
جزء ExampleGen TFX Pipeline داده ها را به خطوط لوله TFX وارد می کند. این فایلها/سرویسهای خارجی را برای تولید نمونههایی که توسط سایر اجزای TFX خوانده میشوند، مصرف میکند. همچنین پارتیشن سازگار و قابل تنظیم را فراهم می کند و مجموعه داده را برای بهترین عمل ML به هم می زند.
- مصرف می کند: داده ها از منابع داده خارجی مانند CSV،
TFRecord، Avro، Parket و BigQuery. - انتشار: رکوردهای
tf.Example، رکوردهایtf.SequenceExample، یا فرمت پروتو، بسته به قالب بار.
ExampleGen و سایر اجزاء
ExampleGen داده هایی را برای مؤلفه هایی فراهم می کند که از کتابخانه TensorFlow Data Validation استفاده می کنند، مانند SchemaGen ، StatisticsGen ، و Example Validator . همچنین دادههایی را برای Transform فراهم میکند، که از کتابخانه TensorFlow Transform و در نهایت برای استقرار اهداف در طول استنتاج استفاده میکند.
منابع و فرمت های داده
در حال حاضر نصب استاندارد TFX شامل اجزای کامل ExampleGen برای این منابع داده و فرمتها است:
مجری های سفارشی نیز در دسترس هستند که توسعه مؤلفه های ExampleGen را برای این منابع داده و قالب ها امکان پذیر می کنند:
برای اطلاعات بیشتر در مورد نحوه استفاده و توسعه مجری های سفارشی، به مثال های استفاده در کد منبع و این بحث مراجعه کنید.
علاوه بر این، این منابع داده و قالبها به عنوان نمونههای مؤلفه سفارشی در دسترس هستند:
دریافت فرمت های داده ای که توسط Apache Beam پشتیبانی می شوند
Apache Beam از دریافت داده ها از طیف گسترده ای از منابع و قالب های داده پشتیبانی می کند ( به زیر مراجعه کنید ). این قابلیتها را میتوان برای ایجاد مؤلفههای ExampleGen سفارشی برای TFX، که توسط برخی مؤلفههای ExampleGen موجود نشان داده شده است، استفاده کرد ( به زیر مراجعه کنید ).
نحوه استفاده از ExampleGen Component
برای منابع داده پشتیبانی شده (در حال حاضر، فایلهای CSV، فایلهای TFRecord با tf.Example ، tf.SequenceExample و فرمت پروتو، و نتایج جستارهای BigQuery) مؤلفه Pipeline ExampleGen را میتوان مستقیماً در استقرار استفاده کرد و نیاز به سفارشیسازی کمی دارد. به عنوان مثال:
example_gen = CsvExampleGen(input_base='data_root')
یا مانند زیر برای وارد کردن TFRecord خارجی با tf.Example به طور مستقیم:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
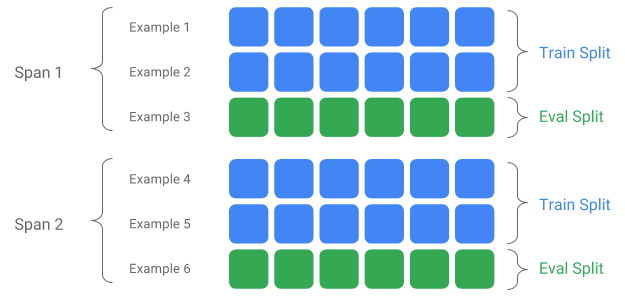
Span، نسخه و Split
Span مجموعه ای از نمونه های آموزشی است. اگر دادههای شما روی یک فایل سیستم باقی بماند، هر Span ممکن است در یک فهرست جداگانه ذخیره شود. معناشناسی یک Span در TFX کدگذاری نشده است. یک Span ممکن است با یک روز داده، یک ساعت داده یا هر گروه بندی دیگری که برای کار شما معنادار است مطابقت داشته باشد.
