tiên, hãy mở rộng BaseExampleGenExecutor bằng Beam PTransform tùy chỉnh, cung cấp khả năng chuyển đổi từ phân tách đầu vào huấn luyện/eval của bạn sang các ví dụ TF. Ví dụ: trình thực thi CsvExampleGen cung cấp chuyển đổi từ phần tách CSV đầu vào sang ví dụ TF.
Sau đó, tạo một thành phần với trình thực thi ở trên, như được thực hiện trong thành phần CsvExampleGen . Ngoài ra, hãy chuyển một trình thực thi tùy chỉnh vào thành phần exampleGen tiêu chuẩn như hiển thị bên dưới.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Giờ đây, chúng tôi cũng hỗ trợ đọc các tệp Avro và Parquet bằng phương pháp này.
Định dạng dữ liệu bổ sung
Apache Beam hỗ trợ đọc một số định dạng dữ liệu bổ sung . thông qua Chuyển đổi I/O của Beam. Bạn có thể tạo các thành phần SampleGen tùy chỉnh bằng cách tận dụng Chuyển đổi I/O Beam bằng cách sử dụng mẫu tương tự như ví dụ Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
Tính đến thời điểm viết bài này, các định dạng và nguồn dữ liệu hiện được hỗ trợ cho Beam Python SDK bao gồm:
- Amazon S3
- Apache Avro
- Apache Hadoop
- Apache Kafka
- Sàn gỗ Apache
- Google Cloud BigQuery
- Bảng lớn trên đám mây của Google
- Kho dữ liệu đám mây của Google
- Google Cloud Pub/Sub
- Bộ nhớ đám mây của Google (GCS)
- MongoDB
Kiểm tra tài liệu Beam để biết danh sách mới nhất.
Tùy chỉnh Ví dụ dựa trên truy vấn (Thử nghiệm)
Đầu tiên, mở rộng BaseExampleGenExecutor bằng Beam PTransform tùy chỉnh, đọc từ nguồn dữ liệu bên ngoài. Sau đó, tạo một thành phần đơn giản bằng cách mở rộng QueryBasedExampleGen.
Điều này có thể hoặc không yêu cầu cấu hình kết nối bổ sung. Ví dụ: trình thực thi BigQuery đọc bằng trình kết nối Beam.io mặc định, trình kết nối này tóm tắt chi tiết cấu hình kết nối. Trình thực thi Presto yêu cầu Beam PTransform tùy chỉnh và protobuf cấu hình kết nối tùy chỉnh làm đầu vào.
Nếu cần có cấu hình kết nối cho thành phần exampleGen tùy chỉnh, hãy tạo một protobuf mới và chuyển nó qua custom_config, hiện là tham số thực thi tùy chọn. Dưới đây là một ví dụ về cách sử dụng một thành phần được cấu hình.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Các thành phần hạ nguồn của Ví dụGen
Cấu hình phân chia tùy chỉnh được hỗ trợ cho các thành phần hạ nguồn.
Thống kêGen
Hành vi mặc định là thực hiện tạo số liệu thống kê cho tất cả các phần tách.
Để loại trừ bất kỳ phần tách nào, hãy đặt exclude_splits cho thành phần StatsGen. Ví dụ:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
Hành vi mặc định là tạo lược đồ dựa trên tất cả các phần tách.
Để loại trừ bất kỳ phần phân tách nào, hãy đặt exclude_splits cho thành phần SchemaGen. Ví dụ:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
Trình xác thực ví dụ
Hành vi mặc định là xác thực số liệu thống kê của tất cả các phần tách trên các mẫu đầu vào dựa trên một lược đồ.
Để loại trừ bất kỳ phần tách nào, hãy đặt exclude_splits cho thành phần Ví dụValidator. Ví dụ:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
chuyển đổi
Hành vi mặc định là phân tích và tạo siêu dữ liệu từ phần tách 'đào tạo' và chuyển đổi tất cả các phần tách.
Để chỉ định phần tách phân tích và phần tách biến đổi, hãy đặt splits_config cho thành phần Transform. Ví dụ:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Huấn luyện viên và người điều chỉnh
Hành vi mặc định là huấn luyện trên phần tách 'train' và đánh giá trên phần tách 'eval'.
Để chỉ định các phần tách tàu và đánh giá các phần tách, hãy đặt train_args và eval_args cho thành phần Trainer. Ví dụ:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Người đánh giá
Hành vi mặc định là cung cấp số liệu được tính toán trên phần tách 'eval'.
Để tính toán số liệu thống kê đánh giá về các phần tách tùy chỉnh, hãy đặt example_splits cho thành phần Người đánh giá. Ví dụ:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Thông tin chi tiết hơn có sẵn trong tài liệu tham khảo API CsvExampleGen , triển khai API FileBasedExampleGen và tài liệu tham khảo API ImportExampleGen .