
O componente ExampleGen TFX Pipeline ingere dados em pipelines TFX. Ele consome arquivos/serviços externos para gerar exemplos que serão lidos por outros componentes do TFX. Ele também fornece partição consistente e configurável e embaralha o conjunto de dados para práticas recomendadas de ML.
- Consome: Dados de fontes de dados externas como CSV,
TFRecord, Avro, Parquet e BigQuery. - Emite: registros
tf.Example, registrostf.SequenceExampleou formato proto, dependendo do formato da carga útil.
ExemploGen e outros componentes
ExampleGen fornece dados para componentes que fazem uso da biblioteca TensorFlow Data Validation , como SchemaGen , StatisticsGen e Example Validator . Ele também fornece dados para Transform , que faz uso da biblioteca TensorFlow Transform e, em última análise, para destinos de implantação durante a inferência.
Fontes e formatos de dados
Atualmente, uma instalação padrão do TFX inclui componentes completos do ExampleGen para estas fontes e formatos de dados:
Também estão disponíveis executores personalizados que permitem o desenvolvimento de componentes ExampleGen para estas fontes e formatos de dados:
Consulte os exemplos de uso no código-fonte e esta discussão para obter mais informações sobre como usar e desenvolver executores customizados.
Além disso, estas fontes e formatos de dados estão disponíveis como exemplos de componentes personalizados :
Ingestão de formatos de dados suportados pelo Apache Beam
O Apache Beam oferece suporte à ingestão de dados de uma ampla variedade de fontes e formatos de dados ( veja abaixo ). Esses recursos podem ser usados para criar componentes SampleGen personalizados para TFX, o que é demonstrado por alguns componentes ExampleGen existentes ( veja abaixo ).
Como usar um componente ExemploGen
Para fontes de dados compatíveis (atualmente, arquivos CSV, arquivos TFRecord com tf.Example , tf.SequenceExample e formato proto e resultados de consultas do BigQuery), o componente de pipeline ExampleGen pode ser usado diretamente na implantação e requer pouca personalização. Por exemplo:
example_gen = CsvExampleGen(input_base='data_root')
ou como abaixo para importar TFRecord externo diretamente com tf.Example :
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Extensão, versão e divisão
Um Span é um agrupamento de exemplos de treinamento. Se seus dados persistirem em um sistema de arquivos, cada Span poderá ser armazenado em um diretório separado. A semântica de um Span não é codificada no TFX; um Span pode corresponder a um dia de dados, uma hora de dados ou qualquer outro agrupamento que seja significativo para sua tarefa.
Cada Span pode conter várias versões de dados. Para dar um exemplo, se você remover alguns exemplos de um Span para limpar dados de baixa qualidade, isso poderá resultar em uma nova versão desse Span. Por padrão, os componentes do TFX operam na versão mais recente dentro de um Span.
Cada Versão dentro de um Span pode ainda ser subdividida em múltiplas Divisões. O caso de uso mais comum para dividir um Span é dividi-lo em dados de treinamento e avaliação.
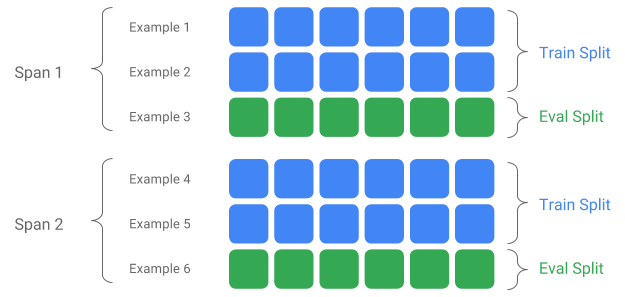
Divisão personalizada de entrada/saída
Para personalizar a proporção de divisão de treinamento/avaliação que o ExampleGen produzirá, defina o output_config para o componente ExampleGen. Por exemplo:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Observe como os hash_buckets foram definidos neste exemplo.
Para uma fonte de entrada que já foi dividida, defina input_config para o componente ExampleGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Para geração de exemplo baseada em arquivo (por exemplo, CsvExampleGen e ImportExampleGen), pattern é um padrão de arquivo relativo glob que mapeia para arquivos de entrada com diretório raiz fornecido pelo caminho base de entrada. Para geração de exemplo baseada em consulta (por exemplo, BigQueryExampleGen, PrestoExampleGen), pattern é uma consulta SQL.