هر Span می تواند چندین نسخه از داده ها را در خود نگه دارد. برای مثال، اگر برخی از نمونهها را از یک Span برای پاک کردن دادههای بی کیفیت حذف کنید، میتواند منجر به نسخه جدیدی از آن Span شود. به طور پیش فرض، اجزای TFX بر روی آخرین نسخه در یک Span کار می کنند.
هر نسخه در یک Span را می توان به چند تقسیم تقسیم کرد. رایج ترین مورد استفاده برای تقسیم Span، تقسیم آن به داده های آموزشی و ارزیابی است.
تقسیم ورودی/خروجی سفارشی
برای سفارشی کردن نسبت تقسیم قطار/eval که ExampleGen خروجی میدهد، output_config برای مؤلفه ExampleGen تنظیم کنید. به عنوان مثال:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
توجه کنید که در این مثال hash_buckets چگونه تنظیم شده است.
برای منبع ورودی که قبلاً تقسیم شده است، input_config برای مؤلفه ExampleGen تنظیم کنید:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
برای ژن نمونه مبتنی بر فایل (مانند CsvExampleGen و ImportExampleGen)، pattern یک الگوی فایل نسبی کروی است که به فایلهای ورودی با دایرکتوری ریشه دادهشده توسط مسیر پایه ورودی نگاشت میشود. برای ژن مثال مبتنی بر پرس و جو (مثلا BigQueryExampleGen، PrestoExampleGen)، pattern یک پرس و جوی SQL است.
به طور پیش فرض، کل dir پایه ورودی به عنوان یک تقسیم ورودی واحد در نظر گرفته می شود و تقسیم خروجی قطار و eval با نسبت 2:1 ایجاد می شود.
لطفاً برای پیکربندی تقسیم ورودی و خروجی ExampleGen به proto/example_gen.proto مراجعه کنید. و برای استفاده از تقسیم های سفارشی پایین دست به راهنمای اجزای پایین دست مراجعه کنید.
روش تقسیم
هنگام استفاده از روش تقسیم hash_buckets ، به جای کل رکورد، می توان از یک ویژگی برای پارتیشن بندی نمونه ها استفاده کرد. اگر ویژگی وجود داشته باشد، ExampleGen از اثر انگشت آن ویژگی به عنوان کلید پارتیشن استفاده می کند.
از این ویژگی می توان برای حفظ یک تقسیم پایدار در خصوص ویژگی های خاص مثال ها استفاده کرد: برای مثال، اگر "user_id" به عنوان نام ویژگی پارتیشن انتخاب شود، یک کاربر همیشه در همان تقسیم قرار می گیرد.
تفسیر معنای "ویژگی" و نحوه تطبیق یک "ویژگی" با نام مشخص شده به پیاده سازی ExampleGen و نوع نمونه ها بستگی دارد.
برای پیاده سازی های آماده ExampleGen:
- اگر tf.Example را ایجاد کند، "ویژگی" به معنای ورودی در tf.Example.features.feature است.
- اگر tf.SequenceExample را ایجاد کند، "ویژگی" به معنای ورودی در tf.SequenceExample.context.feature است.
- فقط ویژگیهای int64 و bytes پشتیبانی میشوند.
در موارد زیر، ExampleGen خطاهای زمان اجرا ایجاد می کند:
- نام ویژگی مشخص شده در مثال وجود ندارد.
- ویژگی خالی:
tf.train.Feature(). - انواع ویژگی های پشتیبانی نشده، به عنوان مثال، ویژگی های شناور.
برای خروجی تقسیم train/eval بر اساس یک ویژگی در مثالها، output_config برای مؤلفه ExampleGen تنظیم کنید. به عنوان مثال:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
به نحوه تنظیم partition_feature_name در این مثال توجه کنید.
دهانه
Span را می توان با استفاده از مشخصات '{SPAN}' در الگوی glob ورودی بازیابی کرد:
- این مشخصات با ارقام مطابقت دارد و داده ها را در اعداد SPAN مربوطه نگاشت می کند. برای مثال، «data_{SPAN}-*.tfrecord» فایلهایی مانند «data_12-a.tfrecord»، «data_12-b.tfrecord» را جمعآوری میکند.
