
คอมโพเนนต์ไปป์ไลน์ ExampleGen TFX นำเข้าข้อมูลไปยังไปป์ไลน์ TFX ใช้ไฟล์/บริการภายนอกเพื่อสร้างตัวอย่างซึ่งคอมโพเนนต์ TFX อื่นๆ จะอ่านได้ นอกจากนี้ยังมีพาร์ติชันที่สอดคล้องและกำหนดค่าได้ และสับเปลี่ยนชุดข้อมูลสำหรับแนวทางปฏิบัติที่ดีที่สุดของ ML
- ใช้: ข้อมูลจากแหล่งข้อมูลภายนอก เช่น CSV,
TFRecord, Avro, Parquet และ BigQuery - ส่งเสียง: บันทึก
tf.Example, บันทึกtf.SequenceExampleหรือรูปแบบโปรโต ขึ้นอยู่กับรูปแบบเพย์โหลด
ExampleGen และส่วนประกอบอื่น ๆ
ExampleGen ให้ข้อมูลแก่ส่วนประกอบที่ใช้ไลบรารี การตรวจสอบความถูกต้องของข้อมูล TensorFlow เช่น SchemaGen , StatisticsGen และ Example Validator นอกจากนี้ยังให้ข้อมูลแก่ Transform ซึ่งใช้ประโยชน์จากไลบรารี TensorFlow Transform และท้ายที่สุดไปยังเป้าหมายการปรับใช้ในระหว่างการอนุมาน
แหล่งข้อมูลและรูปแบบ
ปัจจุบันการติดตั้งมาตรฐานของ TFX มีส่วนประกอบของ ExampleGen เต็มรูปแบบสำหรับแหล่งข้อมูลและรูปแบบเหล่านี้:
นอกจากนี้ยังมีตัวดำเนินการแบบกำหนดเองซึ่งช่วยให้สามารถพัฒนาส่วนประกอบ ExampleGen สำหรับแหล่งข้อมูลและรูปแบบเหล่านี้:
ดูตัวอย่างการใช้งานในซอร์สโค้ดและ การสนทนานี้ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีการใช้และพัฒนาตัวดำเนินการแบบกำหนดเอง
นอกจากนี้ แหล่งข้อมูลและรูปแบบเหล่านี้มีให้เป็นตัวอย่าง ส่วนประกอบที่กำหนดเอง :
การนำเข้ารูปแบบข้อมูลที่ Apache Beam รองรับ
Apache Beam รองรับการนำเข้าข้อมูลจาก แหล่งข้อมูลและรูปแบบที่หลากหลาย ( ดูด้านล่าง ) ความสามารถเหล่านี้สามารถใช้เพื่อสร้างส่วนประกอบ ExampleGen แบบกำหนดเองสำหรับ TFX ซึ่งแสดงให้เห็นโดยส่วนประกอบ ExampleGen ที่มีอยู่บางส่วน ( ดูด้านล่าง )
วิธีใช้ส่วนประกอบ ExampleGen
สำหรับแหล่งข้อมูลที่รองรับ (ปัจจุบันคือไฟล์ CSV, ไฟล์ TFRecord ที่มีรูปแบบ tf.Example , tf.SequenceExample และ proto และผลลัพธ์ของการสืบค้น BigQuery) คอมโพเนนต์ไปป์ไลน์ ExampleGen สามารถนำมาใช้โดยตรงในการปรับใช้และต้องมีการปรับแต่งเพียงเล็กน้อย ตัวอย่างเช่น:
example_gen = CsvExampleGen(input_base='data_root')
หรือชอบด้านล่างสำหรับการนำเข้า TFRecord ภายนอกด้วย tf.Example โดยตรง:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
ช่วง เวอร์ชัน และการแยก
Span คือการรวมกลุ่มตัวอย่างการฝึกอบรม หากข้อมูลของคุณยังคงอยู่ในระบบไฟล์ แต่ละ Span อาจถูกจัดเก็บไว้ในไดเร็กทอรีแยกต่างหาก ความหมายของ Span ไม่ได้ฮาร์ดโค้ดลงใน TFX Span อาจสอดคล้องกับหนึ่งวันของข้อมูล ชั่วโมงของข้อมูล หรือการจัดกลุ่มอื่นๆ ที่มีความหมายต่องานของคุณ