Por padrão, todo o diretório base de entrada é tratado como uma única divisão de entrada, e a divisão de saída train e eval é gerada com uma proporção de 2:1.
Consulte proto/example_gen.proto para obter a configuração de divisão de entrada e saída do ExampleGen. E consulte o guia de componentes downstream para utilizar as divisões personalizadas downstream.
Método de divisão
Ao usar o método de divisão hash_buckets , em vez do registro inteiro, pode-se usar um recurso para particionar os exemplos. Se um recurso estiver presente, o ExampleGen usará uma impressão digital desse recurso como chave de partição.
Este recurso pode ser usado para manter uma divisão estável com certas propriedades de exemplos: por exemplo, um usuário sempre será colocado na mesma divisão se "user_id" for selecionado como o nome do recurso de partição.
A interpretação do que significa um "recurso" e como corresponder um "recurso" ao nome especificado depende da implementação do ExampleGen e do tipo dos exemplos.
Para implementações de ExampleGen prontas:
- Se gerar tf.Example, então um "recurso" significa uma entrada em tf.Example.features.feature.
- Se gerar tf.SequenceExample, então um "recurso" significa uma entrada em tf.SequenceExample.context.feature.
- Somente recursos int64 e bytes são suportados.
Nos seguintes casos, ExampleGen gera erros de tempo de execução:
- O nome do recurso especificado não existe no exemplo.
- Recurso vazio:
tf.train.Feature(). - Tipos de recursos não suportados, por exemplo, recursos flutuantes.
Para gerar a divisão train/eval com base em um recurso nos exemplos, defina o output_config para o componente ExampleGen. Por exemplo:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Observe como o partition_feature_name foi definido neste exemplo.
Período
O span pode ser recuperado usando a especificação '{SPAN}' no padrão glob de entrada :
- Esta especificação combina dígitos e mapeia os dados nos números SPAN relevantes. Por exemplo, 'data_{SPAN}-*.tfrecord' irá coletar arquivos como 'data_12-a.tfrecord', 'data_12-b.tfrecord'.
- Opcionalmente, esta especificação pode ser especificada com a largura dos inteiros quando mapeada. Por exemplo, 'data_{SPAN:2}.file' mapeia para arquivos como 'data_02.file' e 'data_27.file' (como entradas para Span-2 e Span-27 respectivamente), mas não mapeia para 'data_1. arquivo' nem 'data_123.file'.
- Quando a especificação SPAN está faltando, presume-se que seja sempre Span '0'.
- Se SPAN for especificado, o pipeline processará o intervalo mais recente e armazenará o número do intervalo nos metadados.
Por exemplo, vamos supor que existam dados de entrada:
- '/tmp/span-1/train/dados'
- '/tmp/span-1/eval/dados'
- '/tmp/span-2/train/dados'
- '/tmp/span-2/eval/dados'
e a configuração de entrada é mostrada abaixo:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
ao acionar o pipeline, ele processará:
- '/tmp/span-2/train/data' como divisão do trem
- '/tmp/span-2/eval/data' como divisão de avaliação
com número de intervalo como '2'. Se mais tarde '/tmp/span-3/...' estiver pronto, basta acionar o pipeline novamente e ele pegará o intervalo '3' para processamento. Abaixo mostra o exemplo de código para usar a especificação span:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
A recuperação de um determinado intervalo pode ser feita com RangeConfig, detalhado a seguir.
Data
Se sua fonte de dados estiver organizada no sistema de arquivos por data, o TFX oferece suporte ao mapeamento de datas diretamente para abranger números. Existem três especificações para representar o mapeamento de datas para períodos: {AAAA}, {MM} e {DD}:
- As três especificações devem estar presentes no padrão glob de entrada, se algum for especificado:
- A especificação {SPAN} ou este conjunto de especificações de data podem ser especificados exclusivamente.
- Uma data de calendário com o ano a partir de AAAA, o mês a partir de MM e o dia do mês a partir de DD é calculada, então o número do intervalo é calculado como o número de dias desde a época unix (ou seja, 1970-01-01). Por exemplo, 'log-{AAAA}{MM}{DD}.data' corresponde a um arquivo 'log-19700101.data' e o consome como entrada para Span-0, e 'log-20170101.data' como entrada para Span-17167.