- به صورت اختیاری، این مشخصات را می توان با عرض اعداد صحیح در هنگام نقشه برداری مشخص کرد. برای مثال، «data_{SPAN:2}.file» به فایلهایی مانند «data_02.file» و «data_27.file» (به ترتیب به عنوان ورودی برای Span-2 و Span-27) نگاشت میشود، اما به «data_1» نگاشت نمیشود. file" و نه "data_123.file".
- زمانی که مشخصات SPAN وجود ندارد، فرض بر این است که همیشه Span '0' باشد.
- اگر SPAN مشخص شده باشد، خط لوله آخرین بازه را پردازش می کند و شماره دهانه را در ابرداده ذخیره می کند.
به عنوان مثال، فرض کنید داده های ورودی وجود دارد:
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
و پیکربندی ورودی به صورت زیر نشان داده شده است:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
هنگام راه اندازی خط لوله، پردازش می کند:
- '/tmp/span-2/train/data' به عنوان تقسیم قطار
- '/tmp/span-2/eval/data' به عنوان تقسیم eval
با شماره دهانه "2". اگر بعداً '/tmp/span-3/...' آماده شد، کافی است خط لوله را دوباره فعال کنید و دهانه '3' را برای پردازش انتخاب کند. در زیر مثال کد برای استفاده از span spec را نشان می دهد:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
بازیابی یک بازه مشخص را می توان با RangeConfig انجام داد که در زیر به تفصیل توضیح داده شده است.
تاریخ
اگر منبع داده شما بر اساس تاریخ بر روی سیستم فایل سازماندهی شده است، TFX از نگاشت تاریخ ها به طور مستقیم برای اعداد پشتیبانی می کند. سه مشخصات برای نشان دادن نقشه برداری از تاریخ تا بازه وجود دارد: {YYYY}، {MM} و {DD}:
- در صورتی که مشخص شده باشد، این سه مشخصات باید به طور کلی در الگوی glob ورودی وجود داشته باشند:
- مشخصات {SPAN} یا این مجموعه از مشخصات تاریخ را میتوان منحصراً مشخص کرد.
- یک تاریخ تقویم با سال از YYYY، ماه از MM، و روز ماه از DD محاسبه میشود، سپس عدد بازه به عنوان تعداد روزهای پس از دوره یونیکس (یعنی 01-01-1970) محاسبه میشود. برای مثال، «log-{YYYY}{MM}{DD}.data» با فایل «log-19700101.data» مطابقت دارد و آن را به عنوان ورودی برای Span-0 مصرف میکند و «log-20170101.data» بهعنوان ورودی برای Span-17167.
- اگر این مجموعه از مشخصات تاریخ مشخص شده باشد، خط لوله آخرین تاریخ را پردازش میکند و شماره فاصله مربوطه را در ابرداده ذخیره میکند.
به عنوان مثال، فرض کنید داده های ورودی سازماندهی شده بر اساس تاریخ تقویم وجود دارد:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
و پیکربندی ورودی به صورت زیر نشان داده شده است:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
هنگام راه اندازی خط لوله، پردازش می کند:
- '/tmp/1970-01-03/train/data' به عنوان تقسیم قطار
- '/tmp/1970-01-03/eval/data' به عنوان تقسیم ارزش
با شماره دهانه "2". اگر بعداً '/tmp/1970-01-04/...' آماده شد، کافی است خط لوله را دوباره راه اندازی کنید و دهانه '3' را برای پردازش انتخاب کنید. در زیر نمونه کد برای استفاده از مشخصات تاریخ را نشان می دهد:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
نسخه
نسخه را می توان با استفاده از مشخصات '{VERSION}' در الگوی glob ورودی بازیابی کرد:
- این مشخصات با ارقام مطابقت دارد و داده ها را به اعداد VERSION مربوطه در زیر SPAN نگاشت می کند. توجه داشته باشید که مشخصات نسخه را می توان ترکیبی با مشخصات Span یا Date استفاده کرد.
- این مشخصات همچنین می تواند به صورت اختیاری با عرض به همان روشی که مشخصات SPAN تعیین می شود مشخص شود. به عنوان مثال 'span-{SPAN}/version-{VERSION:4}/data-*'.