แต่ละ Span สามารถเก็บข้อมูลได้หลายเวอร์ชัน เพื่อเป็นตัวอย่าง หากคุณลบตัวอย่างบางส่วนออกจาก Span เพื่อล้างข้อมูลคุณภาพต่ำ อาจส่งผลให้ Span เวอร์ชันใหม่เกิดขึ้น ตามค่าเริ่มต้น ส่วนประกอบ TFX ทำงานในเวอร์ชันล่าสุดภายในช่วง
แต่ละเวอร์ชันภายใน Span สามารถแบ่งย่อยออกเป็นหลายส่วนเพิ่มเติมได้ กรณีการใช้งานที่พบบ่อยที่สุดสำหรับการแยก Span คือการแบ่งออกเป็นข้อมูลการฝึกอบรมและการประเมินผล
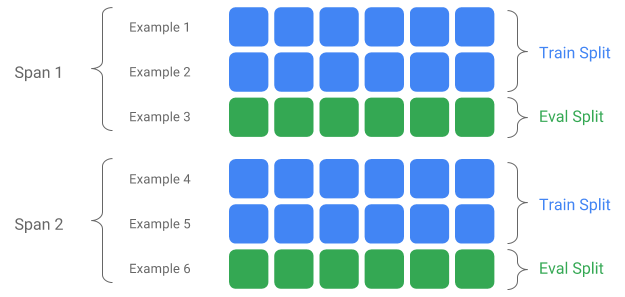
การแยกอินพุต/เอาท์พุตแบบกำหนดเอง
หากต้องการกำหนดอัตราส่วนการแยก Train/Eval ที่ ExampleGen จะส่งออก ให้ตั้ง output_config สำหรับส่วนประกอบ ExampleGen ตัวอย่างเช่น:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
โปรดสังเกตว่า hash_buckets ถูกตั้งค่าในตัวอย่างนี้อย่างไร
สำหรับแหล่งอินพุตที่ถูกแบ่งแล้ว ให้ตั้ง input_config สำหรับส่วนประกอบ ExampleGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
สำหรับไฟล์ตัวอย่าง Gen (เช่น CsvExampleGen และ ImportExampleGen) pattern คือรูปแบบไฟล์แบบโกลบอลที่แมปกับไฟล์อินพุตที่มีไดเร็กทอรีรากที่กำหนดโดยพาธฐานอินพุต สำหรับตัวอย่าง Gen ที่อิงจากการสืบค้น (เช่น BigQueryExampleGen, PrestoExampleGen) pattern คือการสืบค้น SQL
ตามค่าเริ่มต้น dir ฐานอินพุตทั้งหมดจะถือเป็นการแยกอินพุตเดี่ยว และการแยกเอาต์พุตของรถไฟและ eval จะถูกสร้างขึ้นด้วยอัตราส่วน 2:1
โปรดดู proto/example_gen.proto สำหรับการกำหนดค่าการแยกอินพุตและเอาต์พุตของ ExampleGen และดู คำแนะนำส่วนประกอบดาวน์สตรีม สำหรับการใช้ดาวน์สตรีมการแยกแบบกำหนดเอง
วิธีการแยก
เมื่อใช้วิธีการแยก hash_buckets แทนที่จะใช้ทั้งบันทึก เราสามารถใช้คุณลักษณะสำหรับการแบ่งพาร์ติชันตัวอย่างได้ หากมีคุณลักษณะอยู่ ExampleGen จะใช้ลายนิ้วมือของคุณลักษณะนั้นเป็นคีย์พาร์ติชัน
คุณลักษณะนี้สามารถใช้เพื่อรักษาการแยกที่เสถียรด้วยคุณสมบัติบางอย่างของตัวอย่าง: ตัวอย่างเช่น ผู้ใช้จะถูกใส่ในการแบ่งเดียวกันเสมอ หากเลือก "user_id" เป็นชื่อคุณลักษณะของพาร์ติชัน
การตีความความหมายของ "คุณลักษณะ" และวิธีจับคู่ "คุณลักษณะ" กับชื่อที่ระบุนั้นขึ้นอยู่กับการใช้งาน ExampleGen และประเภทของตัวอย่าง
สำหรับการใช้งาน ExampleGen สำเร็จรูป:
- หากสร้าง tf.Example ขึ้นมา "ฟีเจอร์" จะหมายถึงรายการใน tf.Example.features.feature
- หากสร้าง tf.SequenceExample ดังนั้น "ฟีเจอร์" จะหมายถึงรายการใน tf.SequenceExample.context.feature
- รองรับเฉพาะฟีเจอร์ int64 และไบต์เท่านั้น
ในกรณีต่อไปนี้ ExampleGen จะแสดงข้อผิดพลาดรันไทม์:
- ไม่มีชื่อคุณลักษณะที่ระบุในตัวอย่าง
- คุณลักษณะที่ว่างเปล่า:
tf.train.Feature() - ประเภทฟีเจอร์ที่ไม่รองรับ เช่น คุณสมบัติโฟลต