- Se este conjunto de especificações de data for especificado, o pipeline processará a data mais recente e armazenará o número do período correspondente nos metadados.
Por exemplo, vamos supor que existam dados de entrada organizados por data do calendário:
- '/tmp/1970-01-02/trem/dados'
- '/tmp/1970-01-02/eval/dados'
- '/tmp/1970-01-03/trem/dados'
- '/tmp/1970-01-03/eval/dados'
e a configuração de entrada é mostrada abaixo:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
ao acionar o pipeline, ele processará:
- '/tmp/1970-01-03/train/data' como divisão do trem
- '/tmp/1970-01-03/eval/data' como divisão de avaliação
com número de intervalo como '2'. Se mais tarde '/tmp/1970-01-04/...' estiver pronto, basta acionar o pipeline novamente e ele pegará o intervalo '3' para processamento. Abaixo mostra o exemplo de código para usar a especificação de data:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Versão
A versão pode ser recuperada usando a especificação '{VERSION}' no padrão glob de entrada :
- Esta especificação combina dígitos e mapeia os dados para os números de VERSÃO relevantes no SPAN. Observe que a especificação Versão pode ser usada em combinação com a especificação Span ou Data.
- Esta especificação também pode ser opcionalmente especificada com a largura da mesma forma que a especificação SPAN. por exemplo, 'span-{SPAN}/versão-{VERSION:4}/data-*'.
- Quando a especificação VERSION está faltando, a versão é definida como None.
- Se SPAN e VERSION forem especificados, o pipeline processará a versão mais recente para o intervalo mais recente e armazenará o número da versão nos metadados.
- Se VERSION for especificado, mas não SPAN (ou especificação de data), um erro será gerado.
Por exemplo, vamos supor que existam dados de entrada:
- '/tmp/span-1/ver-1/train/dados'
- '/tmp/span-1/ver-1/eval/dados'
- '/tmp/span-2/ver-1/train/dados'
- '/tmp/span-2/ver-1/eval/dados'
- '/tmp/span-2/ver-2/train/dados'
- '/tmp/span-2/ver-2/eval/dados'
e a configuração de entrada é mostrada abaixo:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
ao acionar o pipeline, ele processará:
- '/tmp/span-2/ver-2/train/data' como divisão do trem
- '/tmp/span-2/ver-2/eval/data' como divisão de avaliação
com número de extensão como '2' e número de versão como '2'. Se mais tarde '/tmp/span-2/ver-3/...' estiver pronto, basta acionar o pipeline novamente e ele selecionará o intervalo '2' e a versão '3' para processamento. Abaixo mostra o exemplo de código para usar a especificação de versão:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Configuração de intervalo
O TFX suporta a recuperação e o processamento de um intervalo específico no ExampleGen baseado em arquivo usando range config, uma configuração abstrata usada para descrever intervalos para diferentes entidades TFX. Para recuperar um intervalo específico, defina range_config para um componente ExampleGen baseado em arquivo. Por exemplo, vamos supor que existam dados de entrada:
- '/tmp/span-01/train/dados'
- '/tmp/span-01/eval/dados'
- '/tmp/span-02/train/dados'
- '/tmp/span-02/eval/dados'
Para recuperar e processar especificamente dados com intervalo '1', especificamos uma configuração de intervalo além da configuração de entrada. Observe que ExampleGen oferece suporte apenas a intervalos estáticos de intervalo único (para especificar o processamento de intervalos individuais específicos). Assim, para StaticRange, start_span_number deve ser igual a end_span_number. Usando o intervalo fornecido e as informações de largura do intervalo (se fornecidas) para preenchimento com zeros, o ExampleGen substituirá a especificação SPAN nos padrões de divisão fornecidos pelo número do intervalo desejado. Um exemplo de uso é mostrado abaixo:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
A configuração de intervalo também pode ser usada para processar datas específicas, se a especificação de data for usada em vez da especificação SPAN. Por exemplo, vamos supor que existam dados de entrada organizados por data do calendário:
- '/tmp/1970-01-02/trem/dados'
- '/tmp/1970-01-02/eval/dados'
- '/tmp/1970-01-03/trem/dados'
- '/tmp/1970-01-03/eval/dados'
Para recuperar e processar especificamente dados de 2 de janeiro de 1970, fazemos o seguinte:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Exemplo personalizadoGen
Se os componentes do ExampleGen atualmente disponíveis não atenderem às suas necessidades, você poderá criar um ExampleGen personalizado, que permitirá a leitura de diferentes fontes de dados ou em diferentes formatos de dados.