- وقتی مشخصات VERSION وجود ندارد، نسخه روی None تنظیم می شود.
- اگر SPAN و VERSION هر دو مشخص شده باشند، Pipeline آخرین نسخه را برای آخرین بازه پردازش می کند و شماره نسخه را در ابرداده ذخیره می کند.
- اگر VERSION مشخص شده باشد، اما نه SPAN (یا مشخصات تاریخ)، یک خطا ایجاد می شود.
به عنوان مثال، فرض کنید داده های ورودی وجود دارد:
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
و پیکربندی ورودی به صورت زیر نشان داده شده است:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
هنگام راه اندازی خط لوله، پردازش می کند:
- '/tmp/span-2/ver-2/train/data' به عنوان تقسیم قطار
- '/tmp/span-2/ver-2/eval/data' به عنوان تقسیم eval
با شماره دهانه "2" و شماره نسخه "2". اگر بعداً '/tmp/span-2/ver-3/...' آماده شد، کافی است خط لوله را دوباره فعال کنید و دامنه '2' و نسخه '3' را برای پردازش انتخاب می کند. در زیر نمونه کد برای استفاده از مشخصات نسخه را نشان می دهد:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
پیکربندی محدوده
TFX از بازیابی و پردازش یک دامنه خاص در ExampleGen مبتنی بر فایل با استفاده از پیکربندی محدوده پشتیبانی میکند، یک پیکربندی انتزاعی که برای توصیف محدودههای موجودیتهای مختلف TFX استفاده میشود. برای بازیابی یک دامنه خاص، range_config برای یک جزء ExampleGen مبتنی بر فایل تنظیم کنید. به عنوان مثال، فرض کنید داده های ورودی وجود دارد:
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
برای بازیابی و پردازش دادهها با span '1'، علاوه بر پیکربندی ورودی، پیکربندی محدوده را نیز مشخص میکنیم. توجه داشته باشید که ExampleGen فقط از محدوده های استاتیک تک اسپان (برای مشخص کردن پردازش گستره های فردی خاص) پشتیبانی می کند. بنابراین، برای StaticRange، start_span_number باید برابر end_span_number باشد. با استفاده از دهانه ارائه شده، و اطلاعات عرض دهانه (در صورت ارائه) برای لایه صفر، ExampleGen مشخصات SPAN را در الگوهای تقسیم ارائه شده با عدد دهانه مورد نظر جایگزین می کند. نمونه ای از استفاده در زیر نشان داده شده است:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
پیکربندی محدوده همچنین می تواند برای پردازش تاریخ های خاص استفاده شود، اگر از مشخصات تاریخ به جای مشخصات SPAN استفاده شود. به عنوان مثال، فرض کنید داده های ورودی سازماندهی شده بر اساس تاریخ تقویم وجود دارد:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
برای بازیابی و پردازش دادهها در 2 ژانویه 1970، موارد زیر را انجام میدهیم:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
ExampleGen سفارشی
اگر اجزای ExampleGen موجود در حال حاضر با نیازهای شما مطابقت ندارد، می توانید یک ExampleGen سفارشی ایجاد کنید، که به شما امکان می دهد از منابع داده های مختلف یا در قالب های داده مختلف بخوانید.
سفارشی سازی ExampleGen مبتنی بر فایل (تجربی)
ابتدا، BaseExampleGenExecutor را با یک Beam PTransform سفارشی گسترش دهید، که تبدیل از تقسیم ورودی train/eval شما به نمونههای TF را فراهم میکند. به عنوان مثال، مجری CsvExampleGen تبدیل از یک تقسیم CSV ورودی به نمونه های TF را فراهم می کند.
سپس، همانطور که در کامپوننت CsvExampleGen انجام شد، یک کامپوننت با مجری بالا ایجاد کنید. از طرف دیگر، مطابق شکل زیر، یک اجراکننده سفارشی را به مؤلفه استاندارد ExampleGen منتقل کنید.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
در حال حاضر، ما همچنین از خواندن فایلهای Avro و Parquet با استفاده از این روش پشتیبانی میکنیم.