หากต้องการเอาท์พุตการแยก Train/Eval ตามคุณลักษณะในตัวอย่าง ให้ตั้ง output_config สำหรับส่วนประกอบ ExampleGen ตัวอย่างเช่น:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
โปรดสังเกตว่า partition_feature_name ถูกตั้งค่าในตัวอย่างนี้อย่างไร
ช่วง
Span สามารถดึงข้อมูลได้โดยใช้ข้อมูลจำเพาะ '{SPAN}' ใน รูปแบบ glob อินพุต :
- ข้อมูลจำเพาะนี้จับคู่ตัวเลขและจับคู่ข้อมูลเข้ากับตัวเลข SPAN ที่เกี่ยวข้อง ตัวอย่างเช่น 'data_{SPAN}-*.tfrecord' จะรวบรวมไฟล์เช่น 'data_12-a.tfrecord', 'data_12-b.tfrecord'
- อีกทางเลือกหนึ่ง คุณสามารถระบุข้อมูลจำเพาะนี้ด้วยความกว้างของจำนวนเต็มเมื่อแมปได้ ตัวอย่างเช่น 'data_{SPAN:2}.file' แมปกับไฟล์เช่น 'data_02.file' และ 'data_27.file' (เป็นอินพุตสำหรับ Span-2 และ Span-27 ตามลำดับ) แต่ไม่ได้แมปกับ 'data_1 file' หรือ 'data_123.file'
- เมื่อข้อมูลจำเพาะ SPAN หายไป ระบบจะถือว่า Span เป็น '0' เสมอ
- หากมีการระบุ SPAN ไปป์ไลน์จะประมวลผลช่วงล่าสุด และจัดเก็บหมายเลขช่วงไว้ในข้อมูลเมตา
ตัวอย่างเช่น สมมติว่ามีข้อมูลที่ป้อนเข้ามา:
- '/tmp/span-1/รถไฟ/ข้อมูล'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/รถไฟ/ข้อมูล'
- '/tmp/span-2/eval/data'
และการกำหนดค่าอินพุตจะแสดงดังต่อไปนี้:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
เมื่อทริกเกอร์ไปป์ไลน์ มันจะประมวลผล:
- '/tmp/span-2/train/data' ขณะที่แยกรถไฟ
- '/tmp/span-2/eval/data' เป็นการแยก eval
โดยมีหมายเลขช่วงเป็น '2' หากพร้อมสำหรับ '/tmp/span-3/...' ในภายหลัง เพียงทริกเกอร์ไปป์ไลน์อีกครั้ง จากนั้นมันจะรับ span '3' สำหรับการประมวลผล ด้านล่างแสดงตัวอย่างโค้ดสำหรับการใช้ span spec:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
การเรียกข้อมูลช่วงหนึ่งสามารถทำได้ด้วย RangeConfig ซึ่งมีรายละเอียดด้านล่าง
วันที่
หากแหล่งข้อมูลของคุณจัดระเบียบตามระบบไฟล์ตามวันที่ TFX รองรับการแมปวันที่โดยตรงเพื่อขยายตัวเลข มีข้อกำหนดสามประการที่จะแสดงการแมปตั้งแต่วันที่จนถึงช่วง: {YYYY}, {MM} และ {DD}:
- ข้อมูลจำเพาะทั้งสามควรปรากฏพร้อมกันใน รูปแบบอินพุต glob หากมีการระบุ:
- สามารถระบุข้อกำหนด {SPAN} หรือข้อกำหนดวันที่ชุดนี้โดยเฉพาะได้
- วันที่ในปฏิทินซึ่งมีปีตั้งแต่ YYYY เดือนตั้งแต่ MM และวันของเดือนตั้งแต่ DD จะถูกคำนวณ จากนั้นหมายเลขช่วงจะคำนวณเป็นจำนวนวันนับตั้งแต่ยุคยูนิกซ์ (เช่น 1970-01-01) ตัวอย่างเช่น 'log-{YYYY}{MM}{DD}.data' จะจับคู่กับไฟล์ 'log-19700101.data' และใช้เป็นอินพุตสำหรับ Span-0 และ 'log-20170101.data' เป็นอินพุตสำหรับ ช่วง-17167.