Personalização de ExampleGen baseada em arquivo (experimental)
Primeiro, estenda BaseExampleGenExecutor com um Beam PTransform personalizado, que fornece a conversão de sua divisão de entrada de treinamento/avaliação em exemplos TF. Por exemplo, o executor CsvExampleGen fornece a conversão de uma divisão CSV de entrada em exemplos TF.
Em seguida, crie um componente com o executor acima, como feito em CsvExampleGen component . Como alternativa, passe um executor personalizado para o componente ExemploGen padrão conforme mostrado abaixo.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Agora também oferecemos suporte à leitura de arquivos Avro e Parquet usando este método .
Formatos de dados adicionais
O Apache Beam oferece suporte à leitura de vários formatos de dados adicionais . através de transformações de E/S de feixe. Você pode criar componentes SampleGen personalizados aproveitando o Beam I/O Transforms usando um padrão semelhante ao exemplo Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
No momento em que este livro foi escrito, os formatos e fontes de dados atualmente suportados pelo Beam Python SDK incluem:
- Amazon S3
- Apache Avro
- Apache Hadoop
- Apache Kafka
- Parquet Apache
- Google CloudBigQuery
- Google Cloud BigTable
- Armazenamento de dados do Google Cloud
- Google Cloud Pub/Sub
- Armazenamento em nuvem do Google (GCS)
- MongoDB
Verifique os documentos do Beam para obter a lista mais recente.
Personalização de ExampleGen baseada em consulta (experimental)
Primeiro, estenda BaseExampleGenExecutor com um Beam PTransform personalizado, que lê a fonte de dados externa. Em seguida, crie um componente simples estendendo QueryBasedExampleGen.
Isso pode ou não exigir configurações de conexão adicionais. Por exemplo, o executor do BigQuery lê usando um conector beam.io padrão, que abstrai os detalhes de configuração da conexão. O executor Presto requer um Beam PTransform personalizado e um protobuf de configuração de conexão personalizado como entrada.
Se uma configuração de conexão for necessária para um componente SampleGen personalizado, crie um novo protobuf e passe-o por meio de custom_config, que agora é um parâmetro de execução opcional. Abaixo está um exemplo de como usar um componente configurado.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Componentes downstream de exemploGen
A configuração de divisão personalizada é suportada para componentes downstream.
EstatísticaGen
O comportamento padrão é gerar estatísticas para todas as divisões.
Para excluir quaisquer divisões, defina exclude_splits para o componente StatisticsGen. Por exemplo:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
O comportamento padrão é gerar um esquema baseado em todas as divisões.
Para excluir quaisquer divisões, defina exclude_splits para o componente SchemaGen. Por exemplo:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ExemploValidador
O comportamento padrão é validar as estatísticas de todas as divisões em exemplos de entrada em relação a um esquema.
Para excluir quaisquer divisões, defina exclude_splits para o componente ExampleValidator. Por exemplo:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Transformar
O comportamento padrão é analisar e produzir os metadados da divisão 'train' e transformar todas as divisões.
Para especificar as divisões de análise e de transformação, defina splits_config para o componente Transform. Por exemplo:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Treinador e sintonizador
O comportamento padrão é treinar na divisão 'train' e avaliar na divisão 'eval'.
Para especificar as divisões do trem e avaliar as divisões, defina train_args e eval_args para o componente Trainer. Por exemplo:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Avaliador
O comportamento padrão é fornecer métricas calculadas na divisão 'eval'.
Para calcular estatísticas de avaliação em divisões personalizadas, defina example_splits para o componente Evaluator. Por exemplo:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Mais detalhes estão disponíveis na referência da API CsvExampleGen , na implementação da API FileBasedExampleGen e na referência da API ImportExampleGen .