فرمت های داده های اضافی
Apache Beam از خواندن تعدادی فرمت داده اضافی پشتیبانی می کند. از طریق Beam I/O Transforms. شما می توانید با استفاده از Beam I/O Transforms با استفاده از الگوی مشابه با مثال Avro ، اجزای ExampleGen سفارشی ایجاد کنید.
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
از زمان نوشتن این مقاله، فرمتها و منابع دادهای که در حال حاضر برای Beam Python SDK پشتیبانی میشوند عبارتند از:
- آمازون S3
- آپاچی آورو
- آپاچی هادوپ
- آپاچی کافکا
- پارکت آپاچی
- Google Cloud BigQuery
- Google Cloud BigTable
- Google Cloud Datastore
- Google Cloud Pub/Sub
- Google Cloud Storage (GCS)
- MongoDB
برای آخرین لیست ، اسناد Beam را بررسی کنید.
سفارشی سازی ExampleGen مبتنی بر پرس و جو (تجربی)
ابتدا BaseExampleGenExecutor را با یک Beam PTransform سفارشی گسترش دهید که از منبع داده خارجی خوانده می شود. سپس با گسترش QueryBasedExampleGen یک کامپوننت ساده ایجاد کنید.
این ممکن است نیاز به تنظیمات اتصال اضافی داشته باشد یا نباشد. برای مثال، مجری BigQuery با استفاده از یک رابط پیشفرض beam.io میخواند، که جزئیات پیکربندی اتصال را خلاصه میکند. مجری Presto به یک Beam PTransform سفارشی و یک پروتوباف پیکربندی اتصال سفارشی به عنوان ورودی نیاز دارد.
اگر یک پیکربندی اتصال برای یک جزء ExampleGen سفارشی مورد نیاز است، یک پروتوباف جدید ایجاد کنید و آن را از طریق custom_config که اکنون یک پارامتر اجرایی اختیاری است، ارسال کنید. در زیر مثالی از نحوه استفاده از یک جزء پیکربندی شده آورده شده است.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
ExampleGen اجزای پایین دست
پیکربندی تقسیم سفارشی برای اجزای پایین دست پشتیبانی می شود.
StatisticsGen
رفتار پیشفرض این است که تولید آمار برای همه تقسیمها انجام شود.
برای حذف هر گونه تقسیم، exclude_splits برای جزء StatisticsGen تنظیم کنید. به عنوان مثال:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
رفتار پیشفرض ایجاد یک طرح واره بر اساس همه تقسیمها است.
برای حذف هر گونه تقسیم، exclude_splits برای جزء SchemaGen تنظیم کنید. به عنوان مثال:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
Example Validator
رفتار پیشفرض اعتبارسنجی آمار تمام تقسیمبندیها در نمونههای ورودی در برابر یک طرح است.
برای حذف هر گونه تقسیم، exclude_splits برای جزء ExampleValidator تنظیم کنید. به عنوان مثال:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
تبدیل کنید
رفتار پیشفرض تجزیه و تحلیل و تولید فراداده از تقسیم «قطار» و تبدیل همه تقسیمها است.
برای تعیین تقسیم تجزیه و تحلیل و تبدیل تقسیم، splits_config برای جزء Transform تنظیم کنید. به عنوان مثال:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
ترینر و تیونر
رفتار پیشفرض آموزش در تقسیم «قطار» و ارزیابی در تقسیم «eval» است.
برای تعیین تقسیمبندی قطار و ارزیابی تقسیمبندیها، مولفههای train_args و eval_args را برای Trainer تنظیم کنید. به عنوان مثال:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
ارزیاب
رفتار پیشفرض معیارهایی است که بر روی تقسیم «eval» محاسبه میشوند.
برای محاسبه آمار ارزیابی در تقسیمبندیهای سفارشی، example_splits را برای مؤلفه Evaluator تنظیم کنید. به عنوان مثال:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
جزئیات بیشتر در مرجع CsvExampleGen API ، اجرای FileBasedExampleGen API و ImportExampleGen مرجع API موجود است.