- หากมีการระบุข้อกำหนดวันที่ชุดนี้ ไปป์ไลน์จะประมวลผลวันที่ล่าสุดล่าสุด และจัดเก็บหมายเลขการขยายที่สอดคล้องกันในข้อมูลเมตา
ตัวอย่างเช่น สมมติว่ามีข้อมูลที่ป้อนจัดตามวันที่ในปฏิทิน:
- '/tmp/1970-01-02/รถไฟ/ข้อมูล'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/รถไฟ/ข้อมูล'
- '/tmp/1970-01-03/eval/data'
และการกำหนดค่าอินพุตจะแสดงดังต่อไปนี้:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
เมื่อทริกเกอร์ไปป์ไลน์ มันจะประมวลผล:
- '/tmp/1970-01-03/train/data' ขณะที่แยกรถไฟ
- '/tmp/1970-01-03/eval/data' เป็นการแยก eval
โดยมีหมายเลขช่วงเป็น '2' หากพร้อมแล้วในภายหลังในวันที่ '/tmp/1970-01-04/...' เพียงทริกเกอร์ไปป์ไลน์อีกครั้ง จากนั้นมันจะรับช่วง '3' สำหรับการประมวลผล ด้านล่างแสดงตัวอย่างโค้ดสำหรับการใช้ข้อมูลจำเพาะวันที่:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
เวอร์ชัน
สามารถดึงข้อมูลเวอร์ชันได้โดยใช้ข้อมูลจำเพาะ '{VERSION}' ใน รูปแบบ glob อินพุต :
- ข้อมูลจำเพาะนี้จับคู่ตัวเลขและจับคู่ข้อมูลกับหมายเลข VERSION ที่เกี่ยวข้องภายใต้ SPAN โปรดทราบว่าข้อมูลจำเพาะเวอร์ชันสามารถใช้ร่วมกับข้อมูลจำเพาะ Span หรือ Date ได้
- ข้อมูลจำเพาะนี้สามารถระบุความกว้างได้ในลักษณะเดียวกับข้อกำหนด SPAN เช่น 'span-{SPAN}/version-{VERSION:4}/data-*'
- เมื่อข้อมูลจำเพาะ VERSION หายไป เวอร์ชันจะถูกตั้งค่าเป็นไม่มี
- หากมีการระบุทั้ง SPAN และ VERSION ไปป์ไลน์จะประมวลผลเวอร์ชันล่าสุดสำหรับช่วงล่าสุด และจัดเก็บหมายเลขเวอร์ชันไว้ในข้อมูลเมตา
- หากมีการระบุ VERSION แต่ไม่ใช่ SPAN (หรือข้อกำหนดวันที่) ข้อผิดพลาดจะเกิดขึ้น
ตัวอย่างเช่น สมมติว่ามีข้อมูลที่ป้อนเข้ามา:
- '/tmp/span-1/ver-1/รถไฟ/ข้อมูล'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/รถไฟ/ข้อมูล'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/รถไฟ/ข้อมูล'
- '/tmp/span-2/ver-2/eval/data'
และการกำหนดค่าอินพุตจะแสดงดังต่อไปนี้:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
เมื่อทริกเกอร์ไปป์ไลน์ มันจะประมวลผล:
- '/tmp/span-2/ver-2/train/data' ขณะที่แยกรถไฟ
- '/tmp/span-2/ver-2/eval/data' เป็นการแยก eval
โดยมีหมายเลขช่วงเป็น '2' และหมายเลขเวอร์ชันเป็น '2' หากในภายหลัง '/tmp/span-2/ver-3/...' พร้อมแล้ว เพียงทริกเกอร์ไปป์ไลน์อีกครั้ง จากนั้นมันจะรับ span '2' และเวอร์ชัน '3' สำหรับการประมวลผล ด้านล่างแสดงตัวอย่างโค้ดสำหรับการใช้ข้อมูลจำเพาะเวอร์ชัน:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
การกำหนดค่าช่วง
TFX รองรับการดึงข้อมูลและการประมวลผลช่วงเฉพาะใน ExampleGen แบบไฟล์โดยใช้การกำหนดค่าช่วง ซึ่งเป็นการกำหนดค่าเชิงนามธรรมที่ใช้อธิบายช่วงสำหรับเอนทิตี TFX ที่แตกต่างกัน หากต้องการดึงข้อมูลช่วงเฉพาะ ให้ตั้ง range_config สำหรับส่วนประกอบ ExampleGen ที่ใช้ไฟล์ ตัวอย่างเช่น สมมติว่ามีข้อมูลที่ป้อนเข้า:
- '/tmp/span-01/รถไฟ/ข้อมูล'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/รถไฟ/ข้อมูล'
- '/tmp/span-02/eval/data'
หากต้องการดึงและประมวลผลข้อมูลโดยเฉพาะด้วย span '1' เราจะระบุการกำหนดค่าช่วงนอกเหนือจากการกำหนดค่าอินพุต โปรดทราบว่า ExampleGen รองรับเฉพาะช่วงคงที่ช่วงเดียวเท่านั้น (เพื่อระบุการประมวลผลของแต่ละช่วงที่เฉพาะเจาะจง) ดังนั้น สำหรับ StaticRange start_span_number จะต้องเท่ากับ end_span_number การใช้ช่วงที่ให้มา และข้อมูลความกว้างช่วง (ถ้ามีให้) สำหรับการเติมศูนย์ ExampleGen จะแทนที่ข้อกำหนด SPAN ในรูปแบบการแยกที่ให้มาด้วยหมายเลขช่วงที่ต้องการ ตัวอย่างการใช้งานแสดงไว้ด้านล่าง:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
การกำหนดค่าช่วงยังสามารถใช้เพื่อประมวลผลวันที่ที่ระบุได้ หากใช้ข้อกำหนดวันที่แทนข้อกำหนด SPAN ตัวอย่างเช่น สมมติว่ามีข้อมูลที่ป้อนจัดตามวันที่ในปฏิทิน:
- '/tmp/1970-01-02/รถไฟ/ข้อมูล'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/รถไฟ/ข้อมูล'
- '/tmp/1970-01-03/eval/data'
ในการดึงและประมวลผลข้อมูลโดยเฉพาะในวันที่ 2 มกราคม 1970 เราจะดำเนินการดังต่อไปนี้:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
ตัวอย่างแบบกำหนดเองGen
หากส่วนประกอบ ExampleGen ที่มีอยู่ในปัจจุบันไม่ตรงกับความต้องการของคุณ คุณสามารถสร้าง ExampleGen แบบกำหนดเองได้ ซึ่งจะช่วยให้คุณสามารถอ่านจากแหล่งข้อมูลที่แตกต่างกันหรือในรูปแบบข้อมูลที่แตกต่างกันได้
การปรับแต่ง ExampleGen ตามไฟล์ (ทดลอง)
ขั้นแรก ขยาย BaseExampleGenExecutor ด้วย Beam PTransform แบบกำหนดเอง ซึ่งให้การแปลงจากการแยกอินพุต Train/Eval ของคุณไปเป็นตัวอย่าง TF ตัวอย่างเช่น ตัวดำเนินการ CsvExampleGen ให้การแปลงจากการแยก CSV อินพุตเป็นตัวอย่าง TF
จากนั้น สร้างส่วนประกอบด้วยตัวดำเนินการด้านบน ดังที่ทำใน ส่วนประกอบ CsvExampleGen หรือส่งตัวดำเนินการแบบกำหนดเองไปยังส่วนประกอบ ExampleGen มาตรฐานดังที่แสดงด้านล่าง
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
ขณะนี้ เรายังสนับสนุนการอ่านไฟล์ Avro และ Parquet โดยใช้ วิธี นี้
รูปแบบข้อมูลเพิ่มเติม
Apache Beam รองรับการอ่านรูป แบบข้อมูลเพิ่มเติม จำนวนหนึ่ง ผ่านการแปลง Beam I/O คุณสามารถสร้างส่วนประกอบ ExampleGen แบบกำหนดเองได้โดยใช้ประโยชน์จาก Beam I/O Transforms โดยใช้รูปแบบที่คล้ายกับ ตัวอย่าง Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
ในขณะที่เขียนบทความนี้ รูปแบบและแหล่งข้อมูลที่รองรับในปัจจุบันสำหรับ Beam Python SDK ได้แก่:
- อเมซอน S3
- อาปาเช่รว์
- อาปาเช่ ฮาดูป
- อาปาเช่ คาฟคา
- อาปาเช่ปาร์เก้
- Google Cloud BigQuery
- Google Cloud บิ๊กเทเบิล
- Google Cloud Datastore
- Google Cloud Pub/ย่อย
- ที่เก็บข้อมูลบนคลาวด์ของ Google (GCS)
- MongoDB
ตรวจสอบ เอกสาร Beam เพื่อดูรายการล่าสุด
การปรับแต่ง ExampleGen ตามแบบสอบถาม (ทดลอง)
ขั้นแรก ให้ขยาย BaseExampleGenExecutor ด้วย Beam PTransform แบบกำหนดเอง ซึ่งจะอ่านจากแหล่งข้อมูลภายนอก จากนั้น สร้างส่วนประกอบอย่างง่ายโดยขยาย QueryBasedExampleGen
ซึ่งอาจจำเป็นต้องมีการกำหนดค่าการเชื่อมต่อเพิ่มเติมหรือไม่ก็ได้ ตัวอย่างเช่น โปรแกรมดำเนินการ BigQuery อ่านโดยใช้ตัวเชื่อมต่อ Beam.io เริ่มต้น ซึ่งจะสรุปรายละเอียดการกำหนดค่าการเชื่อมต่อ ตัวดำเนินการ Presto ต้องใช้ Beam PTransform แบบกำหนดเองและ โปรโตคอลการกำหนดค่าการเชื่อมต่อแบบกำหนดเอง เป็นอินพุต
หากจำเป็นต้องมีการกำหนดค่าการเชื่อมต่อสำหรับส่วนประกอบ ExampleGen แบบกำหนดเอง ให้สร้าง protobuf ใหม่และส่งผ่านผ่าน custom_config ซึ่งขณะนี้เป็นพารามิเตอร์การดำเนินการทางเลือก ด้านล่างนี้คือตัวอย่างวิธีใช้ส่วนประกอบที่กำหนดค่าไว้
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
ส่วนประกอบดาวน์สตรีม ExampleGen
รองรับการกำหนดค่าการแยกแบบกำหนดเองสำหรับส่วนประกอบดาวน์สตรีม
สถิติพล
พฤติกรรมเริ่มต้นคือการสร้างสถิติสำหรับการแยกทั้งหมด
หากต้องการแยกการแยกใดๆ ให้ตั้ง exclude_splits สำหรับองค์ประกอบ StatisticsGen ตัวอย่างเช่น:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
พฤติกรรมเริ่มต้นคือการสร้างสคีมาตามการแยกทั้งหมด
หากต้องการยกเว้นการแยกใดๆ ให้ตั้ง exclude_splits สำหรับองค์ประกอบ SchemaGen ตัวอย่างเช่น:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ตัวอย่าง Validator
พฤติกรรมเริ่มต้นคือการตรวจสอบสถิติของการแยกทั้งหมดในตัวอย่างอินพุตกับสคีมา
หากต้องการแยกการแยกออก ให้ตั้ง exclude_splits สำหรับส่วนประกอบ ExampleValidator ตัวอย่างเช่น:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
แปลงร่าง
พฤติกรรมเริ่มต้นคือการวิเคราะห์และสร้างข้อมูลเมตาจากการแยก 'ฝึก' และแปลงการแยกทั้งหมด
หากต้องการระบุการแยกการวิเคราะห์และการแยกการแปลง ให้ตั้ง splits_config สำหรับคอมโพเนนต์การแปลง ตัวอย่างเช่น:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
เทรนเนอร์และจูนเนอร์
พฤติกรรมเริ่มต้นคือการฝึกบนการแยก 'ฝึก' และประเมินผลบนการแยก 'ประเมิน'
หากต้องการระบุการแยกขบวนและประเมินการแยก ให้ตั้ง train_args และ eval_args สำหรับส่วนประกอบ Trainer ตัวอย่างเช่น:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
ผู้ประเมิน
การทำงานเริ่มต้นคือการจัดหาหน่วยเมตริกที่คำนวณจากการแยก 'eval'
ในการคำนวณสถิติการประเมินผลบนการแยกแบบกำหนดเอง ให้ตั้ง example_splits สำหรับส่วนประกอบ Evaluator ตัวอย่างเช่น:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
มีรายละเอียดเพิ่มเติมใน การอ้างอิง CsvExampleGen API , การใช้งาน FileBasedExampleGen API และ การอ้างอิง ImportExampleGen API